Modeling and Intelligent Control of a Distillation Column
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Multicomponent Distillation
01/12/2009 Multicomponent distillation F. Grisafi 1 01/12/2009 Introduction The problem of determining the stage and reflux requitirements for multicomponen t distill a tions ismuch more complex than for binary mixtures. With a multicomponent mixture, fixing one component composition does not uniquely determine theother component compositions and the stage temperature. Also when the feed contains more than two components it is not possible to specify the complete composition of the top and bottom products independently. The separation between the top and bottom products is usually specified by setting limits on two "key components", between which it is desired to make the separation. 2 01/12/2009 Calculation procedure The normal procedure for a typical problem is to solve the MESH (Material balance, Equilibrium, Summation and Heat) balance equations stage-by-stage, from the top and bottom of the column toward the feed point. For such a calculation to be exact, the compositions obtained from both the bottom-up and top-down calculations must mesh at the feed point and mesh the feed composition. The calculated compositions will depend on the compositions assumed for the top and bottom products at the commencement of the calculations. Though it ispossibletomatch the key components, theother components will not match unless the designer was particularly fortunate in choosing the trial top and bottom compositions. 3 01/12/2009 Calculation procedure For a comppyletely rigorous solution the compositions must be adjusted and the calculations repeated until a satisfactory match at the feed point is obtained by iterative trial-and-error calculations. Clearly, the greater the number of components, the more difficult the problem. -

Example: Multicomponent Distillation with Shortcut Methods Consider A
2 Example: multicomponent distillation with shortcut methods Consider a single distillation column as shown in Fig. 6-1. Short-cut methods have been developed that allow you to see the splits that can be achieved at different pressures, with different reflux ratios, and with a different number of stages. It is often useful to do a short-cut distillation calculation first, before doing the more rigorous plate- to-plate calculations, because the preliminary calculations give you an idea of what is reasonable. The methods are based on the relative volatility of the chemicals, and require you to identify two components that will be essentially separated (to the extent you specify). If you line up all the components in the order of their boiling points, and draw a line between two of them, the more volatile component is called the light key and the less volatile component is called the heavy key. B1 Figure 6-1. Distillation Column For this example, you choose the first column in the process shown in Fig. 5-4. In Aspen Plus you use the module DSTWU for the shortcut method; you also use RK-Soave as the physical property method, because it is a good one for hydrocarbons. The feed is 100 lb. moles/hr of propane, 300 lb. moles/hr of i-butane, and the other chemicals as listed in Table 5-1 or Table 6-6, at 138 psia and 75 ºF. The column operates at 138 psia with a reflux ratio of 10 (a wild1 guess initially, confirmed because the column worked). -
Minimum Reflux Ratio
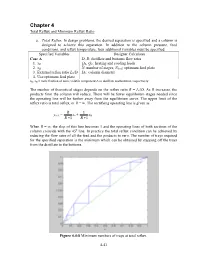
Chapter 4 Total Reflux and Minimum Reflux Ratio a. Total Reflux . In design problems, the desired separation is specified and a column is designed to achieve this separation. In addition to the column pressure, feed conditions, and reflux temperature, four additional variables must be specified. Specified Variables Designer Calculates Case A D, B: distillate and bottoms flow rates 1. xD QR, QC: heating and cooling loads 2. xB N: number of stages, Nfeed : optimum feed plate 3. External reflux ratio L0/D DC: column diameter 4. Use optimum feed plate xD, xB = mole fraction of more volatile component A in distillate and bottoms, respectively The number of theoretical stages depends on the reflux ratio R = L0/D. As R increases, the products from the column will reduce. There will be fewer equilibrium stages needed since the operating line will be further away from the equilibrium curve. The upper limit of the reflux ratio is total reflux, or R = ∞. The rectifying operating line is given as R 1 yn+1 = xn + xD R +1 R +1 When R = ∞, the slop of this line becomes 1 and the operating lines of both sections of the column coincide with the 45 o line. In practice the total reflux condition can be achieved by reducing the flow rates of all the feed and the products to zero. The number of trays required for the specified separation is the minimum which can be obtained by stepping off the trays from the distillate to the bottoms. Figure 4.4-8 Minimum numbers of trays at total reflux. -

Soft Matter Simulation Notes
Advanced Engineering Separations 2019-2020 Thomas Rodgers UG Notes Contents List of Figures vii List of Tables ix Nomenclature xi Course Information xiii 1 Industrial Separations1 1.1 Chapter1 ILOs...............................2 1.2 Introduction.................................3 1.3 Basic Separation Techniques........................3 1.4 Separations by Phase Addition or Creation.................5 1.5 Separations by Barriers........................... 11 1.6 Separations by Solid Agents........................ 14 1.7 Separations by External Field or Gradient................. 16 1.8 Component Recoveries........................... 19 1.8.1 Split Fractions and Split Ratios.................. 19 1.8.2 Separation Factor.......................... 19 1.9 References.................................. 20 1.10 Problems.................................. 21 2 Liquid-Liquid Extraction 27 2.1 Chapter2 ILOs............................... 28 2.2 Introduction................................. 29 2.2.1 Partition coefficient......................... 30 2.2.2 Solvent Selection.......................... 30 2.3 General Design Considerations....................... 32 2.4 Representation of Multi-phase Liquid-Liquid Systems........... 33 2.5 Single Stage Liquid-Liquid Extraction................... 34 2.6 Lever-Arm Rule............................... 36 2.7 Hunter-Nash Graphical Equilibrium-Stage Method............ 37 2.7.1 Step 1 - Calculation of the Mixing Point.............. 38 2.7.2 Step 2 - Product Mass Balance................... 38 2.7.3 Step 3 - Calculation of the Operating Lines............ 39 2.7.4 Step 4 - Tie Lines and Equilibrium Lines............. 40 2.8 Minimum and Maximum Solvent-to-Feed Flow-Rate Ratios....... 41 2.8.1 Minimum Ratio........................... 42 i 2.8.2 Maximum Ratio.......................... 42 2.9 Equipment for Solvent Extraction..................... 45 2.9.1 Mixer-Settlers............................ 45 2.9.2 Spray Columns........................... 46 2.9.3 Packed Columns.......................... 47 2.9.4 Plate Columns.......................... -

Distillation Column Selection and Sizing Rev: 03 Practical Engineering Guidelines for Processing Plant (ENGINEERING DESIGN GUIDELINES) Solutions Feb 2011
Page : 1 of 82 KLM Technology Group Rev: 03 Practical Engineering Rev 1 Feb 2007 Guidelines for Processing Plant Rev 2 April 2008 Solutions www.klmtechgroup.com Rev 3 Feb 2011 Author: KLM Technology Group Rev 1 Chew Yin Hoon #03-12 Block Aronia, Rev 2 Ai Li Ling Riverria Condovilla, Distillation Column Rev 3 Aprilia Jaya Taman Tampoi Utama Selection and Sizing Jalan Sri Perkasa 2 Checked by: 81200 Johor Bahru Malaysia (ENGINEERING DESIGN GUIDELINES) Karl Kolmetz TABLE OF CONTENTS INTRODUCTION Scope 6 Distillation 7 Distillation History 7 Types of Distillation Processes 9 Mode of Operation 10 Column Internals 11 Types of Distillation Column 15 A. Tray Column 15 A.1 Tray Hydraulic 18 B. Packed Column 21 B.1 Packed Hydraulic 23 General Design Consideration 26 The Selection of Column Internals 28 DEFINITIONS 34 This design guideline are believed to be as accurate as possible, but are very general not for specific design cases. They were designed for engineers to do preliminary designs and process specification sheets. The final design must always be guaranteed for the service selected by the manufacturing vendor, but these guidelines will greatly reduce the amount of up front engineering hours that are required to develop the final design. The guidelines are a training tool for young engineers or a resource for engineers with experience. This document is entrusted to the recipient personally, but the copyright remains with us. It must not be copied, reproduced or in any way communicated or made accessible to third parties without our written -

A Short-Cut Method for Predicting the Tot~ Reflux Performance of Distillation
A SHORT-CUT METHOD FOR PREDICTING THE TOT~ REFLUX PERFORMANCE OF DISTILLATION COLUMNS HANDLING THREE PHASE SYSTEMS By YUSUF HEKIM,, Bachelor of Science Middle East Technical University Ankara, Turkey 1971 Submitted to the Faculty of the Graduate College of the Oklahoma State University in partial fulfillment of the requirements for the Degree of MASTER OF SCIENCE December, 1973 OKLAHOMA STATE UNiVERSIT LIBRARY APR 10 1974 A SHORT-CUT METHOD FOR PREDICTING THE TOTAL REFLUX PERFORMANCE OF DISTILLATION COLUMNS HANDLING THREE PHASE SYSTEMS Thesis Approved: l~ Dean of the Graduate College 8'7721!t ii PREFACE This study was carried out to develop a short-cut method of pre dtcting the minimun number of theoretical trays in distillation columns operating on feeds which can exhibit partial miscibility. These systems are usually encountered in the organic chemical industry. The method was applied to one binary and two ternary systems which exhibit hetero geneous azeotropic behavior. The method was developed specifically for single feed, two product distillation columns; but it can be easily extended to describe the behavior of various complex column configura tions as multiple feeds and more than two products. This will lead to an increase in the computational time requirements. Description of the thermodynamic behavior of the systems handled was critical to the solution of this problem. The Renon Non Random Two Liquid method of predicting liquid phase activity coefficients coupled with the Prausnitz model for the vapor phase fugacity was found to be the most successful method for predicting the vapor-liquid-liquid equilibria constants. I would like to give my sincere appreciation to Prof. -

ACF Fall 2019 Packet by Delaware, MSU B, NYU A, UBC a Edited By
ACF Fall 2019 Packet by Delaware, MSU B, NYU A, UBC A Edited by Rahul Keyal, Ganon Evans, Justin French, Halle Friedman, Katherine Lei, Caroline Mao, Ben Miller, Tracy Mirkin, Clark Smith, Kevin Yu Tossups 1. Nationalists in this country believe in a conspiracy that numbers representing the Basmala were code for a Muslim coup. Alleged members of Ata Ullah’s “Faith Movement” in this country were targeted during the Inn Din massacre. This country replaced citizenship for Arakanese people with a National Verification Card. Ashin Wirathu (“WEE-rah-thoo”) and other Buddhist monks in the 969 (“nine-six-nine”) Movement attempted to classify a minority in this country as Bengali as justification for a mass exodus from its Rakhine (“ruh-KYNE”) State to Bangladesh. For 10 points, name this country where the National League of Democracy under Aung San Suu Kyi (“owng SAN soo CHEE”) opposes the forced migration of the Rohingya (“ro-HIN-jah”) people. ANSWER: Myanmar [or Burma; or Republic of the Union of Myanmar] <CE/Geo/Other/Pop Culture> 2. One method of analyzing this process involves finding the intersection of the Q line and two operating lines; that method is named for McCabe and Thiele (“TEEL-uh”). This process is equivalent to a series of flashes, and one can calculate an equivalent number of theoretical stages for this process using the Fenske equation. Some of the products of this process are returned to it in reflux. Vapor–liquid equilibrium is considered when designing apparatuses for this process, whose “fractional” form is used to refine petroleum. -

Establishing a Facility to Measure the Efficiency of Structured Packing Under Total Reflux
ESTABLISHING A FACILITY TO MEASURE THE EFFICIENCY OF STRUCTURED PACKING UNDER TOTAL REFLUX by Emil Friedrich Paquet Thesis presented in partial fulfillment of the requirements for the Degree of MASTER OF SCIENCE IN ENGINEERING (CHEMICAL ENGINEERING) in the Faculty of Engineering at Stellenbosch University Supervised by Prof. J.H. Knoetze March 2011 ii Abstract Structured packing is often the preferred choice for column internals because of its low pressure drop and high efficiencies compared to that of trays and random packing. However, the mass transfer phenomena in these gas-liquid contacting devices is still not well understood, even though it is widely used in industry. A contributing factor to this is the lack of understanding and availability of experimental data in the open literature. These shortcomings complicate the design of a distillation column and make practical experience essential. There is thus a need for more experimental data, especially for packings where only limited information is available. The focus of this study was to establish a testing facility that can be used to measure the efficiency of structured packing under total reflux, and not to measure vast quantities of experimental data; the latter will be done in future. The facilities available at Stellenbosch University limited the internal diameter of the column to 0.2 m, which is sufficient to test higher surface area structured packings (≥350 m 2/m 3). The column is used with a thermosyphon reboiler that uses steam as the heating source and is equipped with a total condenser. Two sections are used for the packed bed that allow for a total packed height of 3.78 m (2x1.89 m). -

Importance of Neem Tree
ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES ADDIS ABABA INSITUTE OF TECHNOLOGY DEPARTMENT OF CHEMICAL ENGINEERING EXTRACTION AND CHARACTERIZATION OF ESSENTIAL OIL FROM MARGOSA SEED ______________________________________________________________________________ By Wondesen Workneh JUNE 2011 ADDIS ABABA, ETHIOPIA ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES ADDIS ABABA INSITUTE OF TECHNOLOGY DEPARTMENT OF CHEMICAL ENGINEERING EXTRACTION AND CHARACTERIZATION OF ESSENTIAL OIL FROM MARGOSA SEED A thesis Submitted to the Research and Graduate School of Addis Ababa University, Addis Ababa Institute of Technology, Department of Chemical Engineering in partial fulfillment of the requirements for the attainment of the Degree of Masters of Science in Chemical Engineering under Process Engineering Stream. By: Wondesen Workneh Advisor: Dr. Ing Zebene Kiflie JUNE 2011 ADDIS ABABA, ETHIOPIA ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES ADDIS ABABA INSITUTE OF TECHNOLOGY DEPARTMENT OF CHEMICAL ENGINEERING EXTRACTION AND CHARACTERIZATION OF ESSENTIAL OIL FROM MARGOSA SEED A thesis submitted to the Research and Graduate School of Addis Ababa University, Addis Ababa Institute of Technology, Department of Chemical Engineering in partial fulfillment of the requirements for the attainment of the Degree of Masters of Science in Chemical Engineering under Process Engineering Stream. By: Wondesen Workneh Approved by the Examining Board: Chairman, Department’s Graduate committee Dr. Ing Zebene Kiflie Advisor Internal Examiner External Examiner Acknowledgments Praise to God the Most Merciful and Compassionate for giving me the strength in completing this research and thesis. First and foremost, I would like to express my appreciation to my advisor, Dr-ing Zebene Kiflie from Addis Ababa University, Addis Ababa Institute Technology (AAIT), Department of Chemical Engineering for supervision, advice, guidance and patience throughout my research. -

Module 5: Distillation
NPTEL – Chemical – Mass Transfer Operation 1 MODULE 5: DISTILLATION LECTURE NO. 1 5.1. Introduction Distillation is method of separation of components from a liquid mixture which depends on the differences in boiling points of the individual components and the distributions of the components between a liquid and gas phase in the mixture. The liquid mixture may have different boiling point characteristics depending on the concentrations of the components present in it. Therefore, distillation processes depends on the vapor pressure characteristics of liquid mixtures. The vapor pressure is created by supplying heat as separating agent. In the distillation, the new phases differ from the original by their heat content. During most of the century, distillation was by far the most widely used method for separating liquid mixtures of chemical components (Seader and Henley, 1998). This is a very energy intensive technique, especially when the relative volatility of the components is low. It is mostly carried out in multi tray columns. Packed column with efficient structured packing has also led to increased use in distillation. 5.1.1. Vapor Pressure Vapor Pressure: The vaporization process changes liquid to gaseous state. The opposite process of this vaporization is called condensation. At equilibrium, the rates of these two processes are same. The pressure exerted by the vapor at this equilibrium state is termed as the vapor pressure of the liquid. It depends on the temperature and the quantity of the liquid and vapor. From the following Clausius-Clapeyron Equation or by using Antoine Equation, the vapor pressure can be calculated. Joint initiative of IITs and IISc – Funded by MHRD Page 1 of 9 NPTEL – Chemical – Mass Transfer Operation 1 Clausius-Clapeyron Equation: pv 1 1 ln (5.1) v p1 R T1 T v v where p and p1 are the vapor pressures in Pascal at absolute temperature T and T1 in K. -

87 Case Study on Mul
[Thirumalesh*, 4.(8): August, 2015] ISSN: 2277-9655 (I2OR), Publication Impact Factor: 3.785 IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY CASE STUDY ON MULTICOMPONENT DISTILLATION AND DISTILLATION COLUMN SEQUENCING Thirumalesh. B.S*, Ramesh.V * Assistant Professor Department of Chemical Engineering,Dayananda Sagar College of Engineering,Bangalore, Karnataka, India. Department of Chemical Engineering,Dayananda Sagar College of Engineering, Bangalore, Karnataka, India. ABSTRACT The objective of this work is to design a multi-component distillation column for the given organic mixture, sequencing of a multi-component distillation column to choose the best sequence. Fractionation of multi-component mixtures into top and side stream products depends on the relative volatility of the organic mixture under consideration. As the mixture consists of more than one component with specific true boiling point (TBP), its relative volatility can be calculated using Antoine’s equation. In this method the component with the lowest relative volatility at the top above the feed tray was designated as a light key component (LK) and the highest volatility at the bottom, below the feed plate are designated as the heavy key component (HK). Based on these data, the column is designed. Short cut methods involving Fenske’s equation, Underwood equation and Gilliland equations, popularly known as the FUG method are employed for the calculations. A simple heuristic method for the systematic synthesis of initial sequences for Multi-component separations is employed here to determine the best sequence. Therefore the sequence with the least vapour load in turn results in low energy demand, thereby forming the best sequence for the designing of a distillation column for a given organic mixture keeping in mind the economic conditions. -
Minimum Number of Trays for Multi- Component Distillation at Total Reflux
ISSN: 2319-5967 ISO 9001:2008 Certified International Journal of Engineering Science and Innovative Technology (IJESIT) Volume 5, Issue 5, September 2016 Manual determination of the number of theoretical plates by MCCAB-Theil and by using MATLAB KAMAL. M. HAMID, Prof. G. A. GESMALSEED, Dr. ATIF ABDELRAHIM Abstract: Determination of the number of theoretical stages in stage wise distillation is rather important for the design of a fractionator’s column. There are many graphical and empirical correlations for the determination of the theoretical stages, among these methods, is the graphical method of MCcabe-theile which is reliable. In a recent work by Gasmelsed G. A. etal it is approved that McCabe-Theile can be used for multi component fractionation, taking the light and heavy keys as pseudo binary. McCabe-Thiele method requires the condition of the feed , the equilibrium data or relationship , the composition of the feed , top and bottom products mol fractions as well as the q – line. In this paper the number of theoretical stage were plotted manually by McCabe-Theile method and by software using MATLAB. The results of the number of stage were compared and found to by in a agreement. It is recommended that MATLAB software program has to be extended for a complete design of the fractionation column. Keywords: Binary, Pseudo system, McCabe-Theile, Matlab. I. INTRODUCTION Distillation columns used to separate a mixture of 2 liquids or more depending on their relative volatility it is important to estimate the number of the stages that needed for pure distillate. Fig (1) A Distillation column II.