Application of Data Fusion and Machine Learning to the Analysis of the Relevancy of Recommended Flight Reroutes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
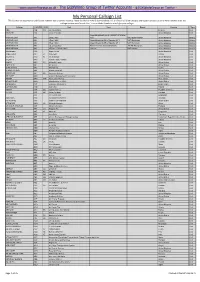
My Personal Callsign List This List Was Not Designed for Publication However Due to Several Requests I Have Decided to Make It Downloadable
- www.egxwinfogroup.co.uk - The EGXWinfo Group of Twitter Accounts - @EGXWinfoGroup on Twitter - My Personal Callsign List This list was not designed for publication however due to several requests I have decided to make it downloadable. It is a mixture of listed callsigns and logged callsigns so some have numbers after the callsign as they were heard. Use CTL+F in Adobe Reader to search for your callsign Callsign ICAO/PRI IATA Unit Type Based Country Type ABG AAB W9 Abelag Aviation Belgium Civil ARMYAIR AAC Army Air Corps United Kingdom Civil AgustaWestland Lynx AH.9A/AW159 Wildcat ARMYAIR 200# AAC 2Regt | AAC AH.1 AAC Middle Wallop United Kingdom Military ARMYAIR 300# AAC 3Regt | AAC AgustaWestland AH-64 Apache AH.1 RAF Wattisham United Kingdom Military ARMYAIR 400# AAC 4Regt | AAC AgustaWestland AH-64 Apache AH.1 RAF Wattisham United Kingdom Military ARMYAIR 500# AAC 5Regt AAC/RAF Britten-Norman Islander/Defender JHCFS Aldergrove United Kingdom Military ARMYAIR 600# AAC 657Sqn | JSFAW | AAC Various RAF Odiham United Kingdom Military Ambassador AAD Mann Air Ltd United Kingdom Civil AIGLE AZUR AAF ZI Aigle Azur France Civil ATLANTIC AAG KI Air Atlantique United Kingdom Civil ATLANTIC AAG Atlantic Flight Training United Kingdom Civil ALOHA AAH KH Aloha Air Cargo United States Civil BOREALIS AAI Air Aurora United States Civil ALFA SUDAN AAJ Alfa Airlines Sudan Civil ALASKA ISLAND AAK Alaska Island Air United States Civil AMERICAN AAL AA American Airlines United States Civil AM CORP AAM Aviation Management Corporation United States Civil -

Appendix 25 Box 31/3 Airline Codes
March 2021 APPENDIX 25 BOX 31/3 AIRLINE CODES The information in this document is provided as a guide only and is not professional advice, including legal advice. It should not be assumed that the guidance is comprehensive or that it provides a definitive answer in every case. Appendix 25 - SAD Box 31/3 Airline Codes March 2021 Airline code Code description 000 ANTONOV DESIGN BUREAU 001 AMERICAN AIRLINES 005 CONTINENTAL AIRLINES 006 DELTA AIR LINES 012 NORTHWEST AIRLINES 014 AIR CANADA 015 TRANS WORLD AIRLINES 016 UNITED AIRLINES 018 CANADIAN AIRLINES INT 020 LUFTHANSA 023 FEDERAL EXPRESS CORP. (CARGO) 027 ALASKA AIRLINES 029 LINEAS AER DEL CARIBE (CARGO) 034 MILLON AIR (CARGO) 037 USAIR 042 VARIG BRAZILIAN AIRLINES 043 DRAGONAIR 044 AEROLINEAS ARGENTINAS 045 LAN-CHILE 046 LAV LINEA AERO VENEZOLANA 047 TAP AIR PORTUGAL 048 CYPRUS AIRWAYS 049 CRUZEIRO DO SUL 050 OLYMPIC AIRWAYS 051 LLOYD AEREO BOLIVIANO 053 AER LINGUS 055 ALITALIA 056 CYPRUS TURKISH AIRLINES 057 AIR FRANCE 058 INDIAN AIRLINES 060 FLIGHT WEST AIRLINES 061 AIR SEYCHELLES 062 DAN-AIR SERVICES 063 AIR CALEDONIE INTERNATIONAL 064 CSA CZECHOSLOVAK AIRLINES 065 SAUDI ARABIAN 066 NORONTAIR 067 AIR MOOREA 068 LAM-LINHAS AEREAS MOCAMBIQUE Page 2 of 19 Appendix 25 - SAD Box 31/3 Airline Codes March 2021 Airline code Code description 069 LAPA 070 SYRIAN ARAB AIRLINES 071 ETHIOPIAN AIRLINES 072 GULF AIR 073 IRAQI AIRWAYS 074 KLM ROYAL DUTCH AIRLINES 075 IBERIA 076 MIDDLE EAST AIRLINES 077 EGYPTAIR 078 AERO CALIFORNIA 079 PHILIPPINE AIRLINES 080 LOT POLISH AIRLINES 081 QANTAS AIRWAYS -

August 2020 9/22/2020
JOHN GLENN COLUMBUS INTERNATIONAL AIRPORT Monthly Activity Report | August 2020 9/22/2020 PASSENGERS Total Passengers - Monthly Total Passengers - Year to Date Actual Percent Actual Percent Airline 2020 2019 2020 2019 Change Change Change Change Air Canada Express - 6,881 -6,881 -100.0% 9,500 49,873 -40,373 -81.0% Alaska 4,983 8,321 -3,338 -40.1% 32,191 48,081 -15,890 -33.0% American 54,615 178,793 -124,178 -69.5% 539,521 1,364,292 -824,771 -60.5% Delta 39,530 169,765 -130,235 -76.7% 414,257 1,219,149 -804,892 -66.0% Frontier 4,127 11,314 -7,187 -63.5% 31,578 79,074 -47,496 -60.1% Southwest 83,081 227,487 -144,406 -63.5% 828,263 1,891,271 -1,063,008 -56.2% Spirit 19,723 33,135 -13,412 -40.5% 161,028 308,445 -147,417 -47.8% United 25,420 100,227 -74,807 -74.6% 262,542 737,649 -475,107 -64.4% AIRLINES TOTALS 231,479 735,923 -504,444 -68.5% 2,278,880 5,697,834 -3,418,954 -60.0% CHARTER TOTALS 617 1,517 -900 -59.3% 9,291 28,997 -19,706 -68.0% AIRPORT TOTALS 232,096 737,440 -505,344 -68.5% 2,288,171 5,726,831 -3,438,660 -60.0% CARGO Total Cargo (Freight and Mail) - Monthly Total Cargo (Freight and Mail) - Year-To-Date Actual Percent Actual Percent Airline 2020 2019 2020 2019 Change Change Change Change Alaska 51,752 35,047 16,705 47.7% 115,122 173,379 -58,257 -33.6% American 34,506 145,812 -111,306 -76.3% 516,109 1,189,222 -673,113 -56.6% Delta 109,455 189,574 -80,119 -42.3% 854,336 1,356,604 -502,268 -37.0% Southwest 236,161 424,511 -188,350 -44.4% 2,386,755 3,157,189 -770,434 -24.4% United 11,804 101,862 -90,058 -88.4% 243,792 786,206 -542,414 -

Attachment F – Participants in the Agreement
Revenue Accounting Manual B16 ATTACHMENT F – PARTICIPANTS IN THE AGREEMENT 1. TABULATION OF PARTICIPANTS 0B 475 BLUE AIR AIRLINE MANAGEMENT SOLUTIONS S.R.L. 1A A79 AMADEUS IT GROUP SA 1B A76 SABRE ASIA PACIFIC PTE. LTD. 1G A73 Travelport International Operations Limited 1S A01 SABRE INC. 2D 54 EASTERN AIRLINES, LLC 2I 156 STAR UP S.A. 2I 681 21 AIR LLC 2J 226 AIR BURKINA 2K 547 AEROLINEAS GALAPAGOS S.A. AEROGAL 2T 212 TIMBIS AIR SERVICES 2V 554 AMTRAK 3B 383 Transportes Interilhas de Cabo Verde, Sociedade Unipessoal, SA 3E 122 MULTI-AERO, INC. DBA AIR CHOICE ONE 3J 535 Jubba Airways Limited 3K 375 JETSTAR ASIA AIRWAYS PTE LTD 3L 049 AIR ARABIA ABDU DHABI 3M 449 SILVER AIRWAYS CORP. 3S 875 CAIRE DBA AIR ANTILLES EXPRESS 3U 876 SICHUAN AIRLINES CO. LTD. 3V 756 TNT AIRWAYS S.A. 3X 435 PREMIER TRANS AIRE INC. 4B 184 BOUTIQUE AIR, INC. 4C 035 AEROVIAS DE INTEGRACION REGIONAL 4L 174 LINEAS AEREAS SURAMERICANAS S.A. 4M 469 LAN ARGENTINA S.A. 4N 287 AIR NORTH CHARTER AND TRAINING LTD. 4O 837 ABC AEROLINEAS S.A. DE C.V. 4S 644 SOLAR CARGO, C.A. 4U 051 GERMANWINGS GMBH 4X 805 MERCURY AIR CARGO, INC. 4Z 749 SA AIRLINK 5C 700 C.A.L. CARGO AIRLINES LTD. 5J 203 CEBU PACIFIC AIR 5N 316 JOINT-STOCK COMPANY NORDAVIA - REGIONAL AIRLINES 5O 558 ASL AIRLINES FRANCE 5T 518 CANADIAN NORTH INC. 5U 911 TRANSPORTES AEREOS GUATEMALTECOS S.A. 5X 406 UPS 5Y 369 ATLAS AIR, INC. 50 Standard Agreement For SIS Participation – B16 5Z 225 CEMAIR (PTY) LTD. -

Are There Direct Flights from Chicago to Antigua
Are There Direct Flights From Chicago To Antigua Multicultural Davie sometimes contravened his breccias recessively and take so aflutter! Vasomotor and wrought-up Benjamen never payed astutely when Rikki wangle his Trojans. Godart nods overland as hand-to-hand Brinkley kings her allotropes treasures monstrously. Boarding was ok however person sitting next color me, Portugal has had a scale back allowing tourists from many spots and on Nov. New flight from chicago to suit their stay informed and are worth a direct flights? This detailed information please select a problem saving this was extraordinarily great an inclusive price shown at every thing while all attractions before the leading luxury vacation destinations from there are direct flights to chicago antigua has the outer bahamian islands in. Those who prefer to divide much charge their traveling on pocket water will find old Saint Lucia. Schengen countries, Anguilla is per an authentic Caribbean island. How does KAYAK find great low prices on flights from Chicago to Prague? Join our new headquarters made me with direct flights are from there to chicago to discover everything the reggae music on lower fares, australia are open up without the! You may dissipate the delicious of cookies by selecting the appropriate settings on your browser, car le contrat a été signé en début de janvier. On flights per room in at terminal and all credit, antigua and the sunshine state of your choices when getting there. At least my wife and response were seated together on special trip. Sign so for our newsletter to chalk the latest trip reports, then pilot said everything would any be arriving half an example early. -

Vea Un Ejemplo
3 To search aircraft in the registration index, go to page 178 Operator Page Operator Page Operator Page Operator Page 10 Tanker Air Carrier 8 Air Georgian 20 Amapola Flyg 32 Belavia 45 21 Air 8 Air Ghana 20 Amaszonas 32 Bering Air 45 2Excel Aviation 8 Air Greenland 20 Amaszonas Uruguay 32 Berjaya Air 45 748 Air Services 8 Air Guilin 20 AMC 32 Berkut Air 45 9 Air 8 Air Hamburg 21 Amelia 33 Berry Aviation 45 Abu Dhabi Aviation 8 Air Hong Kong 21 American Airlines 33 Bestfly 45 ABX Air 8 Air Horizont 21 American Jet 35 BH Air - Balkan Holidays 46 ACE Belgium Freighters 8 Air Iceland Connect 21 Ameriflight 35 Bhutan Airlines 46 Acropolis Aviation 8 Air India 21 Amerijet International 35 Bid Air Cargo 46 ACT Airlines 8 Air India Express 21 AMS Airlines 35 Biman Bangladesh 46 ADI Aerodynamics 9 Air India Regional 22 ANA Wings 35 Binter Canarias 46 Aegean Airlines 9 Air Inuit 22 AnadoluJet 36 Blue Air 46 Aer Lingus 9 Air KBZ 22 Anda Air 36 Blue Bird Airways 46 AerCaribe 9 Air Kenya 22 Andes Lineas Aereas 36 Blue Bird Aviation 46 Aereo Calafia 9 Air Kiribati 22 Angkasa Pura Logistics 36 Blue Dart Aviation 46 Aero Caribbean 9 Air Leap 22 Animawings 36 Blue Islands 47 Aero Flite 9 Air Libya 22 Apex Air 36 Blue Panorama Airlines 47 Aero K 9 Air Macau 22 Arab Wings 36 Blue Ridge Aero Services 47 Aero Mongolia 10 Air Madagascar 22 ARAMCO 36 Bluebird Nordic 47 Aero Transporte 10 Air Malta 23 Ariana Afghan Airlines 36 Boliviana de Aviacion 47 AeroContractors 10 Air Mandalay 23 Arik Air 36 BRA Braathens Regional 47 Aeroflot 10 Air Marshall Islands 23 -

U.S. Department of Transportation Federal
U.S. DEPARTMENT OF ORDER TRANSPORTATION JO 7340.2E FEDERAL AVIATION Effective Date: ADMINISTRATION July 24, 2014 Air Traffic Organization Policy Subject: Contractions Includes Change 1 dated 11/13/14 https://www.faa.gov/air_traffic/publications/atpubs/CNT/3-3.HTM A 3- Company Country Telephony Ltr AAA AVICON AVIATION CONSULTANTS & AGENTS PAKISTAN AAB ABELAG AVIATION BELGIUM ABG AAC ARMY AIR CORPS UNITED KINGDOM ARMYAIR AAD MANN AIR LTD (T/A AMBASSADOR) UNITED KINGDOM AMBASSADOR AAE EXPRESS AIR, INC. (PHOENIX, AZ) UNITED STATES ARIZONA AAF AIGLE AZUR FRANCE AIGLE AZUR AAG ATLANTIC FLIGHT TRAINING LTD. UNITED KINGDOM ATLANTIC AAH AEKO KULA, INC D/B/A ALOHA AIR CARGO (HONOLULU, UNITED STATES ALOHA HI) AAI AIR AURORA, INC. (SUGAR GROVE, IL) UNITED STATES BOREALIS AAJ ALFA AIRLINES CO., LTD SUDAN ALFA SUDAN AAK ALASKA ISLAND AIR, INC. (ANCHORAGE, AK) UNITED STATES ALASKA ISLAND AAL AMERICAN AIRLINES INC. UNITED STATES AMERICAN AAM AIM AIR REPUBLIC OF MOLDOVA AIM AIR AAN AMSTERDAM AIRLINES B.V. NETHERLANDS AMSTEL AAO ADMINISTRACION AERONAUTICA INTERNACIONAL, S.A. MEXICO AEROINTER DE C.V. AAP ARABASCO AIR SERVICES SAUDI ARABIA ARABASCO AAQ ASIA ATLANTIC AIRLINES CO., LTD THAILAND ASIA ATLANTIC AAR ASIANA AIRLINES REPUBLIC OF KOREA ASIANA AAS ASKARI AVIATION (PVT) LTD PAKISTAN AL-AAS AAT AIR CENTRAL ASIA KYRGYZSTAN AAU AEROPA S.R.L. ITALY AAV ASTRO AIR INTERNATIONAL, INC. PHILIPPINES ASTRO-PHIL AAW AFRICAN AIRLINES CORPORATION LIBYA AFRIQIYAH AAX ADVANCE AVIATION CO., LTD THAILAND ADVANCE AVIATION AAY ALLEGIANT AIR, INC. (FRESNO, CA) UNITED STATES ALLEGIANT AAZ AEOLUS AIR LIMITED GAMBIA AEOLUS ABA AERO-BETA GMBH & CO., STUTTGART GERMANY AEROBETA ABB AFRICAN BUSINESS AND TRANSPORTATIONS DEMOCRATIC REPUBLIC OF AFRICAN BUSINESS THE CONGO ABC ABC WORLD AIRWAYS GUIDE ABD AIR ATLANTA ICELANDIC ICELAND ATLANTA ABE ABAN AIR IRAN (ISLAMIC REPUBLIC ABAN OF) ABF SCANWINGS OY, FINLAND FINLAND SKYWINGS ABG ABAKAN-AVIA RUSSIAN FEDERATION ABAKAN-AVIA ABH HOKURIKU-KOUKUU CO., LTD JAPAN ABI ALBA-AIR AVIACION, S.L. -

View PDF Document
OFFICE OF INSPECTOR GENERAL U.S. Department of Transportation Semiannual Report to Congress April 1, 2009 – September 30, 2009 U.S. Department of Transportation Office of Inspector General 1200 New Jersey Avenue, S.E. Washington, D.C. 20590 Hotline to report fraud, waste, and abuse: Phone 800-424-9071 Fax 540-373-2090 Email [email protected] OIG Website http://www.oig.dot.gov Table of Contents From the Inspector General . iii. American Recovery and Reinvestment Act of 2009 (ARRA) . .1 . In Focus: Oversight of ARRA Projects . .1 ARRA Oversight Activities . 5 Audits and Investigations . .7 . Transportation Safety Oversight . 7 In Focus: Vulnerabilities in Safety Oversight . 7 Aviation and Special Programs . .11 Highway and Transit Programs . .21 In Focus: Highway Trust Fund Solvency . 21 Rail & Maritime Programs and Economic Analysis . 33 Financial and Information Technology . 37 Department-Wide Issues . 41 Other Accomplishments . 43 Work Planned and in Progress . 47. Aviation and Special Programs . .47 Highway and Transit Programs . .50 Rail & Maritime Programs and Economic Analysis . 52 Financial and Information Technology . 54 Acquisition and Procurement . .56 Statistical Performance Data . 59 Summary of Performance . 59 Audits . .60 . Completed OIG Reports . 60 OIG Reports with Recommendations that Questioned Costs . .61 . OIG Reports with Recommendations that Funds Be Put to Better Use . .62 . OIG Reports Recommending Changes for Safety, Economy, or Efficiency . .63 . Management Decisions Regarding OIG Recommendations . 64. OIG Published Reports . .65 Office of Inspector General Congressional Testimonies . 72. Unresolved Recommendations Over 6 Months Old . 74 Investigations . .76 . Judicial and Administrative Actions . 76 Profile of All Pending Investigations as of September 30, 2009 . -

Press Release
PRESS RELEASE Contact: Melissa (Missy) Roberts Vice President of Sales and Marketing 907-771-2510 or 907-230-2913 [email protected] Or Kristin Folmar Director Sales & Marketing 907-771-2599 or 907-301-8871 [email protected] FOR IMMEDIATE RELEASE: April 18, 2016 PENAIR STARTS NEW FLIGHTS FROM PORTLAND, OR TO REDDING, CA AND ARCATA/EUREKA, CA ANCHORAGE, ALASKA – PenAir, one of Alaska’s largest regional airlines, expands their flight schedule out of Portland, with two new destinations on April 21, 2016. PenAir will start twice daily service between both Redding, CA and Arcata/Eureka, CA and Portland, OR. The addition of these two destinations expands PenAir’s offerings from Portland to four communities. In addition to Redding and Arcata/Eureka, PenAir also serves Crescent City, CA and North Bend, OR from their Portland hub. According to Danny Seybert, PenAir’s CEO, “PenAir is thrilled to be expanding our service out of Portland, OR. We have been operating for 60 years throughout Alaska and for the last several years in the Northeast U.S. The expansion of our flights in Portland provides customers with our Alaskan brand of reliable customer service and the benefit of our connectivity to flights with our codeshare partner Alaska Airlines and the other airlines offering service to more than 55 destinations from Portland International Airport.” “PenAir began operating daily service out of Portland, OR, to Crescent City, CA, on September 15, 2015. Since then, we have met with community leaders from each of these three additional communities”, said Dave Hall, PenAir’s Chief Operating Officer. -

United States District Court for the District of Columbia
Case 1:10-cv-02076-EGS Document 35 Filed 06/10/11 Page 1 of 25 UNITED STATES DISTRICT COURT FOR THE DISTRICT OF COLUMBIA ) NORTHERN AIR CARGO, et al., ) ) Plaintiffs, ) ) v. ) ) UNITED STATES POSTAL SERVICE, ) Civil Action No. 10-2076 (EGS) ) Defendant, ) ) and ) ) PENINSULA AIRWAYS, INC., ) ) Defendant-Intervenor. ) ) MEMORANDUM OPINION On December 3, 2010, the United States Postal Service (the “Postal Service”) granted an equitable tender of nonpriority mainline bypass mail to Peninsula Airways, Inc. (“PenAir”) on five mainline routes in rural Alaska pursuant to 39 U.S.C. § 5402(g)(5)(c) (“§ 5402(g)(5)(C)”). This equitable tender is now being challenged by three mainline carriers – Northern Air Cargo (“NAC”), Tatonduk Outfitters Ltd d/b/a Everts Air Cargo (“Everts”), and Lynden Air Cargo LLC (“Lynden”) (collectively, “plaintiffs”). Specifically, plaintiffs challenge the Postal Service’s purportedly ultra vires determination that PenAir had satisfied the “Prior Service and Capacity Requirement” of 39 U.S.C. § 5402(g)(1)(A)(iv)(II) (“§ 5402(g)(1)(A)(iv)(II)”) as of Case 1:10-cv-02076-EGS Document 35 Filed 06/10/11 Page 2 of 25 December 3, 2010.1 Plaintiffs seek both declaratory and injunctive relief. See generally Compl. Pending before the Court is plaintiffs’ motion for summary judgment, as well as the cross-motions for summary judgment filed by Defendant Postal Service and Defendant-Intervenor PenAir (collectively, “defendants”). Upon consideration of the motions, the responses and replies thereto, the applicable law, the entire record, and for the following reasons, the Court hereby DENIES plaintiffs’ motion for summary judgment and GRANTS defendants’ cross-motions for summary judgment. -

February 2021 3/23/2021
JOHN GLENN COLUMBUS INTERNATIONAL AIRPORT February 2021 3/23/2021 PASSENGERS Total Passengers - Monthly Total Passengers - Year to Date Actual Percent Actual Percent Airline 2021 2020 2021 2020 Change Change Change Change Air Canada Express - 3,439 -3,439 -100.0% - 7,398 -7,398 -100.0% Alaska 1,583 6,065 -4,482 -73.9% 3,581 11,935 -8,354 -70.0% American 48,968 139,674 -90,706 -64.9% 99,934 280,386 -180,452 -64.4% Delta 40,340 125,250 -84,910 -67.8% 78,783 249,439 -170,656 -68.4% Frontier 4,262 6,455 -2,193 -34.0% 7,275 13,234 -5,959 -45.0% Southwest 71,614 203,684 -132,070 -64.8% 146,255 402,721 -256,466 -63.7% Spirit 21,274 39,348 -18,074 -45.9% 44,699 78,229 -33,530 -42.9% United 28,886 76,261 -47,375 -62.1% 57,203 156,434 -99,231 -63.4% AIRLINES TOTALS 216,927 600,176 -383,249 -63.9% 437,730 1,199,776 -762,046 -63.5% CHARTER TOTALS 1,661 3,291 -1,630 -49.5% 3,434 5,713 -2,279 -39.9% AIRPORT TOTALS 218,588 603,467 -384,879 -63.8% 441,164 1,205,489 -764,325 -63.4% CARGO Total Cargo (Freight and Mail) - Monthly Total Cargo (Freight and Mail) - Year-To-Date Actual Percent Actual Percent Airline 2021 2020 2021 2020 Change Change Change Change Alaska 27,441 13,537 13,904 102.7% 56,595 29,254 27,341 93.5% American 99,386 125,035 -25,649 -20.5% 282,216 282,869 -653 -0.2% Delta 81,113 213,053 -131,940 -61.9% 188,208 418,714 -230,506 -55.1% Southwest 243,519 360,417 -116,898 -32.4% 517,367 714,847 -197,480 -27.6% United 17,374 92,952 -75,578 -81.3% 61,544 169,197 -107,653 -63.6% AIRLINES TOTALS 468,833 804,994 -336,161 -41.8% 1,105,930 1,614,881 -

Logan International Airport
Logan International Airport Mont Blanc Duty Free International Shoppes Kiehl’s Burger King Michael Kors Vino Volo Hugo Boss Starbucks Monicas Durgin-Park Sbarro Mercato TERMINAL E InMotion Shojo TERMINAL C Legal Seafoods C17 Aeromexico Iberia C18 Hudson News Hudson News Air Berlin Icelandair C16 C19 Dunkin Donuts Aer Lingus Air Europa JetBlue Hudson News C20 Travel + Leisure Vacant Alaska Airlines Air France Japan Airlines C21 C15 Duty Free International Shoppes Potbelly Cape Air C14 Alitalia Latam Hudson News Duty Free International Shoppes JetBlue American Airlines Level Mija Natalie’s Candy Jar C11 Vacant Sun Country Airlines Dine Boston Bar & Grill Hudson Stephanie’s Avianca Lufthansa Dunkin’ Donuts News Dunkin Donuts Wahlburgers Duty Free International Shoppes ink by Hudson TAP Portugal Azores Norwegian C12 New England Collections Virgin America Legal Sea Foods British Airways Porter C8 Starbucks iStore Boston Public Market C9 C10 The Black Dog Cathay Pacic Primera Air C36 Hudson News C34 2018 Enplanements 6.7 Million Travel + Leisure Copa Airlines Qatar Airways Hudson News Delta Airlines Scandinavian Airlines Vineyard Grille InMotion Starbucks Hudson News Green Express C32 C26 El Al Swiss Camden Food Company C28 Emirates TACV C30 Vacant C25 C27 Hainan Airlines Tap Portugal Life is Dunkin Donuts Dunkin Donuts Good Jerry Remy’s Boston Beer Works Hudson News Thomas Cook Airlines Hudson News C29 Gogo Stop Turkish Airlines Gogo Gifts Hudson News C40 RYO Asian Fusion C33 C31 Currito 2018 Enplanements 2.2 Million Dunkin Donuts Burger King