Using Reinforcement Learning to Evaluate Player Pair Performance in Ice Hockey
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Head Coach, Tampa Bay Lightning
Table of Contents ADMINISTRATION Team History 270 - 271 All-Time Individual Record 272 - 274 Company Directory 4 - 5 All-Time Team Records 274 - 279 Executives 6 - 11 Scouting Staff 11 - 12 Coaching Staff 13 - 16 PLAYOFF HISTORY & RECORDS Hockey Operations 17 - 20 All-Time Playoff Scoring 282 Broadcast 21 - 22 Playoff Firsts 283 All-Time Playoff Results 284 - 285 2013-14 PLAYER ROSTER Team Playoff Records 286 - 287 Individual Playoff Records 288 - 289 2013-14 Player Roster 23 - 98 Minor League Affiliates 99 - 100 MISCELLANEOUS NHL OPPONENTS In the Community 292 NHL Executives 293 NHL Opponents 109 - 160 NHL Officials and Referees 294 Terms Glossary 295 2013-14 SEASON IN REVIEW Medical Glossary 296 - 298 Broadcast Schedule 299 Final Standings, Individual Leaders, Award Winners 170 - 172 Media Regulations and Policies 300 - 301 Team Statistics, Game-by-Game Results 174 - 175 Frequently Asked Questions 302 - 303 Home and Away Results 190 - 191 Season Summary, Special Teams, Overtime/Shootout 176 - 178 Highs and Lows, Injuries 179 Win / Loss Record 180 HISTORY & RECORDS Season Records 182 - 183 Special Teams 184 Season Leaders 185 All-Time Records 186 - 187 Last Trade With 188 Records vs. Opponents 189 Overtime/Shootout Register 190 - 191 Overtime History 192 Year by Year Streaks 193 All-Time Hat Tricks 194 All-Time Attendance 195 All-Time Shootouts & Penalty Shots 196-197 Best and Worst Record 198 Season Openers and Closers 199 - 201 Year by Year Individual Statistics and Game Results 202 - 243 All-Time Lightning Preseason Results 244 All-Time -
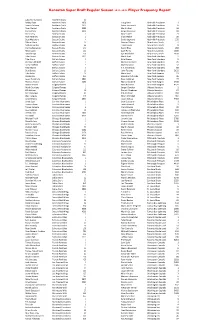
Super Draft Frequency.Xlsx
Kenaston Super Draft Regular Season 2011-2012 Player Frequency Report Lubomir Visnovsky Anaheim Ducks 47 Bobby Ryan Anaheim Ducks 1858 Craig Smith Nashville Predators 1 Teemu Selanne Anaheim Ducks 2410 Patric Hornqvist Nashville Predators 6 Ryan Getzlaf Anaheim Ducks 5089 Martin Erat Nashville Predators 16 Corey Perry Anaheim Ducks 5366 Sergei Kostitsyn Nashville Predators 19 Chris Kelly Boston Bruins 1 Mike Fisher Nashville Predators 21 Rich Peverley Boston Bruins 2 Shea Weber Nashville Predators 26 Brad Marchand Boston Bruins 4 David Legwand Nashville Predators 232 Zdeno Chara Boston Bruins 14 Dainius Zubrus New Jersey Devils 2 Nathan Horton Boston Bruins 60 Travis Zajac New Jersey Devils 8 Patrice Bergeron Boston Bruins 142 Patrik Elias New Jersey Devils 266 Milan Lucic Boston Bruins 144 Zach Parise New Jersey Devils 2189 David Krejci Boston Bruins 150 Ilya Kovalchuk New Jersey Devils 3100 Tyler Seguin Boston Bruins 1011 Mark Streit New York Islanders 2 Tyler Ennis Buffalo Sabres 1 Kyle Okposo New York Islanders 5 Christian Ehrhoff Buffalo Sabres 3 Michael Grabner New York Islanders 25 Drew Stafford Buffalo Sabres 5 Matt Moulson New York Islanders 32 Tyler Myers Buffalo Sabres 9 P.A. Parenteau New York Islanders 58 Brad Boyes Buffalo Sabres 10 John Tavares New York Islanders 5122 Luke Adam Buffalo Sabres 10 Marc Staal New York Rangers 11 Derek Roy Buffalo Sabres 253 Brandon Dubinsky New York Rangers 26 Jason Pominville Buffalo Sabres 2893 Ryan Callahan New York Rangers 77 Thomas Vanek Buffalo Sabres 5280 Marian Gaborik New York Rangers -

Our Online Shop Offers Outlet Nike Football Jersey,Authentic New Nike Jerseys,China Wholesale Cheap Football Jersey,Cheap NHL Je
Our online shop offers Outlet Nike Football Jersey,Authentic new nike jerseys,China wholesale cheap football jersey,Cheap NHL Jerseys.Cheap price and good quality,IF you want to buy good jerseys,click here,Cardinals Jerseys,football jersey creator!Were going to pick up the pace on the NFC South position rankings as we approximate the end We looked along fixed ends Thursday morning and,swiftly were going to transfer onto the broad receivers. In terms of overall strength,nike nfl jersey,new nfl uniforms nike, Id say this position is an of the better ones within the division. But theres a big contention between the Saints,baseball jersey custom, who have a bunch of agreeable receivers to the Panthers,baseball jersey numbers,boise state football jersey, who have only an proven commodity,design your own nfl jersey, to the Buccaneers,nike 2012 nfl, who have lots of potential merely no sure things. On to the rankings. [+] EnlargeKevin C. Cox/Getty ImagesSteve Smith led the Panthers with 982 receiving yards last season.Steve Smith,mlb all star jersey, Panthers. There were three guys among the contest and the other two had better numbers than Smith last annual But Im playing a hunch that Smith will have a monster season,reversible basketball jerseys, even notwithstanding the Panthers have some uncertainty along quarterback. Im basing this aboard my theory that Smith,make your own nfl jersey, always a high-energy companion,vintage nhl jersey,will be extra motivated than ever after simmering on the sidelines throughout training camp meantime reviving from a broken arm. -

Sport-Scan Daily Brief
SPORT-SCAN DAILY BRIEF NHL 06/28/19 Anaheim Ducks Detroit Red Wings 1148559 Ducks coach Dallas Eakins reaching out to veteran 1148587 Why this Detroit Red Wings goalie prospect is so highly players to forge bonds regarded 1148588 Ethan Phillips has special connection to a Detroit Red Arizona Coyotes Wings legend 1148560 Scottsdale native Erik Middendorf gets call to join Arizona 1148589 Smallish Otto Kivenmaki makes big strides in dream to Coyotes camp make Red Wings 1148590 Howe, Yzerman-themed cranes helping with Joe Louis Boston Bruins Arena's demo 1148561 Oskar Steen may now be a better fit with Bruins 1148591 Red Wings ‘goalie of the future’ Filip Larsson prepares for 1148562 Jakub Lauko is ready to make an impact with Bruins Grand Rapids 1148563 Bruins notebook: Undrafted free agents see Boston as a 1148592 Red Wings free agency primer: Who fits Detroit’s destination direction? 1148564 Jack Studnicka, top Bruins prospect, ready to fight for a job Edmonton Oilers 1148565 Report: Bruins still in the mix for Marcus Johansson, 1148593 Will we see Bouchard, Samorukov and Broberg anchoring though several teams have expressed interest D down road? 1148566 Boston Bruins Development Camp: Day 2 thoughts and observations Florida Panthers 1148567 Could Oskar Steen be a dark horse forward candidate for 1148594 The Panthers are holding their annual development camp. Bruins this season? Here’s why you need to know 1148568 Next ace chase: The Bruins hope they already have 1148595 Goalie of future Spencer Knight hits ice for Panthers Tuukka Rask’s -

San Jose Sharks Vs. Tampa Bay Lightning
San Jose Sharks!! Wednesday, December 21st vs. Tampa Bay Lightning!!! Scouts and Scout Leaders, our fourth Scout Night of the season has already sold out so we would like to offer Dec. 21st as well! vs. Your San Jose Sharks including Joe Thornton, Patrick Marleau and Dan Boyle will take on Steven Stamkos and the Tampa Bay Lightning! So come out and support your San Jose Sharks by taking advantage of this special offer! Exclusive Girls and Boys Scout Offer Wednesday, Dec. 21st @ 7:30 PM! Special discounted ticket to the game, no Ticketmaster fees! Commemorative Scout Patch pictured left! Tickets priced at $55 (red), $45 (tan) and $38 (yellow)**! Save up to $25+ per ticket!!!!! Groups of 25+ get a video board announcement! **For upper reserve sideline and end goalie view seats in the red, tan and yellow sections. Paste the link here into your browser for a seating/pricing map! http://sharks.nhl.com/club/page.htm?id=46597 How many patches will you need? ______ A portion of the proceeds benefit the Girl Scouts of Northern California! These special discounts available for Scouts, their families, & friends. Orders must be paid with VISA, MasterCard, American Express or by check payable to the San Jose Sharks. Your order will be filled with the best available seats at the time your order is processed, and tickets will be placed at Will Call under the name listed below for pick up on the day of the event. Orders must be received by 5:00pm, Friday, December 16th. San Jose Sharks vs. -

Turnbull Hockey Pool For
Turnbull Hockey Pool for Each year, Turnbull students participate in several fundraising initiatives, which we promote as a way to develop a sense of community, leadership and social responsibility within the students. Last year's grade 7 and 8 students put forth a great deal of effort campaigning friends and family members to join Turnbull's annual NHL hockey pool, raising a total of $1750 for a charity of their choice (the United Way). This year's group has decided to run the hockey pool for the benefit of Help Lesotho, an international development organization working in the AIDS-ravaged country of Lesotho in southern Africa. From www.helplesotho.org "Help Lesotho’s programs foster hope and motivation in those who are most in need: orphans, vulnerable children, at-risk youth and grandmothers. Our work targets root causes and community priorities, including literacy, youth leadership training, school twinning, child sponsorship and gender programming. Help Lesotho is an effective, sustainable organization that is working at the grass-roots level to support the next generation of leaders in Lesotho." Your participation in this year's NHL hockey pool is very much appreciated. We believe it will provide students and their friends and families an opportunity to have fun together while giving back to their community by raising awareness and funds for a great cause. Prizes: > Grand Prize awarded to contestant whose team accumulates the most points over the regular NHL season = 10" Samsung Galaxy Tablet > Monthly Prizes awarded to the contestants whose teams accumulate the most points over each designated period (see website) = Two Movie Passes How it Works: > Everyone in the community is welcome to join in on the fun. -

NHL Playoffs PDF.Xlsx
Anaheim Ducks Boston Bruins POS PLAYER GP G A PTS +/- PIM POS PLAYER GP G A PTS +/- PIM F Ryan Getzlaf 74 15 58 73 7 49 F Brad Marchand 80 39 46 85 18 81 F Ryan Kesler 82 22 36 58 8 83 F David Pastrnak 75 34 36 70 11 34 F Corey Perry 82 19 34 53 2 76 F David Krejci 82 23 31 54 -12 26 F Rickard Rakell 71 33 18 51 10 12 F Patrice Bergeron 79 21 32 53 12 24 F Patrick Eaves~ 79 32 19 51 -2 24 D Torey Krug 81 8 43 51 -10 37 F Jakob Silfverberg 79 23 26 49 10 20 F Ryan Spooner 78 11 28 39 -8 14 D Cam Fowler 80 11 28 39 7 20 F David Backes 74 17 21 38 2 69 F Andrew Cogliano 82 16 19 35 11 26 D Zdeno Chara 75 10 19 29 18 59 F Antoine Vermette 72 9 19 28 -7 42 F Dominic Moore 82 11 14 25 2 44 F Nick Ritchie 77 14 14 28 4 62 F Drew Stafford~ 58 8 13 21 6 24 D Sami Vatanen 71 3 21 24 3 30 F Frank Vatrano 44 10 8 18 -3 14 D Hampus Lindholm 66 6 14 20 13 36 F Riley Nash 81 7 10 17 -1 14 D Josh Manson 82 5 12 17 14 82 D Brandon Carlo 82 6 10 16 9 59 F Ondrej Kase 53 5 10 15 -1 18 F Tim Schaller 59 7 7 14 -6 23 D Kevin Bieksa 81 3 11 14 0 63 F Austin Czarnik 49 5 8 13 -10 12 F Logan Shaw 55 3 7 10 3 10 D Kevan Miller 58 3 10 13 1 50 D Shea Theodore 34 2 7 9 -6 28 D Colin Miller 61 6 7 13 0 55 D Korbinian Holzer 32 2 5 7 0 23 D Adam McQuaid 77 2 8 10 4 71 F Chris Wagner 43 6 1 7 2 6 F Matt Beleskey 49 3 5 8 -10 47 D Brandon Montour 27 2 4 6 11 14 F Noel Acciari 29 2 3 5 3 16 D Clayton Stoner 14 1 2 3 0 28 D John-Michael Liles 36 0 5 5 1 4 F Ryan Garbutt 27 2 1 3 -3 20 F Jimmy Hayes 58 2 3 5 -3 29 F Jared Boll 51 0 3 3 -3 87 F Peter Cehlarik 11 0 2 2 -

Player Pairs Valuation in Ice Hockey
Player pairs valuation in ice hockey Dennis Ljung Niklas Carlsson Patrick Lambrix Link¨opingUniversity, Sweden Abstract. To overcome the shortcomings of simple metrics for evalu- ating player performance, recent works have introduced more advanced metrics that take into account the context of the players' actions and per- form look-ahead. However, as ice hockey is a team sport, knowing about individual ratings is not enough and coaches want to identify players that play particularly well together. In this paper we therefore extend earlier work for evaluating the performance of players to the related problem of evaluating the performance of player pairs. We experiment with data from seven NHL seasons, discuss the top pairs, and present analyses and insights based on both the absolute and relative ice time together. Keywords: Sports analytics · Data mining · Player valuation. 1 Introduction In the field of sports analytics, many works focus on evaluating the performance of players. A commonly used method to do this is to attribute values to the different actions that players perform and sum up these values every time a player performs these actions. These summary statistics can be computed over, for instance, games or seasons. In ice hockey, common summary metrics include the number of goals, assists, points (assists + goals) and the plus-minus statistics (+/-), in which 1 is added when the player is on the ice when the player's team scores (during even strength play) and 1 is subtracted when the opposing team scores (during even strength). More advanced measures are, for instance, Corsi and Fenwick1. However, these metrics do not capture the context of player actions and the impact they have on the outcome of later actions. -

Sport-Scan Daily Brief
SPORT-SCAN DAILY BRIEF NHL 05/30/19 Anaheim Ducks Boston Bruins cont'd 1145579 Ducks’ slow-moving coaching search appears to be 1145616 ‘I wasn’t good the last two games’: Brad Marchand and picking up steam linemates flame out in Game 2 1145580 What’s taking the Ducks so long to hire a head coach? It’s 1145617 Boston fans may see something familiar in St. Louis’ gritty, a ‘mystery’ says a league exec plucky, underdog comeback 1145618 The brotherly bond uniting Steve and Bruce Cassidy Arizona Coyotes grows as the Cup draws closer 1145581 Dave Tippett to coach Edmonton Oilers, but can he replicate his success with the Coyotes Buffalo Sabres 1145582 Former Coyotes coach Dave Tippett named Oilers head 1145619 On a night of heavy hockey, a different No. 4 in Boston coach produces win No. 1 for Blues in Cup final 1145620 Wild journey for Bruins' Connor Clifton began at Sabres Boston Bruins Prospect Challenge 1145583 Joakim Nordstrom’s best effort was impressive, but 1145621 Zdeno Chara on Ralph Krueger, evolving in his 40s and ... wasted in a loss Tom Brady 1145584 In the end, the Bruins had nothing left in the tank 1145622 Five Things to Know as Blues, Bruins meet in Game 2 of 1145585 The Bruins ‘didn’t have as much energy’ on offense, and it Stanley Cup final cost them 1145623 What Ralph Krueger's player usage in Edmonton can tell 1145586 All of a sudden we’ve got a series between Bruins and us Blues 1145624 Putting the ‘tank’ on trial: How the Sabres’ last six years 1145587 Matt Grzelcyk leaves game after hit from behind compare to teams who went through a similar proces 1145588 Bruins rally towels for Game 2 include a Barstool Sports logo. -

What Is the Value of an Action in Ice Hockey? Learning a Q-Function for the NHL
What is the Value of an Action in Ice Hockey? Learning a Q-function for the NHL Oliver Schulte, Zeyu Zhao, and Kurt Routley Simon Fraser University, Burnaby, BC, Canada {oschulte}@cs.sfu.ca Abstract. Recent work has applied the Markov Game formalism from AI to model game dynamics for ice hockey, using a large state space. Dy- namic programming is used to learn action-value functions that quantify the impact of actions on goal scoring. Learning is based on a massive dataset that contains over 2.8M events in the National Hockey League. As an application of the Markov model, we use the learned action val- ues to measure the impact of player actions on goal scoring. Players are ranked according to the aggregate goal impact of their actions. We show that this ranking is consistent across across seasons, and compare it with previous player metrics, such as plus-minus and total points. 1 Introduction This paper describes and extends a recent approach to sports analytics that applies advanced concepts from Artificial Intelligence to model game dynamics. This approach models game dynamics using Markov games [4], a multi-agent extension of Markov Decision Processes. A Markov game model can answer a fundamental question about a sport: Which actions contribute to winning in what situation? We approach this question for ice hockey by learning an action-value func- tion, or Q-function, for a Markov game model of the National Hockey League (NHL). In reinforcement learning (RL) notation, the expression Q(s; a) denotes the expected reward of taking action a in state s. -

Forbes Magazine Has Ranked Edge Sports Management As One of the Top Ten Hockey Agencies in the World
Forbes Magazine has ranked Edge Sports Management as one of the top ten hockey agencies in the world. Edge Sports Management is a full service firm dedicated to advising and representing hockey players at every stage of their careers and lives. We have had extensive experience and success in advising players to enhance their draft status. We have also been successful in securing top contracts for players that have gone undrafted. We have negotiated “salary cap” contracts for drafted and undrafted entry level players; been very successful in salary arbitration; have procured excellent contracts for NHL free agents; and negotiated some of the largest contracts in the history of the National Hockey League. No matter what contractual situation a player is in, Edge Sports Management has been there before, and our clients can rely on our experience and expertise to negotiate a successful result. What distinguishes us from most agencies is that we pride ourselves on being personally accessible to players and their families at all times. We realize and embrace the fact that our responsibilities to our clients go far beyond simply negotiating a contract. We are there to help our players and their families at every stage of their lives, and in any situation that they may need assistance. To us, there is nothing more rewarding than helping a client achieve success on the ice, while knowing that he and his family are taken care of in all aspects of life. Who We Are We have over 30 years of experience, and have negotiated hundreds of millions dollars worth of contracts. -

Carl Gunnarsson Brief
2013 HOCKEY ARBITRATION COMPETITION OF CANADA Toronto Maple Leafs v Carl Gunnarsson Brief Submitted on Behalf of the Toronto Maple Leafs Team 31 Table of Contents Introduction………………………………………………………………………………………1 Overall Performance of the Player……………………………………………………………...1 Number of Games Played and Injury History…………………………………………………2 Length of Service in the NHL and with the Club……………………………………………...3 Overall Contribution to the Club……………………………………………………………….3 Special Qualities of Leadership or Public Appeal……………………………………………..4 Comparable Players……………………………………………………………………………..4 A) Anton Stralman………………………………………………………………………………5 B) Ryan Wilson…………………………………………………………………………………..6 Valuation & Conclusion…………………………………………………………………………7 Introduction This brief is in regards to the past performance of Mr. Carl Gunnarsson (the “Player”) of the Toronto Maple Leafs (the “Club”) for the matter of salary arbitration pursuant to Article 12.1(a) of the 2013 Collective Bargaining Agreement (the “CBA”) between the National Hockey League (the “NHL”) and the National Hockey League’s Players Association (the “NHLPA”). The CBA states seven categories of evidence that are admissible in salary arbitration cases in section 12.9(g)(ii): the overall performance of the player in previous seasons; the number of games played in previous seasons and any injuries or illnesses; the length of service of the player in the NHL and/or with the Club; the overall contribution of the player to the Club’s competitive success or failure; any special qualities of leadership or public appeal; the overall performance of any player(s) alleged to be comparable to the Player and the compensation of any players alleged to be comparable. As we will show in this brief, Mr. Gunnarsson, due to the above factors, should be compensated with a salary of $2,500,000.