The Impact of Audio-Visual Speech Input on Work-Load in Simultaneous Interpreting
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cognitive Psychology
COGNITIVE PSYCHOLOGY PSYCH 126 Acknowledgements College of the Canyons would like to extend appreciation to the following people and organizations for allowing this textbook to be created: California Community Colleges Chancellor’s Office Chancellor Diane Van Hook Santa Clarita Community College District College of the Canyons Distance Learning Office In providing content for this textbook, the following professionals were invaluable: Mehgan Andrade, who was the major contributor and compiler of this work and Neil Walker, without whose help the book could not have been completed. Special Thank You to Trudi Radtke for editing, formatting, readability, and aesthetics. The contents of this textbook were developed under the Title V grant from the Department of Education (Award #P031S140092). However, those contents do not necessarily represent the policy of the Department of Education, and you should not assume endorsement by the Federal Government. Unless otherwise noted, the content in this textbook is licensed under CC BY 4.0 Table of Contents Psychology .................................................................................................................................................... 1 126 ................................................................................................................................................................ 1 Chapter 1 - History of Cognitive Psychology ............................................................................................. 7 Definition of Cognitive Psychology -

Selective Attention, Arousal, and the Theory of Signal Detection Paula A
Iowa State University Capstones, Theses and Retrospective Theses and Dissertations Dissertations 1974 Selective attention, arousal, and the theory of signal detection Paula A. Goolkasian Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/rtd Part of the Experimental Analysis of Behavior Commons, and the Psychiatry and Psychology Commons Recommended Citation Goolkasian, Paula A., "Selective attention, arousal, and the theory of signal detection " (1974). Retrospective Theses and Dissertations. 6340. https://lib.dr.iastate.edu/rtd/6340 This Dissertation is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Retrospective Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. INFORMATION TO USERS This material was produced from a microfilm copy of the original document. While the most advanced technological means to photograph and reproduce this document have been used, the quality is heavily dependent upon the quality of the original submitted. The following explanation of techniques is provided to help you understand markings or patterns which may appear on this reproduction. 1. The sign or "target" for pages apparently lacking from the document photographed is "Missing Page(s)". If it was possible to obtain the missing page(s) or section, they are spliced into the film along with adjacent pages. This may have necessitated cutting thru an image and duplicating adjacent pages to insure you complete continuity. 2. When an image on the film is obliterated with a large round black mark, it is an indication that the photographer suspected that the copy may have moved during exposure and thus cause a blurred image. -

Applied History of Psychology/History of Research on Attention 1 Applied History of Psychology/History of Research on Attention
Applied History of Psychology/History of Research on Attention 1 Applied History of Psychology/History of Research on Attention There has been a large increase in research activity in the area of attention since the 1950s. This research has focused not only on attention, but also how attention is related to memory and executive functioning. Human learning and behaviour are dependent on our ability to pay attention to our environment, retain and retrieve information, and use cognitive strategies. An understanding of the development of attention is also critical when we consider that deficits in attention often lead to difficulties in school and in the work force. Thus, attention is an important topic in the study of psychology, specifically in the areas of development (see Part II of this book), learning (Part III), and psychological disorders (see the section on ADHD in Part IV). There is no doubt that an understanding of attention and related concepts is critical to our understanding of human cognition and learning. Introduction to The History of Research on Attention The study of attention is a major part of contemporary cognitive psychology and cognitive neuroscience. Attention plays a critical role in essentially all aspects of perception, cognition, and action, influencing the choices we make. The study of attention has been of interest to the field of psychology since its earliest days. However, many ideas about attention can be traced to philosophers in the 18th and 19th centuries, preceding the foundation of the field of psychology. The topic of attention was originally discussed by philosophers. Among the issues considered were the role of attention on conscious awareness and thought, and whether attention was directed voluntarily or involuntarily toward objects or events. -

Psykologiska Institutionen
Does working memory capacity correlate with processing of auditory distractors under low versus high visual load? Rasmus Skarp Handledare: Stefan Wiens VETENSKAPLIG UNDERSÖKNING, 15 POÄNG (2018) STOCKHOLMS UNIVERSITET PSYKOLOGISKA INSTITUTIONEN DOES WORKING MEMORY CAPACITY CORRELATE WITH PROCESSING OF AUDITORY DISTRACTORS UNDER LOW VERSUS HIGH VISUAL LOAD? Rasmus Skarp Individuals with high working memory capacity (WMC) appear to be particularly good at focusing their attention (McCabe, Roediger, McDaniel, Balota, & Hambrick, 2010). Therefore, we studied the correlation between WMC and the ability to suppress neurological activity from a task-irrelevant stimulus. The research question tests the foundations of Lavie’s perceptual load theory; that early selection occurs, by testing if higher WMC enhances people’s ability to inhibit processing of task-irrelevant stimuli from low versus high load (i.e. the difference from low to high load should be smaller for high WMC than for low WMC). This was operationalised by measuring the correlation of WMC and auditory processing under low versus high visual load. Auditory processing was measured with auditory steady state responses (ASSR), and WMC was measured with an operation-letter span task. The results showed no significant correlation between WMC and ability to suppress task-irrelevant stimuli. Based on the data, it is not possible to conclude with certainty that effects of load on auditory processing are unaffected by WMC, because confidence intervals were large. The topic of perception has fascinated humankind for ages. In Plato’s (Plato, 380 B.C. referred to in Adam, 1902) allegory of the cave, prisoners sat looking at the shadows on a cave wall, thinking that this was the one true world. -
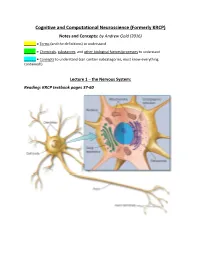
Cognitive and Computational Neuroscience (Formerly KRCP) Notes and Concepts: by Andrew Gold (2016) ______= Terms (And the Definitions) to Understand
Cognitive and Computational Neuroscience (Formerly KRCP) Notes and Concepts: by Andrew Gold (2016) ______ = Terms (and the definitions) to understand _____ = Chemicals, substances, and other biological factors/processes to understand ______ = Concepts to understand (can contain subcategories, must know everything contained!) Lecture 1 – the Nervous System: Reading: KRCP textbook pages 37-60 Nervous System: Neurons (100 Billion, 10^11): Neurons are the basic signaling units that transmit information throughout the Nervous System. Neurons vary in form, interconnectivity, and location, and these variances are closely related to their function. - Glial Cells (1 trillion, 10^12): are nonneural cells that serve various functions in the nervous system, and are still not fully understood. Provide structural support Create electrical insulation to the Neurons (Myelin) Modulate Neuronal activity o Astrocytes: Star-shaped Glial Cells that provide nutrients at the cellular level, as well as provide biochemical support/maintenance of the blood-brain barrier structures. o Oligodendrocytes: Cells that perform Myelination of the Neuron. o Schwann Cells: The primary Glia of the Peripheral Nervous System. Perform the same function of the Oligodendrocytes and Astrocytes, providing the Myelin Sheath as well as general maintenance to the nerves of the PNS. - Cell Body (Soma): Contains the machinery that produces proteins and other cellular macromolecules. Contains a Nucleus, Endoplasmic Reticulum, Cytoskeleton, Mitochondria, Golgi apparatus, other common intracellular organelles. These structures are suspended in Cytoplasm, the salty intracellular fluid made up of a combination of ions from Potassium, Sodium, Chloride, and Calcium. Dentrites: Branching extensions of the Neuron that receives input from other neurons. Many dendrites contain “spines,” or small knobs where dendrites receive input from other neurons. -

Your Attention, Please
Trabajo Final de Máster Your attention, please José María Cardona Guerra Dirigido por Ricardo Muñoz Martín y tutelado por Isabel García Izquierdo Máster en Investigación en Traducción e Interpretación Curso académico: 2014/2015 Fecha de lectura: lunes 23 de noviembre de 2015 Resumen: Este Trabajo de Fin de Máster presenta el estado de la cuestión en la investigación cognitiva del proceso de traducción e interpretación relativa a memoria y atención. Muchas investigaciones están aún bajo el influjo del paradigma del procesamiento de la información que, desde los años 50, ha contemplado la mente como un programa informático compacto y aislado que gestiona datos almacenados y los combina con información que obtiene por medio de los sentidos. Los enfoques cognitivos tradicionales en traducción e interpretación—y, en consecuencia, la investigación sobre los procesos cognitivos— se ha apoyado mucho en la memoria, pues su concepción metafórica como un enorme almacén de datos se ajusta perfectamente al modelo computacional. Este Trabajo de Fin de Máster esboza algunas objeciones al paradigma computacional y propone un cambio de enfoque que confiere mayor importancia a los mecanismos de atención al traducir o interpretar. Para ello, se resumen y comparan estudios que han abordado la memoria y los mecanismos de atención, tanto en monolingües como (después) en bilingües. Finalmente, se ofrece un panorama de los enfoques cognitivos sobre la memoria y la atención en traducción e interpretación. Palabras clave: atención, memoria, cognición, traducción e interpretación Abstract: The aim of this MA final paper is to provide a summary of the state of the art of research within cognitive approaches to the translation and interpreting processes that focus on memory and attention. -

Cognitive Psychology
Cognitive PSYCHoLogY 00_Eysenck Groome_Prelims.indd 1 19-Mar-15 1:44:31 PM Psychology: Revisiting the Classic Studies Series Editors: S. Alexander Haslam, Alan M. Slater and Joanne R. Smith School of Psychology, University of Exeter, Exeter, EX4 4QG sychology: Revisiting the Classic Studies is a new series of texts aimed at stu- P dents and general readers who are interested in understanding issues raised by key studies in psychology. Volumes centre on 12–15 studies, with each chapter providing a detailed account of a particular classic study and its empirical and theoretical impact. Chapters also discuss the important ways in which thinking and research has advanced in the years since the study was conducted. Chapters are written by researchers at the cutting edge of these developments and, as a result, these texts serve as an excellent resource for instructors and students look- ing to explore different perspectives on core material that defines the field of psychology as we know it today. Also available: Social Psychology: Revisiting the Classic Studies Joanne R. Smith and S. Alexander Haslam Developmental Psychology: Revisiting the Classic Studies Alan M. Slater and Paul C. Quinn 00_Eysenck Groome_Prelims.indd 2 17-Mar-15 12:36:02 PM 00_Eysenck Groome_Prelims.indd 3 19-Mar-15 1:44:31 PM SAGE Publications Ltd Editorial arrangement and Chapters 1 and 9 Michael W. Eysenck 1 Oliver’s Yard and David Groome 2015 55 City Road Chapter 2 Michael W. Eysenck 2015 London EC1Y 1SP Chapter 3 Vicki Bruce and Yoav Tadmor 2015 Chapter 4 George Mather 2015 SAGE Publications Inc. -

The Role of Attention in Information Processing Can Be Examined by Asking a Person to Focus on One Stimulus While Ignoring Another
A STUDY OF SELECTIVE ATTENTION IN YOUNG AUTISTIC SUBJECTS A Dissertation presented to the Faculty of the Graduate School at the University of Missouri-Columbia In Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy by ANNA HISMJATULLINA Dr. Nelson Cowan, Dissertation Supervisor DECEMBER 2006 The undersigned, appointed by the dean of the Graduate School, have examined the dissertation entitled A STUDY OF SELECTIVE ATTENTION IN CHILDREN WITH AUTISM Presented by Anna Hismjatullina A candidate for the degree of Doctor of Philosophy And hereby certify that in their opinion it is worthy of acceptance. Professor Nelson Cowan Professor Jeff Rouder Professor Debi Bell Professor Linda Day Professor Shawn Christ ACKNOWLEDGEMENTS I would like to express my gratitude for the guidance, mentoring, and intellectual support provided to me by my dissertation advisor, Dr. Nelson Cowan. His encouragement during the years of my education has made this research project possible. His search for truth instilled the values that I will hold throughout my professional career. This study would not have taken place without our little participants, those with the diagnosis of autism and those without. The help of parents, who manage therapies, homeworks, and play-dates, in search for any insight in diagnosis of autism was highly appreciated. ii TABLE OF CONTENTS ACKNOWLEDGEMENTS................................................................................................ ii LIST OF ILLUSTRATIONS............................................................................................ -

Approach to Automaticity
.!. .'.. 1 ~ A parallel distributed processing i ' approach to automaticity JONATHAN D., COHEN, DAVID SERVAN-SCHREIBER Camegie Mellon University and University of Pittsburgh JAMES L. McCLELLAND Carnegie Mellon University We consider how a particular set of information processing principles, de- veloped within the parallel distributed processing (PDP) framework, can address issues concerning automaticity. These principles include graded, activation-based processing that is subject to attentional modulation; incre- mental, connection-based learning; and interactivity and competition in pro- ~ 0 cessing. We show how simulation models, based on these principles, can account for the major phenomena associated with automaticity, as well as many of those that have been troublesome for more traditional theories. In particular, we show how the PDP framework provides an alternative to the usual, diChotomy between automatic and controlled processing and can ex- plain the relative nature of automaticity as, well as the fact that seemingly automatic processes can be influenced by attention. We also discuss how this framework can provide insight into the role that bidirectional influences play in processing: that is, how attention can influence processing at the same time that processing influences attention. Simulation models of. the Stroop color-word task. and the Eriksen response-competition task are de- scribed that help illustrate the application of the principles to performance in specific behavioral tasks. This special issue surveys current thinking about the concept of au- tomaticity. In this-: article , we consider this issue within the context a set of principles of information processing formulated in the. broad framework of parallel distributed processing (PDP). We will show how these principles make it possible to construct models that capture the major phenomena of automaticity, as well as many findings that have been seen as problematic for the usual dichotomy between automatic and controlled processes. -

Attention Issues in Attention Research IP Psychology Selective Attention Models Selective Attention Models
Attention Issues in Attention Research • Process of focusing • What happens to unattended information? mental effort on • What factors affect our ability to divide our particular task or stimulus attention? –Selective – Shiftable – Divisable –Limited IP Psychology Selective Attention Models Studies of selective attention (e.g. Selective Attention Models Cherry, 1953) • subjects are presented with 2 or more stimuli at the same time – this is called dual-task performance • Early Selection Models – Attention determines nature of info that goes into •for selective attention tasks, subjects are working memory (short-term store) instructed to attend to one input only – Selection occurs “early”, before info enters working memory 1 Dichotic listening task So what do we notice? • Listeners are good at detecting physical info • 2 simultaneous messages – could tell whether unattended channel was… – one to each ear • Male vs. Female • each message has different meaning • Speech vs. Buzzing – like listening to TV & radio at same time • Listeners are bad at detecting meaning info • Subjects must shadow one ear only – couldn’t identify any word/phrase – couldn’t tell whether unattended channel was… – repeat the message from one ear only • Forward vs. Backward • English vs. German • Experimenter then asks about unattended ear! – Listeners extract only certain info from unattended • So, attention is ear – sensitive to physical properties – insensitive to meaning Broadbent’s Filter Model of Broadbent’s Filter Model of selective attention selective attention • sensory information (speech) is received in channels Other channel no longer meaning extracted – channel = ear! processed after filtering… here on after • Info goes first to buffer (=temporary store) • Then filter selects attention (chooses 1 of the channels) I based on physical characteristics (e.g. -
Selective Attention
Selective Attention (dichotic listening) • People attend to one ear by “shadowing” – failed to notice in the other ear • when the unattended speech changed to German • speech in Czech spoken with English pronunciation • What’s reported from the unattended ear? – speech versus noise – gender of talker, loudness, pitch • What’s reported from the unattended ear? – noticed own name (cocktail party effect) • maybe attention “leaks” over? – Treisman (1960): participants mistakenly switch ears when the speech switches • can’t be explained by attention leaking over Theories of Attention • Filter Theory (Broadbent, 1958) – only a limited amount of information can be attended • attention has a limited capacity • there is an information bottleneck – only a small amount of information gets through – bottleneck early in processing (early selection) • before meaning has been determined – Filtering based on physical properties – However, this can’t explaining cocktail party effect • Attenuation Theory (Treisman, 1960) – Information isn’t filtered. Instead it’s attenuated • the volume is turned down, not off – Speech is processed in three stages and information at each stage can be attenuated • physical properties (e.g., attend to high voice, not low) • linguistic content (e.g., attend to English sounds, not Czech) • meaning (e.g., follow this conversation, not that one) – important word have lowered threshold (your name, “fire!”) – thresholds can be temporarily lowered (primed) by context » “the dog chased the ____”) Priming vs. Expectations (costs -

5 Attention and Performance Limitations
5 Attention and Performance Limitations INTRODUCTION As Pashler (1998, p. 1) pointed out, “Attention has long posed a major challenge for psychologists.” Historically, the concept of “attention” was treated as important by many philosophers and psychologists in the late 19th century. However, it fell into disrepute, because the behaviourists regarded all internal processes with the utmost suspicion. Attention became fashionable again following the publication of Broadbent’s book Perception and Communication in 1958, and has remained an important topic ever since. Attention is most commonly used to refer to selectivity of processing. This was the sense emphasised by William James (1890, pp. 403–404): Everyone knows what attention is. It is the taking possession of the mind, in clear and vivid form, of one out of what seem several simultaneously possible objects or trains of thought. Focalisation, concentration, of consciousness are of its essence. What is the relationship between attention and consciousness? Baars (1997) argued that access to consciousness is controlled by attentional mechanisms. Consider, for example, sentences such as, “We look in order to see” or “We listen in order to hear”. According to Baars (1997, p. 364), “The distinction is between selecting an experience and being conscious of the selected event. In everyday language, the first word of each pair [“look”; “listen”] involves attention; the second word [“see”; “hear”] involves consciousness.” In other words, attention resembles choosing a television channel and consciousness resembles the picture on the screen. William James (1890) distinguished between “active” and “passive” modes of attention. Attention is active when controlled in a top-down way by the individual’s goals, whereas it is passive when controlled in a bottom-up way by external stimuli (e.g., a loud noise).