A Hidden Markov Model for Investigating Recent Positive Selection Through Haplotype Structure
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Wo 2010/075007 A2
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date 1 July 2010 (01.07.2010) WO 2010/075007 A2 (51) International Patent Classification: (81) Designated States (unless otherwise indicated, for every C12Q 1/68 (2006.01) G06F 19/00 (2006.01) kind of national protection available): AE, AG, AL, AM, C12N 15/12 (2006.01) AO, AT, AU, AZ, BA, BB, BG, BH, BR, BW, BY, BZ, CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, DO, (21) International Application Number: DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, PCT/US2009/067757 HN, HR, HU, ID, IL, IN, IS, JP, KE, KG, KM, KN, KP, (22) International Filing Date: KR, KZ, LA, LC, LK, LR, LS, LT, LU, LY, MA, MD, 11 December 2009 ( 11.12.2009) ME, MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, NO, NZ, OM, PE, PG, PH, PL, PT, RO, RS, RU, SC, SD, (25) Filing Language: English SE, SG, SK, SL, SM, ST, SV, SY, TJ, TM, TN, TR, TT, (26) Publication Language: English TZ, UA, UG, US, UZ, VC, VN, ZA, ZM, ZW. (30) Priority Data: (84) Designated States (unless otherwise indicated, for every 12/3 16,877 16 December 2008 (16.12.2008) US kind of regional protection available): ARIPO (BW, GH, GM, KE, LS, MW, MZ, NA, SD, SL, SZ, TZ, UG, ZM, (71) Applicant (for all designated States except US): DODDS, ZW), Eurasian (AM, AZ, BY, KG, KZ, MD, RU, TJ, W., Jean [US/US]; 938 Stanford Street, Santa Monica, TM), European (AT, BE, BG, CH, CY, CZ, DE, DK, EE, CA 90403 (US). -

Dimerization of Ltβr by Ltα1β2 Is Necessary and Sufficient for Signal
Dimerization of LTβRbyLTα1β2 is necessary and sufficient for signal transduction Jawahar Sudhamsua,1, JianPing Yina,1, Eugene Y. Chiangb, Melissa A. Starovasnika, Jane L. Groganb,2, and Sarah G. Hymowitza,2 Departments of aStructural Biology and bImmunology, Genentech, Inc., South San Francisco, CA 94080 Edited by K. Christopher Garcia, Stanford University, Stanford, CA, and approved October 24, 2013 (received for review June 6, 2013) Homotrimeric TNF superfamily ligands signal by inducing trimers survival in a xenogeneic human T-cell–dependent mouse model of of their cognate receptors. As a biologically active heterotrimer, graft-versus-host disease (GVHD) (11). Lymphotoxin(LT)α1β2 is unique in the TNF superfamily. How the TNFRSF members are typically activated by TNFSF-induced three unique potential receptor-binding interfaces in LTα1β2 trig- trimerization or higher order oligomerization, resulting in initiation ger signaling via LTβ Receptor (LTβR) resulting in lymphoid organ- of intracellular signaling processes including the canonical and ogenesis and propagation of inflammatory signals is poorly noncanonical NF-κB pathways (2, 3). Ligand–receptor interactions α β understood. Here we show that LT 1 2 possesses two binding induce higher order assemblies formed between adaptor motifs in sites for LTβR with distinct affinities and that dimerization of LTβR the cytoplasmic regions of the receptors such as death domains or α β fi by LT 1 2 is necessary and suf cient for signal transduction. The TRAF-binding motifs and downstream signaling components such α β β crystal structure of a complex formed by LT 1 2,LT R, and the fab as Fas-associated protein with death domain (FADD), TNFR1- fragment of an antibody that blocks LTβR activation reveals the associated protein with death domain (TRADD), and TNFR-as- lower affinity receptor-binding site. -

OSCAR Is a Receptor for Surfactant Protein D That Activates TNF- Α Release from Human CCR2 + Inflammatory Monocytes
OSCAR Is a Receptor for Surfactant Protein D That Activates TNF- α Release from Human CCR2 + Inflammatory Monocytes This information is current as Alexander D. Barrow, Yaseelan Palarasah, Mattia Bugatti, of September 25, 2021. Alex S. Holehouse, Derek E. Byers, Michael J. Holtzman, William Vermi, Karsten Skjødt, Erika Crouch and Marco Colonna J Immunol 2015; 194:3317-3326; Prepublished online 25 February 2015; Downloaded from doi: 10.4049/jimmunol.1402289 http://www.jimmunol.org/content/194/7/3317 Supplementary http://www.jimmunol.org/content/suppl/2015/02/24/jimmunol.140228 http://www.jimmunol.org/ Material 9.DCSupplemental References This article cites 40 articles, 10 of which you can access for free at: http://www.jimmunol.org/content/194/7/3317.full#ref-list-1 Why The JI? Submit online. by guest on September 25, 2021 • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2015 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology OSCAR Is a Receptor for Surfactant Protein D That Activates TNF-a Release from Human CCR2+ Inflammatory Monocytes Alexander D. -

Androgen Receptor Binding Sites Identified by a GREF GATA Model
doi:10.1016/j.jmb.2005.09.009 J. Mol. Biol. (2005) 353, 763–771 COMMUNICATION Androgen Receptor Binding Sites Identified by a GREF_GATA Model Katsuaki Masuda1, Thomas Werner2, Shilpi Maheshwari1 Matthias Frisch2, Soyon Oh1, Gyorgy Petrovics1, Klaus May2 Vasantha Srikantan1, Shiv Srivastava1 and Albert Dobi1* 1Center for Prostate Disease Changes in transcriptional regulation can be permissive for tumor Research, Department of progression by allowing for selective growth advantage of tumor cells. Surgery, Uniformed Services Tumor suppressors can effectively inhibit this process. The PMEPA1 gene, a University, Rockville, MD potent inhibitor of prostate cancer cell growth is an androgen-regulated 20852, USA gene. We addressed the question of whether or not androgen receptor can directly bind to specific PMEPA1 promoter upstream sequences. To test this 2Genomatix Software GmbH hypothesis we extended in silico prediction of androgen receptor binding D-80339 Munich, Germany sites by a modeling approach and verified the actual binding by in vivo chromatin immunoprecipitation assay. Promoter upstream sequences of highly androgen-inducible genes were examined from microarray data of prostate cancer cells for transcription factor binding sites (TFBSs). Results were analyzed to formulate a model for the description of specific androgen receptor binding site context in these sequences. In silico analysis and subsequent experimental verification of the selected sequences suggested that a model that combined a GREF and a GATA TFBS was sufficient for predicting a class of functional androgen receptor binding sites. The GREF matrix family represents androgen receptor, glucocorticoid receptor and progesterone receptor binding sites and the GATA matrix family represents GATA binding protein 1–6 binding sites. -

Eda-Activated Relb Recruits an SWI/SNF (BAF) Chromatin-Remodeling Complex and Initiates Gene Transcription in Skin Appendage Formation
Eda-activated RelB recruits an SWI/SNF (BAF) chromatin-remodeling complex and initiates gene transcription in skin appendage formation Jian Simaa,1,2, Zhijiang Yana,1, Yaohui Chena, Elin Lehrmanna, Yongqing Zhanga, Ramaiah Nagarajaa, Weidong Wanga, Zhong Wangb, and David Schlessingera,2 aLaboratory of Genetics and Genomics, National Institute on Aging/NIH-Intramural Research Program, Baltimore, MD 21224; and bDepartment of Cardiac Surgery, Cardiovascular Research Center, University of Michigan, Ann Arbor, MI 48109 Edited by Elaine Fuchs, The Rockefeller University, New York, NY, and approved June 28, 2018 (received for review January 23, 2018) Ectodysplasin A (Eda) signaling activates NF-κB during skin ap- during organ development induce distinct BAF complexes to pendage formation, but how Eda controls specific gene transcrip- modulate gene expression. tion remains unclear. Here, we find that Eda triggers the formation Here, we report that skin-specific Eda signaling triggers the for- of an NF-κB–associated SWI/SNF (BAF) complex in which p50/RelB re- mation of a large BAF-containing complex that includes a BAF cruits a linker protein, Tfg, that interacts with BAF45d in the BAF com- complex, an NF-κB dimer of p50/RelB, and a specific linker pro- plex. We further reveal that Tfg is initially induced by Eda-mediated tein, Tfg (TRK-fusion gene). Thus, Eda/NF-κB signaling operates RelB activation and then bridges RelB and BAF for subsequent gene through a BAF complex to regulate specific gene expression in regulation. The BAF component BAF250a is particularly up-regulated in organ development, which may exemplify a more general paradigm skin appendages, and epidermal knockout of BAF250a impairs skin for gene-specific regulation in many other systems. -

Genome-Wide Association Study of Multiplex Schizophrenia Pedigrees
Article Genome-Wide Association Study of Multiplex Schizophrenia Pedigrees Douglas F. Levinson, M.D. Anthony O’Neill, M.D. in the primary European-ancestry analyses). Association was tested for single SNPs and Jianxin Shi, Ph.D. George N. Papadimitriou, M.D. genetic pathways. Polygenic scores based Kai Wang, Ph.D. Dimitris Dikeos, M.D. on family study results were used to predict case-control status in the Schizophrenia Sang Oh, M.Sc. Wolfgang Maier, M.D. Psychiatric GWAS Consortium (PGC) data set, and consistency of direction of effect Brien Riley, Ph.D. Bernard Lerer, M.D. with the family study was determined for Ann E. Pulver, Ph.D. Dominique Campion, M.D., top SNPs in the PGC GWAS analysis. Within- family segregation was examined for Dieter B. Wildenauer, Ph.D. Ph.D. schizophrenia-associated rare CNVs. Claudine Laurent, M.D., Ph.D. David Cohen, M.D., Ph.D. Results: No genome-wide significant asso- Maurice Jay, M.D. ciations were observed for single SNPs or for Bryan J. Mowry, M.D., pathways. PGC case and control subjects F.R.A.N.Z.C.P. Ayman Fanous, M.D. had significantly different genome-wide Pablo V. Gejman, M.D. Peter Eichhammer, M.D. polygenic scores (computed by weighting their genotypes by log-odds ratios from the 2 Michael J. Owen, Ph.D., Jeremy M. Silverman, Ph.D. family study) (best p=10 17, explaining F.R.C.Psych. 0.4% of the variance). Family study and Nadine Norton, Ph.D. PGC analyses had consistent directions for Kenneth S. Kendler, M.D. -

Qt4vh1p2c4 Nosplash E372185
Copyright 2014 by Janine Micheli-Jazdzewski ii Dedication I would like to dedicate this thesis to Rock, who is not with us anymore, TR, General Jack D. Ripper, and Page. Thank you for sitting with me while I worked for countless hours over the years. iii Acknowledgements I would like to express my special appreciation and thanks to my advisor Dr. Deanna Kroetz, you have been a superb mentor for me. I would like to thank you for encouraging my research and for helping me to grow as a research scientist. Your advice on both research, as well as on my career have been priceless. I would also like to thank my committee members, Dr. Laura Bull, Dr. Steve Hamilton and Dr. John Witte for guiding my research and expanding my knowledge on statistics, genetics and clinical phenotypes. I also want to thank past and present members of my laboratory for their support and help over the years, especially Dr. Mike Baldwin, Dr. Sveta Markova, Dr. Ying Mei Liu and Dr. Leslie Chinn. Thanks are also due to my many collaborators that made this research possible including: Dr. Eric Jorgenson, Dr. David Bangsberg, Dr. Taisei Mushiroda, Dr. Michiaki Kubo, Dr. Yusuke Nakamura, Dr. Jeffrey Martin, Joel Mefford, Dr. Sarah Shutgarts, Dr. Sulggi Lee and Dr. Sook Wah Yee. A special thank you to the RIKEN Center for Genomic Medicine that generously performed the genome-wide genotyping for these projects. Thanks to Dr. Steve Chamow, Dr. Bill Werner, Dr. Montse Carrasco, and Dr. Teresa Chen who started me on the path to becoming a scientist. -

Development and Validation of a Protein-Based Risk Score for Cardiovascular Outcomes Among Patients with Stable Coronary Heart Disease
Supplementary Online Content Ganz P, Heidecker B, Hveem K, et al. Development and validation of a protein-based risk score for cardiovascular outcomes among patients with stable coronary heart disease. JAMA. doi: 10.1001/jama.2016.5951 eTable 1. List of 1130 Proteins Measured by Somalogic’s Modified Aptamer-Based Proteomic Assay eTable 2. Coefficients for Weibull Recalibration Model Applied to 9-Protein Model eFigure 1. Median Protein Levels in Derivation and Validation Cohort eTable 3. Coefficients for the Recalibration Model Applied to Refit Framingham eFigure 2. Calibration Plots for the Refit Framingham Model eTable 4. List of 200 Proteins Associated With the Risk of MI, Stroke, Heart Failure, and Death eFigure 3. Hazard Ratios of Lasso Selected Proteins for Primary End Point of MI, Stroke, Heart Failure, and Death eFigure 4. 9-Protein Prognostic Model Hazard Ratios Adjusted for Framingham Variables eFigure 5. 9-Protein Risk Scores by Event Type This supplementary material has been provided by the authors to give readers additional information about their work. Downloaded From: https://jamanetwork.com/ on 10/02/2021 Supplemental Material Table of Contents 1 Study Design and Data Processing ......................................................................................................... 3 2 Table of 1130 Proteins Measured .......................................................................................................... 4 3 Variable Selection and Statistical Modeling ........................................................................................ -

Effect of Tnfα Stimulation on Expression of Kidney Risk
www.nature.com/scientificreports OPEN Efect of TNFα stimulation on expression of kidney risk infammatory proteins in human umbilical vein endothelial cells cultured in hyperglycemia Zaipul I. Md Dom1,2, Caterina Pipino1,2,3, Bozena Krolewski1,2, Kristina O’Neil1, Eiichiro Satake1,2 & Andrzej S. Krolewski1,2,4* We recently identifed a kidney risk infammatory signature (KRIS), comprising 6 TNF receptors (including TNFR1 and TNFR2) and 11 infammatory proteins. Elevated levels of these proteins in circulation were strongly associated with risk of the development of end-stage kidney disease (ESKD) during 10-year follow-up. It has been hypothesized that elevated levels of these proteins in circulation might refect (be markers of) systemic exposure to TNFα. In this in vitro study, we examined intracellular and extracellular levels of these proteins in human umbilical vein endothelial cells (HUVECs) exposed to TNFα in the presence of hyperglycemia. KRIS proteins as well as 1300 other proteins were measured using the SOMAscan proteomics platform. Four KRIS proteins (including TNFR1) were down-regulated and only 1 protein (IL18R1) was up-regulated in the extracellular fraction of TNFα-stimulated HUVECs. In the intracellular fraction, one KRIS protein was down- regulated (CCL14) and 1 protein was up-regulated (IL18R1). The levels of other KRIS proteins were not afected by exposure to TNFα. HUVECs exposed to a hyperglycemic and infammatory environment also showed signifcant up-regulation of a distinct set of 53 proteins (mainly in extracellular fraction). In our previous study, circulating levels of these proteins were not associated with progression to ESKD in diabetes. Tumor necrosis factor alpha (TNFα) is a potent pro-infammatory cytokine that exerts its pleiotropic efects on a wide variety of cell types and plays a vital role in the pathogenesis of infammatory diseases 1,2. -

Supplementary Table 1
Supplementary Table 1. 492 genes are unique to 0 h post-heat timepoint. The name, p-value, fold change, location and family of each gene are indicated. Genes were filtered for an absolute value log2 ration 1.5 and a significance value of p ≤ 0.05. Symbol p-value Log Gene Name Location Family Ratio ABCA13 1.87E-02 3.292 ATP-binding cassette, sub-family unknown transporter A (ABC1), member 13 ABCB1 1.93E-02 −1.819 ATP-binding cassette, sub-family Plasma transporter B (MDR/TAP), member 1 Membrane ABCC3 2.83E-02 2.016 ATP-binding cassette, sub-family Plasma transporter C (CFTR/MRP), member 3 Membrane ABHD6 7.79E-03 −2.717 abhydrolase domain containing 6 Cytoplasm enzyme ACAT1 4.10E-02 3.009 acetyl-CoA acetyltransferase 1 Cytoplasm enzyme ACBD4 2.66E-03 1.722 acyl-CoA binding domain unknown other containing 4 ACSL5 1.86E-02 −2.876 acyl-CoA synthetase long-chain Cytoplasm enzyme family member 5 ADAM23 3.33E-02 −3.008 ADAM metallopeptidase domain Plasma peptidase 23 Membrane ADAM29 5.58E-03 3.463 ADAM metallopeptidase domain Plasma peptidase 29 Membrane ADAMTS17 2.67E-04 3.051 ADAM metallopeptidase with Extracellular other thrombospondin type 1 motif, 17 Space ADCYAP1R1 1.20E-02 1.848 adenylate cyclase activating Plasma G-protein polypeptide 1 (pituitary) receptor Membrane coupled type I receptor ADH6 (includes 4.02E-02 −1.845 alcohol dehydrogenase 6 (class Cytoplasm enzyme EG:130) V) AHSA2 1.54E-04 −1.6 AHA1, activator of heat shock unknown other 90kDa protein ATPase homolog 2 (yeast) AK5 3.32E-02 1.658 adenylate kinase 5 Cytoplasm kinase AK7 -

WO 2019/068007 Al Figure 2
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization I International Bureau (10) International Publication Number (43) International Publication Date WO 2019/068007 Al 04 April 2019 (04.04.2019) W 1P O PCT (51) International Patent Classification: (72) Inventors; and C12N 15/10 (2006.01) C07K 16/28 (2006.01) (71) Applicants: GROSS, Gideon [EVIL]; IE-1-5 Address C12N 5/10 (2006.0 1) C12Q 1/6809 (20 18.0 1) M.P. Korazim, 1292200 Moshav Almagor (IL). GIBSON, C07K 14/705 (2006.01) A61P 35/00 (2006.01) Will [US/US]; c/o ImmPACT-Bio Ltd., 2 Ilian Ramon St., C07K 14/725 (2006.01) P.O. Box 4044, 7403635 Ness Ziona (TL). DAHARY, Dvir [EilL]; c/o ImmPACT-Bio Ltd., 2 Ilian Ramon St., P.O. (21) International Application Number: Box 4044, 7403635 Ness Ziona (IL). BEIMAN, Merav PCT/US2018/053583 [EilL]; c/o ImmPACT-Bio Ltd., 2 Ilian Ramon St., P.O. (22) International Filing Date: Box 4044, 7403635 Ness Ziona (E.). 28 September 2018 (28.09.2018) (74) Agent: MACDOUGALL, Christina, A. et al; Morgan, (25) Filing Language: English Lewis & Bockius LLP, One Market, Spear Tower, SanFran- cisco, CA 94105 (US). (26) Publication Language: English (81) Designated States (unless otherwise indicated, for every (30) Priority Data: kind of national protection available): AE, AG, AL, AM, 62/564,454 28 September 2017 (28.09.2017) US AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, BZ, 62/649,429 28 March 2018 (28.03.2018) US CA, CH, CL, CN, CO, CR, CU, CZ, DE, DJ, DK, DM, DO, (71) Applicant: IMMP ACT-BIO LTD. -
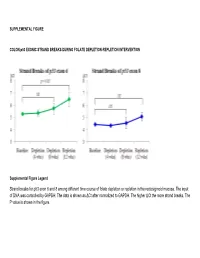
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA.