A Quantitative Proteome Map of the Human Body
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

At Elevated Temperatures, Heat Shock Protein Genes Show Altered Ratios Of
EXPERIMENTAL AND THERAPEUTIC MEDICINE 22: 900, 2021 At elevated temperatures, heat shock protein genes show altered ratios of different RNAs and expression of new RNAs, including several novel HSPB1 mRNAs encoding HSP27 protein isoforms XIA GAO1,2, KEYIN ZHANG1,2, HAIYAN ZHOU3, LUCAS ZELLMER4, CHENGFU YUAN5, HAI HUANG6 and DEZHONG JOSHUA LIAO2,6 1Department of Pathology, Guizhou Medical University Hospital; 2Key Lab of Endemic and Ethnic Diseases of The Ministry of Education of China in Guizhou Medical University; 3Clinical Research Center, Guizhou Medical University Hospital, Guiyang, Guizhou 550004, P.R. China; 4Masonic Cancer Center, University of Minnesota, Minneapolis, MN 55455, USA; 5Department of Biochemistry, China Three Gorges University, Yichang, Hubei 443002; 6Center for Clinical Laboratories, Guizhou Medical University Hospital, Guiyang, Guizhou 550004, P.R. China Received December 16, 2020; Accepted May 10, 2021 DOI: 10.3892/etm.2021.10332 Abstract. Heat shock proteins (HSP) serve as chaperones genes may engender multiple protein isoforms. These results to maintain the physiological conformation and function of collectively suggested that, besides increasing their expres‑ numerous cellular proteins when the ambient temperature is sion, certain HSP and associated genes also use alternative increased. To determine how accurate the general assumption transcription start sites to produce multiple RNA transcripts that HSP gene expression is increased in febrile situations is, and use alternative splicing of a transcript to produce multiple the RNA levels of the HSF1 (heat shock transcription factor 1) mature RNAs, as important mechanisms for responding to an gene and certain HSP genes were determined in three cell increased ambient temperature in vitro. lines cultured at 37˚C or 39˚C for three days. -

Proteomic Signatures of Serum Albumin
Proteomic signatures of serum albumin- bound proteins from stroke patients with and without endovascular closure of PFO are significantly different and suggest a novel mechanism for cholesterol efflux The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Lopez, M. F., B. Krastins, D. A. Sarracino, G. Byram, M. S. Vogelsang, A. Prakash, S. Peterman, et al. 2015. “Proteomic signatures of serum albumin-bound proteins from stroke patients with and without endovascular closure of PFO are significantly different and suggest a novel mechanism for cholesterol efflux.” Clinical Proteomics 12 (1): 2. doi:10.1186/1559-0275-12-2. http:// dx.doi.org/10.1186/1559-0275-12-2. Published Version doi:10.1186/1559-0275-12-2 Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:14065419 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Lopez et al. Clinical Proteomics 2015, 12:2 http://www.clinicalproteomicsjournal.com/content/12/1/2 CLINICAL PROTEOMICS RESEARCH Open Access Proteomic signatures of serum albumin-bound proteins from stroke patients with and without endovascular closure of PFO are significantly different and suggest a novel mechanism for cholesterol efflux Mary F Lopez1*, Bryan Krastins1, David A Sarracino1, Gregory Byram1, Maryann S Vogelsang1, Amol Prakash1, Scott Peterman1, Shadab Ahmad1, Gouri Vadali1, Wenjun Deng2, Ignacio Inglessis2, Tom Wickham2, Kathleen Feeney2, G William Dec2, Igor Palacios2, Ferdinando S Buonanno2, Eng H Lo2 and MingMing Ning2 Abstract Background: The anatomy of PFO suggests that it can allow thrombi and potentially harmful circulatory factors to travel directly from the venous to the arterial circulation – altering circulatory phenotype. -

Microbes and Metagenomics in Human Health an Overview of Recent Publications Featuring Illumina® Technology TABLE of CONTENTS
Microbes and Metagenomics in Human Health An overview of recent publications featuring Illumina® technology TABLE OF CONTENTS 4 Introduction 5 Human Microbiome Gut Microbiome Gut Microbiome and Disease Inflammatory Bowel Disease (IBD) Metabolic Diseases: Diabetes and Obesity Obesity Oral Microbiome Other Human Biomes 25 Viromes and Human Health Viral Populations Viral Zoonotic Reservoirs DNA Viruses RNA Viruses Human Viral Pathogens Phages Virus Vaccine Development 44 Microbial Pathogenesis Important Microorganisms in Human Health Antimicrobial Resistance Bacterial Vaccines 54 Microbial Populations Amplicon Sequencing 16S: Ribosomal RNA Metagenome Sequencing: Whole-Genome Shotgun Metagenomics Eukaryotes Single-Cell Sequencing (SCS) Plasmidome Transcriptome Sequencing 63 Glossary of Terms 64 Bibliography This document highlights recent publications that demonstrate the use of Illumina technologies in immunology research. To learn more about the platforms and assays cited, visit www.illumina.com. An overview of recent publications featuring Illumina technology 3 INTRODUCTION The study of microbes in human health traditionally focused on identifying and 1. Roca I., Akova M., Baquero F., Carlet J., treating pathogens in patients, usually with antibiotics. The rise of antibiotic Cavaleri M., et al. (2015) The global threat of resistance and an increasingly dense—and mobile—global population is forcing a antimicrobial resistance: science for interven- tion. New Microbes New Infect 6: 22-29 1, 2, 3 change in that paradigm. Improvements in high-throughput sequencing, also 2. Shallcross L. J., Howard S. J., Fowler T. and called next-generation sequencing (NGS), allow a holistic approach to managing Davies S. C. (2015) Tackling the threat of anti- microbial resistance: from policy to sustainable microbes in human health. -

Bioinformatics Tools for RNA-Seq Gene and Isoform Quantification
on: Sequ ati en er c n in e g G & t x A Journal of e p Zhang, et al., Next Generat Sequenc & Applic p N l f i c o 2016, 3:3 a l t a i o n r ISSN: 2469-9853n u s DOI: 10.4172/2469-9853.1000140 o Next Generation Sequencing & Applications J Review Article Open Access Bioinformatics Tools for RNA-seq Gene and Isoform Quantification Chi Zhang1, Baohong Zhang1, Michael S Vincent2 and Shanrong Zhao1* 1Early Clinical Development, Pfizer Worldwide R&D, Cambridge, MA, USA 2Inflammation and Immunology RU, Pfizer Worldwide R&D, Cambridge, MA, USA *Corresponding author: Shanrong Zhao, Early Clinical Development, Pfizer Worldwide R&D, Cambridge, MA, 02139, USA, Tel: + 1-212-733-2323; E-mail: [email protected] Rec date: Oct 27, 2016; Acc date: Dec 15, 2016; Pub date: Dec 17, 2016 Copyright: © 2016 Zhang C, et al. This is an open-access article distributed under the terms of the creative commons attribution license, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. Abstract In recent years, RNA-seq has emerged as a powerful technology in estimation of gene or transcript expression. ‘Union-exon’ and transcript based approaches are widely used in gene quantification. The ‘Union-exon’ based approach is simple, but it does not distinguish between isoforms when multiple alternatively spliced transcripts are expressed from the same gene. Because a gene is expressed in one or more transcript isoforms, the transcript based approach is more biologically meaningful than the ‘union exon’-based approach. -

Proteograph Platform Delivers Unbiased
Application of the Proteograph™ Product Suite to the Identification of Differential Protein Isoform Plasma Abundance in Early Lung Cancer vs. Healthy Controls Asim Siddiqui*, John E. Blume, Margaret K. R. Donovan, Marwin Ko, Ryan W. Benz, Theodore L. Platt, Juan C. Cuevas, Serafim Batzoglou and Omid C. Farokhzad Proteograph Platform Delivers Unbiased, Utilizing Proteograph Platform to Interrogate Protein Isoforms in a Proteograph Data Sheds Light on Biological Deep and Rapid Proteomics at Scale Non-small Cell Lung Cancer (NSCLC) Plasma Proteome Study Consequences of Protein Isoforms The ~20,000 genes in the human genome encode over one million Proteograph Platform Enables Deep and Unbiased Plasma Proteomics BMP1 Shows Differential Isoform Abundance Pattern protein variants, because of alternative splice forms, allelic variation and protein modifications. Though large-scale genomics studies Percentage of Samples Number of Peptides Detected The lowest abundant putative protein isoform, BMP1 from the list of have expanded our understanding of cancer biology through in Which Protein Group Detected per Protein candidate proteins identified in this study, comprises four protein analysis of both tissue and biofluids, similarly-scaled unbiased, deep 1A 1B 1C coding isoforms. Two of these isoforms are substantially longer n=80 proteomics studies of biofluids have remained impractical due to 2499 (~400-800 residues) than the other two isoforms covering additional Median 8 complexity of workflows. We have previously described the exons. Peptides mapping to exons that cover all four protein isoforms Proteograph Product Suite, a novel platform that leverages the n=61 (5A) have higher abundance in cancer relative to controls, whereas nano-bio interactions of nanoparticles for deep and unbiased 1992 peptides mapping to exons that cover only the two longer isoforms proteomic sampling at scale. -

Post-Translational Modifications - Essential for Protein Regulation Related Publications AUGUST Research Tools 2015
CYTOSKELETON NEWS NEWS FROM CYTOSKELETON INC. this issue Post-translational Modifications - Essential for Protein Regulation Related Publications AUGUST Research Tools 2015 Meetings Post-translational Modifications - Essential for Protein Regulation To maintain homeostasis, cells need to respond to changes in the SUMOylation, where the former plays a prominent role in protein 2015 European Cytoskeletal intracellular and extracellular milieu. Some of the changes have to degradation through proteasomal pathway7 and the latter is News Forum Meeting be acted upon quickly to avoid detrimental effects that can lead important for regulating cellular processes, including cell cycle, Aug 30-Sept 4 2015 to cell damage or even death. One way that cells act is through apoptosis, DNA repair, and signal transduction pathways8. Ljubljana, Slovenia protein post-translational modifications (PTMs) which enable cells to respond quickly to various changes by influencing numerous PTM crosstalk – Adding layers of complexity to the proteomic network The Triangle Cytoskeleton Meeting properties of proteins including enzymatic activity, protein Sept 21st, 2015 interactions, and subcellular location. Advanced developments PTM crosstalk has gained increasing interest in recent proteomics Saxapahawm NC in mass-spectrometry (MS) methods allow the identification of studies. Two independent groups employed bioinformatics and PTMs on a large scale. Today, more than 200 PTMs are known1,2, database analyses of protein sequences and have identified Neuroscience 2015 ranging from small chemical modifications (e.g., phosphorylation “hotspots” where PTMs of different types are located within a and acetylation) close proximity, about 15 amino acids apart9,10. Some of these Oct 17-21, 2015 NIH3T3 +/- pervanadate 1,2 Ljubljana, Slovenia to the addition of IP: APY03-bead “hotspots” have been reported in the literature to crosstalk . -

The Chromosome-Centric Human Proteome Project for Cataloging Proteins Encoded in the Genome
CORRESPONDENCE The Chromosome-Centric Human Proteome Project for cataloging proteins encoded in the genome To the Editor: utility for biological and disease studies. Table 1 Features of salient genes on The Chromosome-Centric Human With development of new tools for in- chromosomes 13 and 17 Proteome Project (C-HPP) aims to define depth characterization of the transcriptome Genea AST nsSNPs the full set of proteins encoded in each and proteome, the HPP is well positioned Chromosome 13 chromosome through development of a to have a strategic role in addressing the BRCA2 3 54 standardized approach for analyzing the complexity of human phenotypes. With this RB1 2 3 massive proteomic data sets currently being in mind, the HUPO has organized national IRS2 1 3 generated from dedicated efforts of national chromosome teams that will collaborate and international teams. The initial goal with well-established laboratories building Chromosome 17 of the C-HPP is to identify at least one complementary proteotypic peptides, BRCA1 24 24 representative protein encoded by each of antibodies and informatics resources. ERBB2 6 13 the approximately 20,300 human genes1,2. An important C-HPP goal is to encourage TP53 14 5 aEnsembl protein and AST information can be found at The proteins will be characterized for tissue capture and open sharing of proteomic http://www.ensembl.org/Homo_sapiens/. localization and major isoforms, including data sets from diverse samples to enhance AST, alternative splicing transcript; nsSNP, nonsyno- mous single-nucleotide polyphorphism assembled from post-translational modifications (PTMs), a gene- and chromosome-centric display data from the 1000 Genomes Projects. -

Downloaded As a CSV Dump file
cells Article Transcriptome and Methylome Analysis Reveal Complex Cross-Talks between Thyroid Hormone and Glucocorticoid Signaling at Xenopus Metamorphosis Nicolas Buisine 1,† , Alexis Grimaldi 1,†, Vincent Jonchere 1,† , Muriel Rigolet 1, Corinne Blugeon 2 , Juliette Hamroune 2 and Laurent Marc Sachs 1,* 1 UMR7221 Molecular Physiology and Adaption, CNRS, Museum National d’Histoire Naturelle, 57 Rue Cuvier, CEDEX 05, 75231 Paris, France; [email protected] (N.B.); [email protected] (A.G.); [email protected] (V.J.); [email protected] (M.R.) 2 Genomics Core Facility, Département de Biologie, Institut de Biologie de l’ENS (IBENS), École Normale Supérieure, CNRS, INSERM, Université PSL, 75005 Paris, France; [email protected] (C.B.); [email protected] (J.H.) * Correspondence: [email protected] † Co-first authors, alphabetic order. Abstract: Background: Most work in endocrinology focus on the action of a single hormone, and very little on the cross-talks between two hormones. Here we characterize the nature of interactions between thyroid hormone and glucocorticoid signaling during Xenopus tropicalis metamorphosis. Methods: We used functional genomics to derive genome wide profiles of methylated DNA and measured changes of gene expression after hormonal treatments of a highly responsive tissue, tailfin. Clustering classified the data into four types of biological responses, and biological networks were Citation: Buisine, N.; Grimaldi, A.; modeled by system biology. Results: We found that gene expression is mostly regulated by either Jonchere, V.; Rigolet, M.; Blugeon, C.; T or CORT, or their additive effect when they both regulate the same genes. A small but non- Hamroune, J.; Sachs, L.M. -
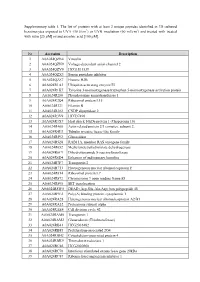
Supplementary Table 1. the List of Proteins with at Least 2 Unique
Supplementary table 1. The list of proteins with at least 2 unique peptides identified in 3D cultured keratinocytes exposed to UVA (30 J/cm2) or UVB irradiation (60 mJ/cm2) and treated with treated with rutin [25 µM] or/and ascorbic acid [100 µM]. Nr Accession Description 1 A0A024QZN4 Vinculin 2 A0A024QZN9 Voltage-dependent anion channel 2 3 A0A024QZV0 HCG1811539 4 A0A024QZX3 Serpin peptidase inhibitor 5 A0A024QZZ7 Histone H2B 6 A0A024R1A3 Ubiquitin-activating enzyme E1 7 A0A024R1K7 Tyrosine 3-monooxygenase/tryptophan 5-monooxygenase activation protein 8 A0A024R280 Phosphoserine aminotransferase 1 9 A0A024R2Q4 Ribosomal protein L15 10 A0A024R321 Filamin B 11 A0A024R382 CNDP dipeptidase 2 12 A0A024R3V9 HCG37498 13 A0A024R3X7 Heat shock 10kDa protein 1 (Chaperonin 10) 14 A0A024R408 Actin related protein 2/3 complex, subunit 2, 15 A0A024R4U3 Tubulin tyrosine ligase-like family 16 A0A024R592 Glucosidase 17 A0A024R5Z8 RAB11A, member RAS oncogene family 18 A0A024R652 Methylenetetrahydrofolate dehydrogenase 19 A0A024R6C9 Dihydrolipoamide S-succinyltransferase 20 A0A024R6D4 Enhancer of rudimentary homolog 21 A0A024R7F7 Transportin 2 22 A0A024R7T3 Heterogeneous nuclear ribonucleoprotein F 23 A0A024R814 Ribosomal protein L7 24 A0A024R872 Chromosome 9 open reading frame 88 25 A0A024R895 SET translocation 26 A0A024R8W0 DEAD (Asp-Glu-Ala-Asp) box polypeptide 48 27 A0A024R9E2 Poly(A) binding protein, cytoplasmic 1 28 A0A024RA28 Heterogeneous nuclear ribonucleoprotein A2/B1 29 A0A024RA52 Proteasome subunit alpha 30 A0A024RAE4 Cell division cycle 42 31 -

The Regulation of Telomerase Reverse Transcriptase (TERT) by CCAAT/Enhancer Binding Protein Β (C/Ebpβ) During Skeletal Muscle Differentiation
The Regulation of Telomerase Reverse Transcriptase (TERT) by CCAAT/Enhancer Binding Protein β (C/EBPβ) During Skeletal Muscle Differentiation Kira Slivitzky This thesis is submitted as a partial fulfillment of the M.Sc. program in Cellular and Molecular Medicine Department of Cellular and Molecular Medicine Faculty of Medicine University of Ottawa Date of final submission: November 2, 2017 © Kira Slivitzky, Ottawa, Canada, 2017 ABSTRACT Our lab has identified the bZIP transcription factor CCAAT/Enhancer Binding Protein beta (C/EBPβ) as a negative regulator of myogenic differentiation. C/EBPβ is highly expressed in satellite cells and is downregulated during myogenic differentiation, a step that is critical for terminal differentiation, as ectopic C/EBPβ expression blocks this process. Telomerase has been identified as a C/EBPβ target gene in liver and other systems, and has been implicated in the regulation of muscle regenerative responses in models of Duchenne Muscular Dystrophy. Given that C/EBPβ is overexpressed in models of muscle wasting, and high levels of telomerase inhibit differentiation, I hypothesized that C/EBPβ inhibits myogenic differentiation through upregulation of TERT (telomerase reverse transcriptase) expression. I demonstrate that overexpression of C/EBPβ in myoblasts increases mTERT expression under both growth and differentiation conditions. Conversely, loss of C/EBPβ expression in myoblasts using shRNA technology or after isolation of primary myoblasts from conditional knockout mice, results in a downregulation of TERT expression and activity. When TERT was pharmacologically inhibited or knocked down using a shRNA, there was a significant improvement in differentiation and fusion in C2C12 myoblasts overexpressing C/EBPβ as evidenced by an increase in the number of MHC+ fibers and expression of muscle-specific differentiation genes. -

Glossary of Terms
GLOSSARY OF TERMS Table of Contents A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z A Amino acids: any of a class of 20 molecules that are combined to form proteins in living things. The sequence of amino acids in a protein and hence protein function are determined by the genetic code. From http://www.geneticalliance.org.uk/glossary.htm#C • The building blocks of proteins, there are 20 different amino acids. From https://www.yourgenome.org/glossary/amino-acid Antisense: Antisense nucleotides are strings of RNA or DNA that are complementary to "sense" strands of nucleotides. They bind to and inactivate these sense strands. They have been used in research, and may become useful for therapy of certain diseases (See Gene silencing). From http://www.encyclopedia.com/topic/Antisense_DNA.aspx. Antisense and RNA interference are referred as gene knockdown technologies: the transcription of the gene is unaffected; however, gene expression, i.e. protein synthesis (translation), is lost because messenger RNA molecules become unstable or inaccessible. Furthermore, RNA interference is based on naturally occurring phenomenon known as Post-Transcriptional Gene Silencing. From http://www.ncbi.nlm.nih.gov/probe/docs/applsilencing/ B Biobank: A biobank is a large, organised collection of samples, usually human, used for research. Biobanks catalogue and store samples using genetic, clinical, and other characteristics such as age, gender, blood type, and ethnicity. Some samples are also categorised according to environmental factors, such as whether the donor had been exposed to some substance that can affect health. -

A Clinically Validated Human Capillary Blood Transcriptome Test for Global Systems Biology Studies
bioRxiv preprint doi: https://doi.org/10.1101/2020.05.22.110080; this version posted May 23, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. A clinically validated human capillary blood transcriptome test for global systems biology studies Ryan Toma1, Ben Pelle2, Nathan Duval1, Matthew M Parks1, Vishakh Gopu1, Hal Tily1, Andrew Hatch1, Ally Perlina1, Guruduth Banavar1, and Momchilo Vuyisich1* 1 Viome, Inc., Bellevue, WA, USA, viome.com, 2 The University of Washington, Seattle, USA *Corresponding author: Momchilo Vuyisich, [email protected] Abstract should be integrated into longitudinal, population- scale, systems biology studies. Chronic diseases are the leading cause of morbidity and mortality globally. Yet, the majority of Introduction them have unknown etiologies, and genetic Quantitative gene expression analysis contribution is weak. In addition, many of the chronic provides a global snapshot of tissue function. The diseases go through the cycles of relapse and human transcriptome varies with tissue type, remission, during which the genomic DNA does not developmental stage, environmental stimuli, and change. This strongly suggests that human gene health/disease state (Frith et al., 2005; Lin et al., 2019; expression is the main driver of chronic disease onset Marioni et al., 2008; Mortazavi et al., 2008; Velculescu and relapses. To identify the etiology of chronic et al., 1999). Changes in the expression patterns can diseases and develop more effective preventative provide insights into the molecular mechanisms of measures, a comprehensive gene expression analysis disease onset and progression. In the era of precision of the human body is needed.