Us-18-Chen-Keenlab-Ios-Jailbreak Internals2
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
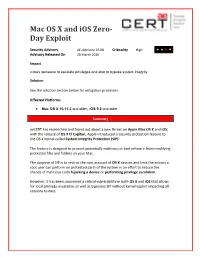
Mac OS X and Ios Zero- Day Exploit
Mac OS X and iOS Zero- Day Exploit Security Advisory AE-Advisory 16-08 Criticality High Advisory Released On 28 March 2016 Impact Allows someone to escalate privileges and also to bypass system integrity Solution See the solution section below for mitigation processes. Affected Platforms Mac OS X 10.11.3 and older, iOS 9.2 and older Summary aeCERT has researched and found out about a new threat on Apple Mac OS X and iOS; with the release of OS X El Capitan, Apple introduced a security protection feature to the OS X kernel called System Integrity Protection (SIP). The feature is designed to prevent potentially malicious or bad software from modifying protected files and folders on your Mac. The purpose of SIP is to restrict the root account of OS X devices and limit the actions a root user can perform on protected parts of the system in an effort to reduce the chance of malicious code hijacking a device or performing privilege escalation. However, it has been uncovered a critical vulnerability in both OS X and iOS that allows for local privilege escalation as well as bypasses SIP without karnel exploit impacting all versions to date. Threat Details The zero day vulnerability is a Non-Memory Corruption bug that allows hackers to execute arbitrary code on any targeted machine, perform remote code execution (RCE) or sandbox escapes. The attacker then escalates the malware's privileges to bypass System Integrity Protection SIP, alter system files, and then stay on the infected system. By default, System Integrity Protection or SIP protects these folders: /System. -
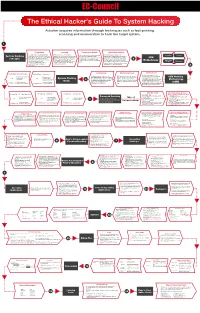
Download the Ethical Hacker's Guide to System Hacking
The Ethical Hacker's Guide To System Hacking Attacker acquires information through techniques such as foot printing, scanning and enumeration to hack the target system. 1 Footprinting Scanning Enumeration Module Vulnerability Analysis It is the process of accumulating data Vulnerability Assessment is an This is a procedure for identifying This is a method of intrusive probing, Footprinting Scanning System Hacking regarding a specific network environment. active hosts, open ports, and unnecessary through which attackers gather examination of the ability of a system or In this phase, the attacker creates a profile services enabled on ports. Attackers use information such as network user lists, application, including current security CEH concepts of the target organization, obtaining different types of scanning, such as port routing tables, security flaws, and procedures, and controls to with stand 2 information such as its IP address range, scanning network scanning, and simple network protocol data (SNMP) assault. Attackers perform this analysis Methodology Vulnerability namespace and employees. Enumeration vulnerability, scanning of target networks data. to identify security loopholes, in the target Analysis Footprinting eases the process of or systems which help in identifying organization’s network, communication system hacking by revealing its possible vulnerabilities. infrastructure, and end systems. vulnerabilities 3 Clearing Logs Maintaining Access Gaining Access Hacking Stage Escalating Privileges Hacking Stage Gaining Access It involves gaining access to To maintain future system access, After gaining access to the target low-privileged user accounts by To acquire the rights of To bypass access CEH Hacking attackers attempt to avoid recognition system, attackers work to maintain cracking passwords through Goal another user or Goal controls to gain System Hacking by legitimate system users. -

Android Exploits Commanding Higher Price Than Ever Before
Memo 10/09/2019 - TLP:WHITE Android exploits commanding higher price than ever before Reference: Memo [190910-1] – Version: 1.0 Keywords: Android, iOS, exploit, vulnerability Sources: Zerodium, Google, Wired Key Points The price of android exploits exceeds the price of iOS exploits for the first time This is possibly because Android security is improving over iOS The release of Android 10 is also a likely cause for the price hike Summary Zerodium1, a cyber security exploit broker dealing in zero-day vulnerabilities, has published its most recent price list. It indicates that the price of an Android full-chain exploit with persistence can fetch the developer up to 2,500,000 dollars. The going rate for a similar exploit for Apple’s iOS has gone down by 500,000 dollars and is now worth 2,000,000. This is the first confirmed time when Android exploits are valued more than iOS. Zerodium payouts for mobile devices Up to $2,500,000 Android zero click full compromise chain with persistence. Up to $2,000,000 iOS zero click full compromise chain with persistence. Up to $1,500,000 WhatsApp zero click remote code execution with iMessage remote code execution with local local privilege escalation on iOS or Android. privilege escalation. Up to $1,000,000 WhatsApp remote code execution with local privilege SMS/MMS remote code execution with local escalation on iOS or Android. privilege escalation on iOS or Android. Comments Zero-click exploits do not require interaction from the user. This is very difficult to achieve and thus commands the highest prices. -

Extreme Privilege Escalation on Windows 8/UEFI Systems
Extreme Privilege Escalation on Windows 8/UEFI Systems C o r e y K a l l e n b e r g @ c o r e y k a l X e n o K o v a h @ x e n o k o v a h John Butterworth @jwbutterworth3 Sam Cornwell @ssc0rnwell © 2014 The MITRE Corporation. All rights reserved. | 2 | Introduction . Who we are: – Trusted Computing and firmware security researchers at The MITRE Corporation . What MITRE is: – A not-for-profit company that runs six US Government "Federally Funded Research & Development Centers" (FFRDCs) dedicated to working in the public interest – Technical lead for a number of standards and structured data exchange formats such as CVE, CWE, OVAL, CAPEC, STIX, TAXII, etc – The first .org, !(.mil | .gov | .com | .edu | .net), on the ARPANET © 2014 The MITRE Corporation. All rights reserved. | 3 | Attack Model (1 of 2) . We’ve gained administrator access on a victim Windows 8 machine . But we are still constrained by the limits of Ring 3 © 2014 The MITRE Corporation. All rights reserved. | 4 | Attack Model (2 of 2) . As attackers we always want – More Power – More Persistence – More Stealth © 2014 The MITRE Corporation. All rights reserved. | 5 | Typical Post-Exploitation Privilege Escalation . Starting with x64 Windows vista, kernel drivers must be signed and contain an Authenticode certificate . In a typical post-exploitation privilege escalation, attacker wants to bypass the signed driver requirement to install a kernel level rootkit . Various methods to achieve this are possible, including: – Exploit existing kernel drivers – Install a legitimate (signed), but vulnerable, driver and exploit it . -

Towards Taming Privilege-Escalation Attacks on Android
Towards Taming Privilege-Escalation Attacks on Android Sven Bugiel1, Lucas Davi1, Alexandra Dmitrienko3, Thomas Fischer2, Ahmad-Reza Sadeghi1;3, Bhargava Shastry3 1CASED/Technische Universitat¨ Darmstadt, Germany 2Ruhr-Universitat¨ Bochum, Germany fsven.bugiel,lucas.davi,[email protected] thomas.fi[email protected] 3Fraunhofer SIT, Darmstadt, Germany falexandra.dmitrienko,ahmad.sadeghi,[email protected] Abstract 1. Introduction Android’s security framework has been an appealing sub- Google Android [1] has become one of the most popular ject of research in the last few years. Android has been operating systems for various mobile platforms [23, 3, 31] shown to be vulnerable to application-level privilege esca- with a growing market share [21]. Concerning security and lation attacks, such as confused deputy attacks, and more privacy aspects, Android deploys application sandboxing recently, attacks by colluding applications. While most of and a permission framework implemented as a reference the proposed approaches aim at solving confused deputy at- monitor at the middleware layer to control access to system tacks, there is still no solution that simultaneously addresses resources and mediate application communication. collusion attacks. The current Android business and usage model allows developers to upload arbitrary applications to the Android In this paper, we investigate the problem of designing and app market1 and involves the end-user in granting permis- implementing a practical security framework for Android to sions to applications at install-time. This, however, opens protect against confused deputy and collusion attacks. We attack surfaces for malicious applications to be installed on realize that defeating collusion attacks calls for a rather users’ devices (see, for instance, the recent DroidDream system-centric solution as opposed to application-dependent Trojan [6]). -

By Zohaib & Vlad
Follow the slides: goo.gl/bvmYgb Privilege Escalation in Windows OS by Zohaib & Vlad Follow the slides: goo.gl/bvmYgb What is Privilege Escalation? An act of exploiting a bug, design flaw or configuration oversight with the goal to gain elevated access to application resources ● Gives the ability to perform unauthorized actions in software, web apps, operating systems What is Privilege Escalation? Vertical Horizontal Accesses to functions that are Accesses functions that are reserved for higher privilege users accessible by other normal users. or applications. ● gaining administrative privileges ● Accessing accounts on the same user level ● Jailbreaking Devices ● Lock Screen Bypass ● Stealing usernames/passwords Vertical: Cross-zone scripting A web browser exploit that takes advantage of a zone-based vulnerability http://windowsupdate.microsoft.com%2f.example.com/ Windows Permission Structure ● root is “Local System” Account ● Windows UAC (User Account Control) ○ disabled admin account, instead uses UAC ● “sudo” is “runas” to run with privileges Types of Accounts: ● Local User ● Domain User ● The LocalSystem Windows with User Access Control ● All users run as an unprivileged user by default, even when logged on as an Administrator. ● Once running, the privilege of an application cannot be changed. ● Users are prompted to provide explicit consent before using elevated privilege, which then lasts for the life of the process. Windows OS Privilege Escalation ● replacing “screensaver” binary ● scan the registry for ○ logon Information ○ network -

All Roads Lead to SYSTEM
MWR Labs Whitepaper All Roads Lead to SYSTEM Kostas Lintovois Contents page Contents page............................................................................................ 2 1. Introduction ............................................................................................ 3 1.1 Windows Service Accounts ......................................................................... 4 2. Auditing Windows Services ......................................................................... 5 2.1 Insecure File System Permissions .................................................................. 5 2.2 Insecure Registry Permissions ...................................................................... 8 2.3 Insecure Named Pipe Permissions ................................................................ 10 2.4 Insecure Service Permissions ...................................................................... 12 2.5 Missing DLLs......................................................................................... 15 2.6 Unquoted Service Binary Paths ................................................................... 18 3. Service Exploitation ................................................................................ 21 4. Scripted Assessment ............................................................................... 23 5. Summary .............................................................................................. 24 6. References .......................................................................................... -

W32.Stuxnet Dossier Version 1.3 (November 2010)
Security Response W32.Stuxnet Dossier Version 1.3 (November 2010) Nicolas Falliere, Liam O Murchu, and Eric Chien While the bulk of the analysis is complete, Stuxnet is an incredibly large and Contents complex threat. The authors expect to make revisions to this document Introduction ....................................................... 1 shortly after release as new information is uncovered or may be publicly Executive Summary ........................................... 2 disclosed. This paper is the work of numerous individuals on the Syman- Attack Scenario .................................................. 3 tec Security Response team over the last three months well beyond the Timeline .............................................................. 4 cited authors. Without their assistance, this paper would not be possible. Infection Statistics ............................................. 5 Stuxnet Architecture.......................................... 8 Introduction Installation ....................................................... 12 Load Point ........................................................ 16 W32.Stuxnet has gained a lot of attention from researchers and me- Command and Control ......................................17 dia recently. There is good reason for this. Stuxnet is one of the Windows Rootkit Functionality ....................... 20 most complex threats we have analyzed. In this paper we take a de- Stuxnet Propagation Methods......................... 21 tailed look at Stuxnet and its various components and particularly -

Active Directory Privilege Escalation
Active Directory Privilege Escalation The World’s #1 Cyber Security Risk Contents 1. Executive Summary (Non-Technical Audience) …………….……………………………………….. 1 2. Executive Summary (Technical Audience) ……..………………………………………………………. 2 3. Root Cause Example, Top-5 Attack Vectors, Multi-step Escalation …..………….….. 3 – 5 4. Minutes to Compromise, Six Myths, 100% Mitigatable, Risk Mitigation ……....... 6 – 9 Active Directory Privilege Escalation Executive Summary Microsoft Active Directory is the very foundation of cyber security and privileged access at 85% of organizations, and within Active Directory deployments lie thousands of privilege escalation paths. Anyone who could identify these privilege escalation paths in Active Directory could easily compromise virtually any IT resource of choice, and in the worst case, the entire foundational Active Directory itself. This is alarming considering that historically 100% of all major recent cyber security breaches involved the compromise and misuse of a single account that possessed privileged access in Active Directory. In organizations that operate on the Microsoft Windows Server platform, the entirety of their building blocks of cyber security i.e. all organizational user accounts, computer accounts, and security groups that protect all organizational IT resources, are stored, managed and secured in Active Directory. These building blocks are represented as Active Directory objects and protected by access control lists (ACLs) within which lie permissions that allow and deny access to a large number of users and groups. In every Active Directory domain, within ACLs of thousands of Active Directory objects lie hundreds of thousands of permissions and it is their net cumulative resulting effect i.e. effective permissions that govern who has what privileged access on each one of these thousands of Active Directory objects. -

Malicious Code, Aka, Malware
Malicious Code, aka, Malware Vijay Ganesh ECE 458, Winter 2013 University of Waterloo Previous Lectures on Aacks • Control-hijack attacks • Exploiting buffer and integer overElow • How the attacker can take control of a machine • We also discusseD techniques to prevent, detect and recover from control-hijack attacks • But, what about the payload? • The entire package is often calleD a virus, worm,… Many of the sliDes are courtesy DaviD Brumley (CMU) 2 Today’s Lecture • Taxonomy of virus, worms,… • How virus propagate • How worms propagate • Detailed discussion of Stuxnet anD Aurora • 3 phases of a successful attack: • Social engineering • Exploit • Propagate, install and create havoc 3 The first worm Catch me if you can. Name: “Creeper” worm, 1971 Author: BoB Thomas, BBN Vector: ARPANET DEC PDP-10 computers 4 Taxonomy of malicious code Virus Worm Rootkit AdvanceD Trojan Malware Persistent Threat Spyware Grayware Triggered 5 Defn: ExecutaBle code Virus hosteD in a larger program. Worm Rootkit Does not self-replicate AdvanceD Trojan Host program Malware Virus Persistent Threat NotaBle example: “Elk Cloner” Spyware First virus found in the wild Grayware Triggered Written in 1981 by Rich Skrenta of Mt. LeBanon High School, PA 6 Computer B worm Defn: Virus Worm Self propagating Rootkit Exploit malicious coDe Computer A Computer C Step 1: Exploit AdvanceD Scan Persistent Trojan worm Malware worm Step 2: Threat Attack Step 3: Copy Spyware Grayware Triggered NotaBle example: “Morris worm”, 1982 Robert Tappen Morris, irst conviction of computer frauD anD aBuse act 7 Defn: Program to hide attackers Virus presence. Worm Rootkit Kernel Space redirect calls to rootkit coDe AdvanceD Example: Trojan System Call Malware Persistent Threat User Space Spyware Grayware Triggered NotaBle example: “Brain Virus”, 1986 First PC virus, intercepted and redirected calls to read boot sector. -

Preventing Privilege Escalation
Preventing Privilege Escalation Niels Provos Markus Friedl Peter Honeyman CITI, University of Michigan GeNUA CITI, University of Michigan Abstract gain extra privilege after successful authentication lim- its the degree of escalation because the user is already Many operating system services require special priv- authorized to hold some privilege. On the other hand, ilege to execute their tasks. A programming error in a a remote adversary gaining superuser privilege with no privileged service opens the door to system compromise authentication presents a greater degree of escalation. in the form of unauthorized acquisition of privileges. In For services that are part of the critical Internet the worst case, a remote attacker may obtain superuser infrastructure is it particularly important to protect privileges. In this paper, we discuss the methodology against programming errors. Sometimes these services and design of privilege separation, a generic approach need to retain special privilege throughout their life- that lets parts of an application run with different levels time. For example, in SSH, the SSH daemon needs to of privilege. Programming errors occurring in the un- know the private host key during re-keying to authenti- privileged parts can no longer be abused to gain unau- cate the key exchange. The daemon also needs to open thorized privileges. Privilege separation is orthogonal new pseudo-terminals when the SSH client so requests. to capability systems or application confinement and These operations require durable special privilege as enhances the security of such systems even further. they can be requested at any time during the lifetime Privilege separation is especially useful for system of a SSH connection. -

Privilege Escalation Detect, Investigate and Respond to Privilege Escalation Incidents
Solution Brief Privilege Escalation Detect, Investigate and Respond to Privilege Escalation Incidents Privilege escalation refers to an attack where the attacker gains higher-level permissions or unauthorized access to privileged user accounts or assets. The attacker might use an enumeration tool to find a valid account to compromise, switch to an account with greater access privileges or increase permissions on a compromised user or system to elevate their access. Security teams struggle to detect APT10, or Red Apollo, is a Chinese attacks using privilege escalation cyber espionage group that leverages privilege escalation to Privilege escalation is the fourth most common tactic deliver malware and steal intellectual used in reported data breaches1. However, many property. APT10 has been linked to legacy security systems that rely on static correlation Cloud Hopper, considered one of the rules are unable to detect when an attacker escalates largest-ever corporate espionage privileges. Additionally, a privileged user’s work efforts. patterns may not occur in regular, predictable patterns, making it difficult to detect privilege Source: Operation Cloud Hopper escalation with legacy tools. If undetected, a privilege escalation can give an adversary access to high value assets with impunity. The result of a privilege escalation attack can be devastating to an organization, as these attacks gain access to networks, typically with the aim of exfiltrating data, disrupting business activity, or installing backdoors to enable continued access to internal systems. Solution Brief Privilege Escalation EXABEAM AND PRIVILEGE and assets, or permission changes in the context of ESCALATION the historic behavior of that user, their peers and their organization to clearly distinguish adversary behavior Exabeam helps security teams outsmart adversaries from normal activity.