ASP.NET Core 5 for Beginners
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Marketdirect Storefront® Release Notes
MarketDirect StoreFront® Release Notes Version 12.2 2 ⚫ EFI Productivity Suite | MarketDirect StoreFront 12.2 Release Notes Copyright © 2004 - 2021 by Electronics for Imaging, Inc. All Rights Reserved. EFI Productivity Suite | MarketDirect StoreFront Release Notes August 2021 MarketDirect StoreFront v. 12.2 Document version 1.0 / 45145977 This publication is protected by copyright, and all rights are reserved. No part of it may be reproduced or transmitted in any form or by any means for any purpose without express prior written consent from Electronics for Imaging, Inc. Information in this document is subject to change without notice and does not represent a commitment on the part of Electronics for Imaging, Inc. Patents This product may be covered by one or more of the following U.S. Patents: 4,716,978, 4,828,056, 4,917,488, 4,941,038, 5,109,241, 5,170,182, 5,212,546, 5,260,878, 5,276,490, 5,278,599, 5,335,040, 5,343,311, 5,398,107, 5,424,754, 5,442,429, 5,459,560, 5,467,446, 5,506,946, 5,517,334, 5,537,516, 5,543,940, 5,553,200, 5,563,689, 5,565,960, 5,583,623, 5,596,416, 5,615,314, 5,619,624, 5,625,712, 5,640,228, 5,666,436, 5,745,657, 5,760,913, 5,799,232, 5,818,645, 5,835,788, 5,859,711, 5,867,179, 5,940,186, 5,959,867, 5,970,174, 5,982,937, 5,995,724, 6,002,795, 6,025,922, 6,035,103, 6,041,200, 6,065,041, 6,112,665, 6,116,707, 6,122,407, 6,134,018, 6,141,120, 6,166,821, 6,173,286, 6,185,335, 6,201,614, 6,215,562, 6,219,155, 6,219,659, 6,222,641, 6,224,048, 6,225,974, 6,226,419, 6,238,105, 6,239,895, 6,256,108, 6,269,190, 6,271,937, -

Customizing and Extending IBM Content Navigator
Front cover Customizing and Extending IBM Content Navigator Understand extension points and customization options Create an action, service, feature, and custom step processor Use widgets in apps, mobile development, and more Wei-Dong Zhu Brett Morris Tomas Barina Rainer Mueller-Maechler Yi Duan Ron Rathgeber Nicole Hughes Jana Saalfeld Marcel Kostal Jian Xin Zhang Chad Lou Jie Zhang ibm.com/redbooks International Technical Support Organization Customizing and Extending IBM Content Navigator May 2014 SG24-8055-01 Note: Before using this information and the product it supports, read the information in “Notices” on page xi. Second Edition (May 2014) This edition applies to Version 2, Release 0, Modification 0 of IBM Content Navigator found in IBM FileNet Content Manager (product number 5724-R81), IBM Content Manager (product number 5724-B19), and IBM Content Manager OnDemand (product number 5724-J33). © Copyright International Business Machines Corporation 2012, 2014. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . xi Trademarks . xii Preface . xiii Authors . xiv Now you can become a published author, too! . xvii Comments welcome. xvii Stay connected to IBM Redbooks . xviii Summary of changes . xix May 2014, Second Edition . xix Part 1. Introduction . 1 Chapter 1. Extension points and customization options . 3 1.1 Before you begin . 4 1.1.1 IBM Content Navigator terms . 4 1.2 Development options with IBM Content Navigator . 6 1.2.1 Configuring IBM Content Navigator . 6 1.2.2 Implementing the EDS interface . 7 1.2.3 Implementing a plug-in . -

The Journey of Visual Studio Code
The Journey of Visual Studio Code Erich Gamma Envision new paradigms for online developer tooling that will be as successful as the IDE has been for the desktop 2012 2011 Eat your own dogfood hp 2011 2012 2012 2013 Meanwhile Microso; Changes Run on Windows Run everywhere Edit in Visual Studio Use your favorite editor Black box compilers Open Language Service APIs Proprietary Open Source Hacker News: Microso “Hit List” h@ps://hn.algolia.com/?query=MicrosoH Pivot or Persevere? Visual Studio A tool that combines the simplicity of a code editor withCode what developers need for the core code-build-debug-commit cycle editor IDE lightweight/fast project systems keyboard centered code understanding file/folders debug many languages integrated build many workflows File>New, wizards designers lightweight/fast ALM integraon file/folders with project conteXt plaorm tools many languages ... keyboard centered code understanding debug task running Inside Visual Studio Code – OSS in AcGon Electron, Node TypeScript Monaco Editor It’s fun to program in JavaScript Compensating patterns for classes, modules and namespaces. Refactoring JavaScript code is difficult! Code becomes read only Defining and documentation of APIs is difficult. Type information in comments are not checked TypeScript OpVonal stac types – be@er tooling: IntelliSense, Refactoring Be@er APIs docs More safety delete this.markers[range.statMarkerId]; // startMarkerId Use features from the future (ES6, ES7) today Growing the Code VS Code Preview – April 2015 Extensions Eclipse Everything is… -

WA2775 Introduction to Angular 7 Programming
WA2775 Introduction to Angular 7 Programming Classroom Setup Guide Web Age Solutions Inc. 1 Table of Contents Part 1 - Minimum Hardware Requirements....................................................................3 Part 2 - Minimum Software Requirements ....................................................................3 Part 3 - Software Provided..............................................................................................3 Part 4 - Instructions.........................................................................................................4 Part 5 - Installing Node.js 10.13.0...................................................................................4 Part 6 - Installing Visual Studio Code.............................................................................6 Part 7 - Summary..........................................................................................................13 2 Part 1 - Minimum Hardware Requirements ● Dual Core CPU or better 64 bits ● 4GB RAM minimum ● 20 GB in the hard disk ● Internet connection Part 2 - Minimum Software Requirements ● Windows OS: Windows 7 / 10, Windows Server 2012. ● Latest Google Chrome browser ● Latest Visual Studio Code ● Nodejs * * - indicates software provided as part of the courseware. Part 3 - Software Provided List of ZIP files required for this course and used in next steps on this document: WA2775_REL_1_0.zip Send an email to [email protected] in order to obtain a copy of the software for this course if you haven't receive it yet. -

The Effect of Ajax on Performance and Usability in Web Environments
The effect of Ajax on performance and usability in web environments Y.D.C.N. op ’t Roodt, BICT Date of acceptance: August 31st, 2006 One Year Master Course Software Engineering Thesis Supervisor: Dr. Jurgen Vinju Internship Supervisor: Ir. Koen Kam Company or Institute: Hyves (Startphone Limited) Availability: public domain Universiteit van Amsterdam, Hogeschool van Amsterdam, Vrije Universiteit 2 This page intentionally left blank 3 Table of contents 1 Foreword ................................................................................................... 6 2 Motivation ................................................................................................. 7 2.1 Tasks and sources................................................................................ 7 2.2 Research question ............................................................................... 9 3 Research method ..................................................................................... 10 3.1 On implementation........................................................................... 11 4 Background and context of Ajax .............................................................. 12 4.1 Background....................................................................................... 12 4.2 Rich Internet Applications ................................................................ 12 4.3 JavaScript.......................................................................................... 13 4.4 The XMLHttpRequest object.......................................................... -
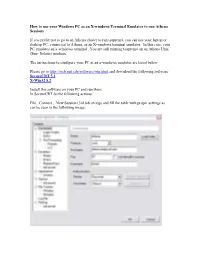
How to Use Your Windows PC As an X-Windows Terminal Emulator to Run Athena Sessions
How to use your Windows PC as an X-windows Terminal Emulator to run Athena Sessions If you prefer not to go to an Athena cluster to run tsuprem4, you can use your laptop or desktop PC, connected to Athena, as an X-windows terminal emulator. In this case, your PC emulates an x-windows terminal. You are still running tsuprem4 on an Athena Unix (Sun- Solaris) machine. The instructions to configure your PC as an x-windows emulator are listed below: Please go to http://web.mit.edu/software/win.html and download the following software: SecureCRT 5.1 X-Win32 8.2 Install this software on your PC and run them. In SecureCRT do the following actions: File...Connect....New Session (3rd tab on top) and fill the table with proper settings as can be seen in the following image: Fill the username field with your Kerberos username and press OK to run and insert your password. Run Xwin32 or Exceed if you have it (Exceed is not available on the MIT website but is available for purchase). In order to see images when running tsuprem4, you need to adjust the DISPLAY system variable according to your IP address. A simple way of getting your IP address, is typing the "setenv" command in SecureCRT screen. You will see something similar to this (with different numbers/characters): USER=pouya LOGNAME=pouya HOME=/afs/athena.mit.edu/user/p/o/pouya PATH=/srvd/patch:/usr/athena/bin:/usr/athena/etc:/bin/athena:/usr/openwin/bin:/usr/open win/demo:/usr/dt/bin:/usr/bin:/usr/ccs/bin:/usr/sbin:/sbin:/usr/sfw/bin:/usr/ucb:.:/mit/avant i/arch/sun4x_510/bin:/mit/matlab/arch/sun4x_510/bin:/mit/maple/arch/sun4x_59/bin MAIL=/var/mail//pouya SHELL=/bin/athena/tcsh TZ=US/Eastern SSH_CLIENT=18.62.30.76 2304 22 SSH_CONNECTION=18.62.30.76 2304 18.7.18.74 22 SSH_TTY=/dev/pts/59 ..... -

The Lift Approach
Science of Computer Programming 102 (2015) 1–19 Contents lists available at ScienceDirect Science of Computer Programming www.elsevier.com/locate/scico Analyzing best practices on Web development frameworks: The lift approach ∗ María del Pilar Salas-Zárate a, Giner Alor-Hernández b, , Rafael Valencia-García a, Lisbeth Rodríguez-Mazahua b, Alejandro Rodríguez-González c,e, José Luis López Cuadrado d a Departamento de Informática y Sistemas, Universidad de Murcia, Campus de Espinardo, 30100 Murcia, Spain b Division of Research and Postgraduate Studies, Instituto Tecnológico de Orizaba, Mexico c Bioinformatics at Centre for Plant Biotechnology and Genomics, Polytechnic University of Madrid, Spain d Computer Science Department, Universidad Carlos III de Madrid, Spain e Department of Engineering, School of Engineering, Universidad Internacional de La Rioja, Spain a r t i c l e i n f oa b s t r a c t Article history: Choosing the Web framework that best fits the requirements is not an easy task for Received 1 October 2013 developers. Several frameworks now exist to develop Web applications, such as Struts, Received in revised form 18 December 2014 JSF, Ruby on Rails, Grails, CakePHP, Django, and Catalyst. However, Lift is a relatively new Accepted 19 December 2014 framework that emerged in 2007 for the Scala programming language and which promises Available online 5 January 2015 a great number of advantages and additional features. Companies such as Siemens© and Keywords: IBM®, as well as social networks such as Twitter® and Foursquare®, have now begun to Best practices develop their applications by using Scala and Lift. Best practices are activities, technical Lift or important issues identified by users in a specific context, and which have rendered Scala excellent service and are expected to achieve similar results in similar situations. -

PATHWORKS for DOS Microsoft Windows Support Guide
PATHWORKS for DOS ' Microsoft Windows Support Guide PATHWORKS for DOS Microsoft Windows Support Guide Order Number: AA-MF87D-TH August 1991 Revision/Update Information: This document supersedes Microsoft Windows Support Guide, order number AA-MF87C-TH. Software Version: PATHWORKS for DOS Version 4.1 Digital Equipment Corporation Maynard, Massachusetts First Published, October 1988 Revised, April 1989, July 1990, October 1990, January 1991, August 1991 The infonnation in this document is subject to change without notice and should not be construed as a commitment by Digital Equipment Corporation. Digital Equipment Corporation assumes no responsibility for any errors that may appear in this document. The software described in this document is furnished under a license and may be used or copied only in accordance with the terms of such license. No responsibility is assumed for the use or reliability of software on equipment that is not supplied by Digital Equipment Corporation or its affiliated companies. Restricted Rights: Use, duplication, or disclosure by the U.S. Government is subject to restrictions as set forth in subparagraph (c)(l)(ii) of the Rights in Technical Data and Computer Software clause at DFARS 252.227-7013. © Digital Equipment Corporation 1988, 1989, 1990, 1991. All Rights Reserved. Printed in U.S.A. The postpaid Reader's Comments fonn at the end of this document requests your critical evaluation to assist in preparing future documentation. The following are trademarks of Digital Equipment Corporation: ALL-IN-I, DDCMP, DDIF, DEC, DECconnect, DEClaser, DE Cmate , DECnet, DECnet-DOS, DECpc, DECrouter, DECSA, DE C server, DECstation, DECwindows, DECwrite, DELNI, DEMPR, DEPCA, DESTA, Digital, DNA, EtherWORKS, LA50, LA75 Companion, LAT, LN03, LN03 PLUS, LN03 ScriptPrinter, METROWAVE, MicroVAX, PATHWORKS, PrintServer, ReGIS, RMS-ll, RSX, RSX-ll, RT, RT-ll, RX33, ThinWire, TK, ULTRIX, VAX, VAX Notes, VAXcluster, VAXmate, VAXmail, VAXserver, VAXshare, VMS, VT, WPS, WPS.PLUS, and the DIGITAL logo. -

OLIVIERI DINO RESUME>
RESUME> OLIVIERI DINO >1984/BOOT HTTP://WWW.ONYRIX.COM /MATH/C64/ /ASM.6510/BASIC/ /INTEL/ASM.8086/ /C/M24/BIOS/ >1990/PASCAL/C++/ADA/ /F.S.M/FORTRAN/ /ASM.80286/LISP/ /SCHEME/ /SIMULA/PROLOG/ /80386/68000/ /MIDI/DELUXEPAINT/ /AMIGA/ATARI.ST/ /WEB/MOSAIC/ /ARCHIE/FTP/MAC.0S9/HTTP/ /JAVA/TCP.IP/CODEWARRIOR/ /HTML/PENTIUM.3/3DMAX/ /NETSCAPE/CSS/ >2000/ASP/IIS/PHP/ /ORACLE/VB6/ /VC++/ONYRIX.COM/FLASHMX/ /MYSQL/AS2/.NET/JSP/C#/ /PL.SQL/JAVASCRIPT/ /LINUX/EJB/MOZILLA/ /PHOTOSHOP/EARENDIL.IT/ /SQL.SERVER/HTTP/ /MAC.OSX/T.SQL/ /UBUNTU/WINXP/ /ADOBE.CS/FLEX/ZEND/AS3/ /ZENTAO.ORG/PERL/ /C#/ECMASCRIPT/ >2010/POSTGRESQL/LINQ/ /AFTERFX/MAYA/ /JQUERY/EXTJS/ /SILVERLIGHT/ /VB.NET/FLASHBUILDER/ /UMAMU.ORG/PYTHON/ /CSS3/LESS/SASS/XCODE/ /BLENDER3D/HTML5/ /NODE.JS/QT/WEBGL/ /ANDROID/ /WINDOWS7/BOOTSTRAP/ /IOS/WINPHONE/MUSTACHE/ /HANDLEBARS/XDK/ /LOADRUNNER/IIB/WEBRTC/ /ARTFLOW/LOGIC.PRO.X/ /DAVINCI.RESOLVE/ /UNITY3D/WINDOWS 10/ /ELECTRON.ATOM/XAMARIN/ /SOCIAL.BOTS/CHROME.EXT/ /AGILE/REACT.NATIVE/ >INSERT COIN >READY PLAYER 1 UPDATED TO JULY 2018 DINO OLIVIERI BORN IN 1969, TURIN, Italy. DEBUT I started PROGRAMMING WITH MY FIRST computer, A C64, SELF LEARNING basic AND machine code 6510 at age OF 14. I STARTED STUDYING computer science at HIGH school. I’VE GOT A DEGREE IN computer science WITHOUT RENOUNCING TO HAVE MANY DIFFERENT work experiences: > videogame DESIGNER & CODER > computer course’S TRAINER > PROGRAMMER > technological consultant > STUDIO SOUND ENGINEER > HARDWARE INSTALLER AIMS AND PASSIONS I’M A MESS OF passions, experiences, IDEAS AND PROFESSIONS. I’M AN husband, A father AND, DESPITE MY age, I LIKE PLAYING LIKE A child WITH MY children. -

Using Visual Studio Code for Embedded Linux Development
Embedded Linux Conference Europe 2020 Using Visual Studio Code for Embedded Linux Development Michael Opdenacker [email protected] © Copyright 2004-2020, Bootlin. embedded Linux and kernel engineering Creative Commons BY-SA 3.0 license. Corrections, suggestions, contributions and translations are welcome! - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 1/24 Michael Opdenacker I Founder and Embedded Linux engineer at Bootlin: I Embedded Linux engineering company I Specialized in low level development: kernel and bootloader, embedded Linux build systems, boot time reduction, secure booting, graphics layers... I Contributing to the community as much as possible (code, experience sharing, free training materials) I Current maintainer of the Elixir Cross Referencer indexing the source code of Linux, U-Boot, BusyBox... (https://elixir.bootlin.com) I Interested in discovering new tools and sharing the experience with the community. I So far, only used Microsoft tools with the purpose of replacing them! - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 2/24 Using Visual Studio Code for Embedded Linux Development In the Stack Overflow 2019 Developer Survey, Visual Studio Code was ranked the most popular developer environment tool, with 50.7% of 87,317 respondents claiming to use it (Wikipedia) - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 3/24 Disclaimer and goals I I’m not a Visual Studio Code guru! I After hearing about VS Code from many Bootlin customers, I wanted to do my own research on it and share it with you. I The main focus of this research is to find out to what extent VS Code can help with embedded Linux development, and how it compares to the Elixir Cross Referencer in terms of code browsing. -

Azure Integration Services Announcements from Ignite 2020
Melb.NET Azure Integration Services Announcements from Ignite 2020 Bill Chesnut Cloud Platform & API Evangelist, SixPivot Azure MVP [email protected] @biztalkbill Agenda General Azure Logic Apps API Management Azure Functions BizTalk Server General • Azure Availability Zones now in Australia East • App Service introduces the new Pv3 SKU for Windows and Linux customers • App Service announces the general availability of Windows Container support • App Service Environment v3 in development--will launch November 1 • Azure Communication Services now available in public preview (US for now) Azure Logic Apps Logic Apps will now run on a new containerized runtime, the same runtime powering Azure Functions, providing hosting flexibility to: • Run on Functions, App Service, Kubernetes, Docker and any cloud. • Deploy multiple workflows to a single Logic App simplifying automated deployments and CI/CD pipelines. • Enable enterprise features such as private endpoints, simpler and more cost effective VNET access, deployment slots and more. • New VS Code Extension • Local Development • Improved Functions integration https://techcommunity.microsoft.com/t5/azure-developer-community-blog/new-logic-apps-runtime-performance-and-developer- improvements/ba-p/1645335 Azure Logic Apps (2) • Better CI/CD with VS Code. • New Designer (more on the screen, easier to understand) • Performance with Stateless • Automation Tasks (Logic Apps without building them) https://techcommunity.microsoft.com/t5/azure-developer-community-blog/new-logic-apps-runtime-performance-and-developer- improvements/ba-p/1645335 Azure API Management Debug API Management Policies in real time • Developer Tier Only • VS Code • Set breakpoints https://marketplace.visualstudio.com/items?itemName=ms-azuretools.vscode-apimanagement Support for Dapr applications in API Management • Using three new policies you can perform service invocations, dispatch messages to pub/sub topics, and send messages to external systems from a Dapr- enlightened self-hosted gateway. -

Presentation Title up to a Maximum of Three Lines Font
The Script Bowl Featuring Groovy, JRuby, Jython and Scala Raghavan “Rags” N. Srinivas CTO, Technology Evangelism The Script Bowl: Groovy Style Guillaume Laforge VP Technology at G2One, Inc. Groovy Project Manager http://www.g2one.com Guillaume Laforge Groovy Project Manager • Co-author of the Groovy in Action best-seller Manning • JSR-241 Spec Lead, • VP Technology at G2One, Inc. standardizing the Groovy • Professional services around dynamic language in the JCP Groovy and Grails • http://www.g2one.com • Initiator of the Grails web application framework 2008 JavaOneSM Conference | java.sun.com/javaone | 3 Groovy is… An Open Source dynamic language for the Virtual Machine for the Java™ platform (Java Virtual Machine or JVM™ machine) No impedence mismatch with Java™ programming environment • Groovy uses a syntax much like Java programming language • Shares the same object / threading / security model as Java programming language • Uses the same APIs (regex, collections, strings…) • Compiles down to normal Java programming language bytecode Provides native syntax constructs • Lists, maps, regex, ranges Supports closures • Simpler than any proposals for Java programming language! Groovy simplifies the use of many Java programming language APIs • XML, Swing, JDBC™ API, unit testing & mocking, templating … 2008 JavaOneSM Conference | java.sun.com/javaone | 4 The Script Bowl: JRuby Charles Nutter Technical Lead, JRuby JRuby Co-Lead Charles Oliver Nutter Longtime developer of Java application environment (11+ yrs ) Engineer at Sun Microsystems