Applied Graph‑ Theoretic Approach for Two‑ Way to One‑ Way Road Network Conversion
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 4 the Provincial and Urban Level: Meeting the Local Needs
The provincial and urban level: meeting local needs Chapter 4 Chapter 4 The provincial and urban level: meeting the local needs Increasingly, cities and regions in developing countries adopt incentive- based transport strategies in order to raise local revenue and alleviate congestion and environmental problems in urban areas. Nevertheless, there is no blue print as to how to successfully manage transport demand on the local level. It should always be borne in mind that sound transport measures based on Economic Instruments: • are highly city-specific, depend on city size, level of develop- ment, road networks and transport demand characteristics, cultu- ral and educational factors that determine transport behaviour, fle- xibility in transport mode choice, public acceptance, institutional capacities to introduce and enforce measures, local institutional and jurisdictional independence from national transport policy fra- meworks; • are most effective if applied as part of a comprehensive transport strategy as outlined in chapters 1 and 2; On the regional and local level important Economic Instruments which are implemented in many countries include: • Surcharges on national/federal measures (see section 4.1), • Parking fees (see section 4.2), • Urban road and congestion pricing (see section 4.3). These measures will be discussed in more detail below. 87 Chapter 4 The provincial and urban level: meeting local needs Surcharges on national/federal measures Surcharges as a policy instrument The basic idea Local charges to Supplementing a national policy. Local conditions are often distinctly better meet the local different from national conditions. To cater for these differences, in needs. many countries Economic Instruments in transport are set at the natio- nal (federal) level to meet the basic national needs, but local govern- ments/authorities are allowed to levy a local/provincial surcharge on these charges. -
Download Project Reference
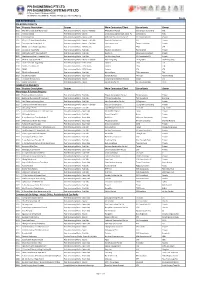
PPI ENGINEERING PTE LTD PPI ENGINEERING SYSTEMS PTE LTD 42 Pioneer Sector 2 Singapore 628393 Tel: 68989095 Fax: 68989785 Website: www.ppi.sg Email: [email protected] Date : Nov-16 JOB REFERENCES ON-GOING PROJECTS Year Projects Description Scopes Main Contractor/Client Consultants Owner 2016 GKE Warehouse at 39 Benoi Road Post-tensioning Works - Beams + Flat Slab HPC Builders Pte Ltd CS Engineers Consulting GKE 2016 Fernvale School Post-tensioning Works - Beams Zheng Keng Engineering & Const. PL Sembcorp AE MOE 2016 OVH at Sentosa Post-tensioning Works - Beams + Slab Woh Hup Construction Pte Ltd KCL Consultants P/L Private 2016 IDS at 279 Jalan Ahmad Ibrahim Post-tensioning Works - Beams + Flat Slab Hua Siah Construction KTP Private 2016 Factory at 10 Changi Sth St 2 Post-tensioning Works - Beams + Flat Slab Lida Construction Tenwit Consultant Private 2016 ER382 - Lornie Road Upgrading Post-tensioning Works - PSPC Beams Coninco TYLin LTA 2016 Ice Cave at Yung Ho Rd Post-tensioning Works - Flat Slab Hua Siah Construction Ronnie & Koh Private 2016 MRF Factory @ 7 Tuas South St 7 Post-tensioning Works - Flat Slab Buildform Milleniums Consultamt Private 2016 Warehouse at Plot 6 Tampines Drive Post-tensioning Works - Flat Slab Lim Wen heng Const. KCL Consultants P/L Private 2016 Shine at Tuas South Ave 7 Post-tensioning Works - Beams + Flat Slab Hock Liang Seng EP Engineers Hock Liang Seng 2016 ER397 - TPE/KPE Upgrading Post-tensioning Works - PSPC Beams Coninco TYLin LTA 2016 ER343 - Portsdown Rd Post-tensioning Works - PSPC Beams Coninco TYLin -

Policy Guidelines for Road Transport Pricing
ECONOMIC AND SOCIAL COMMISSION FOR ASIA AND THE PACIFIC POLICY GUIDELINES FOR ROAD TRANSPORT PRICING A Practical Step-by-Step Approach UNITED NATIONS Economic and Social Commission for Asia and the Pacific & Deutsche Gesellschaft für Technische Zusammenarbeit (GTZ) GmbH POLICY GUIDELINES FOR ROAD TRANSPORT PRICING A Practical Step-by-Step Approach Edited by: Deutsche Gesellschaft für Technische Zusammenarbeit (GTZ) GmbH, Germany; and the United Nations Economic and Social Commission for Asia and the Pacific (ESCAP) Financed by: Bundesministerium für wirtschaftliche Zusammenarbeit und Entwicklung (BMZ), Germany Authors: Jan A. Schwaab and Sascha Thielmann United Nations New York, 2002 ST/ESCAP/2216 Edited by: Deutsche Gesellschaft für Technische Zusammenarbeit (GTZ) GmbH Manfred Breithaupt; Division 44, Environmental Management, Water, Energy and Transport; Dag-Hammarskjöld-Weg 1-5, 65760 Eschborn, Germany Tel.: +49 (0) 6196 / 79 – 1267, Fax: +49 (0) 6196 / 79 - 7144 WWW: http://www.gtz.de United Nations Economic and Social Commission for Asia and the Pacific (ESCAP) Transport and Tourism Division The United Nations Building, Rajadamnern Nok Avenue, Bangkok 10200, Thailand Tel.: +66-2 / 288-1234, Fax: +66-2 / 288-1000, 288-3050 WWW: http://www.unescap.org/tctd/ Financed by: Bundesministerium für wirtschaftliche Zusammenarbeit und Entwicklung (BMZ) Friedrich-Ebert-Allee 40, 53113 Bonn, Germany Tel.: +49 (0) 228 / 535 – 0, Fax: +49 (0) 228 / 535 - 3500 WWW: http://www.bmz.de Authors: Jan A. Schwaab and Sascha Thielmann The authors wish to express their gratitude for the many constructive and helpful comments provided by Manfred Breithaupt, Karl Fjellstrom, Axel Friedrich, Gerhard Metschies, Martine Micozzi, Dieter Niemann, Anthony Ockwell and Werner Rothengatter. -

LAND TRANSPORT Master Plan 2013
LAND TRANSPORT master plan 2013 Contents Executive Summary 02 1 Taking Stock 06 1.1 Making Public Transport a Choice Mode of Travel 1.2 Managing Road Usage 1.3 Meeting Diverse Needs 1.4 How Did We Do? 2 Singapore: Today and Tomorrow 13 2.1 Key Areas of Concern 2.2 Immediate Challenges 2.3 Consulting the Public 2.4 How We Are Tackling the Challenges Ahead 2.5 What Will the Public See with LTMP 2013? 3 More Connections 19 3.1 Expanding Our Rail Network 3.2 More Bus Services 3.3 Facilitating More Walking and Cycling 3.4 Sustainable Expansion of the Road Network 4 Better Service 27 4.1 Improving Rail Services 4.2 Improving Bus Services 4.3 Welfare of Transport Workers 4.4 Taxis and Car-Sharing 4.5 Travelling the Smart Way 4.6 What Commuters Can Do 5 Liveable and Inclusive Community 38 5.1 No Barriers: Improving Mobility for Seniors and the Less Mobile 5.2 Reducing Noise Levels 5.3 Safer Roads for All 5.4 Environmental Sustainability 5.5 Reclaiming Our Public Spaces: Car-free and Car-less Zones 6 Reducing Reliance on Private Transport 43 6.1 The Vehicle Growth Rate 6.2 Stabilising Supply of COEs 6.3 Next Generation ERP 6.4 Tackling Congestion Today 6.5 Parking Policy 6.6 Enforcement Against Illegal Parking 6.7 A Mindset Shift 7 Our Vision 50 Annex A - Summary of Initiatives 53 Executive Summary Executive Summary All of us use land transport, from the pavements on which we walk, to the trains, buses and other vehicles that carry us and the roads that these vehicles use. -

Annual Report 2010/2011 Table of Vision: Contents a People-Centred Land Transport System
It’s all about... Annual Report 2010/2011 Table of Vision: Contents A people-centred land transport system. Mission: 14 Chairman’s Statement To provide an efficient and cost-effective 15 Chief Executive’s Message land transport system for different needs. 16 Board Members 20 Senior Management Strategic thrusts: 24 Organisation Chart • Make public transport a choice mode 26 Connectivity • Optimise road network and enhance 36 Mobility its accessibility 48 Innovation • Excel in service quality • Create value and instill pride in our work 58 Partnership 66 Resilience 71 LTA Subsidiaries 76 Major Contracts Awarded in FY10/11 84 Major Contracts to be Awarded in FY11/12 88 Awards Won in FY10/11 90 Significant Events 92 Financial Review ...you. Our fundamental goal is to improve land travel for you. The new MRT lines that we build, the new expressways that we construct, the old roads that we widen and the new traffic information systems that we create, these are all geared towards getting you to your destination as quickly, as pleasantly and as safely as possible. ...connectivity. We strive to provide a seamless travel experience on the public transport system. We want to ensure you are connected to your goals, your aspirations and your lifestyle. Land Transport Authority Annual Report 2010/2011 03 Land Transport Authority Annual Report 2010/2011 ...mobility. We are constantly improving the road network to provide smooth and pleasant journeys for you and your family. Land Transport Authority Annual Report 2010/2011 05 Land Transport Authority Annual Report 2010/2011 ...innovation. Our priority is to leverage technology and international best practices to make your commute safe, convenient and hassle-free. -

Circular No : URA/PB/2014/21-DCG Fax: 6227 4792 Our Ref : DC/ADMIN/CIRCULAR/PB 14 Date : 7 Oct 2014
Circular No : URA/PB/2014/21-DCG Fax: 6227 4792 Our Ref : DC/ADMIN/CIRCULAR/PB_14 Date : 7 Oct 2014 CIRCULAR TO PROFESSIONAL INSTITUTES Who should know Owners and tenants of shophouses, eating house operators, real estate agents, architects and engineers Effective date With effect from 7 October 2014 NEW LOCATIONS WHERE ADDITIONAL EATING HOUSES IN SHOPHOUSES WILL NOT BE ALLOWED 1. URA and the Land Transport Authority (LTA) have assessed the existing traffic and parking situations of the areas listed below as part of their periodic reviews. To prevent the existing parking and traffic problems from worsening, we will not be able to approve more eating houses in these areas. This is also to address the traffic and parking concerns from the residents there. 2. The seven new locations where additional eating houses in shophouses will not be allowed are: i) Changi Road - Jalan Eunos / Still Road to Jalan Kembangan / Frankel Avenue ii) Upper Paya Lebar Road - Lorong Ah Soo to Paya Lebar Crescent iii) Bukit Timah Road - Wilby Road to Elm Avenue - Anamalai Avenue to Fourth Avenue iv) Sembawang Road - Mandai Road to Transit Road iv) Kampong Glam v) Kampong Bahru Road / Spottiswoode Park Road vi) Jalan Riang 3. The full list of locations where new eating houses will not be allowed are in Appendix A. This supersedes the previous list in URA’s circular dated 6 Feb 2012. 4. We will renew the Temporary Permission (TP) of existing eating houses that are within the locations in Appendix A if there are no major complaints on dis- amenity arising from the use, and there is no breach of our planning guidelines and conditions.