Sun Enterprise 10000 System Overview Manual
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Gigaplane-XB: Extending the Ultra Enterprise Family
Gigaplane-XB: Extending the Ultra Enterprise Family Alan Charlesworth ([email protected]), Andy Phelps, Ricki Williams, Gary Gilbert Sun Microsystems, Inc. Abstract The Gigaplane-XB interconnect of the Starfire system extends the range of Sun’s Ultra Enterprise SMP server family by 4x. It uses multi-level address and data routers to provide 167 million global snoops per second, and 10,667 MBps of uniform-memory-access band- width. The use of point-to-point routers allows the system to be dynamically reconfigured into multiple hardware-protected operating system domains, with hot-swappable boards. Comparisons are made with the bus-based technology of the smaller family members. 1. Introduction Table 1 compares the memory-port architectures of cur- rent microprocessors. A combination of a 16-byte wide When a new processor debuts, we hear mostly about its data path, a 100 MHz system clock, and separate address SPECint95 and SPECfp95 performance. It is probably and data paths has made Sun’s Ultra Port Architecture more important to know how well a processor’s power is (UPA) among the highest-bandwidth memory ports. The balanced its memory bandwidth and latency. From a sys- UPA is used across all Sun’s UltraSPARC systems: from tem designer’s perspective, the main reason to have an desktop workstations to the 64-processor Starfire instruction set architecture is to get the opportunity to (UltraEnterprise/High Performance Computing 10000) engineer into the processor chip a good interconnect server. architecture. Table 1. Memory-port characteristics. Max Data Separate Data Peak data Instruction set Interconnect Current CPU Port width address duty bandwidth architecture architecture model MHz (bytes) and data? factor (MBps) SPARC UPA [9] UltraSPARC-II 100 16 Yes 100% 1,600 Alpha See [3] 21164 88 16 Yes 100% 1,408 Mips Avalanche [18] R10000 100 8 No 84% 840 PA-RISC Runway [1] PA-8000 120 8 No 80% 768 PowerPC See [2] PPC 604 67 8 Yes 100% 533 Pentium Pro/II See [5] Pentium Pro/II 67 8 Yes 100% 533 2. -

Allgemeines Abkürzungsverzeichnis
Allgemeines Abkürzungsverzeichnis L. -

Sun Fire E2900 Server
Sun FireTM E2900 Server Just the Facts February 2005 SunWin token 401325 Sun Confidential – Internal Use Only Just The Facts Sun Fire E2900 Server Copyrights ©2005 Sun Microsystems, Inc. All Rights Reserved. Sun, Sun Microsystems, the Sun logo, Sun Fire, Netra, Ultra, UltraComputing, Sun Enterprise, Sun Enterprise Ultra, Starfire, Solaris, Sun WebServer, OpenBoot, Solaris Web Start Wizards, Solstice, Solstice AdminSuite, Solaris Management Console, SEAM, SunScreen, Solstice DiskSuite, Solstice Backup, Sun StorEdge, Sun StorEdge LibMON, Solstice Site Manager, Solstice Domain Manager, Solaris Resource Manager, ShowMe, ShowMe How, SunVTS, Solstice Enterprise Agents, Solstice Enterprise Manager, Java, ShowMe TV, Solstice TMNscript, SunLink, Solstice SunNet Manager, Solstice Cooperative Consoles, Solstice TMNscript Toolkit, Solstice TMNscript Runtime, SunScreen EFS, PGX, PGX32, SunSpectrum, SunSpectrum Platinum, SunSpectrum Gold, SunSpectrum Silver, SunSpectrum Bronze, SunStart, SunVIP, SunSolve, and SunSolve EarlyNotifier are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the United States and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. UNIX is a registered trademark in the United States and other countries, exclusively licensed through X/Open Company, Ltd. All other product or service names mentioned -

Sun Ultratm 5 Workstation Just the Facts
Sun UltraTM 5 Workstation Just the Facts Copyrights 1999 Sun Microsystems, Inc. All Rights Reserved. Sun, Sun Microsystems, the Sun logo, Ultra, PGX, PGX24, Solaris, Sun Enterprise, SunClient, UltraComputing, Catalyst, SunPCi, OpenWindows, PGX32, VIS, Java, JDK, XGL, XIL, Java 3D, SunVTS, ShowMe, ShowMe TV, SunForum, Java WorkShop, Java Studio, AnswerBook, AnswerBook2, Sun Enterprise SyMON, Solstice, Solstice AutoClient, ShowMe How, SunCD, SunCD 2Plus, Sun StorEdge, SunButtons, SunDials, SunMicrophone, SunFDDI, SunLink, SunHSI, SunATM, SLC, ELC, IPC, IPX, SunSpectrum, JavaStation, SunSpectrum Platinum, SunSpectrum Gold, SunSpectrum Silver, SunSpectrum Bronze, SunVIP, SunSolve, and SunSolve EarlyNotifier are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the United States and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the United States and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. UNIX is a registered trademark in the United States and other countries, exclusively licensed through X/Open Company, Ltd. OpenGL is a registered trademark of Silicon Graphics, Inc. Display PostScript and PostScript are trademarks of Adobe Systems, Incorporated, which may be registered in certain jurisdictions. Netscape is a trademark of Netscape Communications Corporation. DLT is claimed as a trademark of Quantum Corporation in the United States and other countries. Just the Facts May 1999 Positioning The Sun UltraTM 5 Workstation Figure 1. The Ultra 5 workstation The Sun UltraTM 5 workstation is an entry-level workstation based upon the 333- and 360-MHz UltraSPARCTM-IIi processors. The Ultra 5 is Sun’s lowest-priced workstation, designed to meet the needs of price-sensitive and volume-purchase customers in the personal workstation market without sacrificing performance. -

Sun Ultratm 2 Workstation Just the Facts
Sun UltraTM 2 Workstation Just the Facts Copyrights 1999 Sun Microsystems, Inc. All Rights Reserved. Sun, Sun Microsystems, the Sun Logo, Ultra, SunFastEthernet, Sun Enterprise, TurboGX, TurboGXplus, Solaris, VIS, SunATM, SunCD, XIL, XGL, Java, Java 3D, JDK, S24, OpenWindows, Sun StorEdge, SunISDN, SunSwift, SunTRI/S, SunHSI/S, SunFastEthernet, SunFDDI, SunPC, NFS, SunVideo, SunButtons SunDials, UltraServer, IPX, IPC, SLC, ELC, Sun-3, Sun386i, SunSpectrum, SunSpectrum Platinum, SunSpectrum Gold, SunSpectrum Silver, SunSpectrum Bronze, SunVIP, SunSolve, and SunSolve EarlyNotifier are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the United States and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the United States and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. OpenGL is a registered trademark of Silicon Graphics, Inc. UNIX is a registered trademark in the United States and other countries, exclusively licensed through X/Open Company, Ltd. Display PostScript and PostScript are trademarks of Adobe Systems, Incorporated. DLT is claimed as a trademark of Quantum Corporation in the United States and other countries. Just the Facts May 1999 Sun Ultra 2 Workstation Figure 1. The Sun UltraTM 2 workstation Sun Ultra 2 Workstation Scalable Computing Power for the Desktop Sun UltraTM 2 workstations are designed for the technical users who require high performance and multiprocessing (MP) capability. The Sun UltraTM 2 desktop series combines the power of multiprocessing with high-bandwidth networking, high-performance graphics, and exceptional application performance in a compact desktop package. Users of MP-ready and multithreaded applications will benefit greatly from the performance of the Sun Ultra 2 dual-processor capability. -
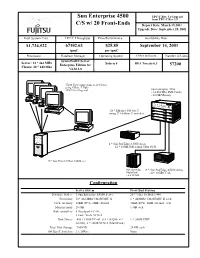
Sun Enterprise 4500 C/S W
Sun Enterprise 4500 TPC-C Rev. 5.0 Upgrade from TPC-C Rev 3.5 C/S w/ 20 Front-Ends Report Date: March 19,2001 Upgrade Date: September 25, 2001 Total System Cost TPC-C Throughput Price/Performance Availability Date $1,734,522 67102.63 $25.85 September 14, 2001 tpmC per tpmC Processors Database Manager Operating System Other Software Number of Users SymfoWARE Server Server: 14 * 464 MHz Solaris 8 BEA Tuxedo 6.3 Enterprise Edition for 57200 Clients: 20 * 440 Mhz VLM 3.0 57200 User Connections to 20 Clients using 10Base T Hubs 1000 Users/Segment Sun Enterprise 4500 - 14 464 Mhz 8Mb Cache - 28 GB Memory 20 * Ethernet 100 baseT using 2* 100Base T switches 4 * Sun StorEdge A1000 Array - 12 * 18GB Differential Ultra-SCSI 20 * Sun Ultra 10 Model 440Server Sun StorEdge 18 * Sun StorEdge A5200 Array MultiPack - 22* 18GB FCAL - 6 x 18 GB Configuration Server System Front End Systems Database Nodes: 1 Sun Enterprise E4500 Server 20 * Ultra 10 Model 440 Processors 14* 464 MHz UltraSPARC II 1 * 440MHz UltraSPARC II each Cache memory 32KB (D+I), 8MB external 32KB (D+I), 2MB external, each Main memory 28 GB 1 GB each Disk controllers 3 Dualport FC-AL, 2 Fast/Wide SCSI-2 Disk Drives 450 * 18GB FC-AL (18 * A5200, 4 * 1 * 20GB EIDE A1000), 6 * 18GB SCSI-2 (MultiPack) Total Disk Storage 7560GB 20 GB each 100 BaseT Switches 3 x 24Port None Sun Enterprise 4500 TPC-C Rev. 5.0 Upgrade from TPC-C Rev. 3.5 C/S w/ 20 Front-Ends Report Date: March 24, 2001 Upgrade Date: September 25, 2001 Pricing Summary Description Part Number Source Unit Price Qty Ext Price 3 Yr. -

Ultra 80 Workstations
Sun UltraTM 80 Workstation Just the Facts Copyrights 2001 Sun Microsystems, Inc. All Rights Reserved. Sun, Sun Microsystems, the Sun logo, Ultra, PGX, PGX32, Sun Workstation, Sun Enterprise, Starfire, Solaris, UltraComputing, VIS, Java, Java 3D, SunCD, Sun StorEdge, Solstice, Solstice AdminTools, SunVTS, Solstice Enterprise Agents, ShowMe, ShowMe How, ShowMe TV, iPlanet, SunPCi, StarOffice, Solaris Resource Manager, TurboGX, TurboGXplus, S24, OpenWindows, SunCD 2Plus, Netra, SunButtons, SunDials, Sun Quad FastEthernet, SunFDDI, SunLink, SunATM, SunVideo, SunVideo Plus, SunCamera, SunMicrophone, SunForum, SunSpectrum, SunSpectrum Platinum, SunSpectrum Gold, SunSpectrum Silver, SunSpectrum Bronze, SunStart, SunSolve, SunSolve EarlyNotifier, and SunClient are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the United States and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the United States and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. UNIX is a registered trademark in the United States and in other countries, exclusively licensed through X/Open Company, Ltd. OpenGL is a trademark of Silicon Graphics, Inc., which may be registered in certain jurisdictions. Netscape is a trademark of Netscape Communications Corporation. PostScript and Display PostScript are trademarks of Adobe Systems, Inc., which may be registered in certain jurisdictions. Last -

Cluster Platform 4500/3 User's Guide
Cluster Platform 4500/3 User’s Guide A product from the SunTone™ Platforms portfolio Sun Microsystems, Inc. 901 San Antonio Road Palo Alto, CA 94303-4900 U.S.A. 650-960-1300 Part No. 816-0445-11 July 2001, Revision A Send comments about this document to: [email protected] Copyright 2001 Sun Microsystems, Inc., 901 San Antonio Road, Palo Alto, CA 94303-4900 U.S.A. All rights reserved. This product or document is distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, AnswerBook2, docs.sun.com, Solstice DiskSuite, OpenBoot, Sun Enterprise, BluePrints, JumpStart, Sun StorEdge, Netra, Solaris, and SunTone are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. Netscape Navigator is a trademark or registered trademark of Netscape Communications Corporation. Oracle is a registered trademark of Oracle Corporation. -

The Soa Platform Guide: Evaluate, Extend, Embrace
THE SOA PLATFORM GUIDE: EVALUATE, EXTEND, EMBRACE White Paper February 2006 2 Table of Contents Sun Microsystems, Inc. Table of Contents Executive Summary . 3 Service Oriented Architecture — Introduction . 4 Definition of SOA . 5 SOA Characteristics . 6 Standards . 6 Loose Coupling . 6 Accessibility and Reuse . 6 SOA Governance . 6 Service Descriptions . 7 An SOA Platform . 8 SOA Platform Design Centers . 8 Service Composition . 9 Service Control . 11 Service Delivery . 12 Service Access . 13 Composite Application Platform . 14 Sun SOA . 16 SOA and Data Center Architecture . 17 Summary . 18 Product Information . 18 For More Information . 19 3 Executive Summary Sun Microsystems, Inc. Chapter 1 Executive Summary In today’s world of shortened product cycles and heightened competition, IT’s task is to create a flexible environment; to ensure that the enterprise is strategically positioned to foster innovation; to respond to changing needs faster than ever before by reducing time to market for new services; and to drive down the cost of integration and total cost of ownership (TCO). This flexibility is made possible through the use of a Service-Oriented Architecture (SOA) — a design paradigm based on a loosely coupled collection of reusable services. The SOA enables agility through aligning the business and IT, providing business processes that embody core capabilities to employees, customers, suppliers, and partners. The set of infrastructure tools employed by IT to build, configure, deploy, monitor, and manage services is called the SOA platform. As technologies that facilitate service communication and orchestration are standardized, enterprises are able to fully realize the benefits of SOA without fear of vendor lock-in. -

Avaya Call Management System Sun Enterprise 3500 Computer Hardware Installation, Maintenance, and Troubleshooting
Avaya Call Management System Sun Enterprise 3500 Computer Hardware Installation, Maintenance, and Troubleshooting 585-215-873 Issue 6.0 May 2005 © 2005 Avaya Inc. Your responsibility for your company's telecommunications All Rights Reserved. security The final responsibility for securing both this system and its networked Notice equipment rests with you, an Avaya customer's system administrator, While reasonable efforts were made to ensure that the information in this your telecommunications peers, and your managers. Base the fulfillment document was complete and accurate at the time of printing, Avaya Inc. of your responsibility on acquired knowledge and resources from a can assume no liability for any errors. Changes and corrections to the variety of sources, including, but not limited to: information in this document may be incorporated in future releases. • Installation documents Documentation disclaimer • System administration documents • Security documents Avaya Inc. is not responsible for any modifications, additions, or deletions • Hardware-/software-based security tools to the original published version of this documentation unless such • Shared information between you and your peers modifications, additions, or deletions were performed by Avaya. • Telecommunications security experts Customer and/or End User agree to indemnify and hold harmless Avaya, Avaya's agents, servants and employees against all claims, lawsuits, To prevent intrusions to your telecommunications equipment, you and demands and judgments arising out of, or in connection with, subsequent your peers should carefully program and configure: modifications, additions or deletions to this documentation to the extent • Your Avaya-provided telecommunications systems and their made by the Customer or End User. interfaces • Your Avaya-provided software applications, as well as their Link disclaimer underlying hardware/software platforms and interfaces Avaya Inc. -

UPA—Sun'shighperformance Graphicsconnection
UPA—Sun’sHighPerformance GraphicsConnection TechnicalWhitePaper 1999 Sun Microsystems, Inc. All rights reserved. Printed in the United States of America. 901 San Antonio Road, Palo Alto, California 94303 U.S.A. The product described in this manual may be protected by one or more U.S. patents, foreign patents, or pending applications. TRADEMARKS Sun, Sun Microsystems, the Sun logo, Ultra, Sun Elite3D, Sun Enterprise, Java 3D, PGX, Java, SBus, and VIS are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the United States and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. OpenGL is a registered trademark of Silicon Graphics, Inc. THIS PUBLICATION IS PROVIDED “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, OR NON-INFRINGEMENT. THIS PUBLICATION COULD INCLUDE TECHNICAL INACCURACIES OR TYPOGRAPHICAL ERRORS. CHANGES ARE PERIODICALLY ADDED TO THE INFORMATION HEREIN; THESE CHANGES WILL BE INCORPORATED IN NEW EDITIONS OF THE PUBLICATION. SUN MICROSYSTEMS, INC. MAY MAKE IMPROVEMENTS AND/OR CHANGES IN THE PRODUCT(S) AND/OR THE PROGRAM(S) DESCRIBED IN THIS PUBLICATION AT ANY TIME. Please Recycle Contents Introduction. 1 Analyzing System Design and Application Performance. 2 Design Trade-offs . 2 An Overview of the UPA Interconnect . 3 Scalability, High Bandwidth, and Efficiency . 5 The UPA64S Graphics Bus. 6 Characterizing Application Performance and Bus Traffic. 7 UPA64S and Other Graphics Bus Technologies . -

Abkürzungs-Liste ABKLEX
Abkürzungs-Liste ABKLEX (Informatik, Telekommunikation) W. Alex 1. Juli 2021 Karlsruhe Copyright W. Alex, Karlsruhe, 1994 – 2018. Die Liste darf unentgeltlich benutzt und weitergegeben werden. The list may be used or copied free of any charge. Original Point of Distribution: http://www.abklex.de/abklex/ An authorized Czechian version is published on: http://www.sochorek.cz/archiv/slovniky/abklex.htm Author’s Email address: [email protected] 2 Kapitel 1 Abkürzungen Gehen wir von 30 Zeichen aus, aus denen Abkürzungen gebildet werden, und nehmen wir eine größte Länge von 5 Zeichen an, so lassen sich 25.137.930 verschiedene Abkür- zungen bilden (Kombinationen mit Wiederholung und Berücksichtigung der Reihenfol- ge). Es folgt eine Auswahl von rund 16000 Abkürzungen aus den Bereichen Informatik und Telekommunikation. Die Abkürzungen werden hier durchgehend groß geschrieben, Akzente, Bindestriche und dergleichen wurden weggelassen. Einige Abkürzungen sind geschützte Namen; diese sind nicht gekennzeichnet. Die Liste beschreibt nur den Ge- brauch, sie legt nicht eine Definition fest. 100GE 100 GBit/s Ethernet 16CIF 16 times Common Intermediate Format (Picture Format) 16QAM 16-state Quadrature Amplitude Modulation 1GFC 1 Gigabaud Fiber Channel (2, 4, 8, 10, 20GFC) 1GL 1st Generation Language (Maschinencode) 1TBS One True Brace Style (C) 1TR6 (ISDN-Protokoll D-Kanal, national) 247 24/7: 24 hours per day, 7 days per week 2D 2-dimensional 2FA Zwei-Faktor-Authentifizierung 2GL 2nd Generation Language (Assembler) 2L8 Too Late (Slang) 2MS Strukturierte