Wikidata Through the Eyes of Dbpedia
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Wikipedia's Economic Value
WIKIPEDIA’S ECONOMIC VALUE Jonathan Band and Jonathan Gerafi policybandwidth In the copyright policy debate, proponents of strong copyright protection tend to be dismissive of the quality of freely available content. In response to counter- examples such as open access scholarly publications and advertising-supported business models (e.g., newspaper websites and the over-the-air television broadcasts viewed by 50 million Americans), the strong copyright proponents center their attack on amateur content. In this narrative, YouTube is for cat videos and Wikipedia is a wildly unreliable source of information. Recent studies, however, indicate that the volunteer-written and -edited Wikipedia is no less reliable than professionally edited encyclopedias such as the Encyclopedia Britannica.1 Moreover, Wikipedia has far broader coverage. Britannica, which discontinued its print edition in 2012 and now appears only online, contains 120,000 articles, all in English. Wikipedia, by contrast, has 4.3 million articles in English and a total of 22 million articles in 285 languages. Wikipedia attracts more than 470 million unique visitors a month who view over 19 billion pages.2 According to Alexa, it is the sixth most visited website in the world.3 Wikipedia, therefore, is a shining example of valuable content created by non- professionals. Is there a way to measure the economic value of this content? Because Wikipedia is created by volunteers, is administered by a non-profit foundation, and is distributed for free, the normal means of measuring value— such as revenue, market capitalization, and book value—do not directly apply. Nonetheless, there are a variety of methods for estimating its value in terms of its market value, its replacement cost, and the value it creates for its users. -

What Do Wikidata and Wikipedia Have in Common? an Analysis of Their Use of External References
What do Wikidata and Wikipedia Have in Common? An Analysis of their Use of External References Alessandro Piscopo Pavlos Vougiouklis Lucie-Aimée Kaffee University of Southampton University of Southampton University of Southampton United Kingdom United Kingdom United Kingdom [email protected] [email protected] [email protected] Christopher Phethean Jonathon Hare Elena Simperl University of Southampton University of Southampton University of Southampton United Kingdom United Kingdom United Kingdom [email protected] [email protected] [email protected] ABSTRACT one hundred thousand. These users have gathered facts about Wikidata is a community-driven knowledge graph, strongly around 24 million entities and are able, at least theoretically, linked to Wikipedia. However, the connection between the to further expand the coverage of the knowledge graph and two projects has been sporadically explored. We investigated continuously keep it updated and correct. This is an advantage the relationship between the two projects in terms of the in- compared to a project like DBpedia, where data is periodically formation they contain by looking at their external references. extracted from Wikipedia and must first be modified on the Our findings show that while only a small number of sources is online encyclopedia in order to be corrected. directly reused across Wikidata and Wikipedia, references of- Another strength is that all the data in Wikidata can be openly ten point to the same domain. Furthermore, Wikidata appears reused and shared without requiring any attribution, as it is to use less Anglo-American-centred sources. These results released under a CC0 licence1. -

Position Description Addenda
POSITION DESCRIPTION January 2014 Wikimedia Foundation Executive Director - Addenda The Wikimedia Foundation is a radically transparent organization, and much information can be found at www.wikimediafoundation.org . That said, certain information might be particularly useful to nominators and prospective candidates, including: Announcements pertaining to the Wikimedia Foundation Executive Director Search Kicking off the search for our next Executive Director by Former Wikimedia Foundation Board Chair Kat Walsh An announcement from Wikimedia Foundation ED Sue Gardner by Wikimedia Executive Director Sue Gardner Video Interviews on the Wikimedia Community and Foundation and Its History Some of the values and experiences of the Wikimedia Community are best described directly by those who have been intimately involved in the organization’s dramatic expansion. The following interviews are available for viewing though mOppenheim.TV . • 2013 Interview with Former Wikimedia Board Chair Kat Walsh • 2013 Interview with Wikimedia Executive Director Sue Gardner • 2009 Interview with Wikimedia Executive Director Sue Gardner Guiding Principles of the Wikimedia Foundation and the Wikimedia Community The following article by Sue Gardner, the current Executive Director of the Wikimedia Foundation, has received broad distribution and summarizes some of the core cultural values shared by Wikimedia’s staff, board and community. Topics covered include: • Freedom and open source • Serving every human being • Transparency • Accountability • Stewardship • Shared power • Internationalism • Free speech • Independence More information can be found at: https://meta.wikimedia.org/wiki/User:Sue_Gardner/Wikimedia_Foundation_Guiding_Principles Wikimedia Policies The Wikimedia Foundation has an extensive list of policies and procedures available online at: http://wikimediafoundation.org/wiki/Policies Wikimedia Projects All major projects of the Wikimedia Foundation are collaboratively developed by users around the world using the MediaWiki software. -

Wikibase Knowledge Graphs for Data Management & Data Science
Business and Economics Research Data Center https://www.berd-bw.de Baden-Württemberg Wikibase knowledge graphs for data management & data science Dr. Renat Shigapov 23.06.2021 @shigapov @_shigapov DATA Motivation MANAGEMENT 1. people DATA SCIENCE knowledg! 2. processes information linking 3. technology data things KNOWLEDGE GRAPHS 2 DATA Flow MANAGEMENT Definitions DATA Wikidata & Tools SCIENCE Local Wikibase Wikibase Ecosystem Summary KNOWLEDGE GRAPHS 29.10.2012 2030 2021 3 DATA Example: Named Entity Linking SCIENCE https://commons.wikimedia.org/wiki/File:Entity_Linking_-_Short_Example.png Rule#$as!d problems Machine Learning De!' Learning Learn data science at https://www.kaggle.com 4 https://commons.wikimedia.org/wiki/File:Data_visualization_process_v1.png DATA Example: general MANAGEMENT research data silos data fabric data mesh data space data marketplace data lake data swamp Research data lifecycle https://www.reading.ac.uk/research-services/research-data-management/ 5 https://www.dama.org/cpages/body-of-knowledge about-research-data-management/the-research-data-lifecycle KNOWLEDGE ONTOLOG( + GRAPH = + THINGS https://www.mediawiki.org https://www.wikiba.se ✔ “Things, not strings” by Google, 2012 + ✔ A knowledge graph links things in different datasets https://mariadb.org https://blazegraph.com ✔ A knowledge graph can link people & relational database graph database processes and enhance technologies The main example: “THE KNOWLEDGE GRAPH COOKBOOK RECIPES THAT WORK” by ANDREAS BLUMAUER & HELMUT NAGY, 2020. https://www.wikidata.org -

Wikipedia Knowledge Graph with Deepdive
The Workshops of the Tenth International AAAI Conference on Web and Social Media Wiki: Technical Report WS-16-17 Wikipedia Knowledge Graph with DeepDive Thomas Palomares Youssef Ahres [email protected] [email protected] Juhana Kangaspunta Christopher Re´ [email protected] [email protected] Abstract This paper is organized as follows: first, we review the related work and give a general overview of DeepDive. Sec- Despite the tremendous amount of information on Wikipedia, ond, starting from the data preprocessing, we detail the gen- only a very small amount is structured. Most of the informa- eral methodology used. Then, we detail two applications tion is embedded in unstructured text and extracting it is a non trivial challenge. In this paper, we propose a full pipeline that follow this pipeline along with their specific challenges built on top of DeepDive to successfully extract meaningful and solutions. Finally, we report the results of these applica- relations from the Wikipedia text corpus. We evaluated the tions and discuss the next steps to continue populating Wiki- system by extracting company-founders and family relations data and improve the current system to extract more relations from the text. As a result, we extracted more than 140,000 with a high precision. distinct relations with an average precision above 90%. Background & Related Work Introduction Until recently, populating the large knowledge bases relied on direct contributions from human volunteers as well With the perpetual growth of web usage, the amount as integration of existing repositories such as Wikipedia of unstructured data grows exponentially. Extract- info boxes. These methods are limited by the available ing facts and assertions to store them in a struc- structured data and by human power. -

Wiki-Reliability: a Large Scale Dataset for Content Reliability on Wikipedia
Wiki-Reliability: A Large Scale Dataset for Content Reliability on Wikipedia KayYen Wong∗ Miriam Redi Diego Saez-Trumper Outreachy Wikimedia Foundation Wikimedia Foundation Kuala Lumpur, Malaysia London, United Kingdom Barcelona, Spain [email protected] [email protected] [email protected] ABSTRACT Wikipedia is the largest online encyclopedia, used by algorithms and web users as a central hub of reliable information on the web. The quality and reliability of Wikipedia content is maintained by a community of volunteer editors. Machine learning and information retrieval algorithms could help scale up editors’ manual efforts around Wikipedia content reliability. However, there is a lack of large-scale data to support the development of such research. To fill this gap, in this paper, we propose Wiki-Reliability, the first dataset of English Wikipedia articles annotated with a wide set of content reliability issues. To build this dataset, we rely on Wikipedia “templates”. Tem- plates are tags used by expert Wikipedia editors to indicate con- Figure 1: Example of an English Wikipedia page with several tent issues, such as the presence of “non-neutral point of view” template messages describing reliability issues. or “contradictory articles”, and serve as a strong signal for detect- ing reliability issues in a revision. We select the 10 most popular 1 INTRODUCTION reliability-related templates on Wikipedia, and propose an effective method to label almost 1M samples of Wikipedia article revisions Wikipedia is one the largest and most widely used knowledge as positive or negative with respect to each template. Each posi- repositories in the world. People use Wikipedia for studying, fact tive/negative example in the dataset comes with the full article checking and a wide set of different information needs [11]. -

Knowledge Graphs on the Web – an Overview Arxiv:2003.00719V3 [Cs
January 2020 Knowledge Graphs on the Web – an Overview Nicolas HEIST, Sven HERTLING, Daniel RINGLER, and Heiko PAULHEIM Data and Web Science Group, University of Mannheim, Germany Abstract. Knowledge Graphs are an emerging form of knowledge representation. While Google coined the term Knowledge Graph first and promoted it as a means to improve their search results, they are used in many applications today. In a knowl- edge graph, entities in the real world and/or a business domain (e.g., people, places, or events) are represented as nodes, which are connected by edges representing the relations between those entities. While companies such as Google, Microsoft, and Facebook have their own, non-public knowledge graphs, there is also a larger body of publicly available knowledge graphs, such as DBpedia or Wikidata. In this chap- ter, we provide an overview and comparison of those publicly available knowledge graphs, and give insights into their contents, size, coverage, and overlap. Keywords. Knowledge Graph, Linked Data, Semantic Web, Profiling 1. Introduction Knowledge Graphs are increasingly used as means to represent knowledge. Due to their versatile means of representation, they can be used to integrate different heterogeneous data sources, both within as well as across organizations. [8,9] Besides such domain-specific knowledge graphs which are typically developed for specific domains and/or use cases, there are also public, cross-domain knowledge graphs encoding common knowledge, such as DBpedia, Wikidata, or YAGO. [33] Such knowl- edge graphs may be used, e.g., for automatically enriching data with background knowl- arXiv:2003.00719v3 [cs.AI] 12 Mar 2020 edge to be used in knowledge-intensive downstream applications. -
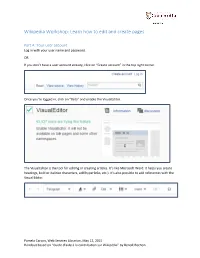
Wikipedia Workshop: Learn How to Edit and Create Pages
Wikipedia Workshop: Learn how to edit and create pages Part A: Your user account Log in with your user name and password. OR If you don’t have a user account already, click on “Create account” in the top right corner. Once you’re logged in, click on “Beta” and enable the VisualEditor. The VisualEditor is the tool for editing or creating articles. It’s like Microsoft Word: it helps you create headings, bold or italicize characters, add hyperlinks, etc.). It’s also possible to add references with the Visual Editor. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part B: Write a sentence or two about yourself Click on your username. This will lead you to your user page. The URL will be: https://en.wikipedia.org/wiki/User:[your user name] Exercise: Click on “Edit source” and write about yourself, then enter a description of your change in the “Edit summary” box and click “Save page”. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part C: Edit an existing article To edit a Wikipedia article, click on the tab “Edit” or “Edit source” (for more advanced users) available at the top of any page. These tabs are also available beside any section title within an article. Editing an entire page Editing just a section Need help? https://en.wikipedia.org/wiki/Wikipedia:Tutorial/Editing Exercise: Go to http://www.statcan.gc.ca/ and find a statistic that interests you. -
Building a Visual Editor for Wikipedia
Building a Visual Editor for Wikipedia Trevor Parscal and Roan Kattouw Wikimania D.C. 2012 (Introduce yourself) (Introduce yourself) We’d like to talk to you about how we’ve been building a visual editor for Wikipedia Trevor Parscal Roan Kattouw Rob Moen Lead Designer and Engineer Data Model Engineer User Interface Engineer Wikimedia Wikimedia Wikimedia Inez Korczynski Christian Williams James Forrester Edit Surface Engineer Edit Surface Engineer Product Analyst Wikia Wikia Wikimedia The People Wikimania D.C. 2012 We are only 2/6ths of the VisualEditor team Our team includes 2 engineers from Wikia - they also use MediaWiki They also fight crime in their of time Parsoid Team Gabriel Wicke Subbu Sastry Lead Parser Engineer Parser Engineer Wikimedia Wikimedia The People Wikimania D.C. 2012 There’s also two remote people working on a new parser This parser makes what we are doing with the VisualEditor possible The Project Wikimania D.C. 2012 You might recognize this, it’s a Wikipedia article You should edit it! Seems simple enough, just hit the edit button and be on your way... The Complexity Problem Wikimania D.C. 2012 Or not... What is all this nonsense you may ask? Well, it’s called Wikitext! Even really smart people who have a lot to contribute to Wikipedia find it confusing The truth is, Wikitext is a lousy IQ test, and it’s holding Wikipedia back, severely Active Editors 20k 0 2001 2007 Today Growth Stagnation The Complexity Problem Wikimania D.C. 2012 The internet has normal people on it now, not just geeks and weirdoes Normal people like simple things, and simple things are growing fast We must make editing Wikipedia easier to use, not just to grow, but even just to stay alive The Complexity Problem Wikimania D.C. -

Falcon 2.0: an Entity and Relation Linking Tool Over Wikidata
Falcon 2.0: An Entity and Relation Linking Tool over Wikidata Ahmad Sakor Kuldeep Singh [email protected] [email protected] L3S Research Center and TIB, University of Hannover Cerence GmbH and Zerotha Research Hannover, Germany Aachen, Germany Anery Patel Maria-Esther Vidal [email protected] [email protected] TIB, University of Hannover L3S Research Center and TIB, University of Hannover Hannover, Germany Hannover, Germany ABSTRACT Management (CIKM ’20), October 19–23, 2020, Virtual Event, Ireland. ACM, The Natural Language Processing (NLP) community has signifi- New York, NY, USA, 8 pages. https://doi.org/10.1145/3340531.3412777 cantly contributed to the solutions for entity and relation recog- nition from a natural language text, and possibly linking them to 1 INTRODUCTION proper matches in Knowledge Graphs (KGs). Considering Wikidata Entity Linking (EL)- also known as Named Entity Disambiguation as the background KG, there are still limited tools to link knowl- (NED)- is a well-studied research domain for aligning unstructured edge within the text to Wikidata. In this paper, we present Falcon text to its structured mentions in various knowledge repositories 2.0, the first joint entity and relation linking tool over Wikidata. It (e.g., Wikipedia, DBpedia [1], Freebase [4] or Wikidata [28]). Entity receives a short natural language text in the English language and linking comprises two sub-tasks. The first task is Named Entity outputs a ranked list of entities and relations annotated with the Recognition (NER), in which an approach aims to identify entity proper candidates in Wikidata. The candidates are represented by labels (or surface forms) in an input sentence. -

Cooperation of Russia's Wiki- Volunteers with the Institutions of the Republic of Tatarstan
ФАДН России Cooperation of Russia's Wiki- volunteers with the institutions of the Republic of Tatarstan «Language policy: practices from across Russia» Online dialogue forum Federal Agency for Ethnic Affairs (FADN), 18.12.2020 Farhad Fatkullin, materials - w.wiki/qT8 Distributed under Creative Commons Attribution-Share Alike 4.0 International free license pursuant to Art.1286 of the Russian Federation Civil Code Project objectives To assure To inspire other perseverance ethnic groups in and the Republic of development Tatarstan and of Tatar around Russia to language in the follow suit digital age Cooperation of Russia's Wiki-volunteers with the Republic of Tatarstan institutions — w.wiki/qT8 And who are you? * thinking, speaking and writing in 6 languages * Conference interpreting since 2000 * Bachelor of Management * Cross-cultural Communication & Interpreting Specialist * Taught Risk Management in English * Haven't been to the Arctic and Antarctic * 2018 Wikimedian of the Year Farhad Fatkullin, born 1979 * Volunteer secretary of «Wikipedias in Kazan the languages of Russia» initiative * Member of the Tatarstan Presidential [email protected] Commission for the Preservation and +7 9274 158066 Strengthening of Tatar language use (as frhdkazan @ Wikipedia Wikimedia RU Non-Profit Partnership representative) Cooperation of Russia's Wiki-volunteers with the Republic of Tatarstan institutions — w.wiki/qT8 Wiki-volunteering? «Imagine a world in which every single human being can freely share in the sum of all knowledge. That's our commitment.» Cooperation -

FOSDEM 2014 Crowdsourced Translation Using Mediawiki.Key
Crowdsourced translation using MediaWiki Siebrand Mazeland i18n/L10n contractor, Wikimedia Foundation Community Manager, translatewiki.net FOSDEM 2014 | Crowdsourced translation using MediaWiki | February 1, 2014 | Siebrand Mazeland | CC-BY-SA 3.0 Why translate using MediaWiki? Way back in 2004, MediaWiki was already there, and Niklas Laxström had an itch to scratch I.e. it wasn’t given much thought We still don’t regret it Started as a set of patches on MediaWiki core Versioning and tracking included for free Most translators already knew MediaWiki FOSDEM 2014 | Crowdsourced translation using MediaWiki | February 1, 2014 | Siebrand Mazeland | CC-BY-SA 3.0 translatewiki.net Using MediaWiki for localisation translatewiki.net the localisation platform for translation communities, language communities, and free and open source projects Supports online and offline translation for MediaWiki and other software FOSDEM 2014 | Crowdsourced translation using MediaWiki | February 1, 2014 | Siebrand Mazeland | CC-BY-SA 3.0 translatewiki.net Using MediaWiki for localisation FOSDEM 2014 | Crowdsourced translation using MediaWiki | February 1, 2014 | Siebrand Mazeland | CC-BY-SA 3.0 translatewiki.net Using MediaWiki for localisation 6.000 registered translators 25 free and open source projects 48.000 translatable strings 440 active translators per month 55.000 translations per month translators do not handle files FOSDEM 2014 | Crowdsourced translation using MediaWiki | February 1, 2014 | Siebrand Mazeland | CC-BY-SA 3.0 translatewiki.net Supported file