Measuring Language Distance of Isolated European Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Shared Lexicon of Baltic, Slavic and Germanic
THE SHARED LEXICON OF BALTIC, SLAVIC AND GERMANIC VINCENT F. VAN DER HEIJDEN ******** Thesis for the Master Comparative Indo-European Linguistics under supervision of prof.dr. A.M. Lubotsky Universiteit Leiden, 2018 Table of contents 1. Introduction 2 2. Background topics 3 2.1. Non-lexical similarities between Baltic, Slavic and Germanic 3 2.2. The Prehistory of Balto-Slavic and Germanic 3 2.2.1. Northwestern Indo-European 3 2.2.2. The Origins of Baltic, Slavic and Germanic 4 2.3. Possible substrates in Balto-Slavic and Germanic 6 2.3.1. Hunter-gatherer languages 6 2.3.2. Neolithic languages 7 2.3.3. The Corded Ware culture 7 2.3.4. Temematic 7 2.3.5. Uralic 9 2.4. Recapitulation 9 3. The shared lexicon of Baltic, Slavic and Germanic 11 3.1. Forms that belong to the shared lexicon 11 3.1.1. Baltic-Slavic-Germanic forms 11 3.1.2. Baltic-Germanic forms 19 3.1.3. Slavic-Germanic forms 24 3.2. Forms that do not belong to the shared lexicon 27 3.2.1. Indo-European forms 27 3.2.2. Forms restricted to Europe 32 3.2.3. Possible Germanic borrowings into Baltic and Slavic 40 3.2.4. Uncertain forms and invalid comparisons 42 4. Analysis 48 4.1. Morphology of the forms 49 4.2. Semantics of the forms 49 4.2.1. Natural terms 49 4.2.2. Cultural terms 50 4.3. Origin of the forms 52 5. Conclusion 54 Abbreviations 56 Bibliography 57 1 1. -
Internal Classification of Indo-European Languages: Survey
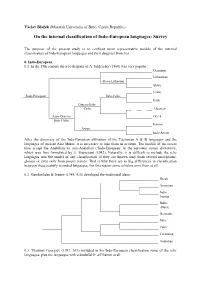
Václav Blažek (Masaryk University of Brno, Czech Republic) On the internal classification of Indo-European languages: Survey The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

CHAPTER SEVENTEEN History of the German Language 1 Indo
CHAPTER SEVENTEEN History of the German Language 1 Indo-European and Germanic Background Indo-European Background It has already been mentioned in this course that German and English are related languages. Two languages can be related to each other in much the same way that two people can be related to each other. If two people share a common ancestor, say their mother or their great-grandfather, then they are genetically related. Similarly, German and English are genetically related because they share a common ancestor, a language which was spoken in what is now northern Germany sometime before the Angles and the Saxons migrated to England. We do not have written records of this language, unfortunately, but we have a good idea of what it must have looked and sounded like. We have arrived at our conclusions as to what it looked and sounded like by comparing the sounds of words and morphemes in earlier written stages of English and German (and Dutch) and in modern-day English and German dialects. As a result of the comparisons we are able to reconstruct what the original language, called a proto-language, must have been like. This particular proto-language is usually referred to as Proto-West Germanic. The method of reconstruction based on comparison is called the comparative method. If faced with two languages the comparative method can tell us one of three things: 1) the two languages are related in that both are descended from a common ancestor, e.g. German and English, 2) the two are related in that one is the ancestor of the other, e.g. -

Can Threatened Languages Be Saved? Reversing Language Shift, Revisited: a 21St Century Perspective
MULTILINGUAL MATTERS 116 Series Editor: John Edwards Can Threatened Languages Be Saved? Reversing Language Shift, Revisited: A 21st Century Perspective Edited by Joshua A. Fishman MULTILINGUAL MATTERS LTD Clevedon • Buffalo • Toronto • Sydney Library of Congress Cataloging in Publication Data Can Threatened Languages Be Saved? Reversing Language Shift Revisited: A 21st Century Perspective/Edited by Joshua A. Fishman. Multilingual Matters: 116 Includes bibliographical references and index. 1. Language attrition. I. Fishman, Joshua A. II. Multilingual Matters (Series): 116 P40.5.L28 C36 2000 306.4’4–dc21 00-024283 British Library Cataloguing in Publication Data A CIP catalogue record for this book is available from the British Library. ISBN 1-85359-493-8 (hbk) ISBN 1-85359-492-X (pbk) Multilingual Matters Ltd UK: Frankfurt Lodge, Clevedon Hall, Victoria Road, Clevedon BS21 7HH. USA: UTP, 2250 Military Road, Tonawanda, NY 14150, USA. Canada: UTP, 5201 Dufferin Street, North York, Ontario M3H 5T8, Canada. Australia: P.O. Box 586, Artarmon, NSW, Australia. Copyright © 2001 Joshua A. Fishman and the authors of individual chapters. All rights reserved. No part of this work may be reproduced in any form or by any means without permission in writing from the publisher. Index compiled by Meg Davies (Society of Indexers). Typeset by Archetype-IT Ltd (http://www.archetype-it.com). Printed and bound in Great Britain by Biddles Ltd. In memory of Charles A. Ferguson 1921–1998 thanks to whom sociolinguistics became both an intellectual and a moral quest Contents Contributors . vii Preface . xii 1 Why is it so Hard to Save a Threatened Language? J.A. -

"Evolution of Human Languages": Current State of Affairs
«Evolution of Human Languages»: current state of affairs (03.2014) Contents: I. Currently active members of the project . 2 II. Linguistic experts associated with the project . 4 III. General description of EHL's goals and major lines of research . 6 IV. Up-to-date results / achievements of EHL research . 9 V. A concise list of actual problems and tasks for future resolution. 18 VI. EHL resources and links . 20 2 I. Currently active members of the project. Primary affiliation: Senior researcher, Center for Comparative Studies, Russian State University for the Humanities (Moscow). Web info: http://ivka.rsuh.ru/article.html?id=80197 George Publications: http://rggu.academia.edu/GeorgeStarostin Starostin Research interests: Methodology of historical linguistics; long- vs. short-range linguistic comparison; history and classification of African languages; history of the Chinese language; comparative and historical linguistics of various language families (Indo-European, Altaic, Yeniseian, Dravidian, etc.). Primary affiliation: Visiting researcher, Santa Fe Institute. Formerly, professor of linguistics at the University of Melbourne. Ilia Publications: http://orlabs.oclc.org/identities/lccn-n97-4759 Research interests: Genetic and areal language relationships in Southeast Asia; Peiros history and classification of Sino-Tibetan, Austronesian, Austroasiatic languages; macro- and micro-families of the Americas; methodology of historical linguistics. Primary affiliation: Senior researcher, Institute of Slavic Studies, Russian Academy of Sciences (Moscow / Novosibirsk). Web info / publications list (in Russian): Sergei http://www.inslav.ru/index.php?option- Nikolayev =com_content&view=article&id=358:2010-06-09-18-14-01 Research interests: Comparative Indo-European and Slavic studies; internal and external genetic relations of North Caucasian languages; internal and external genetic relations of North American languages (Na-Dene; Algic; Mosan). -

Lithuanian Diaspora
University of Notre Dame Australia ResearchOnline@ND Theses 2008 Lithuanian diaspora: An interview study on the preservation or loss of Pre-World War Two traditional culture among Lithuanian Catholic Émigrés in Western Australia and Siberia, in comparison with Lithuanians in their homeland Milena Vico University of Notre Dame Australia Follow this and additional works at: http://researchonline.nd.edu.au/theses Part of the Arts and Humanities Commons COMMONWEALTH OF AUSTRALIA Copyright Regulations 1969 WARNING The am terial in this communication may be subject to copyright under the Act. Any further copying or communication of this material by you may be the subject of copyright protection under the Act. Do not remove this notice. Publication Details Vico, M. (2008). Lithuanian diaspora: An interview study on the preservation or loss of Pre-World War Two traditional culture among Lithuanian Catholic Émigrés in Western Australia and Siberia, in comparison with Lithuanians in their homeland (Doctor of Philosophy (PhD)). University of Notre Dame Australia. http://researchonline.nd.edu.au/theses/33 This dissertation/thesis is brought to you by ResearchOnline@ND. It has been accepted for inclusion in Theses by an authorized administrator of ResearchOnline@ND. For more information, please contact [email protected]. CHAPTER 2 LITHUANIA: THE EARLIEST BEGINNINGS 9 CHAPTER 2 LITHUANIA: THE EARLIEST BEGINNINGS An historical culture is one that binds present and future generations, like links in a chain, to all those who precede them. A man identifies himself, according to the national ideal, through his relationship to his ancestors and forebears, and to the events that shaped their character (Smith, 1979, p. -

The Incidence and Evolution of Palatalized Consonants in Latvian
City University of New York (CUNY) CUNY Academic Works All Dissertations, Theses, and Capstone Projects Dissertations, Theses, and Capstone Projects 5-2015 The Incidence and Evolution of Palatalized Consonants in Latvian Linda Zalite Graduate Center, City University of New York How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/gc_etds/1198 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] THE INCIDENCE AND EVOLUTION OF PALATALIZED CONSONANTS IN LATVIAN by LINDA ZALITE A master’s thesis submitted to the Graduate Faculty in Linguistics in partial fulfillment of the requirements for the degree of Master of Arts, The City University of New York 2015 © 2015 Linda Zalite All Rights Reserved ii This manuscript has been read and accepted for the Graduate Faculty in Linguistics in satisfaction of the dissertation requirement for the degree of Master of Arts. Juliette Blevins Date Thesis Advisor Gita Martohardjono Date Executiv e Officer THE CITY UNIVERSITY OF NEW YORK iii Abstract The Incidence and Evolution of Palatalized Consonants in Latvian by Linda Zalite Advisor: Professor Juliette Blevins This thesis traces the evolution of the palatalized rhotic /rj/ in Baltic languages with focus on the continuation of this segment in Latvian and its recent neutralization with /r/. Historical, phonological, phonetic, and synchronic data is gathered as evidence to further our understanding of the Latvian palatalized rhotic and its near-disappearance in the 20th century. Previous typological works of Endzelīns (1922, 1951), Dini (1997), Rūķe-Draviņa (1994) and Ābele (1929) were considered intending to answer three central questions. -
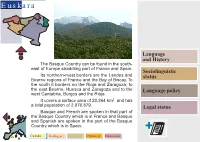
Euskara. Language and History
E uskara Language and History The Basque Country can be found in the south- east of Europe straddling part of France and Spain. Sociolinguistic Its northern-most borders are the Landes and status Bearne regions of France and the Bay of Biscay. To the south it borders on the Rioja and Zaragoza, to the east Bearne, Huesca and Zaragoza and to the Language policy west Cantabria, Burgos and the Rioja. It covers a surface area of 20,864 km2 and has a total population of 2,876,879. Legal status Basque and French are spoken in that part of the Basque Country which is in France and Basque and Spanish are spoken in the part of the Basque Country which is in Spain. C atalà G alego Cymraeg Elsässisch Euskara Language and History Sociolinguistic status Sancho The Wise Language policy defined the Basque language as a "lingua navarrorum" Legal status (1167) The Basque Country is currently divided up into seven different provinces or administrative territories: Lapurdi, Basse-Navarre and Zuberoa in the French part of the Basque Country, which account for a total of 249,275 inhabitants of the total population (according to the 1990 census) and the rest in the Basque Autonomous Community (comprised of Alava, Bizkaia and Gipuzkoa) with 2,104,041 inhabitants (according to the 1991 census) and the region of Navarre with 523,563 inhabitants (1991census). According to data from the II Sociolinguistic Survey of 1996, 26.4% of the population is Basque-speaking in the French Basque Country, 25.3% in the Basque Autonomous Community whilst in the region of Navarre it is only 9.6%. -

Language Isolates Basque and the Reconstruction of Isolated Languages
This article was downloaded by: 10.3.98.104 On: 01 Oct 2021 Access details: subscription number Publisher: Routledge Informa Ltd Registered in England and Wales Registered Number: 1072954 Registered office: 5 Howick Place, London SW1P 1WG, UK Language Isolates Lyle Campbell Basque and the Reconstruction of Isolated Languages Publication details https://www.routledgehandbooks.com/doi/10.4324/9781315750026.ch3 Joseba A. Lakarra Published online on: 25 Sep 2017 How to cite :- Joseba A. Lakarra. 25 Sep 2017, Basque and the Reconstruction of Isolated Languages from: Language Isolates Routledge Accessed on: 01 Oct 2021 https://www.routledgehandbooks.com/doi/10.4324/9781315750026.ch3 PLEASE SCROLL DOWN FOR DOCUMENT Full terms and conditions of use: https://www.routledgehandbooks.com/legal-notices/terms This Document PDF may be used for research, teaching and private study purposes. Any substantial or systematic reproductions, re-distribution, re-selling, loan or sub-licensing, systematic supply or distribution in any form to anyone is expressly forbidden. The publisher does not give any warranty express or implied or make any representation that the contents will be complete or accurate or up to date. The publisher shall not be liable for an loss, actions, claims, proceedings, demand or costs or damages whatsoever or howsoever caused arising directly or indirectly in connection with or arising out of the use of this material. Judith Aissen et al. Introduction CHAPTER 3 BASQUE AND THE RECONSTRUCTION OF ISOLATED LANGUAGES Joseba A. Lakarra 1 INTRODUCTION1 I think it’s appropriate to ask what the purpose of our genetic classification is. I believe that most historical linguists value the classifications because they help us find out about the histories of the languages in a family. -

Evidence for Basque As an Indo-European Language
Evidence for Basque as an Indo-European Language Gianfranco Forni This article provides phonetic, lexical and grammatical evidence that Basque is an Indo-European language. It provides a brief history of previous research into the origins of Basque; a short description of the genesis of this article; a description of the methodology adopted for the present research; an overview of Michelena’s internal reconstruction of Pre-Basque; 23 sets of chronologically arranged sound laws linking Proto-Indo-European to Pre-Basque; Indo-European etymologies for 75% of the Basque native basic lexicon, with systematic cross-references to regular sound laws; Indo- European etymologies of some Basque bound morphemes, including case markers; a discussion of the findings; and Indo- European etymologies of 40 additional, non-basic lexical items. The current mainstream theory: Basque as a language isolate The current consensus among Vasconists and “orthodox” historical linguists is that Basque is a language isolate. Trask (T 358-429) provides an in-depth analysis of previous attempts at relating Basque to other language families, incl. North-Caucasian, and illustrates why such attempts variously failed, except for Aquitanian, which is considered, beyond doubt, to be related to Basque. In fact, the Basque lexicon looks quite un-Indo-European, as shown by the following subset of the basic lexicon: • personal pronouns: ni ‘I’, hi ‘thou’, gu ‘we’, zuek ‘you’, ber- ‘self’; • interrogative stems: no-, ze(r)-; • negation: ez ‘no, not’; • numerals: bat ‘1’, bi ‘2’, -

Juha JANHUNEN (Helsinki)
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Portal Czasopism Naukowych (E-Journals) Studia Etymologica Cracoviensia vol. 14 Kraków 2009 Juha JANHUNEN (Helsinki) SOME ADDITIONAL NOTES ON THE MACROHYDRONYMS OF THE LADOGA REGION In one of his last but not least ingenious papers, published posthumously in Studia Etymologica Cracoviensia 13, Eugene Helimski (2008) deals with the etymologies of the names Ladoga and Neva. Following V. S. Kuleshov (2003), he assumes that the river Neva, which was formed only slightly over three thou- sand years ago as a result of postglacial isostatic uplift, got its name from an Indo-European-speaking population who observed the birth of the ‘New’ river. The semantic identification of Neva with ‘new’ is synchronically supported by the homonymy of this hydronym with the Scandinavian words for ‘new’, as still in modern Swedish Nyen ‘Neva’ vs. ny ‘new’. Helimski concludes that the Neva region must have been within the range of the linguistic expansion routes which brought Germanic from the Indo-European homeland to northern Central Europe and Scandinavia. He also implies that the Neva has since its formation remained within the sphere of the geographic consciousness of Germanic speakers, espe- cially the Scandinavians. In fact, the Swedish fort of Nyenskans was replaced by the Russian city of St. Petersburg only 300 years ago. The etymology of Neva is potentially important in that it shows that the historical presence of the Finnic branch of Uralic on both sides of the Gulf of Finland is secondary to an earlier Indo-European expansion to the region. -

Proto Baltic & Baltic Languages
PROTO-BALTIC >>>|||<<< An excerpt of text from Virdainas © Jos. Pashka 2012 * Warning - RWA xenophobes may find this content emotionally disturbing. > Link to Google Translate URL < "People lie. The evidence doesn't lie " - Grissom. The IE Satem poly-ethnic Middle Dnieper Culture ( R1a1a1, Z280 w/ multiple variants ) appeared well over five thousand years ago in forested regions by the Middle & Upper Dnieper river and it's tributaries - also including a wide area extending East towards the Don, along with an early Northeastern variant (LWb allele, R1a1a1, Z280 Northern variants & Z92, L235 ) which developed of related East Baltic speaking forest-zone Fatyanovo-Balanovo cultures that spread North and East, up to the Ural Mountains, together are seen as Northern extensions ( 3300 - 1800 BCE, Loze 1992, Tab.1 ) of the poly-ethnic Corded Ware ( R1a- M417, Z283 ) culture horizon (re: mtDNA N1a1). [ Note - the (DNA) citations are only partial / general indicators.] There were altogether really quite a few (R1a1a1, Z280 Northern variants ) Baltic Satem speaking cultures - the early West Baltic ( Pamariai / Bay Coast ) Barrow culture in the West - the growing Middle Dnieper in the middle / with a Dnieper-Desna variant - and the geographically immense East Baltic speaking Fatyanovo-Balanovo cultures, settled among (and eventually merging with, among others) neighboring Finno-Ugrics ( N1c1) and Narva substratum on territory in the North & East - up to the Ural mountains and Kama-Volga rivers. A later phase of the Catacomb ( MVK - Mnogovalikovo ) & Pit- grave ( Poltavka ) influenced border Fatyanovo-Balanovo was the Corded Ware Abashevo culture. To the South of these bordered complexes like Sosnica, that later became the Baltic-type Milograd & Bondarikha ( > Jukhnovo ) cultures.