Software Optimization Guide for the AMD Athlon 64 and AMD Opteron
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Owner's Manual
Dell Latitude 3330 Owner's Manual Regulatory Model: P18S Regulatory Type: P18S002 Notes, Cautions, and Warnings NOTE: A NOTE indicates important information that helps you make better use of your computer. CAUTION: A CAUTION indicates either potential damage to hardware or loss of data and tells you how to avoid the problem. WARNING: A WARNING indicates a potential for property damage, personal injury, or death. © 2013 Dell Inc. Trademarks used in this text: Dell™, the Dell logo, Dell Boomi™, Dell Precision™ , OptiPlex™, Latitude™, PowerEdge™, PowerVault™, PowerConnect™, OpenManage™, EqualLogic™, Compellent™, KACE™, FlexAddress™, Force10™ and Vostro™ are trademarks of Dell Inc. Intel®, Pentium®, Xeon®, Core® and Celeron® are registered trademarks of Intel Corporation in the U.S. and other countries. AMD® is a registered trademark and AMD Opteron™, AMD Phenom™ and AMD Sempron™ are trademarks of Advanced Micro Devices, Inc. Microsoft®, Windows®, Windows Server®, Internet Explorer®, MS-DOS®, Windows Vista® and Active Directory® are either trademarks or registered trademarks of Microsoft Corporation in the United States and/or other countries. Red Hat® and Red Hat® Enterprise Linux® are registered trademarks of Red Hat, Inc. in the United States and/or other countries. Novell® and SUSE® are registered trademarks of Novell Inc. in the United States and other countries. Oracle® is a registered trademark of Oracle Corporation and/or its affiliates. Citrix®, Xen®, XenServer® and XenMotion® are either registered trademarks or trademarks of Citrix Systems, Inc. in the United States and/or other countries. VMware®, Virtual SMP®, vMotion®, vCenter® and vSphere® are registered trademarks or trademarks of VMware, Inc. in the United States or other countries. -

Evaluation of AMD EPYC
Evaluation of AMD EPYC Chris Hollowell <[email protected]> HEPiX Fall 2018, PIC Spain What is EPYC? EPYC is a new line of x86_64 server CPUs from AMD based on their Zen microarchitecture Same microarchitecture used in their Ryzen desktop processors Released June 2017 First new high performance series of server CPUs offered by AMD since 2012 Last were Piledriver-based Opterons Steamroller Opteron products cancelled AMD had focused on low power server CPUs instead x86_64 Jaguar APUs ARM-based Opteron A CPUs Many vendors are now offering EPYC-based servers, including Dell, HP and Supermicro 2 How Does EPYC Differ From Skylake-SP? Intel’s Skylake-SP Xeon x86_64 server CPU line also released in 2017 Both Skylake-SP and EPYC CPU dies manufactured using 14 nm process Skylake-SP introduced AVX512 vector instruction support in Xeon AVX512 not available in EPYC HS06 official GCC compilation options exclude autovectorization Stock SL6/7 GCC doesn’t support AVX512 Support added in GCC 4.9+ Not heavily used (yet) in HEP/NP offline computing Both have models supporting 2666 MHz DDR4 memory Skylake-SP 6 memory channels per processor 3 TB (2-socket system, extended memory models) EPYC 8 memory channels per processor 4 TB (2-socket system) 3 How Does EPYC Differ From Skylake (Cont)? Some Skylake-SP processors include built in Omnipath networking, or FPGA coprocessors Not available in EPYC Both Skylake-SP and EPYC have SMT (HT) support 2 logical cores per physical core (absent in some Xeon Bronze models) Maximum core count (per socket) Skylake-SP – 28 physical / 56 logical (Xeon Platinum 8180M) EPYC – 32 physical / 64 logical (EPYC 7601) Maximum socket count Skylake-SP – 8 (Xeon Platinum) EPYC – 2 Processor Inteconnect Skylake-SP – UltraPath Interconnect (UPI) EYPC – Infinity Fabric (IF) PCIe lanes (2-socket system) Skylake-SP – 96 EPYC – 128 (some used by SoC functionality) Same number available in single socket configuration 4 EPYC: MCM/SoC Design EPYC utilizes an SoC design Many functions normally found in motherboard chipset on the CPU SATA controllers USB controllers etc. -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -

The Wysiwyg and Vivien Hardware Guide
The wysiwyg and Vivien Hardware Guide [Updated June 5, 2019] This guide describes the principles of selecting hardware components for a wysiwyg or Vivien workstation, and it is meant to be a guideline for choosing the right hardware for your intended use of the software. As such, actual hardware models are not specified for most components, but based on the information provided below, you will be able to decide on these yourself. Once you have, if you wish to confirm the components you selected, our Technical Support Department will be happy to look over your list; please see the end of this article for information on how to get in touch with us. Before discussing the various components and the criteria for selecting them, there are four important things to note. It strongly recommended that you read all this information and follow the advice before considering the purchase of new hardware. 1. Geometry must always be properly optimized, in all files, regardless of their complexity. Even the best/fastest/most expensive hardware will not be able to properly- handle a file that is not optimized and therefore contains inefficient geometry. If you haven’t done so already, please read through this thread on our Forum, in order to learn how to optimize your files. The key to understanding the optimization principles described here lies with the articles mentioned in the first paragraph of the first message, “Part 1” and “Part 2”; please ensure that you also click those links and read the information they reveal. 2. Even in an optimized file performance can be poor if your video card driver is out-of-date and/or your video card’s settings and/or Shaded View options are inappropriate. -

Solaris 10 OS on AMD Opteron Processor-Based Systems
Solaris™ 10 OS on AMD Opteron™ Processor-based Systems < A powerful combination for your business Sun and AMD take x64 computing to a new level with the breakthrough performance of AMD Opteron™ processor-based systems combined with the Solaris™ 10 OS — the most advanced operating system on the planet. By combining the best of free and open source software with the most powerful industry-standard platforms, customers can take advantage of the most robust and secure, yet economical Web, database, and application servers. A unique partnership Price/performance Coengineering and technology collaboration World-record performance Sun and AMD software engineers work jointly Leveraging more than 20 years of Symmetric on a range of codevelopment efforts including Multiprocessing (SMP) expertise, Sun has future development of HyperTransport, virtu- tuned and optimized Solaris 10 for the AMD alization, fault management, compiler perform- Opteron platform to deliver exceptional ance, and other ways Solaris may take advantage performance and near-linear scalability. For Highlights of the AMD Opteron architecture. Solaris 10 enterprises with demanding compute, net- • Supports the latest generation 5/08 also includes support for the latest gener- work, and Web applications, the combination of AMD x64 processors ation of AMD x64 processors and UltraSPARC of Solaris 10 and AMD Opteron processor-based • PowerNow! enhancements CMT systems. systems is often an ideal fit. Dozens of perform- provide additional power man- ance and price/performance world record agement capabilities Growing the Solaris™ OS ecosystem for AMD64 benchmarks demonstrate this exceptional • Remote client display virtualiztion Sun and AMD are working together with key combination. Solaris 10 has set more than • Solaris Trusted Extensions optimi- target ISVs, system builders, and independent 50 world records, employing various industry- zations for better interoperability hardware vendors (IHVs) to fuel growth of the standard benchmarks or workload scenarios and security Solaris 10 ecosystem around AMD64. -

AMD's Early Processor Lines, up to the Hammer Family (Families K8
AMD’s early processor lines, up to the Hammer Family (Families K8 - K10.5h) Dezső Sima October 2018 (Ver. 1.1) Sima Dezső, 2018 AMD’s early processor lines, up to the Hammer Family (Families K8 - K10.5h) • 1. Introduction to AMD’s processor families • 2. AMD’s 32-bit x86 families • 3. Migration of 32-bit ISAs and microarchitectures to 64-bit • 4. Overview of AMD’s K8 – K10.5 (Hammer-based) families • 5. The K8 (Hammer) family • 6. The K10 Barcelona family • 7. The K10.5 Shanghai family • 8. The K10.5 Istambul family • 9. The K10.5-based Magny-Course/Lisbon family • 10. References 1. Introduction to AMD’s processor families 1. Introduction to AMD’s processor families (1) 1. Introduction to AMD’s processor families AMD’s early x86 processor history [1] AMD’s own processors Second sourced processors 1. Introduction to AMD’s processor families (2) Evolution of AMD’s early processors [2] 1. Introduction to AMD’s processor families (3) Historical remarks 1) Beyond x86 processors AMD also designed and marketed two embedded processor families; • the 2900 family of bipolar, 4-bit slice microprocessors (1975-?) used in a number of processors, such as particular DEC 11 family models, and • the 29000 family (29K family) of CMOS, 32-bit embedded microcontrollers (1987-95). In late 1995 AMD cancelled their 29K family development and transferred the related design team to the firm’s K5 effort, in order to focus on x86 processors [3]. 2) Initially, AMD designed the Am386/486 processors that were clones of Intel’s processors. -

AMD Opteron™ 4000 Series Platform
AMD Opteron™ 4000 Series Platform The world’s lowest power x86 cloud processor1 just got more efficient The AMD Opteron™ 4200 Series processor — the world’s lowest power processor1,3 at fewer than 5 watts per core — while designed for challenging workloads still delivers a performance punch. AMD Opteron™ 4000 Series Platform Product Comparison ™ AMD Opteron 4100 ™ Series Processor AMD Opteron 4200 Series Processor Features Features Benefits 33% increase in core count packed with plenty of processing Processor Cores 4 and 6 core options 6 and 8 core options performance in a smaller2, more efficient3 8-core design while maintaining the same power/thermal ranges L2: 512 K/core L2: 2 MB shared by 2 cores Processor Cache L3: 6 MB L3: 8 MB Twice the L2 cache per core over the previous generation 2 memory channels supporting R/U 2 memory channels supporting ULV- 20% faster memory and new 1.25V ULV memory offering; Memory DDR3 and LV R/U DDR3 up to 1333MHz DIMM, UDIMM, RDIMM up to 1600MHz high memory bandwidth EE/Std/HE EE/Std/HE HE/Std/SE power options to match workload performance Power and power requirements HyperTransport™ Technology 2X HT3 Links (between CPUs) 2X HT3 Links (between CPUs) Helps improve overall system balance and scalability for scale-out (HT) Up to 25.6 GB/s per link @ 6.4 GT/s Up to 25.6 GB/s per link @ 6.4 GT/s computing environments like HPC, database and web serving Up to 8 cores, new features include Up to 20% greater throughput4 expected, 33% more cores5; FMAC in the Performance Up to 6 cores AMD Turbo CORE technology, FMAC, Flex FP help drive more performance by executing FMA4 instructions that Flex FP and an all new architecture execute complex calculations in half the cycles as the competition Features include enhanced APML (in APML-enabled platforms), AMD New power-saving features like C6 C6 Power State shuts down power to idle cores. -

Cache Hierarchy and Memory Subsystem of the Amd Opteron Processor
[3B2-14] mmi2010020016.3d 30/3/010 12:7 Page 16 .......................................................................................................................................................................................................................... CACHE HIERARCHY AND MEMORY SUBSYSTEM OF THE AMD OPTERON PROCESSOR .......................................................................................................................................................................................................................... THE 12-CORE AMD OPTERON PROCESSOR, CODE-NAMED ‘‘MAGNY COURS,’’ COMBINES ADVANCES IN SILICON, PACKAGING, INTERCONNECT, CACHE COHERENCE PROTOCOL, AND SERVER ARCHITECTURE TO INCREASE THE COMPUTE DENSITY OF HIGH-VOLUME COMMODITY 2P/4P BLADE SERVERS WHILE OPERATING WITHIN THE SAME POWER ENVELOPE AS EARLIER-GENERATION AMD OPTERON PROCESSORS.AKEY ENABLING FEATURE, THE PROBE FILTER, REDUCES BOTH THE BANDWIDTH OVERHEAD OF TRADITIONAL BROADCAST-BASED COHERENCE AND MEMORY LATENCY. ......Recent trends point to high and and latency sensitive, which favors the use growing demand for increased compute den- of high-performance cores. In fact, a com- sity in large-scale data centers. Many popular mon use of chip multiprocessor (CMP) serv- server workloads exhibit abundant process- ers is simply running multiple independent and thread-level parallelism, so benefit di- instances of single-threaded applications in rectly from additional cores. One approach multiprogrammed mode. In addition, for Pat Conway to exploiting -
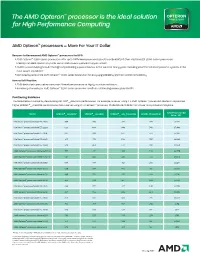
The AMD Opteron™ Processor Is the Ideal Solution for High Performance Computing
The AMD Opteron™ processor is the ideal solution for High Performance Computing AMD Opteron™ processors = More For Your IT Dollar Reasons to Recommend AMD Opteron™ processors for HPC: • AMD Opteron™ 6200 Series processors offer up to 34% lower processor price/theoretical GFLOP than Intel Xeon E5-2600 Series processors. Making it an ideal solution for public sector and university research opportunities.1 • AMD has been helping to build the highest performing supercomputers in the world for many years, including 24 of the 100 most powerful systems in the most recent Top 500 list.2 • Consistency across the AMD Opteron™ 6000 series processors for easy upgradeability and backwards compatibility How to Sell/Position: • AMD dedicated cores deliver consistent thread performance for highly scalable workloads. • 4 memory channels per AMD Opteron™ 6200 Series processor results in outstanding memory bandwidth. Positioning Guidance The table below is sorted by descending SPECint®_rate2006 performance. For example, a server using 2 x AMD Opteron™ processors Model 6274 provides higher SPECint®_rate2006 performance than a server using 2 x Intel Xeon™ processor Model E5-2640 AND has a lower total processor 1kU price. ® 3 ® ® Total Processor 1kU Model SPECint _ rate2006 SPECfp _ rate2006 SPECint _ rate_base2006 GFLOPs (Theoretical) Price - 2P* Intel Xeon™ processor Model E5-2690 705 510 671 371 $4,114 Intel Xeon™ processor Model E5-2680 666 494 640 346 $3,446 Intel Xeon™ processor Model E5-2670 647 486 622 333 $3,104 Intel Xeon™ processor Model E5-2665 -

Modern Computer Architecture and Organization
Modern Computer Architecture Ledin Jim Organization and Architecture Computer Modern and Organization Modern Computer Are you a software developer, systems designer, The book will teach you the fundamentals or computer architecture student looking for of computer systems including transistors, a methodical introduction to digital device logic gates, sequential logic, and instruction Architecture and architectures but overwhelmed by their operations. You will learn details of modern complexity? This book will help you to learn processor architectures and instruction sets how modern computer systems work, from the including x86, x64, ARM, and RISC-V. You will lowest level of transistor switching to the macro see how to implement a RISC-V processor in view of collaborating multiprocessor servers. a low-cost FPGA board and how to write a Organization You'll gain unique insights into the internal quantum computing program and run it on an behavior of processors that execute the code actual quantum computer. By the end of this developed in high-level languages and enable book, you will have a thorough understanding you to design more effi cient and scalable of modern processor and computer software systems. architectures and the future directions these architectures are likely to take. Learn x86, ARM, and RISC-V architectures and the design of smartphones, PCs, and cloud servers Things you will learn: • Get to grips with transistor technology • Understand the purpose and operation and digital circuit principles of the supervisor mode • Discover -
![CPU History [Tualatin] [Banias] [Dothan] [Yonah (Jonah)] [Conroe] [Allendale] [Yorkfield XE] Intel Created Pentium (From Quad-Core CPU](https://docslib.b-cdn.net/cover/8530/cpu-history-tualatin-banias-dothan-yonah-jonah-conroe-allendale-yorkfield-xe-intel-created-pentium-from-quad-core-cpu-3058530.webp)
CPU History [Tualatin] [Banias] [Dothan] [Yonah (Jonah)] [Conroe] [Allendale] [Yorkfield XE] Intel Created Pentium (From Quad-Core CPU
2nd Generation 4th Generation 5th Generation 6th Generation 7th Generation 3rd Generation Intel Pentium III-S Intel Pentium-M (Centrino) Intel Pentium-M (Centrino) Intel Core Duo (Viiv) Intel Core 2 Duo (Viiv)/Xeon Intel Core 2 Duo (Viiv) Intel Core 2 Extreme (Viiv) Intel had the first consumer CPU History [Tualatin] [Banias] [Dothan] [Yonah (Jonah)] [Conroe] [Allendale] [Yorkfield XE] Intel created Pentium (from quad-core CPU. x86/CISC Microprocessors Greek penta which means (2001) (2003) (2004) (2006) (2006) (2007) (2007) 1st Generation Intel Pentium II Xeon Intel Pentium III Xeon Centrino is not a CPU; it is Begin Core five) to distinguish the Intel [P6] [Tanner] a mobile Intel CPU paired nomeclature brand from clones. Names (1998) (1999) Intel Celeron with an Intel Wi-Fi adapter. Intel Celeron Intel Core Solo can be copyrighted, product [Tualeron] [Dothan-1024] Intel Xeon LV Intel Celeron Intel Celeron [Yonah] ID's cannot. (2001) (2004) [Sossaman] [Banias-512] [Shelton (Banias-0)] (2006) (2006) Intel Core 2 Duo Intel Core 2 Extreme Intel Celeron Intel 80386 DX Intel 80486 DX Intel Pentium Intel Pentium Pro Intel Pentium II Intel Pentium II Intel Pentium III Intel Pentium III Intel Pentium 4 Intel Pentium 4 (2004) (2004) Intel Pentium 4 Intel Pentium 4 Intel 4004 Intel 8008 Intel 8086 Intel 80286 [Conroe XE] [Conroe-L] [P3] [P4] [P5/P54/P54C] [P6] [Klamath] [Deuschutes] [Katmai] [Coppermine] [Williamette] [Northwood] [Prescott] [Cedar Mill] END-OF-LINE (Centrino Duo) (1971) (1972) (1978) (1982) (2006) (2007) (1985) (1989) (1993) (1995) (1997) (1998) (1999) (1999) (2000) (2002) (2004) (2006) [Merom] (2006) Yonah is Hebrew for Jonah. -

AMD Opteron™ and Intel® Xeon® X86 Processors in Industry-Standard Servers
AMD Opteron™ and Intel® Xeon® x86 processors in industry-standard servers Technology brief, 2nd edition Introduction ......................................................................................................................................... 2 Processor naming conventions ............................................................................................................... 2 AMD Opteron processors ................................................................................................................. 2 Intel Xeon processors ........................................................................................................................ 2 Microarchitecture ................................................................................................................................. 3 Intel Microarchitecture Nehalem ........................................................................................................ 3 AMD Opteron microarchitecture ........................................................................................................ 6 Instruction set architecture ..................................................................................................................... 7 32-bit operations.............................................................................................................................. 7 64-bit extensions .............................................................................................................................. 8 I/O architecture