PEER Hub Imagenet (-Net)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Chapter 1 Introduction As a Chinese Buddhist in Malaysia, I Have Been
Chapter 1 Introduction As a Chinese Buddhist in Malaysia, I have been unconsciously entangled in a historical process of the making of modern Buddhism. There was a Chinese temple beside my house in Penang, Malaysia. The main deity was likely a deified imperial court officer, though no historical record documented his origin. A mosque serenely resided along the main street approximately 50 meters from my house. At the end of the street was a Hindu temple decorated with colorful statues. Less than five minutes’ walk from my house was a Buddhist association in a two-storey terrace. During my childhood, the Chinese temple was a playground. My friends and I respected the deities worshipped there but sometimes innocently stole sweets and fruits donated by worshippers as offerings. Each year, three major religious events were organized by the temple committee: the end of the first lunar month marked the spring celebration of a deity in the temple; the seventh lunar month was the Hungry Ghost Festival; and the eighth month honored, She Fu Da Ren, the temple deity’s birthday. The temple was busy throughout the year. Neighbors gathered there to chat about national politics and local gossip. The traditional Chinese temple was thus deeply rooted in the community. In terms of religious intimacy with different nearby temples, the Chinese temple ranked first, followed by the Hindu temple and finally, the mosque, which had a psychological distant demarcated by racial boundaries. I accompanied my mother several times to the Hindu temple. Once, I asked her why she prayed to a Hindu deity. -
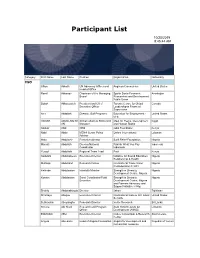
Participant List
Participant List 10/20/2019 8:45:44 AM Category First Name Last Name Position Organization Nationality CSO Jillian Abballe UN Advocacy Officer and Anglican Communion United States Head of Office Ramil Abbasov Chariman of the Managing Spektr Socio-Economic Azerbaijan Board Researches and Development Public Union Babak Abbaszadeh President and Chief Toronto Centre for Global Canada Executive Officer Leadership in Financial Supervision Amr Abdallah Director, Gulf Programs Educaiton for Employment - United States EFE HAGAR ABDELRAHM African affairs & SDGs Unit Maat for Peace, Development Egypt AN Manager and Human Rights Abukar Abdi CEO Juba Foundation Kenya Nabil Abdo MENA Senior Policy Oxfam International Lebanon Advisor Mala Abdulaziz Executive director Swift Relief Foundation Nigeria Maryati Abdullah Director/National Publish What You Pay Indonesia Coordinator Indonesia Yussuf Abdullahi Regional Team Lead Pact Kenya Abdulahi Abdulraheem Executive Director Initiative for Sound Education Nigeria Relationship & Health Muttaqa Abdulra'uf Research Fellow International Trade Union Nigeria Confederation (ITUC) Kehinde Abdulsalam Interfaith Minister Strength in Diversity Nigeria Development Centre, Nigeria Kassim Abdulsalam Zonal Coordinator/Field Strength in Diversity Nigeria Executive Development Centre, Nigeria and Farmers Advocacy and Support Initiative in Nig Shahlo Abdunabizoda Director Jahon Tajikistan Shontaye Abegaz Executive Director International Insitute for Human United States Security Subhashini Abeysinghe Research Director Verite -

Autor Titel Signatur Vermerk Adhe Ama Doch Mein Herz Lebt in Tibet
Autor Titel Signatur Vermerk Adhe Ama Doch mein Herz lebt in Tibet 274 Adhe Aitken, Robert Original Dwelling Place 155.1 Orig Aitken, Robert Zen als Lebenspraxis 155.1 Zena Allione Tsültrim Tibets weise Frauen 195.8.5 Alli Amaro Ajahn & Pasanno auch 102 Isla, 112 Isla, Ajahn The Island An Anthology of the Buddha's Teachings on Nibbana 102.1 Isla 115.2 Isla, 182.2 Isla Ajahn Sumedho Mindfullness: The Path to the Deathless 103.7 Mind auch 182.2, 115.2 Ajhan Sumedho Die Vier Edlen Wahrheiten 103.7 Vier Ajahn Thiradhammo Treasures of the Buddha's Teaching 103.7 Trea auch 182.2, 115.2 Andricevic Zarko Schlichtheit und Schönheit von Chan 133.5 Schl Andricevic Zarko Simplicity and Beauty of Chan 133.5 Simp Andricevic Zarko Umgang mit Hindernissen/Problemen in Retraiten 133.5 Prob Andricevic Zarko Stille in Geschäftigkeit 133.5 Stil Andricevic Zarko Chan und die vier Umwelten 133.5 Vier Anandamayi Ma Worte der Glückselige Mutter 377 Anan Antes, Peter Das Christentum: Eine Einführung 401 Ante Aoyama, Shundo Pflaumenblüten im Schnee 152.6 Pfla Aoyama, Shundo japanischer Text 152.6 Aoyama, Shundo A Zen Life 152.6 Azen Aoyama, Shundo japanischer Text 152.6 Arnold, Paul Das Totenbuch der Maya 743.2 Arno Arokiasamy, Arul M. Leere und Fülle: Zen aus Indien in christlicher Praxis 460 Arok Arokiasamy, Arul M. Warum Bodhidharma in den Westen kam 460 Arok Arrien, Angeles Der Vierfache Weg 960 Arri Auboyer, Jeanine Tibet Kunst des Buddhismus 195.8.9 Tibe Aurobindo Die Synthese des Yoga 318.1 Synt Aurobindo Growing within 318.1 Grow auch 106, 108,156, Austin, James H. -
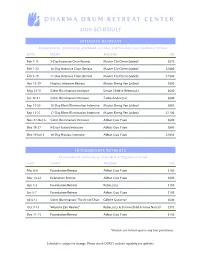
2020 Schedule
2020 SCHEDULE INTENSIVE RETREATS Requirement: previously attended at least a three-day intermediate retreat. DATE EVENT TEACHER FEE Feb 7-15 9-Day Intensive Chan Retreat Master Chi Chern (video) $675 Feb 7-22 16-Day Intensive Chan Retreat Master Chi Chern (video) $1000 Feb 7-29 22-Day Intensive Chan Retreat Master Chi Chern (video) $1500 Apr 11-19 Huatou Intensive Retreat Master Sheng Yen (video) $600 May 23-31 Silent Illumination Intensive Simon Child & Rebecca Li $600 Jun 12-21 Silent Illumination Intensive Zarko Andricevic $600 Sep 11-20 10-Day Silent Illumination Intensive Master Sheng Yen (video) $650 Sep 11-27 17-Day Silent Illumination Intensive Master Sheng Yen (video) $1100 Nov 27-Dec 6 Silent Illumination Intensive Abbot Guo Yuan $600 Dec 19-27 9-Day Huatou Intensive Abbot Guo Yuan $600 Dec 19-Jan 3 16-Day Huatou Intensive Abbot Guo Yuan $1050 INTERMEDIATE RETREATS Requirement: previously attended a beginners event. DATE EVENT TEACHER FEE Mar 6-8 Foundation Retreat Abbot Guo Yuan $150 Mar 14-22 Relaxation Retreat Abbot Guo Yuan $600 Apr 3-5 Foundation Retreat Rebecca Li $150 Jun 5-7 Foundation Retreat Abbot Guo Yuan $150 Jul 4-12 Silent Illumination: The Art of Chan Gilbert Gutierrez $600 Oct 9-14 Western Zen Retreat* Rebecca Li & Simon Child & Fiona Nuttall $375 Dec 11-13 Foundation Retreat Abbot Guo Yuan $150 *Western Zen Retreat open to any level practitioner. Schedule is subject to change. Please check DDRC’s website regularly for updates. 2020 SCHEDULE FOR BEGINNERS DATE EVENT TEACHER FEE Mar 27-29 Weekend Meditation Class Abbot Guo Yuan $150 May 1-3 Weekend Meditation Class Abbot Guo Yuan $150 Jul 17-19 Weekend Meditation Class Abbot Guo Yuan $150 Aug 14-16 Beginner’s Mind Retreat Rebecca Li $150 WORKSHOPS DATE EVENT TEACHER FEE Jan 17-19 Cooking Meditation Chang Hu Fashi $150 Apr 25-26 Photo Mind Dr. -

The Dharma Drum Beat
The Dharma Drum Beat Newsletter of the Dharma Drum Mountain Buddhist Association—Chicago Chapter March/April 2012 Upcoming Events in 2012 Many exciting and rewarding events have been planned for 2012! All events are held at our 1234 N. River Road, Mount Prospect location, unless specified otherwise, and all are free unless noted. We are a bi-lingual organization, welcoming both English and Chinese speakers. Please check the Future Events page on our website for late-breaking news at: http://www.ddmbachicago.org/futureevents Chanting Weekend with Venerable Guo Xing Buddha’s Birthday, Dharma Lectures and Spring April 12-15, 2012 Fundraising Dinner May 11—14 (Times tentative) Thursday, April 12 Venerables Guo Sheng and Chang Hua to visit. 7:00pm—9:00pm Intro to Chanting: A lecture in English on the purpose Friday, May 11 and methods of chanting. This lecture is mainly for 7:00pm—9:00pm Westerners - but also anyone who is new to chanting. Spring fundraising dinner Friday, April 13 Saturday, May 12 7:00pm—9:00pm 10:00am—12:00pm Chanting Sutras: Come to learn the proper way to Buddha’s Birthday Ceremony chant sutras, via lecture and practice. (Mandarin) 12:00pm—1:00pm Saturday, April 14 Vegetarian Potluck Lunch 10:00am—12:00pm 1:00pm—3:30pm Chanting: Ksitigarbha Bodhisattva Repentance Cere- Dharma Talk: The Noble Eight-Fold Path (Mandarin) mony. Ceremony in Mandarin, followed by a Potluck Vegetarian Lunch Sunday, May 13 1:30pm—3:30pm 1:00pm—3:30pm The Role and Methods of Chanting Ceremonies in Dharma Talk: Earth Store Bodhisattva (English) Chan Practice. -

Thunlam 1-10.Pub
Thunlam 1/2010 Nachrichten, Berichte und Hintergründe aus dem Königreich Bhutan Thunlam Newsletter 1/2010 Liebe Freundinnen und Freunde Bhutans, Ihnen allen wünschen wir von der Deutschen Bhutan Himalaya Gesellschaft ein glückbringendes und fried- fertiges Jahr des Eisen-Tigers (lcags stag) 2010/11! Mögen alle Ihre Wünsche in Erfüllung gehen! Die diesjährige Frühlingsausgabe des Thunlam steht ganz im Zeichen der großen Ausstellung „Bhutan. Heilige Kunst aus dem Himalaya.“ im Museum für Ostasiatische Kunst, Köln, die vom 20. Februar— bis zum 23. Mai. 2010 gezeigt wird. Aus diesem Anlass haben wir einige Artikeln dieser Ausgabe speziell der Kunst und Religion gewidmet. Der Religionsteil ist deshalb auch etwas ausführlicher geraten, als sonst. Das soll aber nicht heißen, das andere Themen vernachlässigt würden, wir haben die Seitenzahl des Thun- lam einfach erhöht! Aus gleichem Anlass haben wir auch unseren diesjährigen Bhutantag nach Köln in das Japanische Kultur- institut verlegt, das sich genau gegenüber dem Ostasiatischen Museum befindet. Einzelheiten zum Bhutan- tag und vor allem die Anmeldeformulare sind wie immer auf unserer Webseite zu finden, die auf den aktuel- len Stand gebracht wurde: www.bhutan-himalaya.de. Anschließen wird sich auch ein Symposium zum Glücklichsein in Bhutan und anderswo und eine Münzausstellung mit Münzen aus dem Himalayaraum (weitere Informationen siehe S. 43). Last but not least möchten wir Ihnen wieder viel Vergnügen beim Lesen dieses Thunlam wünschen und vielleicht sehen wir uns ja auf dem Bhutantag oder in der Ausstellung? Ihr Gregor Verhufen Titelbild : Roland Bentz: Bietigheim-Bissingen: Detail von „Die Tanzmaske (Shingjay) mit Hörnern, Pinien- holz geschnitzt. Auf dem Kopf mittig befindet sich ein kleiner Totenschädel. -

100 Buddhismus
Autor Titel Signatur Vermerk 100 Buddhismus 101 Buddhismus allgemein Lasalle-Haus: Symposium Buddhisten und Christen für Gerechtigkeit, Frieden und Bewahrung der Erde 101 siehe 990 Bran Leong, Kenneth S. Jesus - der Zenlehrer: Das Herz seiner Lehre 101 siehe 990 Leon Mensching, Gustav Buddha und Christus 101 siehe 990 Mens Zimmermann, Spitz, Schmid Achtsamkeit; ein buddhistisches Konzept erobert die Wissenschaft 101 Acht auch 894 Acht, 950 Acht Zimmermann, Spitz, Schmid Achtsamkeit; ein buddhistisches Konzept erobert die Wissenschaft, CD 101 Acht auch 894 Acht, 950 Acht Batchelor Stephen Jenseits des Buddhismus, eine säkulare Vision des Dharma 101 Batc Bechert H. / Gombrich R. Der Buddhismus, Geschichte und Gegenwart 101 Bech Carrithers Michael Der Buddha, Eine Einführung 101 Carr Conze, Edward Der Buddhismus 101 Conz Dumoulin, Heinrich Spiritualität des Buddhismus 101 Dumo Hecker Hellmuth Blüte und Verfall im frühen Buddhismus und im Mahayana-Buddhismus 101 Heck O'Flaherty, Wendy Doniger Karma and Rebirth in Classical Indien Traditions 101 Karm siehe 301 Keown, Damien Der Buddhismus, Eine kurze Einführung 101 Keow Kohl Christian Thomas Buddhismus und Quantenphysik 101siehe All 894 Kohl Kollmar, Karnina Kleine Geschichte Tibets 101 Koll siehe 273 Koll Kollmar, Karnina Buddhismus und Christentum: Geschichte, Konfrontation, Dialog 101 siehe 990 vonB von Brück, Michael, Whalen Lai Karma 101 Karm siehe auch 108 Karm Weil, Alfred Tibet Turning the Wheel of Life 101 Weil siehe 273 Pomm Pommaret, Francoise Buddha 101 Pomm Percheron, Maurice Buddhismus -

Intensive Chan/Zen Meditation Retreat Led by Chi Chern Fashi Contact
Intensive Chan/Zen Meditation Retreat Led by Chi Chern Fashi In Poland, August, 2009 Following the success of Chi Chern Fashi’s Chan retreats in Europe last year, once again he has been invited back to Poland to lead this year’s event. The retreat will consist of almost 10 full days of Chan practice, where one will learn basic methods of relaxation and concentration, and especially become introduced to the use of Silent Illumination and Huatou Chan methods, as originally taught by Chan Master Sheng Yen, Chi Chern Fashi’s Chan teacher. The retreat will focus on meditation practice in the context of sitting, as well as amidst daily activities, which include: exercise, daily chores, eating, sleeping, and walking. As all activities are an opportunity for Chan practice, guidance will be given on how to apply the methods during intensive retreat, as well as in day‐to‐day life outside of the Chan Hall. Dharma lectures will be given daily, and participants will have opportunities for interview with the teachers. The retreat will be conducted in English, with Dharma talks in Mandarin Chinese followed by English translation. Because Chi Chern Fashi will be in Europe for a short period of time this year, Poland has been chosen as the central location to host all Dharma friends from various locations throughout Europe, to gather together for intensive Chan practice. For this retreat, we are pleased to announce that he will also be accompanied by two other monastics, Guo Xing Fashi and Chang Wen Fashi, as well as long‐time Chan practitioner, Djordje Cvijic, all disciples of Chan Master Sheng Yen. -

Thunlam Thunlam
Thunlam 2/2009 Nachrichten, Berichte und Hintergründe aus dem Königreich Bhutan Thunlam Newsletter 2/2009 Liebe Freundinnen und Freunde Bhutans, Vor Ihnen liegt die Herbstausgabe des neuen Thunlam. Wie immer, finden Sie informative Berichte aus dem Drachenlande: Nachrichten, zeitkritische Artikel und Neues über die Aktivitäten der Deutschen Bhutan Himalaya Gesellschaft. Es gibt eine wichtige Änderung in der Medienlandschaft Bhutans: Nicht nur wird die staatliche Radio– und Fernsehgesellschaft des Landes, Bhutan Broadcasting Service (BBS) immer professioneller (S. 19), son- dern auch Kuensel, die staatliche Zeitung des Landes, die immer noch die Hauptquelle für die Nachrich- tenauswahl des Thunlam bildet, wird seit Mitte des Jahres täglich produziert, statt wie zuvor, zweimal wö- chentlich. Zu unseren Informationsquellen gehören aber auch die beiden privaten Zeitungen des Landes, Bhutan Times und The Observer. Dazu kommen noch die verbesserten Angebote im Internet: Alle offiziel- len Einrichtungen Bhutans gehen inzwischen mit leuchtendem Beispiel voran und publizieren wichtige Neu- igkeiten, Berichte und sogar ganze Bücher auf ihren Websites. Wie Sie sehen, ist die Informationsflut aus und über Bhutan mittlerweile schier unüberschaubar groß ge- worden. Neben Berichten zu den Aktivitäten unseres Vereins, haben uns in dieser Ausgabe des Thunlam bemüht, Ihnen eine bunte Auswahl an Nachrichten und Informationen aus allen Bereichen bhutanischen Lebens zusammenzustellen. Immerhin sind wieder 42 Seiten dabei herausgekommen. Eine wirklich umfas- sende Information aber kann unser halbjährlich erscheinendes Blättchen nicht mehr leisten. Dazu ist das Leben und sind die Geschehnisse in Bhutan zu vielfältig geworden. Dennoch—wir hoffen, Ihnen die Rosi- nen aus dem großen Medienangebot herausgepickt zu haben und wünschen Ihnen viel Vergnügen beim Lesen! Ihr Gregor Verhufen Titelbild: Seine königliche Hoheit, Prinz Jigyel bei seiner Rede anlässlich der Eröffnung der Bhutan- Ausstellung « Au pays du Dragon: arts sacrés du Bhoutan » im Musée Guimet, Paris, am 06. -
Newsletter 32, December 2016
WCF Newsletter 32, December 2016 www.westernchanfellowship.org December 2016 NEWSLETTER 32 WESTERN CHAN FELLOWSHIP NEWS AND PROGRAMMES Welcome to Newsletter 32. This includes our full 2017 retreat programme and also brings you news of other WCF activities. In the previous newsletter we showed you photos of a new venue we are to use in Merseyside. We have also booked another new venue for a February ‘Taste of Chan’ retreat. Hagg Farm Outdoor Education Centre provides comfortable residential accommodation within the buildings and grounds of a converted 19th Century hill farm. Walks from the door of the centre lead onto the high moors of Kinder and Bleaklow and around the Ladybower reservoirs and dams. There is ample car parking at the Centre for those travelling by car, and for those using public transport it is only 6 miles from Bamford railway station on the Manchester-Sheffield line. The centre provides very pleasant accommodation and has disabled facilities. In addition to our residential retreats there are many other opportunities for you to practise with us, such as at local group events and day retreats (see page 6-7). You may also wish to participate in events led by WCF leaders at other venues outside the WCF programme such as at Gaia House in June and in Europe or USA (see page 6). We are also introducing new types of events (see details inside) such as a stone carving and meditation course and Chinese brush painting. In March in Bristol there will be a seminar with Stephen Batchelor on “Early Buddhism and the Four Great Vows”. -

Chinese Buddhist Revitalization in Malaysia
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by ScholarBank@NUS THE MAKING OF MODERN BUDDHISM: CHINESE BUDDHIST REVITALIZATION IN MALAYSIA TAN LEE OOI (B. Sc. (Hons), M.A. USM A THESIS SUBMITTED FOR THE DEGREE OF DOCTOR OF PHILOSOPHY DEPARTMENT OF SOUTHEAST ASIAN STUDIES NATIONAL UNIVERSITY OF SINGAPORE 2013 DECLARATION I hereby declare that this thesis is my original work and it has been written by me in its entirety. I have duly acknowledged all the sources of information which have been used in the thesis. This thesis has also not been submitted for any degree in any university previously. TAN LEE OOI 25 July 2013 ii Acknowledgements This thesis was completed with the financial support and other resources of the Asia Research Institute PhD Scholarship and the Department of Southeast Asian Studies, National University of Singapore. I am thankful to my supervisor, Dr. Irving Johnson, whom I believe will become a great educator in the future, for his patience in providing critical commentary and correcting grammatical errors in my drafts. I also appreciate my PhD committee members, who tested me during the Qualifying Exam and thus helped me to consider new scopes and directions for my research. Without various conferences, workshops, seminars, and lectures sponsored by the Asia Research Institute that attracted leading scholars on Chinese religions such as Kenneth Dean, David Palmer, Julia Huang, and Mayfair Yang, I would not have been able to strengthen my thesis. Without registration, I attended a module on religion and secularism offered by Prof. -

Amitabha Village Year 2006 3-Day Retreat
Amitabha Village Year 2006 3-Day Retreat Objective: To promote the understanding and practice of Buddhism and meditation in a systematic way. Date: 2 p.m. August 17, 2006 to 12 noon August 20, 2006 Teacher: Venerable Chi Chern Location: Amitabha Village, Perry, Michigan Program: Sitting meditation, prostration, walking meditation (circumambulation), massage, yoga, and dharma teachings conducted in Chinese with English translation. Qualification: Open to beginners and experienced practitioners Boarding: Two choices of accommodation: 1. Sleeping on carpeted floors of Buddha hall (males) or Perry House (females). 2. Camping (please bring your own tent). Fees: $90 or $40 (students) (including meals, site setup, Ven. Chi Chern’s transportation expenses). Paid when check in. Registration: Please e-mail or send the application form to: Lina Wu 1337 Ramblewood Dr. East Lansing, MI 48823 E-mail: [email protected] Registration Closing Date: August 4, 2006 Things You Need to Know: 1. Finishing the entire retreat is required. 2. Please bring your toiletries, personal medication, and sleeping bag. 3. No drug, alcohol and cigarette. 4. The Center will not be responsible for the lost of your valuables. 5. Please wear loose and comfortable clothing. 6. The Center offers vegetarian lunch, and light breakfast and dinner during retreat. Contacts: Chung-Wen Chen & Lina Wu (517) 351-7077 Peter & Lisa Kong (517) 332-0003 James & Nancy Jean (517) 349-6441 彌陀村Amitabha Village, 14780 Beardslee Rd., Perry, Michigan 48872 Direction (map on Website): I-96 exit 117 (Williamston) to Williamston Rd (north) for appx. 6.5 miles, Williamston Rd ends and becomes Beardslee Rd, 3rd house on the left.