Bringing GNU Emacs to Native Code
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

GNU/Linux AI & Alife HOWTO
GNU/Linux AI & Alife HOWTO GNU/Linux AI & Alife HOWTO Table of Contents GNU/Linux AI & Alife HOWTO......................................................................................................................1 by John Eikenberry..................................................................................................................................1 1. Introduction..........................................................................................................................................1 2. Symbolic Systems (GOFAI)................................................................................................................1 3. Connectionism.....................................................................................................................................1 4. Evolutionary Computing......................................................................................................................1 5. Alife & Complex Systems...................................................................................................................1 6. Agents & Robotics...............................................................................................................................1 7. Statistical & Machine Learning...........................................................................................................2 8. Missing & Dead...................................................................................................................................2 1. Introduction.........................................................................................................................................2 -

Compiling Sandboxes: Formally Verified Software Fault Isolation
Compiling Sandboxes: Formally Verified Software Fault Isolation Frédéric Besson1[0000−0001−6815−0652], Sandrine Blazy1[0000−0002−0189−0223], Alexandre Dang1, Thomas Jensen1, and Pierre Wilke2[0000−0001−9681−644X] 1 Inria, Univ Rennes, CNRS, IRISA 2 CentraleSupélec, Inria, Univ Rennes, CNRS, IRISA Abstract. Software Fault Isolation (SFI) is a security-enhancing pro- gram transformation for instrumenting an untrusted binary module so that it runs inside a dedicated isolated address space, called a sandbox. To ensure that the untrusted module cannot escape its sandbox, existing approaches such as Google’s Native Client rely on a binary verifier to check that all memory accesses are within the sandbox. Instead of rely- ing on a posteriori verification, we design, implement and prove correct a program instrumentation phase as part of the formally verified com- piler CompCert that enforces a sandboxing security property a priori. This eliminates the need for a binary verifier and, instead, leverages the soundness proof of the compiler to prove the security of the sandbox- ing transformation. The technical contributions are a novel sandboxing transformation that has a well-defined C semantics and which supports arbitrary function pointers, and a formally verified C compiler that im- plements SFI. Experiments show that our formally verified technique is a competitive way of implementing SFI. 1 Introduction Isolating programs with various levels of trustworthiness is a fundamental se- curity concern, be it on a cloud computing platform running untrusted code provided by customers, or in a web browser running untrusted code coming from different origins. In these contexts, it is of the utmost importance to pro- vide adequate isolation mechanisms so that a faulty or malicious computation cannot compromise the host or neighbouring computations. -

Red Hat Enterprise Linux 6 Developer Guide
Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Dave Brolley William Cohen Roland Grunberg Aldy Hernandez Karsten Hopp Jakub Jelinek Developer Guide Jeff Johnston Benjamin Kosnik Aleksander Kurtakov Chris Moller Phil Muldoon Andrew Overholt Charley Wang Kent Sebastian Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Edition 0 Author Dave Brolley [email protected] Author William Cohen [email protected] Author Roland Grunberg [email protected] Author Aldy Hernandez [email protected] Author Karsten Hopp [email protected] Author Jakub Jelinek [email protected] Author Jeff Johnston [email protected] Author Benjamin Kosnik [email protected] Author Aleksander Kurtakov [email protected] Author Chris Moller [email protected] Author Phil Muldoon [email protected] Author Andrew Overholt [email protected] Author Charley Wang [email protected] Author Kent Sebastian [email protected] Editor Don Domingo [email protected] Editor Jacquelynn East [email protected] Copyright © 2010 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. -

Using the GNU Compiler Collection (GCC)
Using the GNU Compiler Collection (GCC) Using the GNU Compiler Collection by Richard M. Stallman and the GCC Developer Community Last updated 23 May 2004 for GCC 3.4.6 For GCC Version 3.4.6 Published by: GNU Press Website: www.gnupress.org a division of the General: [email protected] Free Software Foundation Orders: [email protected] 59 Temple Place Suite 330 Tel 617-542-5942 Boston, MA 02111-1307 USA Fax 617-542-2652 Last printed October 2003 for GCC 3.3.1. Printed copies are available for $45 each. Copyright c 1988, 1989, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with the Invariant Sections being \GNU General Public License" and \Funding Free Software", the Front-Cover texts being (a) (see below), and with the Back-Cover Texts being (b) (see below). A copy of the license is included in the section entitled \GNU Free Documentation License". (a) The FSF's Front-Cover Text is: A GNU Manual (b) The FSF's Back-Cover Text is: You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development. i Short Contents Introduction ...................................... 1 1 Programming Languages Supported by GCC ............ 3 2 Language Standards Supported by GCC ............... 5 3 GCC Command Options ......................... -

Winappdbg Documentation Release 1.6
WinAppDbg Documentation Release 1.6 Mario Vilas Aug 28, 2019 Contents 1 Introduction 1 2 Programming Guide 3 i ii CHAPTER 1 Introduction The WinAppDbg python module allows developers to quickly code instrumentation scripts in Python under a Win- dows environment. It uses ctypes to wrap many Win32 API calls related to debugging, and provides a powerful abstraction layer to manipulate threads, libraries and processes, attach your script as a debugger, trace execution, hook API calls, handle events in your debugee and set breakpoints of different kinds (code, hardware and memory). Additionally it has no native code at all, making it easier to maintain or modify than other debuggers on Windows. The intended audience are QA engineers and software security auditors wishing to test or fuzz Windows applications with quickly coded Python scripts. Several ready to use tools are shipped and can be used for this purposes. Current features also include disassembling x86/x64 native code, debugging multiple processes simultaneously and produce a detailed log of application crashes, useful for fuzzing and automated testing. Here is a list of software projects that use WinAppDbg in alphabetical order: • Heappie! is a heap analysis tool geared towards exploit writing. It allows you to visualize the heap layout during the heap spray or heap massaging stage in your exploits. The original version uses vtrace but here’s a patch to use WinAppDbg instead. The patch also adds 64 bit support. • PyPeElf is an open source GUI executable file analyzer for Windows and Linux released under the BSD license. • python-haystack is a heap analysis framework, focused on classic C structure matching. -

An Implementation of Python for Racket
An Implementation of Python for Racket Pedro Palma Ramos António Menezes Leitão INESC-ID, Instituto Superior Técnico, INESC-ID, Instituto Superior Técnico, Universidade de Lisboa Universidade de Lisboa Rua Alves Redol 9 Rua Alves Redol 9 Lisboa, Portugal Lisboa, Portugal [email protected] [email protected] ABSTRACT Keywords Racket is a descendent of Scheme that is widely used as a Python; Racket; Language implementations; Compilers first language for teaching computer science. To this end, Racket provides DrRacket, a simple but pedagogic IDE. On the other hand, Python is becoming increasingly popular 1. INTRODUCTION in a variety of areas, most notably among novice program- The Racket programming language is a descendent of Scheme, mers. This paper presents an implementation of Python a language that is well-known for its use in introductory for Racket which allows programmers to use DrRacket with programming courses. Racket comes with DrRacket, a ped- Python code, as well as adding Python support for other Dr- agogic IDE [2], used in many schools around the world, as Racket based tools. Our implementation also allows Racket it provides a simple and straightforward interface aimed at programs to take advantage of Python libraries, thus signif- inexperienced programmers. Racket provides different lan- icantly enlarging the number of usable libraries in Racket. guage levels, each one supporting more advanced features, that are used in different phases of the courses, allowing Our proposed solution involves compiling Python code into students to benefit from a smoother learning curve. Fur- semantically equivalent Racket source code. For the run- thermore, Racket and DrRacket support the development of time implementation, we present two different strategies: additional programming languages [13]. -
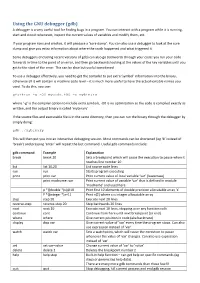
Using the GNU Debugger (Gdb) a Debugger Is a Very Useful Tool for Finding Bugs in a Program
Using the GNU debugger (gdb) A debugger is a very useful tool for finding bugs in a program. You can interact with a program while it is running, start and stop it whenever, inspect the current values of variables and modify them, etc. If your program runs and crashes, it will produce a ‘core dump’. You can also use a debugger to look at the core dump and give you extra information about where the crash happened and what triggered it. Some debuggers (including recent versions of gdb) can also go backwards through your code: you run your code forwards in time to the point of an error, and then go backwards looking at the values of the key variables until you get to the start of the error. This can be slow but useful sometimes! To use a debugger effectively, you need to get the compiler to put extra ‘symbol’ information into the binary, otherwise all it will contain is machine code level – it is much more useful to have the actual variable names you used. To do this, you use: gfortran –g –O0 mycode.f90 –o mybinary where ‘-g’ is the compiler option to include extra symbols, -O0 is no optimization so the code is compiled exactly as written, and the output binary is called ’mybinary’. If the source files and executable file is in the same directory, then you can run the binary through the debugger by simply doing: gdb ./mybinary This will then put you into an interactive debugging session. Most commands can be shortened (eg ‘b’ instead of ‘break’) and pressing ‘enter’ will repeat the last command. -

GNU Emacs Manual
GNU Emacs Manual GNU Emacs Manual Sixteenth Edition, Updated for Emacs Version 22.1. Richard Stallman This is the Sixteenth edition of the GNU Emacs Manual, updated for Emacs version 22.1. Copyright c 1985, 1986, 1987, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with the Invariant Sections being \The GNU Manifesto," \Distribution" and \GNU GENERAL PUBLIC LICENSE," with the Front-Cover texts being \A GNU Manual," and with the Back-Cover Texts as in (a) below. A copy of the license is included in the section entitled \GNU Free Documentation License." (a) The FSF's Back-Cover Text is: \You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development." Published by the Free Software Foundation 51 Franklin Street, Fifth Floor Boston, MA 02110-1301 USA ISBN 1-882114-86-8 Cover art by Etienne Suvasa. i Short Contents Preface ::::::::::::::::::::::::::::::::::::::::::::::::: 1 Distribution ::::::::::::::::::::::::::::::::::::::::::::: 2 Introduction ::::::::::::::::::::::::::::::::::::::::::::: 5 1 The Organization of the Screen :::::::::::::::::::::::::: 6 2 Characters, Keys and Commands ::::::::::::::::::::::: 11 3 Entering and Exiting Emacs ::::::::::::::::::::::::::: 15 4 Basic Editing -

An Evaluation of Go and Clojure
An evaluation of Go and Clojure A thesis submitted in partial satisfaction of the requirements for the degree Bachelors of Science in Computer Science Fall 2010 Robert Stimpfling Department of Computer Science University of Colorado, Boulder Advisor: Kenneth M. Anderson, PhD Department of Computer Science University of Colorado, Boulder 1. Introduction Concurrent programming languages are not new, but they have been getting a lot of attention more recently due to their potential with multiple processors. Processors have gone from growing exponentially in terms of speed, to growing in terms of quantity. This means processes that are completely serial in execution will soon be seeing a plateau in performance gains since they can only rely on one processor. A popular approach to using these extra processors is to make programs multi-threaded. The threads can execute in parallel and use shared memory to speed up execution times. These multithreaded processes can significantly speed up performance, as long as the number of dependencies remains low. Amdahl‘s law states that these performance gains can only be relative to the amount of processing that can be parallelized [1]. However, the performance gains are significant enough to be looked into. These gains not only come from the processing being divvied up into sections that run in parallel, but from the inherent gains from sharing memory and data structures. Passing new threads a copy of a data structure can be demanding on the processor because it requires the processor to delve into memory and make an exact copy in a new location in memory. Indeed some studies have shown that the problem with optimizing concurrent threads is not in utilizing the processors optimally, but in the need for technical improvements in memory performance [2]. -

GNU Guix Cookbook Tutorials and Examples for Using the GNU Guix Functional Package Manager
GNU Guix Cookbook Tutorials and examples for using the GNU Guix Functional Package Manager The GNU Guix Developers Copyright c 2019 Ricardo Wurmus Copyright c 2019 Efraim Flashner Copyright c 2019 Pierre Neidhardt Copyright c 2020 Oleg Pykhalov Copyright c 2020 Matthew Brooks Copyright c 2020 Marcin Karpezo Copyright c 2020 Brice Waegeneire Copyright c 2020 Andr´eBatista Copyright c 2020 Christine Lemmer-Webber Copyright c 2021 Joshua Branson Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled \GNU Free Documentation License". i Table of Contents GNU Guix Cookbook ::::::::::::::::::::::::::::::: 1 1 Scheme tutorials ::::::::::::::::::::::::::::::::: 2 1.1 A Scheme Crash Course :::::::::::::::::::::::::::::::::::::::: 2 2 Packaging :::::::::::::::::::::::::::::::::::::::: 5 2.1 Packaging Tutorial:::::::::::::::::::::::::::::::::::::::::::::: 5 2.1.1 A \Hello World" package :::::::::::::::::::::::::::::::::: 5 2.1.2 Setup:::::::::::::::::::::::::::::::::::::::::::::::::::::: 8 2.1.2.1 Local file ::::::::::::::::::::::::::::::::::::::::::::: 8 2.1.2.2 `GUIX_PACKAGE_PATH' ::::::::::::::::::::::::::::::::: 9 2.1.2.3 Guix channels ::::::::::::::::::::::::::::::::::::::: 10 2.1.2.4 Direct checkout hacking:::::::::::::::::::::::::::::: 10 2.1.3 Extended example :::::::::::::::::::::::::::::::::::::::: -

Emacspeak User's Guide
Emacspeak User's Guide Jennifer Jobst Revision History Revision 1.3 July 24,2002 Revised by: SDS Updated the maintainer of this document to Sharon Snider, corrected links, and converted to HTML Revision 1.2 December 3, 2001 Revised by: JEJ Changed license to GFDL Revision 1.1 November 12, 2001 Revised by: JEJ Revision 1.0 DRAFT October 19, 2001 Revised by: JEJ This document helps Emacspeak users become familiar with Emacs as an audio desktop and provides tutorials on many common tasks and the Emacs applications available to perform those tasks. Emacspeak User's Guide Table of Contents 1. Legal Notice.....................................................................................................................................................1 2. Introduction.....................................................................................................................................................2 2.1. What is Emacspeak?.........................................................................................................................2 2.2. About this tutorial.............................................................................................................................2 3. Before you begin..............................................................................................................................................3 3.1. Getting started with Emacs and Emacspeak.....................................................................................3 3.2. Emacs Command Conventions.........................................................................................................3 -

Programming with GNU Emacs Lisp
Programming with GNU Emacs Lisp William H. Mitchell (whm) Mitchell Software Engineering (.com) GNU Emacs Lisp Programming Slide 1 Copyright © 2001-2008 by William H. Mitchell GNU Emacs Lisp Programming Slide 2 Copyright © 2001-2008 by William H. Mitchell Emacs Lisp Introduction A little history GNU Emacs Lisp Programming Slide 3 Copyright © 2001-2008 by William H. Mitchell Introduction GNU Emacs is a full-featured text editor that contains a complete Lisp system. Emacs Lisp is used for a variety of things: • Complete applications such as mail and news readers, IM clients, calendars, games, and browsers of various sorts. • Improved interfaces for applications such as make, diff, FTP, shells, and debuggers. • Language-specific editing support. • Management of interaction with version control systems such as CVS, Perforce, SourceSafe, and StarTeam. • Implementation of Emacs itself—a substantial amount of Emacs is written in Emacs Lisp. And more... GNU Emacs Lisp Programming Slide 4 Copyright © 2001-2008 by William H. Mitchell A little history1 Lisp: John McCarthy is the father of Lisp. The name Lisp comes from LISt Processing Language. Initial ideas for Lisp were formulated in 1956-1958; some were implemented in FLPL (FORTRAN-based List Processing Language). The first Lisp implementation, for application to AI problems, took place 1958-1962 at MIT. There are many dialects of Lisp. Perhaps the most commonly used dialect is Common Lisp, which includes CLOS, the Common Lisp Object System. See http://www-formal.stanford.edu/jmc/history/lisp/lisp.html for some interesting details on the early history of Lisp. 1 Don't quote me! GNU Emacs Lisp Programming Slide 5 Copyright © 2001-2008 by William H.