Apache Calcite: a Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to Hbase Schema Design
Introduction to HBase Schema Design AmANDeeP KHURANA Amandeep Khurana is The number of applications that are being developed to work with large amounts a Solutions Architect at of data has been growing rapidly in the recent past . To support this new breed of Cloudera and works on applications, as well as scaling up old applications, several new data management building solutions using the systems have been developed . Some call this the big data revolution . A lot of these Hadoop stack. He is also a co-author of HBase new systems that are being developed are open source and community driven, in Action. Prior to Cloudera, Amandeep worked deployed at several large companies . Apache HBase [2] is one such system . It is at Amazon Web Services, where he was part an open source distributed database, modeled around Google Bigtable [5] and is of the Elastic MapReduce team and built the becoming an increasingly popular database choice for applications that need fast initial versions of their hosted HBase product. random access to large amounts of data . It is built atop Apache Hadoop [1] and is [email protected] tightly integrated with it . HBase is very different from traditional relational databases like MySQL, Post- greSQL, Oracle, etc . in how it’s architected and the features that it provides to the applications using it . HBase trades off some of these features for scalability and a flexible schema . This also translates into HBase having a very different data model . Designing HBase tables is a different ballgame as compared to relational database systems . I will introduce you to the basics of HBase table design by explaining the data model and build on that by going into the various concepts at play in designing HBase tables through an example . -

Apache Hbase, the Scaling Machine Jean-Daniel Cryans Software Engineer at Cloudera @Jdcryans
Apache HBase, the Scaling Machine Jean-Daniel Cryans Software Engineer at Cloudera @jdcryans Tuesday, June 18, 13 Agenda • Introduction to Apache HBase • HBase at StumbleUpon • Overview of other use cases 2 Tuesday, June 18, 13 About le Moi • At Cloudera since October 2012. • At StumbleUpon for 3 years before that. • Committer and PMC member for Apache HBase since 2008. • Living in San Francisco. • From Québec, Canada. 3 Tuesday, June 18, 13 4 Tuesday, June 18, 13 What is Apache HBase Apache HBase is an open source distributed scalable consistent low latency random access non-relational database built on Apache Hadoop 5 Tuesday, June 18, 13 Inspiration: Google BigTable (2006) • Goal: Low latency, consistent, random read/ write access to massive amounts of structured data. • It was the data store for Google’s crawler web table, gmail, analytics, earth, blogger, … 6 Tuesday, June 18, 13 HBase is in Production • Inbox • Storage • Web • Search • Analytics • Monitoring 7 Tuesday, June 18, 13 HBase is in Production • Inbox • Storage • Web • Search • Analytics • Monitoring 7 Tuesday, June 18, 13 HBase is in Production • Inbox • Storage • Web • Search • Analytics • Monitoring 7 Tuesday, June 18, 13 HBase is in Production • Inbox • Storage • Web • Search • Analytics • Monitoring 7 Tuesday, June 18, 13 HBase is Open Source • Apache 2.0 License • A Community project with committers and contributors from diverse organizations: • Facebook, Cloudera, Salesforce.com, Huawei, eBay, HortonWorks, Intel, Twitter … • Code license means anyone can modify and use the code. 8 Tuesday, June 18, 13 So why use HBase? 9 Tuesday, June 18, 13 10 Tuesday, June 18, 13 Old School Scaling => • Find a scaling problem. -

Final Report CS 5604: Information Storage and Retrieval
Final Report CS 5604: Information Storage and Retrieval Solr Team Abhinav Kumar, Anand Bangad, Jeff Robertson, Mohit Garg, Shreyas Ramesh, Siyu Mi, Xinyue Wang, Yu Wang January 16, 2018 Instructed by Professor Edward A. Fox Virginia Polytechnic Institute and State University Blacksburg, VA 24061 1 Abstract The Digital Library Research Laboratory (DLRL) has collected over 1.5 billion tweets and millions of webpages for the Integrated Digital Event Archiving and Library (IDEAL) and Global Event Trend Archive Research (GETAR) projects [6]. We are using a 21 node Cloudera Hadoop cluster to store and retrieve this information. One goal of this project is to expand the data collection to include more web archives and geospatial data beyond what previously had been collected. Another important part in this project is optimizing the current system to analyze and allow access to the new data. To accomplish these goals, this project is separated into 6 parts with corresponding teams: Classification (CLA), Collection Management Tweets (CMT), Collection Management Webpages (CMW), Clustering and Topic Analysis (CTA), Front-end (FE), and SOLR. This report describes the work completed by the SOLR team which improves the current searching and storage system. We include the general architecture and an overview of the current system. We present the part that Solr plays within the whole system with more detail. We talk about our goals, procedures, and conclusions on the improvements we made to the current Solr system. This report also describes how we coordinate with other teams to accomplish the project at a higher level. Additionally, we provide manuals for future readers who might need to replicate our experiments. -

Apache Hbase: the Hadoop Database Yuanru Qian, Andrew Sharp, Jiuling Wang
Apache HBase: the Hadoop Database Yuanru Qian, Andrew Sharp, Jiuling Wang 1 Agenda ● Motivation ● Data Model ● The HBase Distributed System ● Data Operations ● Access APIs ● Architecture 2 Motivation ● Hadoop is a framework that supports operations on a large amount of data. ● Hadoop includes the Hadoop Distributed File System (HDFS) ● HDFS does a good job of storing large amounts of data, but lacks quick random read/write capability. ● That’s where Apache HBase comes in. 3 Introduction ● HBase is an open source, sparse, consistent distributed, sorted map modeled after Google’s BigTable. ● Began as a project by Powerset to process massive amounts of data for natural language processing. ● Developed as part of Apache’s Hadoop project and runs on top of Hadoop Distributed File System. 4 Big Picture MapReduce Thrift/REST Your Java Hive/Pig Gateway Application Java Client ZooKeeper HBase HDFS 5 An Example Operation The Job: The Table: A MapReduce job row key column 1 column 2 needs to operate on a series of webpages “com.cnn.world” 13 4.5 matching *.cnn.com “com.cnn.tech” 46 7.8 “com.cnn.money” 44 1.2 6 The HBase Data Model 7 Data Model, Groups of Tables RDBMS Apache HBase database namespace table table 8 Data Model, Single Table RDBMS table col1 col2 col3 col4 row1 row2 row3 9 Data Model, Single Table Apache HBase columns are table fam1 fam2 grouped into fam1:col1 fam1:col2 fam2:col1 fam2:col2 Column Families row1 row2 row3 10 Sparse example Row Key fam1:contents fam1:anchor “com.cnn.www” contents:html = “<html>...” contents:html = “<html>...” -

Mapreduce Service
MapReduce Service Troubleshooting Issue 01 Date 2021-03-03 HUAWEI TECHNOLOGIES CO., LTD. Copyright © Huawei Technologies Co., Ltd. 2021. All rights reserved. No part of this document may be reproduced or transmitted in any form or by any means without prior written consent of Huawei Technologies Co., Ltd. Trademarks and Permissions and other Huawei trademarks are trademarks of Huawei Technologies Co., Ltd. All other trademarks and trade names mentioned in this document are the property of their respective holders. Notice The purchased products, services and features are stipulated by the contract made between Huawei and the customer. All or part of the products, services and features described in this document may not be within the purchase scope or the usage scope. Unless otherwise specified in the contract, all statements, information, and recommendations in this document are provided "AS IS" without warranties, guarantees or representations of any kind, either express or implied. The information in this document is subject to change without notice. Every effort has been made in the preparation of this document to ensure accuracy of the contents, but all statements, information, and recommendations in this document do not constitute a warranty of any kind, express or implied. Issue 01 (2021-03-03) Copyright © Huawei Technologies Co., Ltd. i MapReduce Service Troubleshooting Contents Contents 1 Account Passwords.................................................................................................................. 1 1.1 Resetting -

HDP 3.1.4 Release Notes Date of Publish: 2019-08-26
Release Notes 3 HDP 3.1.4 Release Notes Date of Publish: 2019-08-26 https://docs.hortonworks.com Release Notes | Contents | ii Contents HDP 3.1.4 Release Notes..........................................................................................4 Component Versions.................................................................................................4 Descriptions of New Features..................................................................................5 Deprecation Notices.................................................................................................. 6 Terminology.......................................................................................................................................................... 6 Removed Components and Product Capabilities.................................................................................................6 Testing Unsupported Features................................................................................ 6 Descriptions of the Latest Technical Preview Features.......................................................................................7 Upgrading to HDP 3.1.4...........................................................................................7 Behavioral Changes.................................................................................................. 7 Apache Patch Information.....................................................................................11 Accumulo........................................................................................................................................................... -

Apache Hadoop Goes Realtime at Facebook
Apache Hadoop Goes Realtime at Facebook Dhruba Borthakur Joydeep Sen Sarma Jonathan Gray Kannan Muthukkaruppan Nicolas Spiegelberg Hairong Kuang Karthik Ranganathan Dmytro Molkov Aravind Menon Samuel Rash Rodrigo Schmidt Amitanand Aiyer Facebook {dhruba,jssarma,jgray,kannan, nicolas,hairong,kranganathan,dms, aravind.menon,rash,rodrigo, amitanand.s}@fb.com ABSTRACT 1. INTRODUCTION Facebook recently deployed Facebook Messages, its first ever Apache Hadoop [1] is a top-level Apache project that includes user-facing application built on the Apache Hadoop platform. open source implementations of a distributed file system [2] and Apache HBase is a database-like layer built on Hadoop designed MapReduce that were inspired by Googles GFS [5] and to support billions of messages per day. This paper describes the MapReduce [6] projects. The Hadoop ecosystem also includes reasons why Facebook chose Hadoop and HBase over other projects like Apache HBase [4] which is inspired by Googles systems such as Apache Cassandra and Voldemort and discusses BigTable, Apache Hive [3], a data warehouse built on top of the applications requirements for consistency, availability, Hadoop, and Apache ZooKeeper [8], a coordination service for partition tolerance, data model and scalability. We explore the distributed systems. enhancements made to Hadoop to make it a more effective realtime system, the tradeoffs we made while configuring the At Facebook, Hadoop has traditionally been used in conjunction system, and how this solution has significant advantages over the with Hive for storage and analysis of large data sets. Most of this sharded MySQL database scheme used in other applications at analysis occurs in offline batch jobs and the emphasis has been on Facebook and many other web-scale companies. -

Hbase: the Definitive Guide
HBase: The Definitive Guide HBase: The Definitive Guide Lars George Beijing • Cambridge • Farnham • Köln • Sebastopol • Tokyo HBase: The Definitive Guide by Lars George Copyright © 2011 Lars George. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://my.safaribooksonline.com). For more information, contact our corporate/institutional sales department: (800) 998-9938 or [email protected]. Editors: Mike Loukides and Julie Steele Indexer: Angela Howard Production Editor: Jasmine Perez Cover Designer: Karen Montgomery Copyeditor: Audrey Doyle Interior Designer: David Futato Proofreader: Jasmine Perez Illustrator: Robert Romano Printing History: September 2011: First Edition. Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. HBase: The Definitive Guide, the image of a Clydesdale horse, and related trade dress are trademarks of O’Reilly Media, Inc. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc., was aware of a trademark claim, the designations have been printed in caps or initial caps. While every precaution has been taken in the preparation of this book, the publisher and author assume no responsibility for errors or omissions, or for damages resulting from the use of the information con- tained herein. ISBN: 978-1-449-39610-7 [LSI] 1314323116 For my wife Katja, my daughter Laura, and son Leon. -

Desarrollo De Una Solución Business Intelligence Mediante Un Paradigma De Data Lake
Desarrollo de una solución Business Intelligence mediante un paradigma de Data Lake José María Tagarro Martí Grado de Ingeniería Informática Consultor: Humberto Andrés Sanz Profesor: Atanasi Daradoumis Haralabus 13 de enero de 2019 Esta obra está sujeta a una licencia de Reconocimiento-NoComercial-SinObraDerivada 3.0 España de Creative Commons FICHA DEL TRABAJO FINAL Desarrollo de una solución Business Intelligence mediante un paradigma de Data Título del trabajo: Lake Nombre del autor: José María Tagarro Martí Nombre del consultor: Humberto Andrés Sanz Fecha de entrega (mm/aaaa): 01/2019 Área del Trabajo Final: Business Intelligence Titulación: Grado de Ingeniería Informática Resumen del Trabajo (máximo 250 palabras): Este trabajo implementa una solución de Business Intelligence siguiendo un paradigma de Data Lake sobre la plataforma de Big Data Apache Hadoop con el objetivo de ilustrar sus capacidades tecnológicas para este fin. Los almacenes de datos tradicionales necesitan transformar los datos entrantes antes de ser guardados para que adopten un modelo preestablecido, en un proceso conocido como ETL (Extraer, Transformar, Cargar, por sus siglas en inglés). Sin embargo, el paradigma Data Lake propone el almacenamiento de los datos generados en la organización en su propio formato de origen, de manera que con posterioridad puedan ser transformados y consumidos mediante diferentes tecnologías ad hoc para las distintas necesidades de negocio. Como conclusión, se indican las ventajas e inconvenientes de desplegar una plataforma unificada tanto para análisis Big Data como para las tareas de Business Intelligence, así como la necesidad de emplear soluciones basadas en código y estándares abiertos. Abstract (in English, 250 words or less): This paper implements a Business Intelligence solution following the Data Lake paradigm on Hadoop’s Big Data platform with the aim of showcasing the technology for this purpose. -

TR-4744: Secure Hadoop Using Apache Ranger with Netapp In
Technical Report Secure Hadoop using Apache Ranger with NetApp In-Place Analytics Module Deployment Guide Karthikeyan Nagalingam, NetApp February 2019 | TR-4744 Abstract This document introduces the NetApp® In-Place Analytics Module for Apache Hadoop and Spark with Ranger. The topics covered in this report include the Ranger configuration, underlying architecture, integration with Hadoop, and benefits of Ranger with NetApp In-Place Analytics Module using Hadoop with NetApp ONTAP® data management software. TABLE OF CONTENTS 1 Introduction ........................................................................................................................................... 4 1.1 Overview .........................................................................................................................................................4 1.2 Deployment Options .......................................................................................................................................5 1.3 NetApp In-Place Analytics Module 3.0.1 Features ..........................................................................................5 2 Ranger ................................................................................................................................................... 6 2.1 Components Validated with Ranger ................................................................................................................6 3 NetApp In-Place Analytics Module Design with Ranger.................................................................. -

Beyond Macrobenchmarks: Microbenchmark-Based Graph Database Evaluation
Beyond Macrobenchmarks: Microbenchmark-based Graph Database Evaluation Matteo Lissandrini Martin Brugnara Yannis Velegrakis Aalborg University University of Trento University of Trento [email protected] [email protected] [email protected] ABSTRACT There are two categories of graph management systems Despite the increasing interest in graph databases their re- that address two complementary yet distinct sets of func- quirements and specifications are not yet fully understood tionalities. The first is that of graph processing systems [27, by everyone, leading to a great deal of variation in the sup- 42,44], which analyze graphs to discover characteristic prop- ported functionalities and the achieved performances. In erties, e.g., average connectivity degree, density, and mod- this work, we provide a comprehensive study of the exist- ularity. They also perform batch analytics at large scale, ing graph database systems. We introduce a novel micro- implementing computationally expensive graph algorithms, benchmarking framework that provides insights on their per- such as PageRank [54], SVD [23], strongly connected com- formance that go beyond what macro-benchmarks can of- ponents identification [63], and core identification [12, 20]. fer. The framework includes the largest set of queries and Those are systems like GraphLab, Giraph, Graph Engine, operators so far considered. The graph database systems and GraphX [67]. The second category is that of graph are evaluated on synthetic and real data, from different do- databases (GDB for short) [5]. Their focus is on storage mains, and at scales much larger than any previous work. and querying tasks where the priority is on high-throughput The framework is materialized as an open-source suite and and transactional operations. -
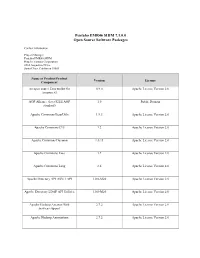
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho EMR46 SHIM Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component An open source Java toolkit for 0.9.0 Apache License Version 2.0 Amazon S3 AOP Alliance (Java/J2EE AOP 1.0 Public Domain standard) Apache Commons BeanUtils 1.9.3 Apache License Version 2.0 Apache Commons CLI 1.2 Apache License Version 2.0 Apache Commons Daemon 1.0.13 Apache License Version 2.0 Apache Commons Exec 1.2 Apache License Version 2.0 Apache Commons Lang 2.6 Apache License Version 2.0 Apache Directory API ASN.1 API 1.0.0-M20 Apache License Version 2.0 Apache Directory LDAP API Utilities 1.0.0-M20 Apache License Version 2.0 Apache Hadoop Amazon Web 2.7.2 Apache License Version 2.0 Services support Apache Hadoop Annotations 2.7.2 Apache License Version 2.0 Name of Product/Product Version License Component Apache Hadoop Auth 2.7.2 Apache License Version 2.0 Apache Hadoop Common - 2.7.2 Apache License Version 2.0 org.apache.hadoop:hadoop-common Apache Hadoop HDFS 2.7.2 Apache License Version 2.0 Apache HBase - Client 1.2.0 Apache License Version 2.0 Apache HBase - Common 1.2.0 Apache License Version 2.0 Apache HBase - Hadoop 1.2.0 Apache License Version 2.0 Compatibility Apache HBase - Protocol 1.2.0 Apache License Version 2.0 Apache HBase - Server 1.2.0 Apache License Version 2.0 Apache HBase - Thrift - 1.2.0 Apache License Version 2.0 org.apache.hbase:hbase-thrift Apache HttpComponents Core