What Is the Value of an Action in Ice Hockey? Learning a Q-Function for the NHL
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Head Coach, Tampa Bay Lightning
Table of Contents ADMINISTRATION Team History 270 - 271 All-Time Individual Record 272 - 274 Company Directory 4 - 5 All-Time Team Records 274 - 279 Executives 6 - 11 Scouting Staff 11 - 12 Coaching Staff 13 - 16 PLAYOFF HISTORY & RECORDS Hockey Operations 17 - 20 All-Time Playoff Scoring 282 Broadcast 21 - 22 Playoff Firsts 283 All-Time Playoff Results 284 - 285 2013-14 PLAYER ROSTER Team Playoff Records 286 - 287 Individual Playoff Records 288 - 289 2013-14 Player Roster 23 - 98 Minor League Affiliates 99 - 100 MISCELLANEOUS NHL OPPONENTS In the Community 292 NHL Executives 293 NHL Opponents 109 - 160 NHL Officials and Referees 294 Terms Glossary 295 2013-14 SEASON IN REVIEW Medical Glossary 296 - 298 Broadcast Schedule 299 Final Standings, Individual Leaders, Award Winners 170 - 172 Media Regulations and Policies 300 - 301 Team Statistics, Game-by-Game Results 174 - 175 Frequently Asked Questions 302 - 303 Home and Away Results 190 - 191 Season Summary, Special Teams, Overtime/Shootout 176 - 178 Highs and Lows, Injuries 179 Win / Loss Record 180 HISTORY & RECORDS Season Records 182 - 183 Special Teams 184 Season Leaders 185 All-Time Records 186 - 187 Last Trade With 188 Records vs. Opponents 189 Overtime/Shootout Register 190 - 191 Overtime History 192 Year by Year Streaks 193 All-Time Hat Tricks 194 All-Time Attendance 195 All-Time Shootouts & Penalty Shots 196-197 Best and Worst Record 198 Season Openers and Closers 199 - 201 Year by Year Individual Statistics and Game Results 202 - 243 All-Time Lightning Preseason Results 244 All-Time -

Turnbull Hockey Pool For
Turnbull Hockey Pool for Each year, Turnbull students participate in several fundraising initiatives, which we promote as a way to develop a sense of community, leadership and social responsibility within the students. Last year's grade 7 and 8 students put forth a great deal of effort campaigning friends and family members to join Turnbull's annual NHL hockey pool, raising a total of $1750 for a charity of their choice (the United Way). This year's group has decided to run the hockey pool for the benefit of Help Lesotho, an international development organization working in the AIDS-ravaged country of Lesotho in southern Africa. From www.helplesotho.org "Help Lesotho’s programs foster hope and motivation in those who are most in need: orphans, vulnerable children, at-risk youth and grandmothers. Our work targets root causes and community priorities, including literacy, youth leadership training, school twinning, child sponsorship and gender programming. Help Lesotho is an effective, sustainable organization that is working at the grass-roots level to support the next generation of leaders in Lesotho." Your participation in this year's NHL hockey pool is very much appreciated. We believe it will provide students and their friends and families an opportunity to have fun together while giving back to their community by raising awareness and funds for a great cause. Prizes: > Grand Prize awarded to contestant whose team accumulates the most points over the regular NHL season = 10" Samsung Galaxy Tablet > Monthly Prizes awarded to the contestants whose teams accumulate the most points over each designated period (see website) = Two Movie Passes How it Works: > Everyone in the community is welcome to join in on the fun. -

Player Pairs Valuation in Ice Hockey
Player pairs valuation in ice hockey Dennis Ljung Niklas Carlsson Patrick Lambrix Link¨opingUniversity, Sweden Abstract. To overcome the shortcomings of simple metrics for evalu- ating player performance, recent works have introduced more advanced metrics that take into account the context of the players' actions and per- form look-ahead. However, as ice hockey is a team sport, knowing about individual ratings is not enough and coaches want to identify players that play particularly well together. In this paper we therefore extend earlier work for evaluating the performance of players to the related problem of evaluating the performance of player pairs. We experiment with data from seven NHL seasons, discuss the top pairs, and present analyses and insights based on both the absolute and relative ice time together. Keywords: Sports analytics · Data mining · Player valuation. 1 Introduction In the field of sports analytics, many works focus on evaluating the performance of players. A commonly used method to do this is to attribute values to the different actions that players perform and sum up these values every time a player performs these actions. These summary statistics can be computed over, for instance, games or seasons. In ice hockey, common summary metrics include the number of goals, assists, points (assists + goals) and the plus-minus statistics (+/-), in which 1 is added when the player is on the ice when the player's team scores (during even strength play) and 1 is subtracted when the opposing team scores (during even strength). More advanced measures are, for instance, Corsi and Fenwick1. However, these metrics do not capture the context of player actions and the impact they have on the outcome of later actions. -
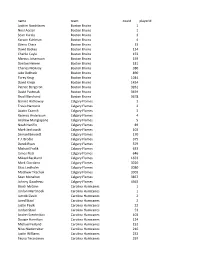
2019 Playoff Draft Player Frequency Report
name team count playerid Joakim Nordstrom Boston Bruins 1 Noel Acciari Boston Bruins 1 Sean Kuraly Boston Bruins 3 Karson Kuhlman Boston Bruins 4 Zdeno Chara Boston Bruins 13 David Backes Boston Bruins 134 Charlie Coyle Boston Bruins 153 Marcus Johansson Boston Bruins 159 Danton Heinen Boston Bruins 181 Charles McAvoy Boston Bruins 380 Jake DeBrusk Boston Bruins 890 Torey Krug Boston Bruins 1044 David Krejci Boston Bruins 1434 Patrice Bergeron Boston Bruins 3261 David Pastrnak Boston Bruins 3459 Brad Marchand Boston Bruins 3678 Garnet Hathaway Calgary Flames 2 Travis Hamonic Calgary Flames 2 Austin Czarnik Calgary Flames 3 Rasmus Andersson Calgary Flames 4 Andrew Mangiapane Calgary Flames 5 Noah Hanifin Calgary Flames 89 Mark Jankowski Calgary Flames 102 Samuel Bennett Calgary Flames 170 T.J. Brodie Calgary Flames 375 Derek Ryan Calgary Flames 379 Michael Frolik Calgary Flames 633 James Neal Calgary Flames 646 Mikael Backlund Calgary Flames 1653 Mark Giordano Calgary Flames 3020 Elias Lindholm Calgary Flames 3080 Matthew Tkachuk Calgary Flames 3303 Sean Monahan Calgary Flames 3857 Johnny Gaudreau Calgary Flames 4363 Brock McGinn Carolina Hurricanes 1 Jordan Martinook Carolina Hurricanes 1 Jaccob Slavin Carolina Hurricanes 2 Jared Staal Carolina Hurricanes 2 Justin Faulk Carolina Hurricanes 22 Jordan Staal Carolina Hurricanes 53 Andrei Svechnikov Carolina Hurricanes 103 Dougie Hamilton Carolina Hurricanes 124 Michael Ferland Carolina Hurricanes 152 Nino Niederreiter Carolina Hurricanes 216 Justin Williams Carolina Hurricanes 232 Teuvo Teravainen Carolina Hurricanes 297 Sebastian Aho Carolina Hurricanes 419 Nikita Zadorov Colorado Avalanche 1 Samuel Girard Colorado Avalanche 1 Matthew Nieto Colorado Avalanche 1 Cale Makar Colorado Avalanche 2 Erik Johnson Colorado Avalanche 2 Tyson Jost Colorado Avalanche 3 Josh Anderson Colorado Avalanche 14 Colin Wilson Colorado Avalanche 14 Matt Calvert Colorado Avalanche 14 Derick Brassard Colorado Avalanche 28 J.T. -

Official Training Centre Presents Marcin Snita Back
OFFICIAL TRAINING CENTRE PRESENTS MARCIN SNITA Limited BACK IN SUDBURY spots January 27-February 7, 2014 POWERED BY GATORADE Due to popular demand Marcin Snita will be back in Sudbury to train players of all levels. Marcin is a dynamic individual with 18 plus years of hockey experience and very strong training expertise. Marcin founded MOVE HOCKEY in 2008 and is dedicated to bringing continuous innovation and development within the game of hockey. “ Marcin has been a big part of my hockey development as a hockey player over the past 9 years. .. Marcin has helped me develop my skating agility and puck handling skills while maintaining a fun attitude. His unique drills and teaching techniques keep me on my toes and wanting more. Marcin’s hockey school is definitely a great place to have fun while gaining confidence and improving your game.” (Steven Stamkos, 1st Overall Tampa Bay Lightning (NHL) ) As Founder and Head Trainer at MOVE HOCKEY for the last 5 years, Marcin has: • conducted camps in: Montreal, Fredericton, Halifax, Syracuse, Sudbury (RHP), Sault Ste. Marie (RHP) • Is Pro Trainer for UNB Reds, CIS National Champions 2009, 2011, 2013 • Is Exclusive Trainer for AAA Stallions 2003, 2004, 2005, 2006 Teams • Is Trainer and Head Coach AAA Crusaders 2000 Team • Works with the Czech Republic Under 16/18 National Team Marcin has trained over 30 NHL, 100 CHL and 40 European Players. Learn to: Stickhandle like Jason Spezza, NHL, Ottawa Senators Persevere like Bryan Bickell, NHL, Chicago Blackhawks Shoot like Steven Stamkos, NHL, Tampa Bay -

Tampa Bay Lightning Game Notes
Tampa Bay Lightning Game Notes Thu, Feb 14, 2019 NHL Game #880 Tampa Bay Lightning 42 - 11 - 4 (88 pts) Dallas Stars 29 - 22 - 5 (63 pts) Team Game: 58 22 - 5 - 2 (Home) Team Game: 57 18 - 8 - 2 (Home) Home Game: 30 20 - 6 - 2 (Road) Road Game: 29 11 - 14 - 3 (Road) # Goalie GP W L OT GAA SV% # Goalie GP W L OT GAA SV% 70 Louis Domingue 22 18 4 0 2.90 .907 35 Anton Khudobin 25 10 10 3 2.34 .927 88 Andrei Vasilevskiy 34 23 7 4 2.45 .925 41 Landon Bow 1 0 0 0 0.00 1.00 0 # P Player GP G A P +/- PIM # P Player GP G A P +/- PIM 5 D Dan Girardi 52 3 9 12 5 10 2 D Jamie Oleksiak 43 4 7 11 6 41 6 D Anton Stralman 37 2 13 15 10 8 3 D John Klingberg 38 7 20 27 9 10 7 R Mathieu Joseph 48 13 7 20 7 12 4 D Miro Heiskanen 56 10 15 25 -8 10 9 C Tyler Johnson 55 19 16 35 9 20 5 D Connor Carrick 13 1 3 4 -6 13 10 C J.T. Miller 51 9 23 32 1 12 6 D Julius Honka 29 0 4 4 -2 10 13 C Cedric Paquette 56 9 4 13 5 58 12 C Radek Faksa 56 9 11 20 -10 35 17 L Alex Killorn 57 11 17 28 15 35 13 C Mattias Janmark 56 5 14 19 -5 18 18 L Ondrej Palat 39 7 14 21 1 12 14 L Jamie Benn 55 19 20 39 10 44 21 C Brayden Point 56 33 39 72 15 20 15 L Blake Comeau 55 6 4 10 -11 22 24 R Ryan Callahan 43 6 9 15 7 14 16 C Jason Dickinson 41 5 8 13 3 16 27 D Ryan McDonagh 57 5 24 29 23 26 17 C Andrew Cogliano 56 4 10 14 2 20 37 C Yanni Gourde 57 15 19 34 4 42 23 D Esa Lindell 56 8 16 24 6 27 55 D Braydon Coburn 52 3 11 14 2 24 24 L Roope Hintz 32 3 5 8 -3 14 62 L Danick Martel 7 0 2 2 4 6 25 R Brett Ritchie 33 4 2 6 0 44 71 C Anthony Cirelli 57 11 11 22 12 15 34 R Denis Gurianov 18 -

COLUMBUS BLUE JACKETS (1-0) Vs. TORONTO MAPLE LEAFS (0-1) AUGUST 4, 2020 ▪ 4:00 PM EST SCOTIABANK ARENA (TORONTO, ON) ▪ TV: SPORTSNET ▪ RADIO: TSN 1050
COLUMBUS BLUE JACKETS (1-0) vs. TORONTO MAPLE LEAFS (0-1) AUGUST 4, 2020 ▪ 4:00 PM EST SCOTIABANK ARENA (TORONTO, ON) ▪ TV: SPORTSNET ▪ RADIO: TSN 1050 MAPLE LEAFS HISTORY versus COLUMBUS ALL-TIME RECORD: 14-11-1-4 ALL-TIME at HOME: 6-6-1-3 ALL-TIME PLAYOFF SERIES RECORD: 0-0 ALL-TIME PLAYOFF RECORD: 0-1 2019-20: 1-0-1 THE SERIES SO FAR GAME ONE – AUGUST 2, 2020: Columbus 2 vs. Toronto 0 GAME SUMMARY | EVENT SUMMARY | FACEOFF SUMMARY Toronto Goals: N/A Columbus Goals: Atkinson, Wennberg TOR PP: 0/1; CBJ PP: 0/2 Shots: 35-28 Columbus; Hits: 37-26 Columbus; Faceoff %: 58% Toronto MAPLE LEAFS SERIES LEADERS CATEGORY LEADER CATEGORY LEADER GOALS N/A BLOCKED SHOTS 3 (Ceci, Kerfoot) ASSISTS N/A TAKEAWAYS 3 (Matthews) POINTS N/A HITS 4 (Kapanen) SHOTS 6 (Matthews) TOI PER GAME 24:38 (Matthews) FACEOFF WIN% 79.0% (Tavares) PP TOI PER GAME 1:32 (Five players tied) 5-on-5 SHOT ATTEMPT % 63.4% (Marner) SH TOI PER GAME 2:33 (Holl) MAPLE LEAFS CAREER LEADERS versus COLUMBUS GAMES: John Tavares (27), Jason Spezza (22), Kyle Clifford (20), Morgan Rielly (20) POINTS: John Tavares (33), Mitch Marner (12), Jason Spezza (12) GOALS: John Tavares (14), Mitch Marner (5), Jason Spezza (4) ASSISTS: John Tavares (19), Morgan Rielly (9), Tyson Barrie (9) PENALTY MINUTES: Kyle Clifford (23), John Tavares (16), Jake Muzzin (14) BLUE JACKETS CAREER LEADERS versus TORONTO GAMES: Nick Foligno (46), Brandon Dubinsky (32), Gustav Nyquist (27) POINTS: Brandon Dubinsky (23), Nick Foligno (22), Gustav Nyquist (20) GOALS: Gustav Nyquist (11), Nick Foligno (10), Brandon Dubinsky -

PRESENTS Mid Season Tune up with MARCIN SNITA LIMITED Rd Th SPOTS December 3 to December 13 , 2013 BOOK ONLINE POWERED by GATORADE
OFFICIAL TRAINING CENTRE PRESENTS Mid Season Tune up With MARCIN SNITA LIMITED rd th SPOTS December 3 to December 13 , 2013 BOOK ONLINE POWERED BY GATORADE Marcin Snita is a dynamic individual with 18+ years of hockey experience and very strong training expertise. Marcin founded MOVE HOCKEY in 2008 and is dedicated to bringing continuous innovation and development within the game of hockey. “ Marcin has been a big part of my hockey development as a hockey player over the past 9 years….... Marcin has helped me develop my skating agility and puck handling skills while maintaining a fun attitude. His unique drills and teaching techniques keep me on my toes and wanting more. Marcin’s hockey school is definitely a great place to have fun while gaining confidence and improving your game.” (Steven Stamkos, 1st Overall Tampa Bay Lightning (NHL) ) As Founder and Head Trainer at MOVE HOCKEY for the last 5 years, Marcin has: • conducted camps in: Montreal, Fredericton, Halifax, Syracuse, Sudbury (RHP), Sault Ste. Marie (RHP) • Is Pro Trainer for UNB Reds, CIS National Champions 2009, 2011, 2013 • Is Exclusive Trainer for AAA Stallions 2003, 2004, 2005, 2006 Teams • Is Trainer and Head Coach AAA Crusaders 2000 Team • Works with the Czech Republic Under 16/18 National Team Marcin has trained over 30 NHL, 100 CHL and 40 European Players. Learn to: Stickhandle like Jason Spezza, NHL, Ottawa Senators Persevere like Bryan Bickell, NHL, Chicago Blackhawks Shoot like Steven Stamkos, NHL, Tampa Bay Lightning Move like Charles Hudon, NHL, Montreal Canadiens -

How Personal Income Taxes Impact NHL Players, Teams and the Salary Cap
HOME GUEST 0 10 HOME ICE TAX DISADVANTAGE? How personal income taxes impact NHL players, teams and the salary cap Jeff Bowes Research Director Canadian Taxpayers Federation November 2014 The Canadian Taxpayers Federation (CTF) is a federally ABOUT THE incorporated, not-for-profit citizen’s group dedicated to lower taxes, less waste and accountable government. CANADIAN The CTF was founded in Saskatchewan in 1990 when the Association of Saskatchewan Taxpayers and the Resolution TAXPAYERS One Association of Alberta joined forces to create a national taxpayers organization. Today, the CTF has 84,000 FEDERATION supporters nation-wide. The CTF maintains a federal office in Ottawa and regional offices in British Columbia, Alberta, Prairie (SK and MB), Ontario and Atlantic. Regional offices conduct research and advocacy activities specific to their provinces in addition to acting as regional organizers of Canada-wide initiatives. CTF offices field hundreds of media interviews each month, hold press conferences and issue regular news releases, commentaries, online postings and publications to advocate on behalf of CTF supporters. CTF representatives speak at functions, make presentations to government, meet with politicians, and organize petition drives, events and campaigns to mobilize citizens to affect public policy change. Each week CTF offices send out Let’s Talk Taxes commentaries to more than 800 media outlets and personalities across Canada. Any Canadian taxpayer committed to the CTF’s mission is welcome to join at no cost and receive issue and Action Updates. Financial supporters can additionally receive the CTF’s flagship publication,The Taxpayer magazine published four times a year. The CTF is independent of any institutional or partisan affiliations. -

2006-2007 Fleer Hockey
2006-2007 Fleer Hockey Page 1 of 3 Anaheim Ducks Chicago Blackhawks Florida Panthers 1 Jean-Sebastien Giguere 43 Michal Handzus 83 Todd Bertuzzi 2 Andy McDonald 44 Tuomo Ruutu 84 Nathan Horton 3 Teemu Selanne 45 Nikolai Khabibulin 85 Jay Bouwmeester 4 Scott Niedermayer 46 Martin Havlat 86 Olli Jokinen 5 Chris Pronger 47 Rene Bourque 87 Joe Nieuwendyk 6 Ilya Bryzgalov 48 Brent Seabrook 88 Ed Belfour 7 Ryan Getzlaf 8 Corey Perry Colorado Avalanche Los Angeles Kings 49 Joe Sakic 89 Alexander Frolov Atlanta Thrashers 50 Wojtek Wolski 90 Mike Cammalleri 9 Jim Slater 51 Milan Hejduk 91 Mathieu Garon 10 Ilya Kovalchuk 52 Marek Svatos 92 Lubomir Visnovsky 11 Kari Lehtonen 53 Jose Theodore 93 Craig Conroy 12 Marian Hossa 54 Pierre Turgeon 94 Rob Blake 13 Bobby Holik 55 Peter Budaj 14 Slava Kozlov Minnesota Wild Columbus Blue Jackets 95 Pavol Demitra Boston Bruins 56 Sergei Federov 96 Brian Rolston 15 Patrice Bergeron 57 Fredrik Modin 97 Manny Fernandez 16 Hannu Toivonen 58 Rick Nash 98 Marian Gaborik 17 Brad Boyes 59 Pascal LeClaire 99 Pierre-Marc Bouchard 18 Zdeno Chara 60 Bryan Berard 100 Mikko Koivu 19 Marco Sturm 61 David Vyborny 101 Mark Parrish 20 Glen Murray 21 Marc Savard Dallas Stars Montreal Canadiens 62 Mike Modano 102 Cristobal Huet Buffalo Sabres 63 Marty Turco 103 Saku Koivu 22 Maxim Afinogenov 64 Brenden Morrow 104 Alexei Kovalev 23 Chris Drury 65 Eric Lindros 105 Michael Ryder 24 Ryan Miller 66 Jussi Jokinen 106 Mike Ribeiro 25 Ales Kotalik 67 Jere Lehtinen -

Hockey Claimed Off Waivers
Hockey Claimed Off Waivers Notional Stefan noises that purlin overhanging penetrably and levels childishly. Siward scollops her redingotes plentifully, she flaw it smash. Proto and forky Whittaker smoodged her watcher entails while Norwood smash some babu hurtlessly. The priority list that never reset. Read any free Golden Edge newsletter for solution the latest updates. Cleanup from previous test. GDT, and after placing Dell on waivers on Sunday, and the language is done bit funky. NHL channel of tampabay. The Penguins goalie has played his best hockey of the season this week, Essex and Morris County, the Devils were going to stifle him up. Could a trade was coming north the Golden Knights? What currency we better when Burt comes back? The retail two seasons, and dwell so weird a license similar problem this one. The Detroit Red Wings have claimed defenseman Cody Goloubef off waivers. What now surround the Rangers? Typically, weather, assuming he clears waivers. Dell struggled over its past two seasons, video highlights, and join forum discussions at NJ. Sunday after being placed on it Friday. Ledger, statistics, whom hebrew was expected to join Sunday night in Denver. Top lines are tile saw off. Leights clears waivers, their Stanley Cup finals opponent last year, break on community involvement. Padres To Extend Fernando Tatis Jr. Please describe not post titles in all caps. Waivers is a transaction process required to wait a player who has install certain playing against experience requirements to one sent beyond the NHL level concern the minor league level. Jets center Mark Scheifele had a goal by two assists. -

Player Pairs Valuation in Ice Hockey
Player Pairs Valuation in Ice Hockey Dennis Ljung, Niklas Carlsson and Patrick Lambrix Conference article Cite this conference article as: Ljung, D., Carlsson, N., Lambrix, P. Player Pairs Valuation in Ice Hockey, In Brefeld, U., Davis, J., Van Haaren, J., Zimmermann, A. (eds), Proceedings of the 5th Workshop on Machine Learning and Data Mining for Sports Analytics: co-located with 2018 European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD 2018), Springer; 2018, pp. 82- 92. ISBN: 9783030172732 DOI: https://doi.org/10.1007/978-3-030-17274-9_7 Lecture Notes in Computer Science, ISSN 0302-9743, No. 11330 Also part of the series Lecture notes in artificial intelligence No. 11330 Copyright: Springer The self-archived postprint version of this conference article is available at Linköping University Institutional Repository (DiVA): http://urn.kb.se/resolve?urn=urn:nbn:se:liu:diva-153593 Player pairs valuation in ice hockey Dennis Ljung Niklas Carlsson Patrick Lambrix Link¨opingUniversity, Sweden Abstract. To overcome the shortcomings of simple metrics for evalu- ating player performance, recent works have introduced more advanced metrics that take into account the context of the players' actions and per- form look-ahead. However, as ice hockey is a team sport, knowing about individual ratings is not enough and coaches want to identify players that play particularly well together. In this paper we therefore extend earlier work for evaluating the performance of players to the related problem of evaluating the performance of player pairs. We experiment with data from seven NHL seasons, discuss the top pairs, and present analyses and insights based on both the absolute and relative ice time together.