Konstruktion Einer Software-Architektur Für Operatives Reporting Am Beispiel Eines Prozessleitsystems Der BMW AG
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IBM Cognos Analytics - Reporting Version 11.1
IBM Cognos Analytics - Reporting Version 11.1 User Guide IBM © Product Information This document applies to IBM Cognos Analytics version 11.1.0 and may also apply to subsequent releases. Copyright Licensed Materials - Property of IBM © Copyright IBM Corp. 2005, 2021. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. IBM, the IBM logo and ibm.com are trademarks or registered trademarks of International Business Machines Corp., registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the Web at " Copyright and trademark information " at www.ibm.com/legal/copytrade.shtml. The following terms are trademarks or registered trademarks of other companies: • Adobe, the Adobe logo, PostScript, and the PostScript logo are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States, and/or other countries. • Microsoft, Windows, Windows NT, and the Windows logo are trademarks of Microsoft Corporation in the United States, other countries, or both. • Intel, Intel logo, Intel Inside, Intel Inside logo, Intel Centrino, Intel Centrino logo, Celeron, Intel Xeon, Intel SpeedStep, Itanium, and Pentium are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. • Linux is a registered trademark of Linus Torvalds in the United States, other countries, or both. • UNIX is a registered trademark of The Open Group in the United States and other countries. • Java and all Java-based trademarks and logos are trademarks or registered trademarks of Oracle and/or its affiliates. -

IBM Cognos Business Intelligence Versión 10.2.0
IBM Cognos Business Intelligence Versión 10.2.0 Planificación de una migración de IBM Cognos Series 7 a IBM Cognos BI Nota Antes de utilizar esta información y el producto al que da soporte, lea la información del apartado “Avisos” en la página 95. Información del producto Este manual es la traducción del original en inglés IBM Cognos Business Intelligence Version 10.2.0 Planning a Migration from IBM Cognos Series 7 to IBM Cognos BI. Este documento se aplica a IBM Cognos Business Intelligence Versión 10.2.0 y puede aplicarse también a las versiones posteriores. Para comprobar si hay versiones más recientes de este documento, visite los Information Center de IBM Cognos (http://publib.boulder.ibm.com/infocenter/cogic/v1r0m0/index.jsp). Material con licencia - Propiedad de IBM © Copyright IBM Corporation 2005, 2012. Contenido Introducción .................................vii Capítulo 1. Preguntas frecuentes .........................1 ¿Qué es diferente en IBM Cognos Business Intelligence 10.2? ...................1 ¿Como puedo garantizar una migración satisfactoria? .....................1 ¿Hay algún servicio o partner de IBM Cognos disponible que pueda ayudarme? ............3 ¿Debo migrar los datos de todas las aplicaciones de IBM Cognos Series 7 a IBM Cognos BI? ........4 ¿A parte de las herramientas de migración, necesito algo más para mover mis aplicaciones clave? .......5 ¿Cuándo debo realizar la migración? ...........................6 ¿Cuánto tiempo se necesita para realizar la migración? .....................6 ¿Cuál es la diferencia entre Analysis Studio y PowerPlay Studio? ..................7 ¿Cuál es el futuro de IBM Cognos Series 7? .........................8 ¿Cuál es la diferencia entre migración y actualización? .....................8 ¿Pasar de IBM Cognos ReportNet a IBM Cognos BI es una migración? ...............10 Capítulo 2. -

Installation and Configuration
Installation and Configuration InFormTM ITM Release 4.6 SP3 Part number: DC-INF46-001-030 Copyright © 1998 - 2011, Oracle and/or its affiliates. All rights reserved. The Programs (which include both the software and documentation) contain proprietary information; they are provided under a license agreement containing restrictions on use and disclosure and are also protected by copyright, patent, and other intellectual and industrial property laws. Reverse engineering, disassembly, or decompilation of the Programs, except to the extent required to obtain interoperability with other independently created software or as specified by law, is prohibited. The information contained in this document is subject to change without notice. If you find any problems in the documentation, please report them to us in writing. This document is not warranted to be error-free. Except as may be expressly permitted in your license agreement for these Programs, no part of these Programs may be reproduced or transmitted in any form or by any means, electronic or mechanical, for any purpose. If the Programs are delivered to the United States Government or anyone licensing or using the Programs on behalf of the United States Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the Programs, including documentation and technical data, shall be subject to the licensing restrictions set forth in the applicable Oracle license agreement, and, to the extent applicable, the additional rights set forth in FAR 52.227-19, Commercial Computer Software -- Restricted Rights (June 1987). -

The FULL PROMISE of Business Intelligence
The FULL PROMISE of business intelligence COGNOS 8 BUSINESS SIMPLE, COMPLETE, INTELLIGENCE AND PROVEN. While every attempt has been made to ensure that the information in this document is accurate and complete, some typographical errors or technical inaccuracies may exist. Cognos does not accept responsibility for any kind of loss resulting from the use of information con- tained in this document. This page shows the publication date. The information contained in this document is subject to change without notice. This text contains proprietary information, which is protected by copyright. All rights are reserved. No part of this document may be photocopied, reproduced, stored in a retrieval system, transmitted in any form or by any means, or translated into another language without the prior written consent of Cognos Incorporated. The incorporation of the product attributes discussed in these materials into any release or upgrade of any Cognos software product – as well as the timing of any such release or upgrade – is at the sole discretion of Cognos. U.S. Government Restricted Rights. The accompanying materials are provided with Restricted Rights. Use, duplication for disclosure by the Government is subject to the restrictions in subparagraph (c)(1)(ii) of the Rights in Technical Data and Computer Software clause at DFARS 252.227-7013, or subparagraphs (c) (1) and (2) of the Commercial Computer Software – Restricted Rights at 48CFR52.227-19, as applicable. The Contractor is Cognos Corporation, 67 South Bedford Street, Burlington, MA 01803-5164. This edition published November 2006 Copyright © 1989-2006 Cognos Incorporated. Table of Contents One product for business intelligence . -

Application (764.0
NATIONAL ENTERPRISE ARCHITECTURE FRAMEWORK KINGDOM OF BAHRAIN Technology Standards and Guidelines Application Domain © Copyright. All rights reserved with eGovernment Authority (eGA) Kingdom of Bahrain. This document is the intellectual property of eGA. No part of this work may be reproduced in any form or by any means - electronic, graphic or mechanical - including photocopying, recording, taping, or storage in an information retrieval system, without prior written permission of eGA. DOCUMENT INFORMATION AND HISTORY Document Reference Number: ETS-APP-02.01 Title: Application Domain Document Type: Enterprise Technology Standards Category: Application Approver: ICT Governance Committee (ICTGC) Approval Date: 04/12/2013 Effective Date: 04/12/2013 Last Review Date: 02/12/2013 Next Review Date: As Required SPOC for Change: NEAF Chief Architect – Email ID: [email protected] Synopsis: Establishes technology standards and guidelines in Application Domain for Information Systems interoperability and information exchange Document History Version Date Author Remarks Number (dd/mm/yyyy) 1.0 06/12/2010 NEAF Team Baseline version 2.0 02/12/2013 NEAF Team Updated and incorporated review comments from ICTGC Review and Approval History Version Date Reviewer / Approver Remarks Number (dd/mm/yyyy) 2.0 04/12/2013 ICTGC Formal approval by ICTGC Technology Standards and Guidelines: Page 2 of 40 Application TABLE OF CONTENTS 1. Introduction .............................................................................................................................................................. -

Report Studio User Guide
COGNOS(R) 8 Business Intelligence REPORT STUDIO USER GUIDE Report Studio Tour Cognos(R) 8 Business Intelligence Readme Report Studio User Guide USER GUIDE THE NEXT LEVEL OF PERFORMANCETM Product Information This document applies to Cognos(R) 8 Version 8.1.2 MR2 and may also apply to subsequent releases. To check for newer versions of this document, visit the Cognos Global Customer Services Web site (http://support.cognos.com). Copyright Copyright (C) 2006 Cognos Incorporated. Portions of Cognos(R) software products are protected by one or more of the following U.S. Patents: 6,609,123 B1; 6,611,838 B1; 6,662,188 B1; 6,728,697 B2; 6,741,982 B2; 6,763,520 B1; 6,768,995 B2; 6,782,378 B2; 6,847,973 B2; 6,907,428 B2; 6,853,375 B2; 6,986,135 B2; 6,995,768 B2. Cognos and the Cognos logo are trademarks of Cognos Incorporated in the United States and/or other countries. All other names are trademarks or registered trademarks of their respective companies. While every attempt has been made to ensure that the information in this document is accurate and complete, some typographical errors or technical inaccuracies may exist. Cognos does not accept responsibility for any kind of loss resulting from the use of information contained in this document. This document shows the publication date. The information contained in this document is subject to change without notice. Any improvements or changes to either the product or the document will be documented in subsequent editions. U.S. Government Restricted Rights. -

Diplomarbeit
Die approbierte Originalversion dieser Diplom-/Masterarbeit ist an der Hauptbibliothek der Technischen Universität Wien aufgestellt (http://www.ub.tuwien.ac.at). The approved original version of this diploma or master thesis is available at the main library of the Vienna University of Technology (http://www.ub.tuwien.ac.at/englweb/). Diplomarbeit Alphanet - Clinical Trials Moving Towards Online Solutions ausgeführt an der Besonderen Einrichtung für Medizinische Statistik und Informatik, Institut für Medizinische Bildverarbeitung und Mustererkennung der Medizinischen Universität Wien unter der Leitung von Univ.-Prof. Dipl.-Ing. Dr. Ernst Schuster, Dipl.-Ing. Dr. Michael Prinz durch Eduard Gringinger Nicholas Trieb Matrikelnummer 0126915 Matrikelnummer 0009112 Aichhorngasse 5/2/20 Altgasse 27/5 1120 Wien 1130 Wien Wien, am 30. August 2007 Abstract This master’s thesis entails a description of a web application with a dynamic central database which allows the creation and management of clinical studies. Over a multi user system, users are able to individually create their own multi-centered clinical studies as well as combine different clinical studies for statistical analysis. With the latest technology (Ajax and JSF) it is possible to create data entry screens quickly, easily and without any programming. The unique graphical user interface, allows dragging and dropping elements for a high-speed design of electronic case report forms (eCRF). Through the dynamical structure of the database, there are no limitations to the creation of individual clinical studies. These fields can easily be created and managed by the different users. In order to facilitate a clearly laid-out clinical study, the user has the ability to create and integrate categories. -

Argus Insight 6.0 Cognos Installation Guide
Oracle® Argus Insight Cognos Installation Guide, Release 6.0 E18251-01 August 2010 Oracle Argus Insight Cognos Installation Guide, Release 6.0 E18251-01 Copyright © 2010, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this software or related documentation is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms set forth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). -

IBM Cognos Report Studio Version 10.2.2: User Guide Chapter 5
IBM Cognos Report Studio Version 10.2.2 User Guide Note Before using this information and the product it supports, read the information in “Notices” on page 1013. Product Information This document applies to IBM Cognos Business Intelligence Version 10.2.2 and may also apply to subsequent releases. Licensed Materials - Property of IBM © Copyright IBM Corporation 2005, 2015. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Introduction .................................xlix Chapter 1. What's New in Cognos Report Studio? .................1 New features in version 10.2.2 .............................1 IBM Cognos Active Report preview...........................1 IBM Cognos Active Report output ...........................1 IBM Cognos Active Report templates ..........................1 Reusable report styles ...............................2 Slider orientation in IBM Cognos Active Report ......................2 Tabbed reports in HTML output ............................2 Dynamically named worksheet tabs in Excel 2007 output ...................2 New maps in IBM Cognos BI.............................2 Report run format restrictions ............................2 Support for IBM Cognos Theme Designer ........................3 Improvements to the current default chart technology ....................3 Enhancements to extensible visualizations ........................3 New features in version 10.2.1.1 .............................4 Extensible visualizations in regular -

Open Security with IBM Cognos 8 BI
Solution Brief Open security with IBM Cognos 8 BI Sharing information securely Open security with IBM Cognos 8 BI Highlights Business intelligence (BI) is about Sending and storing unsecured sharing information, but good BI pays data exposes it to various risks. IBM equal attention to its converse: securing Cognos 8 Business Intelligence, the Open security solutions keep information tightly protected but information. Corporations need to strike first single, all-in-one, entirely Web- still accessible to authorized a balance between making information based BI software, addresses the users. both accessible to those who should security concerns of large and small IBM Cognos® 8 BI leverages have it, and protecting it from those organizations alike. It lets you leverage existing security infrastructure who shouldn’t. Of course, effective your existing security infrastructure and adds its own application security should not be at the expense of where it makes sense, and provides layer. efficient operations, nor should it cost simple, straightforward application Users can log into multiple a fortune to deploy and manage. How security and encryption. IBM Cognos 8 authentication namespaces but do you roll out an effectively-secured BI provides anonymous access rights, see only the data they’re allowed business intelligence infrastructure row and column data security, 168-bit to view. that leverages your existing security data transmission encryption, and Data access permissions can be investments? many other features that make it easy assigned by user, by group or by to balance ready access with ironclad role – all with a single click. Your security strategy concentrates on security. Advanced encryption protocols three main areas: protect data sent to/from the IBM Cognos 8 BI Web interface Transparent authentication • Authentication – who are your The first principle of security – users? Your information should be authentication – involves identifying readily accessible but only to the the user. -
Enterprise Architecture
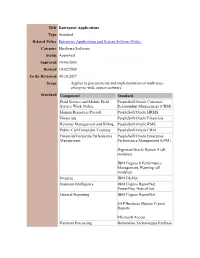
Title Enterprise Applications Type Standard Related Policy Enterprise Applications and System Software Policy Category Hardware/Software Status Approved Approved 10/06/2005 Revised 10/02/2008 To Be Reviewed 06/18/2017 Scope Applies to procurements and implementation of multi-user, enterprise-wide system software. Standard Component Standard Field Service and Mobile Field PeopleSoft/Oracle Customer Service Work Orders Relationship Management (CRM) Human Resources/Payroll PeopleSoft/Oracle HRMS Financials PeopleSoft/Oracle Financials Revenue Management and Billing PeopleSoft/Oracle RMS Public Call/Complaint Tracking PeopleSoft/Oracle CRM Financial/Corporate Performance PeopleSoft/Oracle Enterprise Management Performance Management (EPM) Hyperion/Oracle System 9 (all modules) IBM Cognos 8 Performance Management, Planning (all modules) Imaging IBM FileNet Business Intelligence IBM Cognos ReportNet, PowerPlay, NoticeCast General Reporting IBM Cognos ReportNet SAP/Business Objects Crystal Reports Microsoft Access Payment Processing Bottomline Technologies PayBase Bank of America (Web-based) Public Safety Policy/Standard Innovative Data Solutions Operating Procedure (SOP) PowerDMS Management Point of Sale/Ticketing Siriusware Salesware Rationale These standards are set forth to satisfy the requirements of conducting daily business in an efficient manner. Departments must recognize, specify, and justify the need for purchasing new applications. This standard enables the City to: 1. Facilitate the exchange and sharing of data electronically, by using the same programs (with related file formats) and platforms across the Metropolitan Area. 2. Achieve substantial savings in person-time support costs, over a period of time, by reducing the number of products that are supported 3. Reduce training costs by having the same application software in use throughout City Government. . -

Metadata Integration Vendor Panel Introduction & Welcome
Metadata Integration Vendor Panel Introduction & Welcome presented by Christian Bremeau Meta Integration, President, CEO Adaptive Geoff Sherwood Senior Consultant, Adaptive Repository ASG Scott McCurdy Vice President, Rochade Business Objects Awez Syed Director, Product Management CA Danny Sandwell Product Manager, ERwin Cognos Rachel Bland Product Manager, Metadata & Modeling Embarcadero Greg Keller Vice President, Product Management IBM Nathan Bobbin Product Manager, Metadata Services Informatica Marc Bourget Product Manager, Metadata Services MetaMatrix John Verhaeg Principal Software Engineer Microsoft Donald Farmer Group Program Manager, SQL Server BI NCR Teradata Steve Long Product Manager, Meta Data Services Oracle Joseph Zheng Director, Software Development, OWB SAS Liz McIntosh Metadata Integration Technologies Sybase Dave Dichmann Product Manager, PowerDesigner The 10th Annual Wilshire Meta-Data Conference Metadata Integration Vendor Panel –Page 1 Denver, Colorado and the 18th Annual DAMA International Symposium, Tuesday, April 25, 2006 10:30 am - 11:30 am &11:45 am - 12:45 pm 2006, April 23d, to 27th Metadata Flow & Life Cycle: the heart beat… Forward Metadata Flow The metadata movement between tools can: - preserve the model “as is” or include transformations Legacy (e.g. forward or reverse engineering from/to BI tools) Reverse Metadata Flow - create and a new model, or update an existing one Migration Multi-Vendor Development Tools Design & Modeling Business Intelligence (BI) OM - Object DM - Data Dimensional Report Modeling