Vectorization with Haswell and Cilkplus
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Elementary Functions: Towards Automatically Generated, Efficient
Elementary functions : towards automatically generated, efficient, and vectorizable implementations Hugues De Lassus Saint-Genies To cite this version: Hugues De Lassus Saint-Genies. Elementary functions : towards automatically generated, efficient, and vectorizable implementations. Other [cs.OH]. Université de Perpignan, 2018. English. NNT : 2018PERP0010. tel-01841424 HAL Id: tel-01841424 https://tel.archives-ouvertes.fr/tel-01841424 Submitted on 17 Jul 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Délivré par l’Université de Perpignan Via Domitia Préparée au sein de l’école doctorale 305 – Énergie et Environnement Et de l’unité de recherche DALI – LIRMM – CNRS UMR 5506 Spécialité: Informatique Présentée par Hugues de Lassus Saint-Geniès [email protected] Elementary functions: towards automatically generated, efficient, and vectorizable implementations Version soumise aux rapporteurs. Jury composé de : M. Florent de Dinechin Pr. INSA Lyon Rapporteur Mme Fabienne Jézéquel MC, HDR UParis 2 Rapporteur M. Marc Daumas Pr. UPVD Examinateur M. Lionel Lacassagne Pr. UParis 6 Examinateur M. Daniel Menard Pr. INSA Rennes Examinateur M. Éric Petit Ph.D. Intel Examinateur M. David Defour MC, HDR UPVD Directeur M. Guillaume Revy MC UPVD Codirecteur À la mémoire de ma grand-mère Françoise Lapergue et de Jos Perrot, marin-pêcheur bigouden. -

Andre Heidekrueger
AMD Heterogenous Computing X86 in development AMD new CPU and Accelerator Designs Building blocks for Heterogenous computing with the GPU Accelerators and the Latest x86 Platform Innovations 1 | Hot Chips | August, 2010 Server Industry Trends China has Seismic The performance of the 265m datasets online gamers fastest supercomputer typically exceed a terabyte grew 500x in the last decade The top 8 systems Accelerator-based on the Green 500 list use accelerators 800 servers on the Green 500 images list are 3x as energy are uploaded to Facebook efficient as those without every second 2 | Hot Chips | August,accelerators 2010 2 Top500.org Performance Projections: Can the Current Trajectory Achieve Exascale? 1 EFlops Might get there on current trajectory, but… • Too late for major government programs leading to 2018 • System power in traditional x86 architecture would be unmanageable Source for chart: Top500.org; annotations by AMD 3 | Hot Chips | August, 2010 Three Eras of Processor Performance Multi-Core Heterogeneous Single-Core Systems Era Era Era Enabled by: Enabled by: Enabled by: Moore’s Law Moore’s Law Moore’s Law Voltage Scaling Desire for Throughput Abundant data parallelism Micro-Architecture 20 years of SMP arch Power efficient GPUs Constrained by: Constrained by: Temporarily constrained by: Power Power Programming models Complexity Parallel SW availability Communication overheads Scalability o o ? we are we are here o here we are Performance here thread Performance - Time Time Application Targeted Time Throughput Throughput Performance (# of Processors) (Data-parallel exploitation) Single 4 | Driving HPC Performance Efficiency Fusion Architecture The Benefits of Heterogeneous Computing x86 CPU owns GPU Optimized for the Software World Modern Workloads . -

Operating Systems and Applications for Embedded Systems >>> Toolchains
>>> Operating Systems And Applications For Embedded Systems >>> Toolchains Name: Mariusz Naumowicz Date: 31 sierpnia 2018 [~]$ _ [1/19] >>> Plan 1. Toolchain Toolchain Main component of GNU toolchain C library Finding a toolchain 2. crosstool-NG crosstool-NG Installing Anatomy of a toolchain Information about cross-compiler Configruation Most interesting features Sysroot Other tools POSIX functions AP [~]$ _ [2/19] >>> Toolchain A toolchain is the set of tools that compiles source code into executables that can run on your target device, and includes a compiler, a linker, and run-time libraries. [1. Toolchain]$ _ [3/19] >>> Main component of GNU toolchain * Binutils: A set of binary utilities including the assembler, and the linker, ld. It is available at http://www.gnu.org/software/binutils/. * GNU Compiler Collection (GCC): These are the compilers for C and other languages which, depending on the version of GCC, include C++, Objective-C, Objective-C++, Java, Fortran, Ada, and Go. They all use a common back-end which produces assembler code which is fed to the GNU assembler. It is available at http://gcc.gnu.org/. * C library: A standardized API based on the POSIX specification which is the principle interface to the operating system kernel from applications. There are several C libraries to consider, see the following section. [1. Toolchain]$ _ [4/19] >>> C library * glibc: Available at http://www.gnu.org/software/libc. It is the standard GNU C library. It is big and, until recently, not very configurable, but it is the most complete implementation of the POSIX API. * eglibc: Available at http://www.eglibc.org/home. -

Hierarchical Roofline Analysis for Gpus: Accelerating Performance
Hierarchical Roofline Analysis for GPUs: Accelerating Performance Optimization for the NERSC-9 Perlmutter System Charlene Yang, Thorsten Kurth Samuel Williams National Energy Research Scientific Computing Center Computational Research Division Lawrence Berkeley National Laboratory Lawrence Berkeley National Laboratory Berkeley, CA 94720, USA Berkeley, CA 94720, USA fcjyang, [email protected] [email protected] Abstract—The Roofline performance model provides an Performance (GFLOP/s) is bound by: intuitive and insightful approach to identifying performance bottlenecks and guiding performance optimization. In prepa- Peak GFLOP/s GFLOP/s ≤ min (1) ration for the next-generation supercomputer Perlmutter at Peak GB/s × Arithmetic Intensity NERSC, this paper presents a methodology to construct a hi- erarchical Roofline on NVIDIA GPUs and extend it to support which produces the traditional Roofline formulation when reduced precision and Tensor Cores. The hierarchical Roofline incorporates L1, L2, device memory and system memory plotted on a log-log plot. bandwidths into one single figure, and it offers more profound Previously, the Roofline model was expanded to support insights into performance analysis than the traditional DRAM- the full memory hierarchy [2], [3] by adding additional band- only Roofline. We use our Roofline methodology to analyze width “ceilings”. Similarly, additional ceilings beneath the three proxy applications: GPP from BerkeleyGW, HPGMG Roofline can be added to represent performance bottlenecks from AMReX, and conv2d from TensorFlow. In so doing, we demonstrate the ability of our methodology to readily arising from lack of vectorization or the failure to exploit understand various aspects of performance and performance fused multiply-add (FMA) instructions. bottlenecks on NVIDIA GPUs and motivate code optimizations. -

XL C/C++: Language Reference About This Document
IBM XL C/C++ for Linux, V16.1.1 IBM Language Reference Version 16.1.1 SC27-8045-01 IBM XL C/C++ for Linux, V16.1.1 IBM Language Reference Version 16.1.1 SC27-8045-01 Note Before using this information and the product it supports, read the information in “Notices” on page 63. First edition This edition applies to IBM XL C/C++ for Linux, V16.1.1 (Program 5765-J13, 5725-C73) and to all subsequent releases and modifications until otherwise indicated in new editions. Make sure you are using the correct edition for the level of the product. © Copyright IBM Corporation 1998, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document ......... v Chapter 4. IBM extension features ... 11 Who should read this document........ v IBM extension features for both C and C++.... 11 How to use this document.......... v General IBM extensions ......... 11 How this document is organized ....... v Extensions for GNU C compatibility ..... 15 Conventions .............. v Extensions for vector processing support ... 47 Related information ........... viii IBM extension features for C only ....... 56 Available help information ........ ix Extensions for GNU C compatibility ..... 56 Standards and specifications ........ x Extensions for vector processing support ... 58 Technical support ............ xi IBM extension features for C++ only ...... 59 How to send your comments ........ xi Extensions for C99 compatibility ...... 59 Extensions for C11 compatibility ...... 59 Chapter 1. Standards and specifications 1 Extensions for GNU C++ compatibility .... 60 Chapter 2. Language levels and Notices .............. 63 language extensions ......... 3 Trademarks ............. -

Section “Common Predefined Macros” in the C Preprocessor
The C Preprocessor For gcc version 12.0.0 (pre-release) (GCC) Richard M. Stallman, Zachary Weinberg Copyright c 1987-2021 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation. A copy of the license is included in the section entitled \GNU Free Documentation License". This manual contains no Invariant Sections. The Front-Cover Texts are (a) (see below), and the Back-Cover Texts are (b) (see below). (a) The FSF's Front-Cover Text is: A GNU Manual (b) The FSF's Back-Cover Text is: You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development. i Table of Contents 1 Overview :::::::::::::::::::::::::::::::::::::::: 1 1.1 Character sets:::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.2 Initial processing ::::::::::::::::::::::::::::::::::::::::::::::: 2 1.3 Tokenization ::::::::::::::::::::::::::::::::::::::::::::::::::: 4 1.4 The preprocessing language :::::::::::::::::::::::::::::::::::: 6 2 Header Files::::::::::::::::::::::::::::::::::::: 7 2.1 Include Syntax ::::::::::::::::::::::::::::::::::::::::::::::::: 7 2.2 Include Operation :::::::::::::::::::::::::::::::::::::::::::::: 8 2.3 Search Path :::::::::::::::::::::::::::::::::::::::::::::::::::: 9 2.4 Once-Only Headers::::::::::::::::::::::::::::::::::::::::::::: 9 2.5 Alternatives to Wrapper #ifndef :::::::::::::::::::::::::::::: -

Cheat Sheets of the C Standard Library
Cheat Sheets of the C standard library Version 1.06 Last updated: 2012-11-28 About This document is a set of quick reference sheets (or ‘cheat sheets’) of the ANSI C standard library. It contains function and macro declarations in every header of the library, as well as notes about their usage. This document covers C++, but does not cover the C99 or C11 standard. A few non-ANSI-standard functions, if they are interesting enough, are also included. Style used in this document Function names, prototypes and their parameters are in monospace. Remarks of functions and parameters are marked italic and enclosed in ‘/*’ and ‘*/’ like C comments. Data types, whether they are built-in types or provided by the C standard library, are also marked in monospace. Types of parameters and return types are in bold. Type modifiers, like ‘const’ and ‘unsigned’, have smaller font sizes in order to save space. Macro constants are marked using proportional typeface, uppercase, and no italics, LIKE_THIS_ONE. One exception is L_tmpnum, which is the constant that uses lowercase letters. Example: int system ( const char * command ); /* system: The value returned depends on the running environment. Usually 0 when executing successfully. If command == NULL, system returns whether the command processor exists (0 if not). */ License Copyright © 2011 Kang-Che “Explorer” Sung (宋岡哲 <explorer09 @ gmail.com>) This work is licensed under the Creative Commons Attribution 3.0 Unported License. http://creativecommons.org/licenses/by/3.0/ . When copying and distributing this document, I advise you to keep this notice and the references section below with your copies, as a way to acknowledging all the sources I referenced. -

Nesc 1.2 Language Reference Manual
nesC 1.2 Language Reference Manual David Gay, Philip Levis, David Culler, Eric Brewer August 2005 1 Introduction nesC is an extension to C [3] designed to embody the structuring concepts and execution model of TinyOS [2]. TinyOS is an event-driven operating system designed for sensor network nodes that have very limited resources (e.g., 8K bytes of program memory, 512 bytes of RAM). TinyOS has been reimplemented in nesC. This manual describes v1.2 of nesC, changes from v1.0 and v1.1 are summarised in Section 2. The basic concepts behind nesC are: • Separation of construction and composition: programs are built out of components, which are assembled (“wired”) to form whole programs. Components define two scopes, one for their specification (containing the names of their interfaces) and one for their implementation. Components have internal concurrency in the form of tasks. Threads of control may pass into a component through its interfaces. These threads are rooted either in a task or a hardware interrupt. • Specification of component behaviour in terms of set of interfaces. Interfaces may be provided or used by the component. The provided interfaces are intended to represent the functionality that the component provides to its user, the used interfaces represent the functionality the component needs to perform its job. • Interfaces are bidirectional: they specify a set of functions to be implemented by the inter- face’s provider (commands) and a set to be implemented by the interface’s user (events). This allows a single interface to represent a complex interaction between components (e.g., registration of interest in some event, followed by a callback when that event happens). -

Theoretical Peak FLOPS Per Instruction Set on Modern Intel Cpus
Theoretical Peak FLOPS per instruction set on modern Intel CPUs Romain Dolbeau Bull – Center for Excellence in Parallel Programming Email: [email protected] Abstract—It used to be that evaluating the theoretical and potentially multiple threads per core. Vector of peak performance of a CPU in FLOPS (floating point varying sizes. And more sophisticated instructions. operations per seconds) was merely a matter of multiplying Equation2 describes a more realistic view, that we the frequency by the number of floating-point instructions will explain in details in the rest of the paper, first per cycles. Today however, CPUs have features such as vectorization, fused multiply-add, hyper-threading or in general in sectionII and then for the specific “turbo” mode. In this paper, we look into this theoretical cases of Intel CPUs: first a simple one from the peak for recent full-featured Intel CPUs., taking into Nehalem/Westmere era in section III and then the account not only the simple absolute peak, but also the full complexity of the Haswell family in sectionIV. relevant instruction sets and encoding and the frequency A complement to this paper titled “Theoretical Peak scaling behavior of current Intel CPUs. FLOPS per instruction set on less conventional Revision 1.41, 2016/10/04 08:49:16 Index Terms—FLOPS hardware” [1] covers other computing devices. flop 9 I. INTRODUCTION > operation> High performance computing thrives on fast com- > > putations and high memory bandwidth. But before > operations => any code or even benchmark is run, the very first × micro − architecture instruction number to evaluate a system is the theoretical peak > > - how many floating-point operations the system > can theoretically execute in a given time. -

INTRODUCTION to ANSI C Outline
1/17/14 INTRODUCTION TO ANSI C Dr. Chokchai (Box) Leangsuksun Louisiana Tech University Original slides were created by Dr. Tom Chao Zhou, https://www.cse.cuhk.edu.hk 1 Outline • History • Introduction to C – Basics – If Statement – Loops – Functions – Switch case – Pointers – Structures – File I/O Louisiana Tech University 2 1 1/17/14 Introduction • The C programming language was designed by Dennis Ritchie at Bell Laboratories in the early 1970s • Influenced by – ALGOL 60 (1960), – CPL (Cambridge, 1963), – BCPL (Martin Richard, 1967), – B (Ken Thompson, 1970) • Traditionally used for systems programming, though this may be changing in favor of C++ • Traditional C: – The C Programming Language, by Brian Kernighan and Dennis Ritchie, 2nd Edition, Prentice Hall – Referred to as K&R Original by Fred Kuhns) Louisiana Tech University 3 Standard C • Standardized in 1989 by ANSI (American National Standards Institute) known as ANSI C • International standard (ISO) in 1990 which was adopted by ANSI and is known as C89 • As part of the normal evolution process the standard was updated in 1995 (C95) and 1999 (C99) • C++ and C – C++ extends C to include support for Object Oriented Programming and other features that facilitate large software development projects – C is not strictly a subset of C++, but it is possible to write “Clean C” that conforms to both the C++ and C standards. Original by Fred Kuhns) Original by Fred Kuhns) Louisiana Tech University 4 2 1/17/14 Elements of a C Program • A C development environment: – Application Source: application source and header files – System libraries and headers: a set of standard libraries and their header files. -
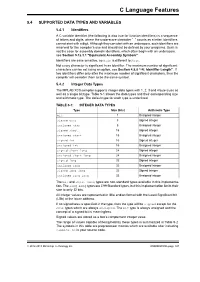
C Language Features
C Language Features 5.4 SUPPORTED DATA TYPES AND VARIABLES 5.4.1 Identifiers A C variable identifier (the following is also true for function identifiers) is a sequence of letters and digits, where the underscore character “_” counts as a letter. Identifiers cannot start with a digit. Although they can start with an underscore, such identifiers are reserved for the compiler’s use and should not be defined by your programs. Such is not the case for assembly domain identifiers, which often begin with an underscore, see Section 5.12.3.1 “Equivalent Assembly Symbols”. Identifiers are case sensitive, so main is different to Main. Not every character is significant in an identifier. The maximum number of significant characters can be set using an option, see Section 4.8.8 “-N: Identifier Length”. If two identifiers differ only after the maximum number of significant characters, then the compiler will consider them to be the same symbol. 5.4.2 Integer Data Types The MPLAB XC8 compiler supports integer data types with 1, 2, 3 and 4 byte sizes as well as a single bit type. Table 5-1 shows the data types and their corresponding size and arithmetic type. The default type for each type is underlined. TABLE 5-1: INTEGER DATA TYPES Type Size (bits) Arithmetic Type bit 1 Unsigned integer signed char 8 Signed integer unsigned char 8 Unsigned integer signed short 16 Signed integer unsigned short 16 Unsigned integer signed int 16 Signed integer unsigned int 16 Unsigned integer signed short long 24 Signed integer unsigned short long 24 Unsigned integer signed long 32 Signed integer unsigned long 32 Unsigned integer signed long long 32 Signed integer unsigned long long 32 Unsigned integer The bit and short long types are non-standard types available in this implementa- tion. -

Choosing System C Library
Choosing System C library Khem Raj Comcast Embedded Linux Conference Europe 2014 Düsseldorf Germany Introduction “God defined C standard library everything else is creation of man” Introduction • Standard library for C language • Provides primitives for OS service • Hosted/freestanding • String manipulations • Types • I/O • Memory • APIs Linux Implementations • GNU C library (glibc) • uClibc • eglibc – Now merged into glibc • Dietlibc • Klibc • Musl • bionic Multiple C library FAQs • Can I have multiple C libraries side by side ? • Can programs compiled with glibc run on uclibc or vice versa ? • Are they functional compatible ? • Do I need to choose one over other if I am doing real time Linux? • I have a baremetal application what libc options do I have ? Posix Compliance • Posix specifies more than ISO C • Varying degree of compliance What matters to you ? • Code Size • Functionality • Interoperability • Licensing • Backward Compatibility • Variety of architecture support • Dynamic Linking • Build system Codesize • Dietlibc/klibc – Used in really small setup e.g. initramfs • Bionic – Small linked into every process • uClibc – Configurable • Size can be really small at the expense of functionality • Eglibc – Has option groups can be ( < 1M ) License • Bionic – BSD/Apache-2.0 • Musl - MIT • Uclibc – LGPL-2.1 • Eglibc/Glibc – LGPL-2.1 Assigned to FSF • Dietlibc – GPLv2 • Klibc – GPLv2 • Newlib – some parts are GPLv3 Compliance • Musl strives for ISO/C and POSIX compliance No-mmu • uClibc supported No-mmu Distributions • Glibc is used in