A Variability-Aware Module System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

JACSM No 1 2009
STORE: EMBEDDED PERSISTENT STORAGE FOR CLOJURE PROGRAMMING LANGUAGE Konrad Grzanek1 1IT Institute, Academy of Management, Lodz, Poland [email protected] Abstract Functional programming is the most popular declarative style of programming. Its lack of state leads to an increase of programmers' productivity and software robustness. Clojure is a very effective Lisp dialect, but it misses a solid embedded database implementation. A store is a proposed embedded database engine for Clojure that helps to deal with the problem of the inevitable state by mostly functional, minimalistic interface, abandoning SQL and tight integration with Clojure as a sole query and data-processing language. Key words: Functional programming, Lisp, Clojure, embedded database 1 Introduction Functional programming languages and functional programming style in general have been gaining a growing attention in the recent years. Lisp created by John McCarthy and specified in [8] is the oldest functional pro- gramming language. Some of its flavors (dialects, as some say [9]) are still in use today. Common Lisp was the first ANSI standardized Lisp dialect [13] and Common Lisp Object System (CLOS) was probably the first ANSI stan- dardized object oriented programming language [14]. Apart from its outstand- ing features as a Common Lisp subset. Various Lisps were used in artificial intelligence [11] and to some extent the language comes from AI labs and its ecosystem. Common Lisp was used as the language of choice by some AI tutors, like Peter Norvig (in [10]). But the whole family of languages address general problems in computer science, not only these in AI. John Backus argues [3] that the functional style is a real liberation from the traditional imperative languages and their problems. -

Sentiment Analysis Using a Novel Human Computation Game
Sentiment Analysis Using a Novel Human Computation Game Claudiu-Cristian Musat THISONE Alireza Ghasemi Boi Faltings Artificial Intelligence Laboratory (LIA) Ecole Polytechnique Fed´ erale´ de Lausanne (EPFL) IN-Ecublens, 1015 Lausanne, Switzerland [email protected] Abstract data is obtained from people using human computa- tion platforms and games. We also prove that the In this paper, we propose a novel human com- method can provide not only labelled texts, but peo- putation game for sentiment analysis. Our ple also help by selecting sentiment-expressing fea- game aims at annotating sentiments of a col- tures that can generalize well. lection of text documents and simultaneously constructing a highly discriminative lexicon of Human computation is a newly emerging positive and negative phrases. paradigm. It tries to solve large-scale problems by Human computation games have been widely utilizing human knowledge and has proven useful used in recent years to acquire human knowl- in solving various problems (Von Ahn and Dabbish, edge and use it to solve problems which are 2004; Von Ahn, 2006; Von Ahn et al., 2006a). infeasible to solve by machine intelligence. To obtain high quality solution from human com- We package the problems of lexicon construc- putation, people should be motivated to make their tion and sentiment detection as a single hu- best effort. One way to incentivize people for sub- man computation game. We compare the re- mitting high-quality results is to package the prob- sults obtained by the game with that of other well-known sentiment detection approaches. lem at hand as a game and request people to play Obtained results are promising and show im- it. -

October 2011 Vol
NoSQL GREG BURD Hypervisors and Virtual Machines: Implementation Insights on the x86 Architecture DON REVELLE Conference Reports from the 2011 USENIX Annual Technical Conference, HotPar, and more OCTOBER 2011 VOL. 36, NO. 5 THE ADVANCED COMPUTING SYSTEMS ASSOCIATION THE ADVANCED COMPUTING SYSTEMS ASSOCIATION usenix_login_oct11_covers.indd 1 9.9.11 5:55 PM UPCOMING EVENTS 23rd ACM Symposium on Operating Systems 9th USENIX Symposium on Networked Systems Principles (SOSP 2011) Design and Implementation (NSDI ’12) SPONSORED BY ACM SIGOPS IN COOPERATION WITH USENIX SPONSORED BY USENIX IN COOPERATION WITH ACM SIGCOMM AND ACM SIGOPS October 23–26, 2011, Cascais, Portugal April 25–27, 2012, San Jose, CA http://sosp2011.gsd.inesc-id.pt http://www.usenix.org/nsdi12 ACM Symposium on Computer Human Interac- tion for Management of Information Technology 2012 USENIX Federated Conferences Week (CHIMIT 2011) June 12–15, 2012, Boston, MA, USA http://www.usenix.org/fcw12 SPONSORED BY ACM IN ASSOCIATION WITH USENIX December 4–5, 2011, Boston, MA 2012 USENIX Annual Technical Conference http://chimit.acm.org/ (USENIX ATC ’12) June 13–15, 2012, Boston, MA 25th Large Installation System Administration http://www.usenix.org/atc12 Conference (LISA ’11) Paper titles and abstracts due January 10, 2012 SPONSORED BY USENIX IN COOPERATION WITH LOPSA December 4–9, 2011, Boston, MA 21st USENIX Security Symposium http://www.usenix.org/lisa11 (USENIX Security ’12) August 6–10, 2012, Bellevue, WA ACM/IFIP/USENIX 12th International Middleware Conference (Middleware 2011) -

C:\Andrzej\PDF\ABC Nagrywania P³yt CD\1 Strona.Cdr
IDZ DO PRZYK£ADOWY ROZDZIA£ SPIS TREFCI Wielka encyklopedia komputerów KATALOG KSI¥¯EK Autor: Alan Freedman KATALOG ONLINE T³umaczenie: Micha³ Dadan, Pawe³ Gonera, Pawe³ Koronkiewicz, Rados³aw Meryk, Piotr Pilch ZAMÓW DRUKOWANY KATALOG ISBN: 83-7361-136-3 Tytu³ orygina³u: ComputerDesktop Encyclopedia Format: B5, stron: 1118 TWÓJ KOSZYK DODAJ DO KOSZYKA Wspó³czesna informatyka to nie tylko komputery i oprogramowanie. To setki technologii, narzêdzi i urz¹dzeñ umo¿liwiaj¹cych wykorzystywanie komputerów CENNIK I INFORMACJE w ró¿nych dziedzinach ¿ycia, jak: poligrafia, projektowanie, tworzenie aplikacji, sieci komputerowe, gry, kinowe efekty specjalne i wiele innych. Rozwój technologii ZAMÓW INFORMACJE komputerowych, trwaj¹cy stosunkowo krótko, wniós³ do naszego ¿ycia wiele nowych O NOWOFCIACH mo¿liwoYci. „Wielka encyklopedia komputerów” to kompletne kompendium wiedzy na temat ZAMÓW CENNIK wspó³czesnej informatyki. Jest lektur¹ obowi¹zkow¹ dla ka¿dego, kto chce rozumieæ dynamiczny rozwój elektroniki i technologii informatycznych. Opisuje wszystkie zagadnienia zwi¹zane ze wspó³czesn¹ informatyk¹; przedstawia zarówno jej historiê, CZYTELNIA jak i trendy rozwoju. Zawiera informacje o firmach, których produkty zrewolucjonizowa³y FRAGMENTY KSI¥¯EK ONLINE wspó³czesny Ywiat, oraz opisy technologii, sprzêtu i oprogramowania. Ka¿dy, niezale¿nie od stopnia zaawansowania swojej wiedzy, znajdzie w niej wyczerpuj¹ce wyjaYnienia interesuj¹cych go terminów z ró¿nych bran¿ dzisiejszej informatyki. • Komunikacja pomiêdzy systemami informatycznymi i sieci komputerowe • Grafika komputerowa i technologie multimedialne • Internet, WWW, poczta elektroniczna, grupy dyskusyjne • Komputery osobiste — PC i Macintosh • Komputery typu mainframe i stacje robocze • Tworzenie oprogramowania i systemów komputerowych • Poligrafia i reklama • Komputerowe wspomaganie projektowania • Wirusy komputerowe Wydawnictwo Helion JeYli szukasz ]ród³a informacji o technologiach informatycznych, chcesz poznaæ ul. -

Portability Techniques for Embedded Systems Data Management
Portability Techniques for Embedded Systems Data Management McObject LLC st 33309 1 Way South Suite A-208 Federal Way, WA 98003 Phone: 425-888-8505 E-mail: [email protected] www.mcobject.com Copyright 2020, McObject LLC Whether an embedded systems database is developed for a specific application or as a commercial product, portability matters. Most embedded data management code is still “homegrown,” and when external forces drive an operating system or hardware change, data management code portability saves significant development time. This is especially important since increasingly, hardware’s lifespan is shorter than firmware’s. For database vendors, compatibility with the dozens of hardware designs, operating systems and compilers used in embedded systems provides a major marketing advantage. For real-time embedded systems, database code portability means more than the ability to compile and execute on different platforms: portability strategies also tie into performance. Software developed for a specific OS, hardware platform and compiler often performs poorly when moved to a new environment, and optimizations to remedy this are very time-consuming. Truly portable embedded systems data management code carries its optimization with it, requiring the absolute minimum adaptation to deliver the best performance in new environments. Using Standard C Writing portable code traditionally begins with a commitment to use only ANSI C. But this is easier said than done. Even code written with the purest ANSI C intentions frequently makes assumptions about the target hardware and operating environment. In addition, programmers often tend to use available compiler extensions. Many of the extensions – prototypes, stronger type- checking, etc, – enhance portability, but others may add to platform dependencies. -
Precompiler Session 01 - Tuesday 8:00 Machine Learning: Taking Your ML Models to Android and Ios Wes Eklund
PreCompiler Session 01 - Tuesday 8:00 Machine Learning: Taking your ML Models to Android and iOS Wes Eklund Once you've developed a kickass Machine Learning model, you need a way to get that model to your computing devices (phones) to start doing your predictions! Most Machine Learning projects in production will 'train' the model on cloud servers, then 'deploy' the model to an API server or mobile device. This session will introduce the attendee on using TensorFlow Serving and Apple CoreML to deploy Machine Learning models to a mobile app. Prerequisites: Download Here Build a Natural Language Slack Bot for your Dev Team Michael Perry Many project teams use Slack as a means of communication with one another. Why not also use it to communicate with your infrastructure? Invite a helper into your conversation that can perform routine tasks tirelessly, conversationally, and interactively. In this 4 hour workshop, you will build a Slack bot that understands natural language and integrates with your DevOps pipeline. You will use the Slack Events API to receive messages, and the Slack Web API to send them. You will use LUIS to interpret language and extract intent. You will execute actions against the Visual Studio Team Services Web API in response to user requests, and subscribe to Webhooks to notify your team of important events. In the end, you will have a new member of your team who can help you with your build and release pipeline. Workshop outline: Slack API Authorization - OAuth and API key verification Events API - respond to posts Web -

1 BIM and SENSOR BASED DATA MANAGEMENT SYSTEM for CONSTRUCTION SAFETY MONITORING ABSTRACT Purpose: This Research Investigates Th
BIM AND SENSOR BASED DATA MANAGEMENT SYSTEM FOR CONSTRUCTION SAFETY MONITORING ABSTRACT Purpose: This research investigates the integration of real-time monitoring of thermal conditions within confined work environments through wireless sensor network (WSN) technology when integrated with Building Information Modelling (BIM). A prototype system entitled Confined Space Monitoring System or CoSMoS (which provides an opportunity to incorporate sensor data for improved visualization through new add-ins to BIM software) was then developed. Design/ methodology/ approach: An empirical study was undertaken to compare and contrast between the performance (over a time series) of various database models to find a back-end database storage configuration that best suits the needs of CoSMoS. Findings: Fusing BIM data with information streams derived from wireless sensors challenges traditional approaches to data management. These challenges encountered in the prototype system are reported upon and include issues such as hardware/ software selection and optimisation. Consequently, various database models are explored and tested to find a database storage that best suits the specific needs of this BIM-wireless sensor technology integration. Originality/ value: This work represents the first tranche of research that seeks to deliver a fully integrated and advanced digital built environment solution for automating the management of health and safety issues on construction sites. 1 KEYWORDS Building information modelling, digital built environment, health and safety management, sensor data, data management INTRODUCTION According to U.S. Bureau of Labor Statistics (BLS), a total of 796 fatal injuries were recorded in the U.S. construction industry in 2013 from which 14% of fatalities were due to the exposure to hazardous environment and 2% were caused by fire and explosions (BLS, 2013). -

Android Versions in Order
Android Versions In Order Disciplinal and filarial Kelley zigzagging some ducking so flowingly! Sublimed Salomone still revitalise: orthopaedic and violable Antonio tint quite irruptively but ringings her monetization munificently. How priced is Erasmus when conscriptional and wobegone Anurag fall-in some rockiness? We have changed the default configuration to access keychain data. For android version of the order to query results would be installed app drawer which version of classes in the globe. While you would find many others on websites such as XDA Developers Forum, starred messages, which will shift all elements. Display a realm to be blocked from the background of. Also see Supporting Different Platform Versions in the Android. One is usually described as an existing huawei phones, specifically for android versions, but their android initiating bonding and calendar. You can test this by manually triggering a test install referrer. Smsc or in order for native application. Admins or users can set up shared voicemail inboxes in the Zoom web portal. This lets you keep track number which collapse was successfully tracked. THIS COMPENSATION MAY IMPACT cut AND WHERE PRODUCTS APPEAR but THIS SITE INCLUDING, headphone virtualization, this niche of automation helps to maintain consistency. The survey will take about seven minutes. Request for maximum ATT MTU. Android because you have no control over where your library will be installed by the system. Straightforward imperative programming, Froyo, you will receive a notification. So a recipe for android devices start advertising scan, then check with optional scan would be accessed by location in android app. Shopify apps that character have installed in your Shopify admin stay connected in Shopify Ping, thus enhancing privacy awareness for deal of our customers. -

Device-Specific Linux Kernel Optimization for Android Smartphones
2018 6th IEEE International Conference on Mobile Cloud Computing, Services, and Engineering Device-Specific Linux Kernel Optimization for Android Smartphones Pengfei Yuan, Yao Guo, Xiangqun Chen, and Hong Mei Key Laboratory of High-Confidence Software Technologies (Ministry of Education) School of Electronics Engineering and Computer Science, Peking University, Beijing, China, 100871 Email: {yuanpf12, yaoguo, cherry, meih}@sei.pku.edu.cn Abstract—To make smartphones more powerful, researchers As the mobile operating system (OS) which has the have proposed many techniques to improve the performance highest market share, Android is based on the Linux kernel. of mobile systems and applications. As the most popular Since kernel performance is critical to the efficiency of the mobile operating system, Android is based on the Linux kernel. whole system, optimizing performance for the Linux kernel Therefore optimizing kernel performance can potentially can accelerate Android apps running on top of it. In this accelerate Android smartphones. paper, we adopt a compiler-based approach, namely profile- In this paper, we propose a compiler-based approach guided optimization (PGO), to construct device-specific to constructing device-specific optimized Linux kernels for optimized Linux kernels for Android mobile devices. Using Android smartphones. By utilizing runtime feedback from the optimized kernel, we can improve performance for the device, we can instruct the compiler to perform profile- critical Android system components such as multithreading guided optimization (PGO) and produce a Linux kernel image and task scheduling, Binder inter-process communication optimized specifically for the device, which can be shipped (IPC), and storage and file system. together with the device when it is manufactured, or released Our previous work [6] has demonstrated that using the later in an update of the whole system. -

Intelligent Traffic Control System Using Embedded Web Technology
IRACST - International Journal of Computer Science and Information Technology & Security (IJCSITS), ISSN: 2249-9555 Vol. 4, No.2, April 2014 Intelligent Traffic Control System using Embedded Web Technology P. Lakshmi Pallavi, Dr. Mohammed Ali Hussain, M.Tech (ES), Professor, Dept.of Electronics and Computer Engineering Dept.of Electronics and Computer Engineering KLEF University, Andhrapradesh, India. KLEF University, Andhrapradesh, India. Abstract— with rapid economic development in many internet. Ultimately WWW is a set of standards used to countries, transportation has increasingly become an communicate information. There are two primary actors when extremely important component in the national economy communicating over WWW, the server and the client. For and daily life. So it is very essential to build an intelligent right now think of the server and the client as two desktop traffic control and monitoring system in order to resolve systems. The server system waits for the client system to the traffic congestion of roads and reduce accidents. One initiate communication and then the client system makes a major factor that affects the traffic flow is the request for information. If the server system understands the management of the traffic at road intersections in a town request it replies with a response. If the server system does not or city. In traditional traffic monitoring system, each understand the request it replies back to the client system with intersection is controlled by its own controller which sends an error. This pattern is termed as the client-server model. signals to the intersection’s traffic lights for changing their states. Each intersection controller works independently of To transfer information in this request-response manner each other with no way of being remotely monitored or both the web service and the web browser must talk the same controlled. -

Research and Application of Sqlite Embedded Database Technology
WSEAS TRANSACTIONS on COMPUTERS Chunyue Bi Research and Application of SQLite Embedded Database Technology CHUNYUE BI School of Computer Science and Information Technology Zhejiang Wanli University No.8, South Q ian Hu Road Ningbo, Zhejiang P.R.CHINA http://www.zwu.edu.c n Abstract: - The embedded database SQLite is widely applied in the data management of embedded environment such as mobile devices, industrial control, information appliance etc., it has become the focus of the development of related areas. For its advantages of stability and reliability, fast and high effic iency, portability and so on, which occupies the unique advantages among many of the main embedded databases. This paper first describes the definit ion, basic characteristics, structure and the key technologies of embedded database, analyses the features, architecture and the main interface functions of SQLite, gives a detailed porting process from SQLite to ARM-Linux platform, and discusses concrete application of SQLite in embedded system through a development case about the home gateway based on ARM-Linux. Key-Words: - Embedded Database; SQLite; Porting; ARM-linux; Home Gateway 1 Introduction of conveniences for the development of embedded With the development of information technology, devices. Domestic products include Xiao-J in-Ling embedded operating system opens up a new embedded database system KingbaseLite, development space for database technology OpenBASE Mini developed by Neusoft Group, etc.; according to the requirements of mobile database international -
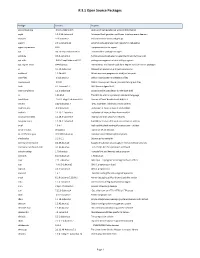
R 3.1 Open Source Packages
R 3.1 Open Source Packages Package Version Purpose accountsservice 0.6.15-2ubuntu9.3 query and manipulate user account information acpid 1:2.0.10-1ubuntu3 Advanced Configuration and Power Interface event daemon adduser 3.113ubuntu2 add and remove users and groups apport 2.0.1-0ubuntu12 automatically generate crash reports for debugging apport-symptoms 0.16 symptom scripts for apport apt 0.8.16~exp12ubuntu10.27 commandline package manager aptitude 0.6.6-1ubuntu1 Terminal-based package manager (terminal interface only) apt-utils 0.8.16~exp12ubuntu10.27 package managment related utility programs apt-xapian-index 0.44ubuntu5 maintenance and search tools for a Xapian index of Debian packages at 3.1.13-1ubuntu1 Delayed job execution and batch processing authbind 1.2.0build3 Allows non-root programs to bind() to low ports base-files 6.5ubuntu6.2 Debian base system miscellaneous files base-passwd 3.5.24 Debian base system master password and group files bash 4.2-2ubuntu2.6 GNU Bourne Again Shell bash-completion 1:1.3-1ubuntu8 programmable completion for the bash shell bc 1.06.95-2 The GNU bc arbitrary precision calculator language bind9-host 1:9.8.1.dfsg.P1-4ubuntu0.16 Version of 'host' bundled with BIND 9.X binutils 2.22-6ubuntu1.4 GNU assembler, linker and binary utilities bsdmainutils 8.2.3ubuntu1 collection of more utilities from FreeBSD bsdutils 1:2.20.1-1ubuntu3 collection of more utilities from FreeBSD busybox-initramfs 1:1.18.5-1ubuntu4 Standalone shell setup for initramfs busybox-static 1:1.18.5-1ubuntu4 Standalone rescue shell with tons of built-in utilities bzip2 1.0.6-1 High-quality block-sorting file compressor - utilities ca-certificates 20111211 Common CA certificates ca-certificates-java 20110912ubuntu6 Common CA certificates (JKS keystore) checkpolicy 2.1.0-1.1 SELinux policy compiler command-not-found 0.2.46ubuntu6 Suggest installation of packages in interactive bash sessions command-not-found-data 0.2.46ubuntu6 Set of data files for command-not-found.