Deployment Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Performance Counters in Htop 3.0
Slide: [ ] Talk: Perf counters in htop 3.0 Presenter: https://hisham.hm PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command Performance counters in htop 3.0 Hisham Muhammad @[email protected] https://hisham.hm Slide: [ 2 ] Date: 2018-08-25 Talk: Perf counters in htop 3.0 Presenter: https://hisham.hm PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command About me original author of htop, a project started in 2004 http://hisham.hm/htop/ lead dev of LuaRocks, package manager for Lua http://luarocks.org/ co-founder of the GoboLinux distribution http://gobolinux.org/ developer at Kong – FLOSS API gateway http://getkong.org/ (we’re hiring!) Slide: [ 3 ] Date: 2018-08-25 Talk: Perf counters in htop 3.0 Presenter: https://hisham.hm PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command What is htop an interactive process manager intended to be “a better top” by this all I originally meant was: scrolling! (versions of top improved a lot since!) Slide: [ 4 ] Date: 2018-08-25 Talk: Perf counters in htop 3.0 Presenter: https://hisham.hm PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command Hello, htop! Slide: [ 5 ] Date: 2018-08-25 Talk: Perf counters in htop 3.0 Presenter: https://hisham.hm PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command htop beyond Linux Linux MacOS FreeBSD OpenBSD DragonFlyBSD Solaris (illumos) Slide: [ 6 ] Date: 2018-08-25 Talk: Perf counters in htop 3.0 Presenter: https://hisham.hm PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command Then Apple released a broken kernel.. -

Freiesmagazin 12/2012
freiesMagazin Dezember 2012 Topthemen dieser Ausgabe Slackware 14.0 Seite 3 Die wohl älteste noch aktive Linux-Distribution hat nach überdurchschnittlich langer Entwick- lungszeit die neue Version 14.0 veröffentlicht. Der Artikel gibt eine Übersicht über Altes und Neues, was sich seit Version 9.0 so alles geändert hat – und was nicht. (weiterlesen) Video Disk Recoder auf Basis von easyVDR 1.0 Seite 10 Der Artikel erklärt den Aufbau eines MediaCenters auf Basis der Distribution easyVDR und stellt die Neuerungen der Version 1.0 sowie deren Installation und Konfiguration vor. Der Schwerpunkt des Artikels liegt dabei in der Hardwareauswahl und den neuen Features der jetzt auf der Linux-Distribution Ubuntu basierten Version 1.0 sowie der „easy“ Inbetriebnahme dieser. (weiterlesen) Softmaker Office 2012 Seite 25 Der Markt für Büroprogramme ist unübersichtlich: In der Windows-Welt gilt Microsoft Office trotz der saftigen Preise immer noch als Referenz. Unter Linux dürfte dagegen LibreOffice mitt- lerweile den Stand eines Standards erreicht haben. Hinzu kommen noch zahlreiche freie An- wendungen und diverse kommerzielle Alternativen. Eines der Programme mit professionellem Anspruch ist SoftMaker Office, das nicht nur Nischenmärkte unter verschiedenen Systemen besetzen, sondern eine Alternative zu den Platzhirschen sein will. (weiterlesen) © freiesMagazin CC-BY-SA 3.0 Ausgabe 12/2012 ISSN 1867-7991 MAGAZIN Editorial Sechster Programmierwettbewerb werden dann ebenfalls einige Meta-Daten zu der Inhalt Linux allgemein Im März 2012 gab es mit dem fünften Wett- jeweiligen Ausgabe angezeigt. Slackware 14.0 S. 3 bewerb ein kleines Zwischenspiel außer der Aber auch so haben wir weiter an der CSS-Datei Video Disk Recoder auf Basis von S. -

Red Hat Enterprise Linux 8 Installing, Managing, and Removing User-Space Components
Red Hat Enterprise Linux 8 Installing, managing, and removing user-space components An introduction to AppStream and BaseOS in Red Hat Enterprise Linux 8 Last Updated: 2021-06-25 Red Hat Enterprise Linux 8 Installing, managing, and removing user-space components An introduction to AppStream and BaseOS in Red Hat Enterprise Linux 8 Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. -
20 Linux System Monitoring Tools Every Sysadmin Should Know by Nixcraft on June 27, 2009 · 315 Comments · Last Updated November 6, 2012
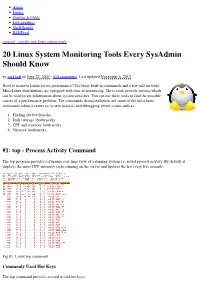
About Forum Howtos & FAQs Low graphics Shell Scripts RSS/Feed nixcraft - insight into linux admin work 20 Linux System Monitoring Tools Every SysAdmin Should Know by nixCraft on June 27, 2009 · 315 comments · Last updated November 6, 2012 Need to monitor Linux server performance? Try these built-in commands and a few add-on tools. Most Linux distributions are equipped with tons of monitoring. These tools provide metrics which can be used to get information about system activities. You can use these tools to find the possible causes of a performance problem. The commands discussed below are some of the most basic commands when it comes to system analysis and debugging server issues such as: 1. Finding out bottlenecks. 2. Disk (storage) bottlenecks. 3. CPU and memory bottlenecks. 4. Network bottlenecks. #1: top - Process Activity Command The top program provides a dynamic real-time view of a running system i.e. actual process activity. By default, it displays the most CPU-intensive tasks running on the server and updates the list every five seconds. Fig.01: Linux top command Commonly Used Hot Keys The top command provides several useful hot keys: Hot Usage Key t Displays summary information off and on. m Displays memory information off and on. Sorts the display by top consumers of various system resources. Useful for quick identification of performance- A hungry tasks on a system. f Enters an interactive configuration screen for top. Helpful for setting up top for a specific task. o Enables you to interactively select the ordering within top. r Issues renice command. -

Red Hat Jboss Developer Studio
RED HAT JBOSS DEVELOPER STUDIO DATASHEET BENEFITS EVERYTHING YOU NEED TO DEVELOP, TEST, AND DEPLOY RICH WEB, MOBILE WEB, AND ENTERPRISE APPLICATIONS AND SOA SERVICES. • Provides a pre-assembled ® ® development environment, Red Hat JBoss Developer Studio provides superior support for your entire development life including both tooling and cycle in a single tool. It is a certified Eclipse-based integrated development environment (IDE) for runtime components developing, testing, and deploying rich web applications, mobile web applications, transactional enterprise applications, and SOA-based integration applications and services. • Enables development of applications for deployment JBoss Developer Studio includes a broad set of tooling capabilities and support for multiple pro- on-premise or in the cloud gramming models and frameworks, including Java™ Enterprise Edition 6, RichFaces, JavaServer ® through its seamless inte- Faces (JSF), Enterprise JavaBeans (EJB), Java Persistence API (JPA), and Hibernate , JAX-RS gration with both OpenShift with RESTEasy, Contexts Dependency Injection (CDI), HTML5, and many other popular technolo- Enterprise by Red Hat and gies. It is fully tested and certified to ensure that all its plug-ins, runtime components, and their OpenShift Online by Red Hat dependencies are compatible with each other. • Certified updates so you JBoss Developer Studio provides developer choice in supporting multiple Java virtual machines don’t have to worry about (JVMs), productivity with Maven, and testing with Arquillian. It also includes all needed depen- updating parts that may dencies and third-party plugins. These pre-configured tools save time and offer significant value, not work with the rest of improving productivity and reducing deployment times. the environment Developers can have confidence that their development environment is stable, upgradeable, • Tested and certified to deployable, and supportable. -

Oracle® Linux 7 Monitoring and Tuning the System
Oracle® Linux 7 Monitoring and Tuning the System F32306-03 October 2020 Oracle Legal Notices Copyright © 2020, Oracle and/or its affiliates. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial computer software documentation" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, reproduction, duplication, release, display, disclosure, modification, preparation of derivative works, and/or adaptation of i) Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs), ii) Oracle computer documentation and/or iii) other Oracle data, is subject to the rights and limitations specified in the license contained in the applicable contract. -

Address Space Layout Permutation (ASLP): Towards Fine-Grained Randomization of Commodity Software
Address Space Layout Permutation (ASLP): Towards Fine-Grained Randomization of Commodity Software Chongkyung Kil,∗ Jinsuk Jun,∗ Christopher Bookholt,∗ Jun Xu,† Peng Ning∗ Department of Computer Science∗ Google, Inc.† North Carolina State University {ckil, jjun2, cgbookho, pning}@ncsu.edu [email protected] Abstract a memory corruption attack), an attacker attempts to alter program memory with the goal of causing that program to Address space randomization is an emerging and behave in a malicious way. The result of a successful at- promising method for stopping a broad range of memory tack ranges from system instability to execution of arbitrary corruption attacks. By randomly shifting critical memory code. A quick survey of US-CERT Cyber Security Alerts regions at process initialization time, address space ran- between mid-2005 and 2004 shows that at least 56% of the domization converts an otherwise successful malicious at- attacks have a memory corruption component [24]. tack into a benign process crash. However, existing ap- Memory corruption vulnerabilities are typically caused proaches either introduce insufficient randomness, or re- by the lack of input validation in the C programming lan- quire source code modification. While insufficient random- guage, with which the programmers are offered the free- ness allows successful brute-force attacks, as shown in re- dom to decide when and how to handle inputs. This flex- cent studies, the required source code modification prevents ibility often results in improved application performance. this effective method from being used for commodity soft- However, the number of vulnerabilities caused by failures ware, which is the major source of exploited vulnerabilities of input validation indicates that programming errors of this on the Internet. -

5.7 Release Notes
Red Hat Enterprise Linux 5 5.7 Release Notes Release Notes for Red Hat Enterprise Linux 5.7 Red Hat Inc. Red Hat Enterprise Linux 5 5.7 Release Notes Release Notes for Red Hat Enterprise Linux 5.7 Legal Notice Copyright © 2011 Red Hat, Inc. This document is licensed by Red Hat under the Creative Commons Attribution-ShareAlike 3.0 Unported License. If you distribute this document, or a modified version of it, you must provide attribution to Red Hat, Inc. and provide a link to the original. If the document is modified, all Red Hat trademarks must be removed. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat Software Collections is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. The OpenStack ® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation's permission. -

Using the Mysql Yum Repository Abstract
Using the MySQL Yum Repository Abstract This document provides some basic instructions for using the MySQL Yum Repository to install and upgrade MySQL. It is excerpted from the MySQL 5.6 Reference Manual. For legal information, see the Legal Notices. For help with using MySQL, please visit the MySQL Forums, where you can discuss your issues with other MySQL users. Document generated on: 2021-09-23 (revision: 70881) Table of Contents Preface and Legal Notices ............................................................................................................ v 1 Installing MySQL on Linux Using the MySQL Yum Repository ..................................................... 1 2 Replacing a Third-Party Distribution of MySQL Using the MySQL Yum Repository ........................ 5 3 Upgrading MySQL with the MySQL Yum Repository ................................................................... 9 iii iv Preface and Legal Notices This document provides some basic instructions for using the MySQL Yum Repository to install and upgrade MySQL. It is excerpted from the MySQL 5.6 Reference Manual. Licensing information—MySQL 5.6. This product may include third-party software, used under license. If you are using a Commercial release of MySQL 5.6, see the MySQL 5.6 Commercial Release License Information User Manual for licensing information, including licensing information relating to third-party software that may be included in this Commercial release. If you are using a Community release of MySQL 5.6, see the MySQL 5.6 Community Release License Information User Manual for licensing information, including licensing information relating to third-party software that may be included in this Community release. Licensing information—MySQL NDB Cluster 7.3. This product may include third-party software, used under license. If you are using a Commercial release of NDB Cluster 7.3, see the MySQL NDB Cluster 7.3 Commercial Release License Information User Manual for licensing information relating to third-party software that may be included in this Commercial release. -

Security Enhancements in Red Hat Enterprise Linux (Beside Selinux)
Security Enhancements in Red Hat Enterprise Linux (beside SELinux) Ulrich Drepper Red Hat, Inc. [email protected] December 9, 2005 Abstract Bugs in programs are unavoidable. Programs developed using C and C++ are especially in danger. If bugs cannot be avoided the next best thing is to limit the damage. This article will show improvements in Red Hat Enterprise Linux which achieve just that. 1 Introduction These problems are harder to protect against since nor- mally2 all of the OS’s functionality is available and the Security problems are one of the biggest concerns in the attacker might even be able to use self-compiled code. industry today. Providing services on networked comput- ers which are accessible through the intranet and/or Inter- Remotely exploitable problems are more serious since net potentially to untrusted individuals puts the installa- the attacker can be anywhere if the machine is available tion at risk. A number of changes have been made to the through the Internet. On the plus side, only applications Linux OS1 which help a lot to mitigate the risks. Up- accessible through the network services provided by the coming Red Hat Enterprise Linux versions will feature machine can be exploited, which limits the range of ex- the SELinux extensions, originally developed by the Na- ploits. Further limitations are the attack vectors. Usually tional Security Agency (NSA), with whom Red Hat now remote attackers can influence applications only by pro- collaborates to productize the developed code. SELinux viding specially designed input. This often means cre- means a major change in Linux and is a completely sep- ating buffer overflows, i.e., situations where the data is arate topic by itself. -

The Kdesvn Handbook
The kdesvn Handbook Rajko Albrecht The kdesvn Handbook 2 Contents 1 Introduction 7 1.1 Terms . .7 2 Using kdesvn 8 2.1 kdesvn features . .8 2.2 Beginning with subversion and kdesvn . .8 2.2.1 Creating a working copy . .9 2.2.2 Committing local changes . .9 2.2.3 Update working copy . .9 2.2.4 Adding and Deleting from working copy . .9 2.2.4.1 Add items . 10 2.2.4.2 Deleting items from working copy and unversion . 10 2.2.5 Displaying logs . 10 2.2.5.1 The log display dialog . 10 2.3 Working on repositories . 11 2.3.1 Restoring deleted items . 11 2.3.2 Importing folders . 11 2.3.2.1 With drag and drop . 11 2.3.2.2 Select folder to import with directory-browser . 11 2.4 Other Operations . 11 2.4.1 Merge . 11 2.4.1.1 Internal merge . 12 2.4.1.2 Using external program for merge . 12 2.4.2 Resolving conflicts . 12 2.5 Properties used by kdesvn for configuration . 13 2.5.1 Bugtracker integration . 13 2.6 The revision tree . 13 2.6.1 Requirements . 14 2.7 Internal log cache . 14 2.7.1 Offline mode . 14 2.7.2 Log cache and revision tree . 14 The kdesvn Handbook 2.8 Meaning of icon overlays . 14 2.9 kdesvn and passwords . 16 2.9.1 Not saving passwords . 16 2.9.2 Saving passwords in KWallet . 16 2.9.3 Saving to subversion’s own password storage . -

Add-Ons for Red Hat Enterprise Linux
DATASHEET ADD-ONS FOR RED HAT ENTERPRISE LINUX WORKLOAD AND MISSION-CRITICAL PLATFORM ENHANCEMENTS In conjunction with Red Hat® Enterprise Linux®, Red Hat offers a portfolio of Add-Ons to extend the features of your Red Hat Enterprise Linux subscription. Add-Ons to Red Hat Enterprise Linux tailor your application environment to suit your particular computing requirements. With increased flexibility and choice, customers can deploy what they need, when they need it. ADD-ON OPTIONS FOR AVAILABILITY MANAGEMENT High Availability Add-On Red Hat’s High Availability Add-On provides on-demand failover services between nodes within a cluster, making applications highly available. The High Availability Add-On supports up to 16 nodes and may be configured for most applications that use customizable agents, as well as for virtual guests. The High Availability Add-On also includes failover support for off-the-shelf applications like Apache, MySQL, and PostgreSQL. When using the High Availability Add-On, a highly available service can fail over from one node to another with no apparent interruption to cluster clients. The High Availability Add-On also ensures data integrity when one cluster node takes over control of a service from another clus- ter node. It achieves this by promptly evicting nodes from the cluster that are deemed to be faulty using a method called “fencing” that prevents data corruption. www.redhat.com DATASHEET ADD-ONS For RED Hat ENterprise LINUX 6 Resilient Storage Add-On Red Hat’s Resilient Storage Add-On enables a shared storage or clustered file system to access the same storage device over a network.