Chapter 3: Using the GNU Compiler Collection Features of GNU CC
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Red Hat Enterprise Linux 6 Developer Guide
Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Dave Brolley William Cohen Roland Grunberg Aldy Hernandez Karsten Hopp Jakub Jelinek Developer Guide Jeff Johnston Benjamin Kosnik Aleksander Kurtakov Chris Moller Phil Muldoon Andrew Overholt Charley Wang Kent Sebastian Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Edition 0 Author Dave Brolley [email protected] Author William Cohen [email protected] Author Roland Grunberg [email protected] Author Aldy Hernandez [email protected] Author Karsten Hopp [email protected] Author Jakub Jelinek [email protected] Author Jeff Johnston [email protected] Author Benjamin Kosnik [email protected] Author Aleksander Kurtakov [email protected] Author Chris Moller [email protected] Author Phil Muldoon [email protected] Author Andrew Overholt [email protected] Author Charley Wang [email protected] Author Kent Sebastian [email protected] Editor Don Domingo [email protected] Editor Jacquelynn East [email protected] Copyright © 2010 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. -

Using Restricted Transactional Memory to Build a Scalable In-Memory Database
Using Restricted Transactional Memory to Build a Scalable In-Memory Database Zhaoguo Wang†, Hao Qian‡, Jinyang Li§, Haibo Chen‡ † School of Computer Science, Fudan University ‡ Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University § Department of Computer Science, New York University Abstract However, the correctness of the resulting code is complex to reason about and relies on the processor’s (increasingly The recent availability of Intel Haswell processors marks the complex) memory model. transition of hardware transactional memory from research Recently, Intel has shipped its 4th-generation Haswell toys to mainstream reality. DBX is an in-memory database processor with support for Hardware Transactional Mem- that uses Intel’s restricted transactional memory (RTM) to ory [16]. This opens up a third possibility to scaling multi- achieve high performance and good scalability across multi- core software. Instead of relying on fine-grained locking core machines. The main limitation (and also key to practi- and atomic operations, one can synchronize using hardware cality) of RTM is its constrained working set size: an RTM transactions, which offer a programming model that is ar- region that reads or writes too much data will always be guably even more straightforward than mutual exclusion. aborted. The design of DBX addresses this challenge in sev- The promise is that the resulting implementation is much eral ways. First, DBX builds a database transaction layer on simpler and easier-to-understand while still retaining the top of an underlying shared-memory store. The two layers performance benefits of fine-grained locking. use separate RTM regions to synchronize shared memory Does hardware transactional memory actually deliver its access. -

Studying the Real World Today's Topics
Studying the real world Today's topics Free and open source software (FOSS) What is it, who uses it, history Making the most of other people's software Learning from, using, and contributing Learning about your own system Using tools to understand software without source Free and open source software Access to source code Free = freedom to use, modify, copy Some potential benefits Can build for different platforms and needs Development driven by community Different perspectives and ideas More people looking at the code for bugs/security issues Structure Volunteers, sponsored by companies Generally anyone can propose ideas and submit code Different structures in charge of what features/code gets in Free and open source software Tons of FOSS out there Nearly everything on myth Desktop applications (Firefox, Chromium, LibreOffice) Programming tools (compilers, libraries, IDEs) Servers (Apache web server, MySQL) Many companies contribute to FOSS Android core Apple Darwin Microsoft .NET A brief history of FOSS 1960s: Software distributed with hardware Source included, users could fix bugs 1970s: Start of software licensing 1974: Software is copyrightable 1975: First license for UNIX sold 1980s: Popularity of closed-source software Software valued independent of hardware Richard Stallman Started the free software movement (1983) The GNU project GNU = GNU's Not Unix An operating system with unix-like interface GNU General Public License Free software: users have access to source, can modify and redistribute Must share modifications under same -

Using the GNU Compiler Collection (GCC)
Using the GNU Compiler Collection (GCC) Using the GNU Compiler Collection by Richard M. Stallman and the GCC Developer Community Last updated 23 May 2004 for GCC 3.4.6 For GCC Version 3.4.6 Published by: GNU Press Website: www.gnupress.org a division of the General: [email protected] Free Software Foundation Orders: [email protected] 59 Temple Place Suite 330 Tel 617-542-5942 Boston, MA 02111-1307 USA Fax 617-542-2652 Last printed October 2003 for GCC 3.3.1. Printed copies are available for $45 each. Copyright c 1988, 1989, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with the Invariant Sections being \GNU General Public License" and \Funding Free Software", the Front-Cover texts being (a) (see below), and with the Back-Cover Texts being (b) (see below). A copy of the license is included in the section entitled \GNU Free Documentation License". (a) The FSF's Front-Cover Text is: A GNU Manual (b) The FSF's Back-Cover Text is: You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development. i Short Contents Introduction ...................................... 1 1 Programming Languages Supported by GCC ............ 3 2 Language Standards Supported by GCC ............... 5 3 GCC Command Options ......................... -

Winappdbg Documentation Release 1.6
WinAppDbg Documentation Release 1.6 Mario Vilas Aug 28, 2019 Contents 1 Introduction 1 2 Programming Guide 3 i ii CHAPTER 1 Introduction The WinAppDbg python module allows developers to quickly code instrumentation scripts in Python under a Win- dows environment. It uses ctypes to wrap many Win32 API calls related to debugging, and provides a powerful abstraction layer to manipulate threads, libraries and processes, attach your script as a debugger, trace execution, hook API calls, handle events in your debugee and set breakpoints of different kinds (code, hardware and memory). Additionally it has no native code at all, making it easier to maintain or modify than other debuggers on Windows. The intended audience are QA engineers and software security auditors wishing to test or fuzz Windows applications with quickly coded Python scripts. Several ready to use tools are shipped and can be used for this purposes. Current features also include disassembling x86/x64 native code, debugging multiple processes simultaneously and produce a detailed log of application crashes, useful for fuzzing and automated testing. Here is a list of software projects that use WinAppDbg in alphabetical order: • Heappie! is a heap analysis tool geared towards exploit writing. It allows you to visualize the heap layout during the heap spray or heap massaging stage in your exploits. The original version uses vtrace but here’s a patch to use WinAppDbg instead. The patch also adds 64 bit support. • PyPeElf is an open source GUI executable file analyzer for Windows and Linux released under the BSD license. • python-haystack is a heap analysis framework, focused on classic C structure matching. -
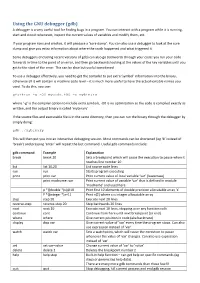
Using the GNU Debugger (Gdb) a Debugger Is a Very Useful Tool for Finding Bugs in a Program
Using the GNU debugger (gdb) A debugger is a very useful tool for finding bugs in a program. You can interact with a program while it is running, start and stop it whenever, inspect the current values of variables and modify them, etc. If your program runs and crashes, it will produce a ‘core dump’. You can also use a debugger to look at the core dump and give you extra information about where the crash happened and what triggered it. Some debuggers (including recent versions of gdb) can also go backwards through your code: you run your code forwards in time to the point of an error, and then go backwards looking at the values of the key variables until you get to the start of the error. This can be slow but useful sometimes! To use a debugger effectively, you need to get the compiler to put extra ‘symbol’ information into the binary, otherwise all it will contain is machine code level – it is much more useful to have the actual variable names you used. To do this, you use: gfortran –g –O0 mycode.f90 –o mybinary where ‘-g’ is the compiler option to include extra symbols, -O0 is no optimization so the code is compiled exactly as written, and the output binary is called ’mybinary’. If the source files and executable file is in the same directory, then you can run the binary through the debugger by simply doing: gdb ./mybinary This will then put you into an interactive debugging session. Most commands can be shortened (eg ‘b’ instead of ‘break’) and pressing ‘enter’ will repeat the last command. -

Bringing GNU Emacs to Native Code
Bringing GNU Emacs to Native Code Andrea Corallo Luca Nassi Nicola Manca [email protected] [email protected] [email protected] CNR-SPIN Genoa, Italy ABSTRACT such a long-standing project. Although this makes it didactic, some Emacs Lisp (Elisp) is the Lisp dialect used by the Emacs text editor limitations prevent the current implementation of Emacs Lisp to family. GNU Emacs can currently execute Elisp code either inter- be appealing for broader use. In this context, performance issues preted or byte-interpreted after it has been compiled to byte-code. represent the main bottleneck, which can be broken down in three In this work we discuss the implementation of an optimizing com- main sub-problems: piler approach for Elisp targeting native code. The native compiler • lack of true multi-threading support, employs the byte-compiler’s internal representation as input and • garbage collection speed, exploits libgccjit to achieve code generation using the GNU Com- • code execution speed. piler Collection (GCC) infrastructure. Generated executables are From now on we will focus on the last of these issues, which con- stored as binary files and can be loaded and unloaded dynamically. stitutes the topic of this work. Most of the functionality of the compiler is written in Elisp itself, The current implementation traditionally approaches the prob- including several optimization passes, paired with a C back-end lem of code execution speed in two ways: to interface with the GNU Emacs core and libgccjit. Though still a work in progress, our implementation is able to bootstrap a func- • Implementing a large number of performance-sensitive prim- tional Emacs and compile all lexically scoped Elisp files, including itive functions (also known as subr) in C. -

Ethereal Developer's Guide Draft 0.0.2 (15684) for Ethereal 0.10.11
Ethereal Developer's Guide Draft 0.0.2 (15684) for Ethereal 0.10.11 Ulf Lamping, Ethereal Developer's Guide: Draft 0.0.2 (15684) for Ethere- al 0.10.11 by Ulf Lamping Copyright © 2004-2005 Ulf Lamping Permission is granted to copy, distribute and/or modify this document under the terms of the GNU General Public License, Version 2 or any later version published by the Free Software Foundation. All logos and trademarks in this document are property of their respective owner. Table of Contents Preface .............................................................................................................................. vii 1. Foreword ............................................................................................................... vii 2. Who should read this document? ............................................................................... viii 3. Acknowledgements ................................................................................................... ix 4. About this document .................................................................................................. x 5. Where to get the latest copy of this document? ............................................................... xi 6. Providing feedback about this document ...................................................................... xii I. Ethereal Build Environment ................................................................................................14 1. Introduction .............................................................................................................15 -

The GNU Compiler Collection on Zseries
The GNU Compiler Collection on zSeries Dr. Ulrich Weigand Linux for zSeries Development, IBM Lab Böblingen [email protected] Agenda GNU Compiler Collection History and features Architecture overview GCC on zSeries History and current status zSeries specific features and challenges Using GCC GCC optimization settings GCC inline assembly Future of GCC GCC and Linux Apache Samba mount cvs binutils gdb gcc Linux ls grep Kernel glibc DB2 GNU - essentials UDB SAP R/3 Unix - tools Applications GCC History Timeline January 1984: Start of the GNU project May 1987: Release of GCC 1.0 February 1992: Release of GCC 2.0 August 1997: EGCS project announced November 1997: Release of EGCS 1.0 April 1999: EGCS / GCC merge July 1999: Release of GCC 2.95 June 2001: Release of GCC 3.0 May/August 2002: Release of GCC 3.1/3.2 March 2003: Release of GCC 3.3 (estimated) GCC Features Supported Languages part of GCC distribution: C, C++, Objective C Fortran 77 Java Ada distributed separately: Pascal Modula-3 under development: Fortran 95 Cobol GCC Features (cont.) Supported CPU targets i386, ia64, rs6000, s390 sparc, alpha, mips, arm, pa-risc, m68k, m88k many embedded targets Supported OS bindings Unix: Linux, *BSD, AIX, Solaris, HP/UX, Tru64, Irix, SCO DOS/Windows, Darwin (MacOS X) embedded targets and others Supported modes of operation native compiler cross-compiler 'Canadian cross' builds GCC Architecture: Overview C C++ Fortran Java ... front-end front-end front-end front-end tree Optimizer rtx i386 s390 rs6000 sparc ... back-end back-end back-end -

Introduction to GNU Octave
Introduction to GNU Octave Hubert Selhofer, revised by Marcel Oliver updated to current Octave version by Thomas L. Scofield 2008/08/16 line 1 1 0.8 0.6 0.4 0.2 0 -0.2 -0.4 8 6 4 2 -8 -6 0 -4 -2 -2 0 -4 2 4 -6 6 8 -8 Contents 1 Basics 2 1.1 What is Octave? ........................... 2 1.2 Help! . 2 1.3 Input conventions . 3 1.4 Variables and standard operations . 3 2 Vector and matrix operations 4 2.1 Vectors . 4 2.2 Matrices . 4 1 2.3 Basic matrix arithmetic . 5 2.4 Element-wise operations . 5 2.5 Indexing and slicing . 6 2.6 Solving linear systems of equations . 7 2.7 Inverses, decompositions, eigenvalues . 7 2.8 Testing for zero elements . 8 3 Control structures 8 3.1 Functions . 8 3.2 Global variables . 9 3.3 Loops . 9 3.4 Branching . 9 3.5 Functions of functions . 10 3.6 Efficiency considerations . 10 3.7 Input and output . 11 4 Graphics 11 4.1 2D graphics . 11 4.2 3D graphics: . 12 4.3 Commands for 2D and 3D graphics . 13 5 Exercises 13 5.1 Linear algebra . 13 5.2 Timing . 14 5.3 Stability functions of BDF-integrators . 14 5.4 3D plot . 15 5.5 Hilbert matrix . 15 5.6 Least square fit of a straight line . 16 5.7 Trapezoidal rule . 16 1 Basics 1.1 What is Octave? Octave is an interactive programming language specifically suited for vectoriz- able numerical calculations. -

Lecture 1: Introduction to UNIX
The Operating System Course Overview Getting Started Lecture 1: Introduction to UNIX CS2042 - UNIX Tools September 29, 2008 Lecture 1: UNIX Intro The Operating System Description and History Course Overview UNIX Flavors Getting Started Advantages and Disadvantages Lecture Outline 1 The Operating System Description and History UNIX Flavors Advantages and Disadvantages 2 Course Overview Class Specifics 3 Getting Started Login Information Lecture 1: UNIX Intro The Operating System Description and History Course Overview UNIX Flavors Getting Started Advantages and Disadvantages What is UNIX? One of the first widely-used operating systems Basis for many modern OSes Helped set the standard for multi-tasking, multi-user systems Strictly a teaching tool (in its original form) Lecture 1: UNIX Intro The Operating System Description and History Course Overview UNIX Flavors Getting Started Advantages and Disadvantages A Brief History of UNIX Origins The first version of UNIX was created in 1969 by a group of guys working for AT&T's Bell Labs. It was one of the first big projects written in the emerging C language. It gained popularity throughout the '70s and '80s, although non-AT&T versions eventually took the lion's share of the market. Predates Microsoft's DOS by 12 years! Lecture 1: UNIX Intro The Operating System Description and History Course Overview UNIX Flavors Getting Started Advantages and Disadvantages Lecture Outline 1 The Operating System Description and History UNIX Flavors Advantages and Disadvantages 2 Course Overview Class Specifics 3 -

GNU Octave Beginner's Guide
GNU Octave Beginner's Guide Become a profcient Octave user by learning this high-level scientfc numerical tool from the ground up Jesper Schmidt Hansen BIRMINGHAM - MUMBAI GNU Octave Beginner's Guide Copyright © 2011 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmited in any form or by any means, without the prior writen permission of the publisher, except in the case of brief quotatons embedded in critcal artcles or reviews. Every efort has been made in the preparaton of this book to ensure the accuracy of the informaton presented. However, the informaton contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, its dealers, and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark informaton about all of the companies and products mentoned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this informaton. First published: June 2011 Producton Reference: 2150611 Published by Packt Publishing Ltd. 32 Lincoln Road Olton Birmingham, B27 6PA, UK. ISBN 978-1-849513-32-6 www.packtpub.com Cover Image by John Quick ([email protected]) Credits Author Project Coordinator Jesper Schmidt Hansen Joel Goveya Reviewers Proofreaders Piotr Gawron Lesley Harrison Kenneth Geisshirt Clyde Jenkins Jordi Gutérrez Hermoso Lynda Sliwoski Acquisiton Editor Indexers Usha Iyer Hemangini Bari Tejal Daruwale Development Editor Monica Ajmera Mehta Roger D'souza Graphics Technical Editor Nilesh R.