“A Big-Data-Driven Approach for MTRC and Coronavirus Analysis”
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

OFFICIAL RECORD of PROCEEDINGS Wednesday, 11
LEGISLATIVE COUNCIL ─ 11 February 2015 6007 OFFICIAL RECORD OF PROCEEDINGS Wednesday, 11 February 2015 The Council met at Eleven o'clock MEMBERS PRESENT: THE PRESIDENT THE HONOURABLE JASPER TSANG YOK-SING, G.B.S., J.P. THE HONOURABLE ALBERT HO CHUN-YAN THE HONOURABLE LEE CHEUK-YAN THE HONOURABLE JAMES TO KUN-SUN THE HONOURABLE CHAN KAM-LAM, S.B.S., J.P. THE HONOURABLE LEUNG YIU-CHUNG DR THE HONOURABLE LAU WONG-FAT, G.B.M., G.B.S., J.P. THE HONOURABLE EMILY LAU WAI-HING, J.P. THE HONOURABLE TAM YIU-CHUNG, G.B.S., J.P. THE HONOURABLE ABRAHAM SHEK LAI-HIM, G.B.S., J.P. THE HONOURABLE TOMMY CHEUNG YU-YAN, S.B.S., J.P. THE HONOURABLE FREDERICK FUNG KIN-KEE, S.B.S., J.P. THE HONOURABLE VINCENT FANG KANG, S.B.S., J.P. 6008 LEGISLATIVE COUNCIL ─ 11 February 2015 THE HONOURABLE WONG KWOK-HING, B.B.S., M.H. PROF THE HONOURABLE JOSEPH LEE KOK-LONG, S.B.S., J.P., Ph.D., R.N. THE HONOURABLE JEFFREY LAM KIN-FUNG, G.B.S., J.P. THE HONOURABLE ANDREW LEUNG KWAN-YUEN, G.B.S., J.P. THE HONOURABLE WONG TING-KWONG, S.B.S., J.P. THE HONOURABLE RONNY TONG KA-WAH, S.C. THE HONOURABLE CYD HO SAU-LAN, J.P. THE HONOURABLE STARRY LEE WAI-KING, J.P. DR THE HONOURABLE LAM TAI-FAI, S.B.S., J.P. THE HONOURABLE CHAN HAK-KAN, J.P. THE HONOURABLE CHAN KIN-POR, B.B.S., J.P. DR THE HONOURABLE PRISCILLA LEUNG MEI-FUN, S.B.S., J.P. -

New Territories
Branch ATM District Branch / ATM Address Voice Navigation ATM 1009 Kwai Chung Road, Kwai Chung, New Kwai Chung Road Branch P P Territories 7-11 Shek Yi Road, Sheung Kwai Chung, New Sheung Kwai Chung Branch P P P Territories 192-194 Hing Fong Road, Kwai Chung, New Ha Kwai Chung Branch P P P Territories Shop 102, G/F Commercial Centre No.1, Cheung Hong Estate Commercial Cheung Hong Estate, 12 Ching Hong Road, P P P P Centre Branch Tsing Yi, New Territories A18-20, G/F Kwai Chung Plaza, 7-11 Kwai Foo Kwai Chung Plaza Branch P P Road, Kwai Chung, New Territories Shop No. 114D, G/F, Cheung Fat Plaza, Cheung Fat Estate Branch P P P P Cheung Fat Estate, Tsing Yi, New Territories Shop 260-265, Metroplaza, 223 Hing Fong Metroplaza Branch P P Road, Kwai Chung, New Territories 40 Kwai Cheong Road, Kwai Chung, New Kwai Cheong Road Branch P P P P Territories Shop 115, Maritime Square, Tsing Yi Island, Maritime Square Branch P P New Territories Maritime Square Wealth Management Shop 309A-B, Level 3, Maritime Square, Tsing P P P Centre Yi, New Territories ATM No.1 at Open Space Opposite to Shop No.114, LG1, Multi-storey Commercial /Car Shek Yam Shopping Centre Park Accommodation(also known as Shek Yam Shopping Centre), Shek Yam Estate, 120 Lei Muk Road, Kwai Chung, New Territories. Shop No.202, 2/F, Cheung Hong Shopping Cheung Hong Estate Centre No.2, Cheung Hong Estate, 12 Ching P Hong Road, Tsing Yi, New Territories Shop No. -

Designated 7-11 Convenience Stores
Store # Area Region in Eng Address in Eng 0001 HK Happy Valley G/F., Winner House,15 Wong Nei Chung Road, Happy Valley, HK 0009 HK Quarry Bay Shop 12-13, G/F., Blk C, Model Housing Est., 774 King's Road, HK 0028 KLN Mongkok G/F., Comfort Court, 19 Playing Field Rd., Kln 0036 KLN Jordan Shop A, G/F, TAL Building, 45-53 Austin Road, Kln 0077 KLN Kowloon City Shop A-D, G/F., Leung Ling House, 96 Nga Tsin Wai Rd, Kowloon City, Kln 0084 HK Wan Chai G6, G/F, Harbour Centre, 25 Harbour Rd., Wanchai, HK 0085 HK Sheung Wan G/F., Blk B, Hiller Comm Bldg., 89-91 Wing Lok St., HK 0094 HK Causeway Bay Shop 3, G/F, Professional Bldg., 19-23 Tung Lo Wan Road, HK 0102 KLN Jordan G/F, 11 Nanking Street, Kln 0119 KLN Jordan G/F, 48-50 Bowring Street, Kln 0132 KLN Mongkok Shop 16, G/F., 60-104 Soy Street, Concord Bldg., Kln 0150 HK Sheung Wan G01 Shun Tak Centre, 200 Connaught Rd C, HK-Macau Ferry Terminal, HK 0151 HK Wan Chai Shop 2, 20 Luard Road, Wanchai, HK 0153 HK Sheung Wan G/F., 88 High Street, HK 0226 KLN Jordan Shop A, G/F, Cheung King Mansion, 144 Austin Road, Kln 0253 KLN Tsim Sha Tsui East Shop 1, Lower G/F, Hilton Tower, 96 Granville Road, Tsimshatsui East, Kln 0273 HK Central G/F, 89 Caine Road, HK 0281 HK Wan Chai Shop A, G/F, 151 Lockhart Road, Wanchai, HK 0308 KLN Tsim Sha Tsui Shop 1 & 2, G/F, Hart Avenue Plaza, 5-9A Hart Avenue, TST, Kln 0323 HK Wan Chai Portion of shop A, B & C, G/F Sun Tao Bldg, 12-18 Morrison Hill Rd, HK 0325 HK Causeway Bay Shop C, G/F Pak Shing Bldg, 168-174 Tung Lo Wan Rd, Causeway Bay, HK 0327 KLN Tsim Sha Tsui Shop 7, G/F Star House, 3 Salisbury Road, TST, Kln 0328 HK Wan Chai Shop C, G/F, Siu Fung Building, 9-17 Tin Lok Lane, Wanchai, HK 0339 KLN Kowloon Bay G/F, Shop No.205-207, Phase II Amoy Plaza, 77 Ngau Tau Kok Road, Kln 0351 KLN Kwun Tong Shop 22, 23 & 23A, G/F, Laguna Plaza, Cha Kwo Ling Rd., Kwun Tong, Kln. -

Hung Hom Station to Transform Into an Upgraded Interchange Hub New Interchange Arrangements for the East Rail Line and West Rail Line
PR040/21 7 June 2021 Hung Hom Station to Transform into an Upgraded Interchange Hub New Interchange Arrangements for the East Rail Line and West Rail Line The new Tuen Ma Line (“TML”) platform at Hung Hom Station (“HUH”) will be opened on 20 June 2021 (Sunday), i.e. one week before the commissioning of TML, and new interchange arrangements for the West Rail Line (“WRL”) and the East Rail Line (“EAL”) will be in place on the same day. A series of upgrading works, including the construction of new platforms, have been implemented at HUH to cope with the full opening of the TML, as well as the commissioning of the Cross-Harbour Section of EAL. The new platforms will be put into service in phases according to the progress of the two projects. While the Cross-Harbour Section of EAL is still under construction, upon the opening of the new TML platform at HUH, passengers have to pass through the concourse to reach the existing EAL platform and the WRL (future TML) platform for changing between EAL and WRL (future TML) at HUH. (Please refer to annex for details). Passengers will have to follow the new interchange arrangements until the commissioning of the Cross-Harbour Section of EAL and the full launch of the new two-level platforms at HUH. By then passengers will be taking the EAL and TML at the new platforms. “Signage with colours corresponding to the relevant rail lines will be installed to direct passengers to the platforms they want to go to. We will also deploy additional staff, put up notices and make public announcements to assist and remind passengers of the new arrangements. -

Conference Information with Programme Schedule
Conference Information The 17th Annual Conference of the East Asian Social Policy Research Network & The 27th Annual Conference of the Foundation for International Studies on Social Security “BEYOND INEQUALITY? SOCIAL SECURITY AND SOCIAL WELFARE BETWEEN EAST AND WEST” 26-28 June 2020, Lingnan University, Hong Kong Conference programme EASP and FISS have worked closely together in recent months to ensure that all plenaries and panel sessions will be open to all delegates no matter whether they formally attend the EASP or FISS conference. All panel sessions will be announced after the deadline for abstract submission has passed. Booking & registration will start from 1 April (Standard rate: HK$1,500), with late registrations (from 1 June onwards) being charged at a slightly higher rate (HK$1,750). The provisional starting time of the opening ceremony on the first day of the conferences (26 June) is 9.00am and registrations will open at 8.15am. The conference will officially close on the third day (28 June) at 1.15pm. Lunch boxes will be provided on the final day to cater for those having to catch trains or flights. All other times are still provisional at this moment. DAY ONE – Friday, 26 June 2020: 8.15-9.00: Registration 9.00-9.30: Opening Ceremony and Official Welcomes from Lingnan University, FISS, and EASP § Prof. Ka Ho Mok, Vice Chancellor, Lingnan University, Hong Kong § Prof. Peter Saunders, FISS President § Prof. Shih-Jiunn Shi, Chair of EASP § Prof. Stefan Kühner, Secretary EASP/Lingnan University, Hong Kong Official conference photo taking DAY ONE – Cont. 9.30-10.20: Plenary 1: Prof. -
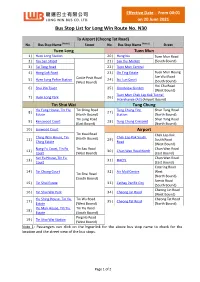
Bus Stop List for Long Win Route No. N30
Effective Date:From 00:01 on 20 June 2021 Bus Stop List for Long Win Route No. N30 To Airport (Cheong Tat Road) No. Bus Stop Name (Note 1) Street No. Bus Stop Name (Note 1) Street Yuen Long Tuen Mun 1) Yuen Long Station 20) Hung Kiu Tuen Mun Road 2) Yau San Street 21) San Hui Market (South Bound) 3) Tai Tong Road 22) Tuen Mun Central 4) Hong Lok Road 23) On Ting Estate Tuen Mun Heung Sze Wui Road 5) Yuen Long Police Station Castle Peak Road 24) Siu Lun Court (West Bound) (South Bound) Hoi Chu Road 6) Shui Pin Tsuen 25) Goodview Garden (West Bound) Tuen Mun Chek Lap Kok Tunnel 7) Yuen Long Park 26) Interchange (A3) (Airport Bound) Tin Shui Wai Tung Chung Yiu Fung House, Tin Yiu Tin Shing Road Tung Chung Fire Shun Tung Road 8) 27) Estate (North Bound) Station (North Bound) Tin Lung Road Shun Tung Road 9) Kenswood Court 28) Tung Chung Crescent (East Bound) (North Bound) 10) Lynwood Court Airport Tin Kwai Road Chek Lap Kok Ching Wan House, Tin Chek Lap Kok South 11) (North Bound) 29) South Road Ching Estate Road (West Bound) Nang Fu Court, Tin Fu Tin Sau Road Chun Wan Road 12) 30) Chun Wan Road North Court (West Bound) (East Bound) Yan Fu House, Tin Fu Chun Wan Road 13) 31) HACTL Court (East Bound) Catering Road 14) Tin Chung Court 32) Air Mail Centre West Tin Shui Road (North Bound) (South Bound) Scenic Road 15) Tin Shui Estate 33) Cathay Pacific City (South Bound) Cheong Lin Road 16) Tin Shui Wai Park 34) Cheong Lin Road (West Bound) Yiu Shing House, Tin Yiu Tin Wu Road Cheong Tat Road 17) 35) Cheong Tat Road Estate (West Bound) (North Bound) Yiu Man House, Tin Yiu Tin Yiu Road 18) Estate (South Bound) Ping Ha Road 19) Tin Shui Wai Station (West Bound) Note 1: Passengers can click on the hyperlink for the above bus stop name to check for the location and the street view of the bus stops. -

Chapter 3 Land Matters
Project Administration Handbook for Civil Engineering Works 2020 Edition CHAPTER 3 LAND MATTERS The parts of the PAH shown in blue and bold should only be updated by Works Branch of Development Bureau. Rev Issue Date Amendment Incorporated First Issue October 2020 NA Chapter 3 (Rev. 0) 1 Project Administration Handbook for Civil Engineering Works 2020 Edition SYNOPSIS This chapter sets out the procedures for the acquisition and control of land required for projects managed by CEDD, DSD, HyD and WSD. It does not cover the land requirements of quasi-government bodies such as the MTR Corporation Limited (MTRCL), but it describes the procedures necessary to avoid any possible interference with these land requirements. The authority for land matters is the Director of Lands (D of L) who exercises his duties through the respective District Lands Offices (DLOs). The role of CEDD, DSD, HyD and WSD in land matters is either as a works department requiring the temporary use of the site and associated areas, or in some instances as the operation department requiring the permanent use of the land. Because of the large number of departments that have a pertinent interest in land matters, it is necessary for formal procedures for the reservation, allocation, acquisition and clearance of land to be followed before any land can be made available for works to proceed. This chapter does not give details of procedures to be followed by the Lands Department (LandsD), which are covered by Land Instructions (LIs). However, reflections have been made to concur with the procedures laid down in the LIs. -

Review of Operations
Review of Operations 21 Property Sales 64 Property Related Businesses 22 Hong Kong Property Business 71 Telecommunications and Information Technology 22 Land Bank 72 Transportation, Infrastructure and Logistics 24 Property Development 34 Property Investment 75 Corporate Finance 44 Mainland Property Business 76 Customer Service 44 Land Bank 46 Property Development 60 Property Investment The Group’s International Commerce Centre and International Finance Centre form a magnificent Victoria Harbour Gateway SUN HUNG KAI PROPERTIES LIMITED 20 Annual Report 2009/10 Property Sales The Group sold or pre-sold an attributable HK$23,218 million worth of properties in the third quarter of 2010, mainly from Hong Kong of properties in the year under review, compared to last year’s properties including Lime Stardom in Kowloon and Larvotto in HK$25,674 million. A number of projects in Hong Kong and on the Island South. Nearly 95 per cent of the units in these two projects mainland were put on the market over the past year and produced have been sold. highly encouraging sales. The Group will continue offering new developments for sale as Sales of Hong Kong properties amounted to HK$20,562 million, planned. Major residential projects in Hong Kong to go on sale in mostly from YOHO Midtown in Yuen Long, Aria and The Latitude the rest of the current financial year include luxury town houses in Kowloon and The Cullinan at Kowloon Station. The remaining Valais at Beas River, Avignon on Castle Peak Road, Park Nara and a HK$2,656 million was from mainland and Singapore properties, project on Po Yip Street in Yuen Long and the residential towers including Lake Dragon in Guangzhou and Orchard Residences in at the integrated landmark development at Tseung Kwan O Singapore. -
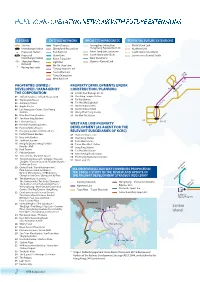
2 Hong Kong Operating Network with Future
Shenzhen Lo Wu HONG KONG OPERATING NETWORK WITH FUTURE EXTENSIONS Intercity Through Beijing Train Route Map Lok Ma Chau Sheung Shui LEGEND EXISTING NETWORK PROJECTS IN PROGRESS POTENTIAL FUTURE EXTENSIONS Shanghai Station Airport Express Guangzhou-Shenzhen- North Island Link Kwu Tung Hong Kong Express Rail Link Fanling Beijing Line Interchange Station Disneyland Resort Line Northern Link Zhaoqing Guangzhou Proposed Station East Rail Line Kwun Tong Line Extension South Island Line (West) Shanghai Line South Island Line (East) Proposed Island Line Extension to Central South Guangdong Line Foshan Interchange Station Kwun Tong Line West Island Line Dongguan HONG KONG SAR Shenzhen Metro Light Rail Shatin to Central Link Network Ma On Shan Line * Racing days only Tseung Kwan O Line Tai Wo Tsuen Wan Line Yuen Long Long Tung Chung Line Ping 44 West Rail Line 40 47 33 Kam Tai Po Market PROPERTIES OWNED / PROPERTY DEVELOPMENTS UNDER Sheung 48 Road DEVELOPED / MANAGED BY CONSTRUCTION / PLANNING 49 THE CORPORATION 34 LOHAS Park Package 2C-10 Tin Shui Wai Ma On Shan 36 50 01 Telford Gardens / Telford Plaza I and II 38 Che Kung Temple Station Wu Kai Sha 02 World-wide House 39 Tai Wai Station New Territories Heng On 03 Admiralty Centre 40 Tin Shui Wai Light Rail University 04 Argyle Centre 41 Austin Station Site C Siu Hong Tai Shui 05 Luk Yeung Sun Chuen / Luk Yeung 42 Austin Station Site D Hang Galleria 52 Wong Chuk Hang Station 06 New Kwai Fong Gardens 53 Ho Man Tin Station 27 07 Sun Kwai Hing Gardens 35 29 Tuen Mun Racecourse* 08 Fairmont House 30 -

Administration's Paper on Tuen Mun South Extension
LC Paper No. CB(4)646/19-20(01) Translation Legislative Council Panel on Transport Subcommittee on Matters Relating to Railways Tuen Mun South Extension Introduction This paper briefs Members on the proposed way forward of the Tuen Mun South (“TMS”) Extension project. Background 2. The TMS Extension is one of the seven recommended railway schemes in the Railway Development Strategy 2014 (“RDS-2014”). The proposed project will extend the West Rail Line (“WRL”) from Tuen Mun Station southwards by about 2.4 kilometres, including the provision of a new station near Tuen Mun Ferry Pier and an intermediate station at Tuen Mun Area 16 (“A16”), to improve railway access to the community south of the Tuen Mun town centre. MTRCL’s Project Proposal for TMS Extension 3. In February 2016, the Transport and Housing Bureau (“THB”) invited the MTR Corporation Limited (“MTRCL”) to submit a proposal for TMS Extension under the ownership approach 1 . MTRCL submitted a Project Proposal in December 2016, which was subsequently supplemented with updates in July 2017 and January 2018 respectively. In addition to a new TMS Station to be provided near Tuen Mun Ferry Pier as envisaged in RDS-2014, MTRCL proposed in its latest Project Proposal to provide an additional station at Tuen Mun A16 (see A Annex A) with topside development. 4. Incorporating an A16 Station in the TMS Extension will provide residential development opportunities at A16. Having considered the pros and 1 Under the ownership approach, MTRCL will be responsible for the financing, design, construction, operation and maintenance of the new railway, and ultimately own the railway. -

SUN HUNG KAI PROPERTIES LIMITED 2 ANNUAL REPORT 2014/15 Worldreginfo - D930b7f2-B74a-49Ea-993D-33D5f2a11b1e Corporate Information and Information for Shareholders
WorldReginfo - d930b7f2-b74a-49ea-993d-33d5f2a11b1e - WorldReginfo Annual Report 2014/15 Annual Stock Code : 16 Warrant Code : 1441 2014/15 Annual Report C105708 3 4 2 1 5 1. Sun Hung Kai Centre in Wanchai, Hong Kong 2. The Cullinan at Kowloon Station, Hong Kong 3. International Commerce Centre at Kowloon Station, Hong Kong 4. Two International Finance Centre in Central, Hong Kong 5. One International Finance Centre in Central, Hong Kong WorldReginfo - d930b7f2-b74a-49ea-993d-33d5f2a11b1e Contents 2 Board of Directors and Committees 3 Corporate Information and Information for Shareholders 4 Financial Highlights and Land Bank 6 Group Financial Summary 7 Business Structure 8 Chairman’s Statement 22 Business Model and Strategic Direction 24 Review of Operations 26 Hong Kong Property Business 52 Mainland Property Business 72 Property Related Businesses 81 Telecommunications and Information Technology 82 Infrastructure and Other Businesses 85 Corporate Finance 86 Financial Review 88 Investor Relations 90 Sustainable Development 98 Corporate Governance Report 112 Directors’ Report 136 Directors’ Biographical Information 147 Executive Committee 148 Consolidated Financial Statements WorldReginfo - d930b7f2-b74a-49ea-993d-33d5f2a11b1e Board of Directors and Committees Board of Directors Executive Directors Kwok Ping-luen, Raymond (Chairman & Managing Director) Wong Chik-wing, Mike (Deputy Managing Director) Lui Ting, Victor (Deputy Managing Director) Kwok Kai-fai, Adam Kwong Chun Chan Kwok-wai, Patrick (Chief Financial Officer) Tung Chi-ho, Eric -

AECOM to Provide Design Consultancy for Tuen Mun South Extension, Hong Kong
AECOM to provide design consultancy for Tuen Mun South Extension, Hong Kong October 29, 2020 LOS ANGELES--(BUSINESS WIRE)--Oct. 29, 2020-- AECOM (NYSE:ACM), the world’s premier infrastructure consulting firm, has been awarded the detailed planning and design consultancy contract for the Tuen Mun South Extension, Hong Kong. The project includes a 2.4-km extension of the West Rail Line from the existing Tuen Mun Station to a new terminus at Tuen Mun South, with a new intermediate station A16, which will be developed with the property development in the area. "As we execute our strategy of bringing together one integrated design organization, we will leverage our best-in-class, global transportation design capabilities to bring the full breadth of our expertise to bear on this project," said Troy Rudd, AECOM’s chief executive officer. “Over the past 5 decades, AECOM has worked in close partnership with Mass Transit Railway (MTR) and provided strategy studies to 90% of Hong Kong’s rail system. We look forward to working with MTR on this latest rail transportation project which builds upon this to enhance connectivity of our communities in Hong Kong,” said Ian Chung, AECOM’s chief executive, Greater China. The scope of the consultancy includes development of the scheme into an engineering design, preparation of the construction program, gazette plans, project cost estimate, and liaison with government departments and other stakeholders. AECOM will work closely with the MTR Projects team to deliver the above services. On completion, this project will greatly improve local connectivity, supporting planned housing developments and improving livability for residents of this new town.