Proteograph Platform Delivers Unbiased
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

At Elevated Temperatures, Heat Shock Protein Genes Show Altered Ratios Of
EXPERIMENTAL AND THERAPEUTIC MEDICINE 22: 900, 2021 At elevated temperatures, heat shock protein genes show altered ratios of different RNAs and expression of new RNAs, including several novel HSPB1 mRNAs encoding HSP27 protein isoforms XIA GAO1,2, KEYIN ZHANG1,2, HAIYAN ZHOU3, LUCAS ZELLMER4, CHENGFU YUAN5, HAI HUANG6 and DEZHONG JOSHUA LIAO2,6 1Department of Pathology, Guizhou Medical University Hospital; 2Key Lab of Endemic and Ethnic Diseases of The Ministry of Education of China in Guizhou Medical University; 3Clinical Research Center, Guizhou Medical University Hospital, Guiyang, Guizhou 550004, P.R. China; 4Masonic Cancer Center, University of Minnesota, Minneapolis, MN 55455, USA; 5Department of Biochemistry, China Three Gorges University, Yichang, Hubei 443002; 6Center for Clinical Laboratories, Guizhou Medical University Hospital, Guiyang, Guizhou 550004, P.R. China Received December 16, 2020; Accepted May 10, 2021 DOI: 10.3892/etm.2021.10332 Abstract. Heat shock proteins (HSP) serve as chaperones genes may engender multiple protein isoforms. These results to maintain the physiological conformation and function of collectively suggested that, besides increasing their expres‑ numerous cellular proteins when the ambient temperature is sion, certain HSP and associated genes also use alternative increased. To determine how accurate the general assumption transcription start sites to produce multiple RNA transcripts that HSP gene expression is increased in febrile situations is, and use alternative splicing of a transcript to produce multiple the RNA levels of the HSF1 (heat shock transcription factor 1) mature RNAs, as important mechanisms for responding to an gene and certain HSP genes were determined in three cell increased ambient temperature in vitro. lines cultured at 37˚C or 39˚C for three days. -

Proteomic Signatures of Serum Albumin
Proteomic signatures of serum albumin- bound proteins from stroke patients with and without endovascular closure of PFO are significantly different and suggest a novel mechanism for cholesterol efflux The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Lopez, M. F., B. Krastins, D. A. Sarracino, G. Byram, M. S. Vogelsang, A. Prakash, S. Peterman, et al. 2015. “Proteomic signatures of serum albumin-bound proteins from stroke patients with and without endovascular closure of PFO are significantly different and suggest a novel mechanism for cholesterol efflux.” Clinical Proteomics 12 (1): 2. doi:10.1186/1559-0275-12-2. http:// dx.doi.org/10.1186/1559-0275-12-2. Published Version doi:10.1186/1559-0275-12-2 Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:14065419 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Lopez et al. Clinical Proteomics 2015, 12:2 http://www.clinicalproteomicsjournal.com/content/12/1/2 CLINICAL PROTEOMICS RESEARCH Open Access Proteomic signatures of serum albumin-bound proteins from stroke patients with and without endovascular closure of PFO are significantly different and suggest a novel mechanism for cholesterol efflux Mary F Lopez1*, Bryan Krastins1, David A Sarracino1, Gregory Byram1, Maryann S Vogelsang1, Amol Prakash1, Scott Peterman1, Shadab Ahmad1, Gouri Vadali1, Wenjun Deng2, Ignacio Inglessis2, Tom Wickham2, Kathleen Feeney2, G William Dec2, Igor Palacios2, Ferdinando S Buonanno2, Eng H Lo2 and MingMing Ning2 Abstract Background: The anatomy of PFO suggests that it can allow thrombi and potentially harmful circulatory factors to travel directly from the venous to the arterial circulation – altering circulatory phenotype. -

Post-Translational Modifications - Essential for Protein Regulation Related Publications AUGUST Research Tools 2015
CYTOSKELETON NEWS NEWS FROM CYTOSKELETON INC. this issue Post-translational Modifications - Essential for Protein Regulation Related Publications AUGUST Research Tools 2015 Meetings Post-translational Modifications - Essential for Protein Regulation To maintain homeostasis, cells need to respond to changes in the SUMOylation, where the former plays a prominent role in protein 2015 European Cytoskeletal intracellular and extracellular milieu. Some of the changes have to degradation through proteasomal pathway7 and the latter is News Forum Meeting be acted upon quickly to avoid detrimental effects that can lead important for regulating cellular processes, including cell cycle, Aug 30-Sept 4 2015 to cell damage or even death. One way that cells act is through apoptosis, DNA repair, and signal transduction pathways8. Ljubljana, Slovenia protein post-translational modifications (PTMs) which enable cells to respond quickly to various changes by influencing numerous PTM crosstalk – Adding layers of complexity to the proteomic network The Triangle Cytoskeleton Meeting properties of proteins including enzymatic activity, protein Sept 21st, 2015 interactions, and subcellular location. Advanced developments PTM crosstalk has gained increasing interest in recent proteomics Saxapahawm NC in mass-spectrometry (MS) methods allow the identification of studies. Two independent groups employed bioinformatics and PTMs on a large scale. Today, more than 200 PTMs are known1,2, database analyses of protein sequences and have identified Neuroscience 2015 ranging from small chemical modifications (e.g., phosphorylation “hotspots” where PTMs of different types are located within a and acetylation) close proximity, about 15 amino acids apart9,10. Some of these Oct 17-21, 2015 NIH3T3 +/- pervanadate 1,2 Ljubljana, Slovenia to the addition of IP: APY03-bead “hotspots” have been reported in the literature to crosstalk . -
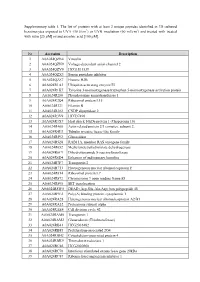
Supplementary Table 1. the List of Proteins with at Least 2 Unique
Supplementary table 1. The list of proteins with at least 2 unique peptides identified in 3D cultured keratinocytes exposed to UVA (30 J/cm2) or UVB irradiation (60 mJ/cm2) and treated with treated with rutin [25 µM] or/and ascorbic acid [100 µM]. Nr Accession Description 1 A0A024QZN4 Vinculin 2 A0A024QZN9 Voltage-dependent anion channel 2 3 A0A024QZV0 HCG1811539 4 A0A024QZX3 Serpin peptidase inhibitor 5 A0A024QZZ7 Histone H2B 6 A0A024R1A3 Ubiquitin-activating enzyme E1 7 A0A024R1K7 Tyrosine 3-monooxygenase/tryptophan 5-monooxygenase activation protein 8 A0A024R280 Phosphoserine aminotransferase 1 9 A0A024R2Q4 Ribosomal protein L15 10 A0A024R321 Filamin B 11 A0A024R382 CNDP dipeptidase 2 12 A0A024R3V9 HCG37498 13 A0A024R3X7 Heat shock 10kDa protein 1 (Chaperonin 10) 14 A0A024R408 Actin related protein 2/3 complex, subunit 2, 15 A0A024R4U3 Tubulin tyrosine ligase-like family 16 A0A024R592 Glucosidase 17 A0A024R5Z8 RAB11A, member RAS oncogene family 18 A0A024R652 Methylenetetrahydrofolate dehydrogenase 19 A0A024R6C9 Dihydrolipoamide S-succinyltransferase 20 A0A024R6D4 Enhancer of rudimentary homolog 21 A0A024R7F7 Transportin 2 22 A0A024R7T3 Heterogeneous nuclear ribonucleoprotein F 23 A0A024R814 Ribosomal protein L7 24 A0A024R872 Chromosome 9 open reading frame 88 25 A0A024R895 SET translocation 26 A0A024R8W0 DEAD (Asp-Glu-Ala-Asp) box polypeptide 48 27 A0A024R9E2 Poly(A) binding protein, cytoplasmic 1 28 A0A024RA28 Heterogeneous nuclear ribonucleoprotein A2/B1 29 A0A024RA52 Proteasome subunit alpha 30 A0A024RAE4 Cell division cycle 42 31 -

The Regulation of Telomerase Reverse Transcriptase (TERT) by CCAAT/Enhancer Binding Protein Β (C/Ebpβ) During Skeletal Muscle Differentiation
The Regulation of Telomerase Reverse Transcriptase (TERT) by CCAAT/Enhancer Binding Protein β (C/EBPβ) During Skeletal Muscle Differentiation Kira Slivitzky This thesis is submitted as a partial fulfillment of the M.Sc. program in Cellular and Molecular Medicine Department of Cellular and Molecular Medicine Faculty of Medicine University of Ottawa Date of final submission: November 2, 2017 © Kira Slivitzky, Ottawa, Canada, 2017 ABSTRACT Our lab has identified the bZIP transcription factor CCAAT/Enhancer Binding Protein beta (C/EBPβ) as a negative regulator of myogenic differentiation. C/EBPβ is highly expressed in satellite cells and is downregulated during myogenic differentiation, a step that is critical for terminal differentiation, as ectopic C/EBPβ expression blocks this process. Telomerase has been identified as a C/EBPβ target gene in liver and other systems, and has been implicated in the regulation of muscle regenerative responses in models of Duchenne Muscular Dystrophy. Given that C/EBPβ is overexpressed in models of muscle wasting, and high levels of telomerase inhibit differentiation, I hypothesized that C/EBPβ inhibits myogenic differentiation through upregulation of TERT (telomerase reverse transcriptase) expression. I demonstrate that overexpression of C/EBPβ in myoblasts increases mTERT expression under both growth and differentiation conditions. Conversely, loss of C/EBPβ expression in myoblasts using shRNA technology or after isolation of primary myoblasts from conditional knockout mice, results in a downregulation of TERT expression and activity. When TERT was pharmacologically inhibited or knocked down using a shRNA, there was a significant improvement in differentiation and fusion in C2C12 myoblasts overexpressing C/EBPβ as evidenced by an increase in the number of MHC+ fibers and expression of muscle-specific differentiation genes. -

Cartography of Neurexin Alternative Splicing Mapped by Single
Cartography of neurexin alternative splicing mapped PNAS PLUS by single-molecule long-read mRNA sequencing Barbara Treutleina,b,1, Ozgun Gokcec,1, Stephen R. Quakea,b,d,2, and Thomas C. Südhofc,d,2 Departments of aBioengineering and cMolecular and Cellular Physiology, School of Medicine, bDepartment of Applied Physics, and dHoward Hughes Medical Institute, Stanford University, Stanford, CA 94305 Contributed by Thomas C. Südhof, February 24, 2014 (sent for review January 24, 2014) Neurexins are evolutionarily conserved presynaptic cell-adhesion α-andβ-neurexins contain different extracellular sequences molecules that are essential for normal synapse formation and but identical transmembrane regions and short cytoplasmic tails. synaptic transmission. Indirect evidence has indicated that exten- Specifically, the extracellular sequences of α-neurexins are sive alternative splicing of neurexin mRNAs may produce hundreds composed of six LNS (laminin-α, neurexin, sex hormone-binding if not thousands of neurexin isoforms, but no direct evidence for globulin) domains with three interspersed EGF-like repeats such diversity has been available. Here we use unbiased long-read followed by an O-linked sugar attachment sequence and a con- sequencing of full-length neurexin (Nrxn)1α, Nrxn1β,Nrxn2β, served cysteine loop sequence (8, 15). In contrast, the extracel- Nrxn3α, and Nrxn3β mRNAs to systematically assess how many lular sequences of β-neurexins comprise a short β-neurexin– sites of alternative splicing are used in neurexins with a significant specific sequence, and then splice into the sixth LNS domain of frequency, and whether alternative splicing events at these sites α-neurexins, from which point on β-neurexins are identical to are independent of each other. -

Network-Based Method for Drug Target Discovery at the Isoform Level
www.nature.com/scientificreports OPEN Network-based method for drug target discovery at the isoform level Received: 20 November 2018 Jun Ma1,2, Jenny Wang2, Laleh Soltan Ghoraie2, Xin Men3, Linna Liu4 & Penggao Dai 1 Accepted: 6 September 2019 Identifcation of primary targets associated with phenotypes can facilitate exploration of the underlying Published: xx xx xxxx molecular mechanisms of compounds and optimization of the structures of promising drugs. However, the literature reports limited efort to identify the target major isoform of a single known target gene. The majority of genes generate multiple transcripts that are translated into proteins that may carry out distinct and even opposing biological functions through alternative splicing. In addition, isoform expression is dynamic and varies depending on the developmental stage and cell type. To identify target major isoforms, we integrated a breast cancer type-specifc isoform coexpression network with gene perturbation signatures in the MCF7 cell line in the Connectivity Map database using the ‘shortest path’ drug target prioritization method. We used a leukemia cancer network and diferential expression data for drugs in the HL-60 cell line to test the robustness of the detection algorithm for target major isoforms. We further analyzed the properties of target major isoforms for each multi-isoform gene using pharmacogenomic datasets, proteomic data and the principal isoforms defned by the APPRIS and STRING datasets. Then, we tested our predictions for the most promising target major protein isoforms of DNMT1, MGEA5 and P4HB4 based on expression data and topological features in the coexpression network. Interestingly, these isoforms are not annotated as principal isoforms in APPRIS. -

A Quantitative Proteome Map of the Human Body
bioRxiv preprint doi: https://doi.org/10.1101/797373; this version posted October 9, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. A Quantitative Proteome Map of the Human Body Lihua Jiang1†, Meng Wang1†, Shin Lin1, Ruiqi Jian1, Xiao Li1, Joanne Chan1, Huaying Fang1, Guanlan Dong1, GTEx Consortium, Hua Tang*1, Michael P. Snyder*1 1Stanford University, Stanford, CA; 2University of Washington, Seattle, WA * to whom correspondence should be addressed: [email protected], [email protected] † These authors contributed equally Short title: A Quantitative Map of the Human Proteome Summary Quantitative proteome study of 32 human tissues and integrated analysis with transcriptome data revealed that understanding protein levels could provide in-depth knowledge to post transcriptional or translational regulations, human metabolism, secretome, and diseases. Abstract Determining protein levels in each tissue and how they compare with RNA levels is important for understanding human biology and disease as well as regulatory processes that control protein levels. We quantified the relative protein levels from 12,627 genes across 32 normal human tissue types prepared by the GTEx project. Known and new tissue specific or enriched proteins (5,499) were identified and compared to transcriptome data. Many ubiquitous transcripts are found to encode highly tissue specific proteins. Discordance in the sites of RNA expression and protein detection also revealed potential sites of synthesis and action of protein signaling molecules. -

Telomerase Biogenesis and Activities from the Perspective of Its Direct Interacting Partners
cancers Review Telomerase Biogenesis and Activities from the Perspective of Its Direct Interacting Partners Kathryn T. T. T. Nguyen and Judy M. Y. Wong * Faculty of Pharmaceutical Sciences, University of British Columbia, Vancouver, BC V6T 1Z3, Canada; [email protected] * Correspondence: [email protected] Received: 1 June 2020; Accepted: 22 June 2020; Published: 24 June 2020 Abstract: Telomerase reverse transcriptase (TERT)—the catalytic subunit of telomerase—is reactivated in up to 90% of all human cancers. TERT is observed in heterogenous populations of protein complexes, which are dynamically regulated in a cell type- and cell cycle-specific manner. Over the past two decades, in vitro protein–protein interaction detection methods have discovered a number of endogenous TERT binding partners in human cells that are responsible for the biogenesis and functionalization of the telomerase holoenzyme, including the processes of TERT trafficking between subcellular compartments, assembly into telomerase, and catalytic action at telomeres. Additionally, TERT have been found to interact with protein species with no known telomeric functions, suggesting that these complexes may contribute to non-canonical activities of TERT. Here, we survey TERT direct binding partners and discuss their contributions to TERT biogenesis and functions. The goal is to review the comprehensive spectrum of TERT pro-malignant activities, both telomeric and non-telomeric, which may explain the prevalence of its upregulation in cancer. Keywords: TERT; TERT interacting -

The Major Reverse Transcriptase–Incompetent Splice Variant of the Human Telomerase Protein Inhibits Telomerase Activity but Protects from Apoptosis
Published OnlineFirst April 22, 2013; DOI: 10.1158/0008-5472.CAN-12-3082 Cancer Molecular and Cellular Pathobiology Research The Major Reverse Transcriptase–Incompetent Splice Variant of the Human Telomerase Protein Inhibits Telomerase Activity but Protects from Apoptosis Imke Listerman, Jie Sun, Francesca S. Gazzaniga, Jason L. Lukas, and Elizabeth H. Blackburn Abstract Human telomerase reverse transcriptase (hTERT; the catalytic protein subunit of telomerase) is subjected to numerous alternative splicing events, but the regulation and function of these splice variants is obscure. Full- length hTERT includes conserved domains that encode reverse transcriptase activity, RNA binding, and other functions. The major splice variant termed aþbÀ or b-deletion is highly expressed in stem and cancer cells, where it codes for a truncated protein lacking most of the reverse transcriptase domain but retaining the known RNA- binding motifs. In a breast cancer cell panel, we found that b-deletion was the hTERT transcript that was most highly expressed. Splicing of this transcript was controlled by the splice regulators SRSF11, HNRNPH2, and HNRNPL, and the b-deletion transcript variant was associated with polyribosomes in cells. When ectopically overexpressed, b-deletion protein competed for binding to telomerase RNA (hTR/TERC), thereby inhibiting endogenous telomerase activity. Overexpressed b-deletion protein localized to the nucleus and mitochondria and protected breast cancer cells from cisplatin-induced apoptosis. Our results reveal that a major hTERT splice variant can confer a growth advantage to cancer cells independent of telomere maintenance, suggesting that hTERT makes multiple contributions to cancer pathophysiology. Cancer Res; 73(9); 1–12. Ó2013 AACR. Introduction (5). -

P53/P73 Protein Network in Colorectal Cancer and Other Human Malignancies
cancers Review p53/p73 Protein Network in Colorectal Cancer and Other Human Malignancies Andela¯ Horvat †, Ana Tadijan † , Ignacija Vlaši´c † and Neda Slade * Laboratory for Protein Dynamics, Division of Molecular Medicine, Ruder¯ Boškovi´cInstitute, Bijeniˇcka54, 10000 Zagreb, Croatia; [email protected] (A.H.); [email protected] (A.T.); [email protected] (I.V.) * Correspondence: [email protected] † Contributed equally. Simple Summary: The p53 family of proteins comprises p53, p63, and p73, which share high structural and functional similarity. The two distinct promoters of each locus, the alternative splicing, and the alternative translation initiation sites enable the generation of numerous isoforms with different protein-interacting domains and distinct activities. The co-expressed p53/p73 isoforms have significant but distinct roles in carcinogenesis. Their activity is frequently impaired in human tumors including colorectal carcinoma due to dysregulated expression and a dominant-negative effect accomplished by some isoforms and p53 mutants. The interactions between isoforms are particularly important to understand the onset of tumor formation, progression, and therapeutic response. The understanding of the p53/p73 network can contribute to the development of new targeted therapies. Abstract: The p53 tumor suppressor protein is crucial for cell growth control and the maintenance of genomic stability. Later discovered, p63 and p73 share structural and functional similarity with p53. To understand the p53 pathways more profoundly, all family members should be considered. Citation: Horvat, A.; Tadijan, A.; Each family member possesses two promoters and alternative translation initiation sites, and they Vlaši´c,I.; Slade, N. p53/p73 Protein undergo alternative splicing, generating multiple isoforms. -

Tools and Technologies to Characterize Isoforms at Proteome-Scale
Tools and technologies to characterize isoforms at proteome-scale Gloria Sheynkman Marc Vidal Laboratory Center for Cancer Systems Biology, Dana Faber Cancer Institute Department of Genetics, Harvard University SMRTLeiden May 2nd, 2017 CCSB CENTER FOR CANCER SYSTEMS BIOLOGY Gene numbers Number 20K of genes Complexity Ensembl Dec 2015 release Isoform numbers 100K Number of Numbersplice of formsisoforms Number 20K of genes Complexity Ensembl Dec 2015 release Combinations of splice sites produce diverse protein isoforms. Tropomyosin Alpha-1 Chain chr15:63,334,785-63,364,028 MCF-7 Cells A G A AA AAA canonical alternative casette constitutive nucleotide retained alternative alternative A A lncRNA canonical A A A promoter promoter exon exons polymorphism intron donor 3’ end polyadenylation site (5’ end) AAA A A A AAA A A A AAA A A A A AA A A A AA A A A AA A A A AA A A AAA A A A AAA A A A AAA A A A AAA A A A A AA A A The proteoform hypothesis ~100K isoforms ~1 million proteoforms Smith & Kelleher Nat Methods 2013 Splicing regulation and disease •splicing is pervasive, inherent to encoded products of the genome •splicing is highly regulated in space and time •high tissue- and developmental- specificity •“splice code” •splicing is dysregulated in many diseases, including cancer •estimates of 50% all disease variants affect splicing •splice-modulating therapies (e.g. antisense oligos) Wang et al Nature Review Genetics (2007), 6 Isoform function? 100K Number of Numbersplice of formsisoforms Number 20K of genes Complexity Ensembl Dec 2015 release Isoforms and functional divergence In vivo functions Identical “Isoforms” Different “Alloforms” Opposite “Antiforms” Examples of functionally divergent isoforms Alloforms Antiforms Bcl-X anti-apoptotic Bcl-X pro-apoptotic Christofk et al Nature 2008 Schwerk et al Mol Cell 2005 Divergent functional capabilities described in literature Isoforms for a few hundred genes Physical interactions Cellular localization Enzymatic activities Stability ….