Portability Techniques for Embedded Systems Data Management
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

JACSM No 1 2009
STORE: EMBEDDED PERSISTENT STORAGE FOR CLOJURE PROGRAMMING LANGUAGE Konrad Grzanek1 1IT Institute, Academy of Management, Lodz, Poland [email protected] Abstract Functional programming is the most popular declarative style of programming. Its lack of state leads to an increase of programmers' productivity and software robustness. Clojure is a very effective Lisp dialect, but it misses a solid embedded database implementation. A store is a proposed embedded database engine for Clojure that helps to deal with the problem of the inevitable state by mostly functional, minimalistic interface, abandoning SQL and tight integration with Clojure as a sole query and data-processing language. Key words: Functional programming, Lisp, Clojure, embedded database 1 Introduction Functional programming languages and functional programming style in general have been gaining a growing attention in the recent years. Lisp created by John McCarthy and specified in [8] is the oldest functional pro- gramming language. Some of its flavors (dialects, as some say [9]) are still in use today. Common Lisp was the first ANSI standardized Lisp dialect [13] and Common Lisp Object System (CLOS) was probably the first ANSI stan- dardized object oriented programming language [14]. Apart from its outstand- ing features as a Common Lisp subset. Various Lisps were used in artificial intelligence [11] and to some extent the language comes from AI labs and its ecosystem. Common Lisp was used as the language of choice by some AI tutors, like Peter Norvig (in [10]). But the whole family of languages address general problems in computer science, not only these in AI. John Backus argues [3] that the functional style is a real liberation from the traditional imperative languages and their problems. -

Zilog’S Ez80acclaim!™ Product Family, Which Offers On-Chip Flash Versions of Zilog’S Ez80® • 3.0–3.6 V Supply Voltage with 5 V Tolerant Inputs Processor Core
eZ80Acclaim!™ Flash Microcontrollers eZ80F91 Product Brief PB013502-0104 Product Block Diagram • I2C with independent clock rate generator • SPI with independent clock rate generator eZ80F91 MCU • Four Counter/Timers with prescalers supporting event counting, input capture, output compare, and 256 KB Flash + 32-Bit GPIO PWM modes 512 B Flash • Watch-Dog Timer with internal RC clocking 10/100 Mbps option 8KB SRAM Ethernet MAC • Real-time clock with on-chip 32kHz oscillator, 8KB Frame Buffer selectable 50/60Hz input, and separate RTC_VDD pin for battery backup. Infrared 2 • Glueless external memory interface with 4 Chip- Encoder/ 2 UART I C SPI Selects/Wait-State Generators and external WAIT Decoder input pin. Supports Intel and Motorola buses. Real-Time • JTAG Interface supporting emulation features 4 PRT WDT Clock • Low-power PLL and on-chip oscillator • Programmable-priority vectored interrupts, non- 4 CS JTAG ZDI PLL maskable interrupts, and interrupt controller +WSG • New DMA-like eZ80® CPU instructions • Power management features supporting HALT/ Features SLEEP modes and selective peripheral power- down controls The eZ80F91 microcontroller is a member of • 144-pin BGA or 144-pin LQFP package ZiLOG’s eZ80Acclaim!™ product family, which offers on-chip Flash versions of ZiLOG’s eZ80® • 3.0–3.6 V supply voltage with 5 V tolerant inputs processor core. The eZ80F91 offers the following • Operating Temperature Ranges: features: – Standard: 0ºC to +70ºC • 50MHz High-Performance eZ80® CPU – Extended: –40ºC to +105ºC • 256 KB Flash Program Memory plus extra 512B device configuration Flash memory General Description • 32 bits of General-Purpose I/O The eZ80F91 device is an industry first, featuring a • 16K B total on-chip high-speed SRAM: high-performance 8-bit microcontroller with an integrated 10/100 BaseT Ethernet Media Access – 8KB for general-purpose use controller (EMAC). -
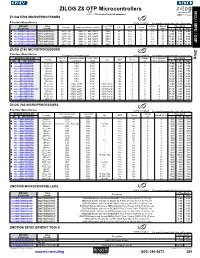
ZILOG Z8 OTP Microcontrollers MCU / MPU / DSP This Product Is Rohs Compliant
ZILOG Z8 OTP Microcontrollers DSP MPU / MCU / This product is RoHS compliant. ZILOG EZ80 MICROPROCESSORS ♦ Surface Mount Device For quantities greater than listed, call for quote. MOUSER Zilog Core CPU Voltage Speed Price Each Package Communications Controller I/O WDT Timers STOCK NO. Part No. Used (V) (MHz) 1 25 100 ♦ 692-EZ80L92AZ020EG EZ80L92AZ020EC LQFP-100 DMA, I2C, SPI, UART EZ80 24 Yes 6 3.3 20 9.29 9.10 8.63 ♦ 692-EZ80L92AZ020SG EZ80L92AZ020SC LQFP-100 DMA, I2C, SPI, UART EZ80 24 Yes 6 3.3 20 8.08 7.78 7.50 ♦ 692-EZ80L92AZ050EG EZ80L92AZ050EC LQFP-100 DMA, I2C, SPI, UART EZ80 24 Yes 6 3.3 50 10.21 9.75 9.49 ♦ 692-EZ80L92AZ050SG EZ80L92AZ050SC LQFP-100 DMA, I2C, SPI, UART EZ80 24 Yes 6 3.3 50 8.89 8.54 8.26 ♦ 692-EZ80190AZ050SG EZ80190AZ050SC LQFP-100 DMA, I2C, SPI, UART EZ80 32 Yes 6 3.3 50 12.03 11.59 11.17 ♦ 692-EZ80190AZ050EG EZ80190AZ050EC LQFP-100 DMA, I2C, SPI, UART EZ80 32 Yes 6 3.3 50 13.82 13.28 12.84 ZILOG Z180 MICROPROCESSORS Zilog ♦Surface Mount Device *See above for development tools. For quantities greater than listed, call for quote. MOUSER STOCK NO. Speed Communications Core CPU Voltage Development Price Each Package I/O WDT Timers Mfr. Mfr. Part No. (MHz) Controller Used (V) Tools Available 1 25 100 ♦ 692-Z8018006VSG PLCC-68 6 CPU Z180 - No 2 5 - 8.40 7.36 6.01 ♦ 692-Z8018006VEG PLCC-68 6 CPU Z180 - No 2 5 - 10.00 8.55 7.14 692-Z8018006PSG DIP-64 6 CPU Z180 - No 2 5 - 8.40 7.36 6.01 692-Z8018006PEG DIP-64 6 CPU Z180 - No 2 5 - 10.00 8.55 7.14 692-Z8018008PSG DIP-64 8 CPU Z180 - No 2 5 - 8.75 7.38 6.25 ♦ 692-Z8018008VSG -

Sentiment Analysis Using a Novel Human Computation Game
Sentiment Analysis Using a Novel Human Computation Game Claudiu-Cristian Musat THISONE Alireza Ghasemi Boi Faltings Artificial Intelligence Laboratory (LIA) Ecole Polytechnique Fed´ erale´ de Lausanne (EPFL) IN-Ecublens, 1015 Lausanne, Switzerland [email protected] Abstract data is obtained from people using human computa- tion platforms and games. We also prove that the In this paper, we propose a novel human com- method can provide not only labelled texts, but peo- putation game for sentiment analysis. Our ple also help by selecting sentiment-expressing fea- game aims at annotating sentiments of a col- tures that can generalize well. lection of text documents and simultaneously constructing a highly discriminative lexicon of Human computation is a newly emerging positive and negative phrases. paradigm. It tries to solve large-scale problems by Human computation games have been widely utilizing human knowledge and has proven useful used in recent years to acquire human knowl- in solving various problems (Von Ahn and Dabbish, edge and use it to solve problems which are 2004; Von Ahn, 2006; Von Ahn et al., 2006a). infeasible to solve by machine intelligence. To obtain high quality solution from human com- We package the problems of lexicon construc- putation, people should be motivated to make their tion and sentiment detection as a single hu- best effort. One way to incentivize people for sub- man computation game. We compare the re- mitting high-quality results is to package the prob- sults obtained by the game with that of other well-known sentiment detection approaches. lem at hand as a game and request people to play Obtained results are promising and show im- it. -

October 2011 Vol
NoSQL GREG BURD Hypervisors and Virtual Machines: Implementation Insights on the x86 Architecture DON REVELLE Conference Reports from the 2011 USENIX Annual Technical Conference, HotPar, and more OCTOBER 2011 VOL. 36, NO. 5 THE ADVANCED COMPUTING SYSTEMS ASSOCIATION THE ADVANCED COMPUTING SYSTEMS ASSOCIATION usenix_login_oct11_covers.indd 1 9.9.11 5:55 PM UPCOMING EVENTS 23rd ACM Symposium on Operating Systems 9th USENIX Symposium on Networked Systems Principles (SOSP 2011) Design and Implementation (NSDI ’12) SPONSORED BY ACM SIGOPS IN COOPERATION WITH USENIX SPONSORED BY USENIX IN COOPERATION WITH ACM SIGCOMM AND ACM SIGOPS October 23–26, 2011, Cascais, Portugal April 25–27, 2012, San Jose, CA http://sosp2011.gsd.inesc-id.pt http://www.usenix.org/nsdi12 ACM Symposium on Computer Human Interac- tion for Management of Information Technology 2012 USENIX Federated Conferences Week (CHIMIT 2011) June 12–15, 2012, Boston, MA, USA http://www.usenix.org/fcw12 SPONSORED BY ACM IN ASSOCIATION WITH USENIX December 4–5, 2011, Boston, MA 2012 USENIX Annual Technical Conference http://chimit.acm.org/ (USENIX ATC ’12) June 13–15, 2012, Boston, MA 25th Large Installation System Administration http://www.usenix.org/atc12 Conference (LISA ’11) Paper titles and abstracts due January 10, 2012 SPONSORED BY USENIX IN COOPERATION WITH LOPSA December 4–9, 2011, Boston, MA 21st USENIX Security Symposium http://www.usenix.org/lisa11 (USENIX Security ’12) August 6–10, 2012, Bellevue, WA ACM/IFIP/USENIX 12th International Middleware Conference (Middleware 2011) -

Data Acquisition
#147 October 2002 www.circuitcellar.com CIRCUIT CELLAR® THE MAGAZINE FOR COMPUTER APPLICATIONS DATA ACQUISITION 2-D Or Not 2-D Solar-Powered Robot The LED Alternative Mad DashWWW.GiURUMELE.Hi2.RO For Flash Cash Contest Primer 10> 7925274 75349 $4.95 U.S. ($5.95 Canada) WWW.GiURUMELE.Hi2.RO WWW.GiURUMELE.Hi2.RO Digital Oscilloscopes • 2 Channel Digital Oscilloscope DSO-2102S $525 • 100 MSa/s max single shot rate DSO-2102M $650 • 32K samples per channel Each includes Oscilloscope, • Advanced Triggering Probes, Interface Cable, Power • Only 9 oz and 6.3” x 3.75” x 1.25” Adapter, and software for • Small, Lightweight, and Portable Win95/98, WinNT, Win2000 • Parallel Port interface to PC and DOS. • Advanced Math options • FFT Spectrum Analyzer options Logic Analyzers • 40 to 160 channels • 24 Channel Logic Analyzer • up to 500 MSa/s • 100MSa/S max sample rate • Variable Threshold • Variable Threshold Voltage • 8 External Clocks • Large 128k Buffer • 16 Level Triggering • Small, Lightweight and Portable • up to 512KWWW.GiURUMELE.Hi2.RO samples/ch • Only 4 oz and 4.75” x 2.75” x 1” • Optional Parallel Interface • Parallel Port Interface to PC • Optional 100 MSa/s Pattern Generator • Trigger Out • Windows 95/98 Software LA4240-32K (200MHz, 40CH) $1350 LA4280-32K (200MHz, 80CH) $2000 LA2124-128K (100MSa/s, 24CH) LA4540-128K (500MHz, 40CH) $1900 Clips, Wires, Interface Cable, AC LA4580-128K (500MHz, 80CH) $2800 Adapter and Software $800 LA45160-128K (500MHz, 160CH) $7000 All prices include Pods and Software www.LinkIns4.com Link Instruments • 369 Passaic Ave • Suite 100 • Fairfield, NJ 07004 • (973) 808-8990 • Fax (973) 808-8786 WWW.GiURUMELE.Hi2.RO TASK MANAGER EDITORIAL DIRECTOR/FOUNDER CHIEF FINANCIAL OFFICER Be a Contender Steve Ciarcia Jeannette Ciarcia MANAGING EDITOR Jennifer Huber CUSTOMER SERVICE Elaine Johnston TECHNICAL EDITOR C.J. -

A Variability-Aware Module System
A Variability-Aware Module System Christian Kästner, Klaus Ostermann, and Sebastian Erdweg Philipps University Marburg, Germany Module systems enable a divide and conquer strategy to software develop- ment. To implement compile-time variability in software product lines, mod- ules can be composed in different combinations. However, this way variability dictates a dominant decomposition. Instead, we introduce a variability-aware module system that supports compile-time variability inside a module and its interface. This way, each module can be considered a product line that can be type checked in isolation. Variability can crosscut multiple modules. The module system breaks with the antimodular tradition of a global variabil- ity model in product-line development and provides a path toward software ecosystems and product lines of product lines developed in an open fashion. We discuss the design and implementation of such a module system on a core calculus and provide an implementation for C, which we use to type check the open source product line Busybox with 811 compile-time options. 1 Introduction A module system allows developers to decompose a large system into manageable sub- systems, which can be developed and checked in isolation [13]. A module hides informa- tion about internal implementations and exports only a well-defined and often machine- enforced interface. This enables an open-world development style, in which software can be composed from modular self-contained parts. The need for compile-time variability, for example in software product lines [6, 17, 10], challenges existing module systems. To tailor a software system, stakeholders may want to select from compile-time configuration options (or features) and derive a specific configuration (or variant, or product) of the system. -

C:\Andrzej\PDF\ABC Nagrywania P³yt CD\1 Strona.Cdr
IDZ DO PRZYK£ADOWY ROZDZIA£ SPIS TREFCI Wielka encyklopedia komputerów KATALOG KSI¥¯EK Autor: Alan Freedman KATALOG ONLINE T³umaczenie: Micha³ Dadan, Pawe³ Gonera, Pawe³ Koronkiewicz, Rados³aw Meryk, Piotr Pilch ZAMÓW DRUKOWANY KATALOG ISBN: 83-7361-136-3 Tytu³ orygina³u: ComputerDesktop Encyclopedia Format: B5, stron: 1118 TWÓJ KOSZYK DODAJ DO KOSZYKA Wspó³czesna informatyka to nie tylko komputery i oprogramowanie. To setki technologii, narzêdzi i urz¹dzeñ umo¿liwiaj¹cych wykorzystywanie komputerów CENNIK I INFORMACJE w ró¿nych dziedzinach ¿ycia, jak: poligrafia, projektowanie, tworzenie aplikacji, sieci komputerowe, gry, kinowe efekty specjalne i wiele innych. Rozwój technologii ZAMÓW INFORMACJE komputerowych, trwaj¹cy stosunkowo krótko, wniós³ do naszego ¿ycia wiele nowych O NOWOFCIACH mo¿liwoYci. „Wielka encyklopedia komputerów” to kompletne kompendium wiedzy na temat ZAMÓW CENNIK wspó³czesnej informatyki. Jest lektur¹ obowi¹zkow¹ dla ka¿dego, kto chce rozumieæ dynamiczny rozwój elektroniki i technologii informatycznych. Opisuje wszystkie zagadnienia zwi¹zane ze wspó³czesn¹ informatyk¹; przedstawia zarówno jej historiê, CZYTELNIA jak i trendy rozwoju. Zawiera informacje o firmach, których produkty zrewolucjonizowa³y FRAGMENTY KSI¥¯EK ONLINE wspó³czesny Ywiat, oraz opisy technologii, sprzêtu i oprogramowania. Ka¿dy, niezale¿nie od stopnia zaawansowania swojej wiedzy, znajdzie w niej wyczerpuj¹ce wyjaYnienia interesuj¹cych go terminów z ró¿nych bran¿ dzisiejszej informatyki. • Komunikacja pomiêdzy systemami informatycznymi i sieci komputerowe • Grafika komputerowa i technologie multimedialne • Internet, WWW, poczta elektroniczna, grupy dyskusyjne • Komputery osobiste — PC i Macintosh • Komputery typu mainframe i stacje robocze • Tworzenie oprogramowania i systemów komputerowych • Poligrafia i reklama • Komputerowe wspomaganie projektowania • Wirusy komputerowe Wydawnictwo Helion JeYli szukasz ]ród³a informacji o technologiach informatycznych, chcesz poznaæ ul. -

Natalia Nikolaevna Shusharina Maxin.Pmd
BIOSCIENCES BIOTECHNOLOGY RESEARCH ASIA, September 2016. Vol. 13(3), 1523-1536 Development of the Brain-computer Interface Based on the Biometric Control Channels and Multi-modal Feedback to Provide A Human with Neuro-electronic Systems and Exoskeleton Structures to Compensate the Motor Functions Natalia Nikolaevna Shusharina1, Evgeny Anatolyevich Bogdanov1, Stepan Aleksandrovich Botman1, Ekaterina Vladimirovna Silina2, Victor Aleksandrovich Stupin3 and Maksim Vladimirovich Patrushev1 1Immanuel Kant Baltic Federal University (IKBFU), Nevskogo Str., 14, Kaliningrad, 236041, Russia 2I.M. Sechenov First Moscow State Medical University (First MSMU), Trubetskaya str, 8, Moscow, 119991, Russia 3Pirogov´s Russian National Research Medical University (RNRMU), Ostrovityanova str, 1, Moscow, 117997, Russia http://dx.doi.org/10.13005/bbra/2295 (Received: 15 June 2016; accepted: 05 August 2016) The aim of this paper is to create a multi-functional neuro-device and to study the possibilities of long-term monitoring of several physiological parameters of an organism controlled by brain activity with transmitting the data to the exoskeleton. To achieve this goal, analytical review of modern scientific-and-technical, normative, technical, and medical literature involving scientific and technical problems has been performed; the research area has been chosen and justified, including the definition of optimal electrodes and their affixing to the body of the patient, the definition of the best suitable power source and its operation mode, the definition of the best suitable useful signal amplifiers, and a system of filtering off external noises. A neuro-device mock-up has been made for recognizing electrophysiological signals and transmitting them to the exoskeleton, also the software has been written. -

Installing Klocwork Insight
Installation and Upgrade Klocwork Insight 10.0 SR4 Document version 1.4 Klocwork Installation and Upgrade Version 10.0 PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Wed, 30 Apr 2014 20:28:47 EST Contents Articles Before you install 1 System requirements 1 Release Notes 10 About the Klocwork packages and components 23 Upgrading from a previous version 25 Upgrading from a previous version 25 Import your existing projects into a new projects root 26 Migrate your projects root directory 29 Installing the Klocwork Server package on Windows -- Upgrade only 34 Installing the Klocwork Server package on Unix -- Upgrade only 36 Installing the Klocwork Server package on Mac -- Upgrade only 38 Get a license 40 Getting a license 40 Installing the Server package 43 Installing Klocwork Insight 43 Installing the Klocwork Server package on Windows 44 Installing the Klocwork Server package on Unix 47 Installing the Klocwork Server package on Mac 50 Viewing and changing Klocwork server settings 52 Downloading and deploying the desktop analysis plug-ins 54 kwupdate 55 Installing a desktop analysis plug-in or command line utility 57 Installing a desktop analysis plug-in 57 Installing the Klocwork plug-in from the Eclipse update site 60 Running a custom installation for new or upgraded IDEs 61 Installing the Distributed Analysis package 62 Installing the Distributed Analysis package 62 Configuring and starting the Klocwork servers 65 Viewing and changing Klocwork server settings 65 -

The New Rabbit 3000М Microprocessor
3UHOLPLQDU\Ã6XPPDU\Ã 7KH1HZ5DEELW 0LFURSURFHVVRU Key New Features Low-EMI: typically <10 dB µV/m @ 3 m Ultra-low power modes 1.5–3.6 V (5 V tolerant I/O) 54 MHz clock speed 56+ digital I/O 6 serial ports supporting IrDA, SDLC/HDLC, Async, SPI Pulse capture and measurement Quadrature encoder inputs SHOWN ACTUAL SIZE (top) PWM outputs 16 x 16 x 1.5 mm Standard Features of Rabbit Processors The new Rabbit 3000™ is an extremely low-EMI microprocessor designed Glueless memory and I/O interface specifically for embedded control, communications, and Ethernet Direct support for 1 MB code/data space connectivity. The Rabbit 3000 shares its instruction set and conceptual (up to 6 MB with glueless interface) design with the proven Rabbit 2000™. Battery-backable real-time clock The Rabbit 3000 is fast—running at up to 54 MHz—and C-friendly, with Watchdog timer compact code and direct software support for 1 MB of code/data space. Remote boot/program Rabbit 3000 development tools include extensive support for Internet and network connectivity, with full source code for TCP/IP provided royalty free. Slave port interface The Rabbit 3000 operates at 3.3 V (with 5 V tolerant I/O) and boasts 6 serial ports with IrDA, 56+ digital I/O, quadrature encoder inputs, PWM Design Advantages outputs, and pulse capture and measurement capabilities. It also features a Extensive Ethernet/Internet support battery-backable real-time clock, glueless interfacing, and ultra-low power and royalty-free TCP/IP stack with modes. Its compact instruction set and high clock speeds give the Rabbit source and sample programs 3000 blazingly fast performance for math, logic, and I/O. -
Precompiler Session 01 - Tuesday 8:00 Machine Learning: Taking Your ML Models to Android and Ios Wes Eklund
PreCompiler Session 01 - Tuesday 8:00 Machine Learning: Taking your ML Models to Android and iOS Wes Eklund Once you've developed a kickass Machine Learning model, you need a way to get that model to your computing devices (phones) to start doing your predictions! Most Machine Learning projects in production will 'train' the model on cloud servers, then 'deploy' the model to an API server or mobile device. This session will introduce the attendee on using TensorFlow Serving and Apple CoreML to deploy Machine Learning models to a mobile app. Prerequisites: Download Here Build a Natural Language Slack Bot for your Dev Team Michael Perry Many project teams use Slack as a means of communication with one another. Why not also use it to communicate with your infrastructure? Invite a helper into your conversation that can perform routine tasks tirelessly, conversationally, and interactively. In this 4 hour workshop, you will build a Slack bot that understands natural language and integrates with your DevOps pipeline. You will use the Slack Events API to receive messages, and the Slack Web API to send them. You will use LUIS to interpret language and extract intent. You will execute actions against the Visual Studio Team Services Web API in response to user requests, and subscribe to Webhooks to notify your team of important events. In the end, you will have a new member of your team who can help you with your build and release pipeline. Workshop outline: Slack API Authorization - OAuth and API key verification Events API - respond to posts Web