SAI: a Sensible Artificial Intelligence That Plays with Handicap and Targets
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Rules of Go It Would Be Suicidal (And Hence Illegal) for White to Play at E, the Board Is Initially Because the Block of Four White Empty
Scoring Example another liberty at D. Rules of Go It would be suicidal (and hence illegal) for white to play at E, The board is initially because the block of four white empty. stones would have no liberties. Could black play at E? It looks like a suicidal move, because Black plays first. the black stone would have no liberties, but it would occupy On a turn, either place a the white block’s last liberty at stone on a vacant inter- the same time; the move is legal and the white stones are section or pass (giving a captured. stone to the opponent to The black block F can never be keep as a prisoner). In the diagram above, white captured. It has two internal has 8 points in the center and liberties (eyes) at the points Stones may be captured 7 points at the upper right. marked G. To capture the by tightly surrounding Two white stones (shown be- block, white would have to oc- low the board) are prisoners. cupy both of them, but either them. Captured stones White’s score is 8 + 7 − 2 = 13. move would be suicidal and are taken off the board Black has 3 points at the up- therefore illegal. and kept as prisoners. per left and 9 at the lower Suppose white plays at H, cap- right. One black stone is a turing the black stone at I. prisoner. Black’s score is (Notice that H is not an eye.) It is illegal to make a − 3 + 9 1 = 11. White wins. -

How to Play Go Lesson 1: Introduction to Go
How To Play Go Lesson 1: Introduction To Go 1.1 About The Game Of Go Go is an ancient game originated from China, with a definite history of over 3000 years, although there are historians who say that the game was invented more than 4000 years ago. The Chinese call the game Weiqi. Other names for Go include Baduk (Korean), Igo (Japanese) and Goe (Taiwanese). This game is getting increasingly popular around the world, especially in Asian, European and American countries, with many worldwide competitions being held. Diagram 1-1 The game of Go is played on a board as shown in Diagram 1-1. The Go set comprises of the board, together with 180 black and white stones each. Diagram 1-1 shows the standard 19x19 board (i.e. the board has 19 lines by 19 lines), but there are 13x13 and 9x9 boards in play. However, the 9x9 and 13x13 boards are usually for beginners; more advanced players would prefer the traditional 19x19 board. Compared to International Chess and Chinese Chess, Go has far fewer rules. Yet this allowed for all sorts of moves to be played, so Go can be a more intellectually challenging game than the other two types of Chess. Nonetheless, Go is not a difficult game to learn, so have a fun time playing the game with your friends. Several rule sets exist and are commonly used throughout the world. Two of the most common ones are Chinese rules and Japanese rules. Another is Ing's rules. All the rules are basically the same, the only significant difference is in the way counting of territories is done when the game ends. -

Computer Go: from the Beginnings to Alphago Martin Müller, University of Alberta
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk ✤ Game of Go ✤ Short history - Computer Go from the beginnings to AlphaGo ✤ The science behind AlphaGo ✤ The legacy of AlphaGo The Game of Go Go ✤ Classic two-player board game ✤ Invented in China thousands of years ago ✤ Simple rules, complex strategy ✤ Played by millions ✤ Hundreds of top experts - professional players ✤ Until 2016, computers weaker than humans Go Rules ✤ Start with empty board ✤ Place stone of your own color ✤ Goal: surround empty points or opponent - capture ✤ Win: control more than half the board Final score, 9x9 board ✤ Komi: first player advantage Measuring Go Strength ✤ People in Europe and America use the traditional Japanese ranking system ✤ Kyu (student) and Dan (master) levels ✤ Separate Dan ranks for professional players ✤ Kyu grades go down from 30 (absolute beginner) to 1 (best) ✤ Dan grades go up from 1 (weakest) to about 6 ✤ There is also a numerical (Elo) system, e.g. 2500 = 5 Dan Short History of Computer Go Computer Go History - Beginnings ✤ 1960’s: initial ideas, designs on paper ✤ 1970’s: first serious program - Reitman & Wilcox ✤ Interviews with strong human players ✤ Try to build a model of human decision-making ✤ Level: “advanced beginner”, 15-20 kyu ✤ One game costs thousands of dollars in computer time 1980-89 The Arrival of PC ✤ From 1980: PC (personal computers) arrive ✤ Many people get cheap access to computers ✤ Many start writing Go programs ✤ First competitions, Computer Olympiad, Ing Cup ✤ Level 10-15 kyu 1990-2005: Slow Progress ✤ Slow progress, commercial successes ✤ 1990 Ing Cup in Beijing ✤ 1993 Ing Cup in Chengdu ✤ Top programs Handtalk (Prof. -

Learning to Play the Game of Go
Learning to Play the Game of Go James Foulds October 17, 2006 Abstract The problem of creating a successful artificial intelligence game playing program for the game of Go represents an important milestone in the history of computer science, and provides an interesting domain for the development of both new and existing problem-solving methods. In particular, the problem of Go can be used as a benchmark for machine learning techniques. Most commercial Go playing programs use rule-based expert systems, re- lying heavily on manually entered domain knowledge. Due to the complexity of strategy possible in the game, these programs can only play at an amateur level of skill. A more recent approach is to apply machine learning to the prob- lem. Machine learning-based Go playing systems are currently weaker than the rule-based programs, but this is still an active area of research. This project compares the performance of an extensive set of supervised machine learning algorithms in the context of learning from a set of features generated from the common fate graph – a graph representation of a Go playing board. The method is applied to a collection of life-and-death problems and to 9 × 9 games, using a variety of learning algorithms. A comparative study is performed to determine the effectiveness of each learning algorithm in this context. Contents 1 Introduction 4 2 Background 4 2.1 Go................................... 4 2.1.1 DescriptionoftheGame. 5 2.1.2 TheHistoryofGo ...................... 6 2.1.3 Elementary Strategy . 7 2.1.4 Player Rankings and Handicaps . 7 2.1.5 Tsumego .......................... -

Go Books Detail
Evanston Go Club Ian Feldman Lending Library A Compendium of Trick Plays Nihon Ki-in In this unique anthology, the reader will find the subject of trick plays in the game of go dealt with in a thorough manner. Practically anything one could wish to know about the subject is examined from multiple perpectives in this remarkable volume. Vital points in common patterns, skillful finesse (tesuji) and ordinary matters of good technique are discussed, as well as the pitfalls that are concealed in seemingly innocuous positions. This is a gem of a handbook that belongs on the bookshelf of every go player. Chapter 1 was written by Ishida Yoshio, former Meijin-Honinbo, who intimates that if "joseki can be said to be the highway, trick plays may be called a back alley. When one masters the alleyways, one is on course to master joseki." Thirty-five model trick plays are presented in this chapter, #204 and exhaustively analyzed in the style of a dictionary. Kageyama Toshiro 7 dan, one of the most popular go writers, examines the subject in Chapter 2 from the standpoint of full board strategy. Chapter 3 is written by Mihori Sho, who collaborated with Sakata Eio to produce Killer of Go. Anecdotes from the history of go, famous sayings by Sun Tzu on the Art of Warfare and contemporary examples of trickery are woven together to produce an entertaining dialogue. The final chapter presents twenty-five problems for the reader to solve, using the knowledge gained in the preceding sections. Do not be surprised to find unexpected booby traps lurking here also. -

The Way to Go Is a Copyrighted Work
E R I C M A N A G F O O N How to U I O N D A T www.usgo.org www.agfgo.org play the Asian game of Go The Way to by Karl Baker American Go Association Box 397 Old Chelsea Station New York, NY 10113 GO Legal Note: The Way To Go is a copyrighted work. Permission is granted to make complete copies for personal use. Copies may be distributed freely to others either in print or electronic form, provided no fee is charged for distribution and all copies contain this copyright notice. The Way to Go by Karl Baker American Go Association Box 397 Old Chelsea Station New York, NY 10113 http://www.usgo.org Cover print: Two Immortals and the Woodcutter A watercolor by Seikan. Date unknown. How to play A scene from the Ranka tale: Immortals playing go as the the ancient/modern woodcutter looks on. From Japanese Prints and the World of Go by William Pinckard at: Asian Game of Go http://www.kiseido.com/printss/cover.htm Dedicated to Ann All in good time there will come a climax which will lift one to the heights, but first a foundation must be laid, INSPIRED BY HUNDREDS broad, deep and solid... OF BAFFLED STUDENTS Winfred Ernest Garrison © Copyright 1986, 2008 Preface American Go Association The game of GO is the essence of simplicity and the ultimate in complexity all at the same time. It is taught earnestly at military officer training schools in the Orient, as an exercise in military strategy. -

Strategic Choices: Small Budgets and Simple Regret Cheng-Wei Chou, Ping-Chiang Chou, Chang-Shing Lee, David L
Strategic Choices: Small Budgets and Simple Regret Cheng-Wei Chou, Ping-Chiang Chou, Chang-Shing Lee, David L. Saint-Pierre, Olivier Teytaud, Mei-Hui Wang, Li-Wen Wu, Shi-Jim Yen To cite this version: Cheng-Wei Chou, Ping-Chiang Chou, Chang-Shing Lee, David L. Saint-Pierre, Olivier Teytaud, et al.. Strategic Choices: Small Budgets and Simple Regret. TAAI, 2012, Hualien, Taiwan. hal-00753145v1 HAL Id: hal-00753145 https://hal.inria.fr/hal-00753145v1 Submitted on 19 Nov 2012 (v1), last revised 18 Mar 2013 (v2) HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Strategic Choices: Small Budgets and Simple Regret Cheng-Wei Chou 1, Ping-Chiang Chou, Chang-Shing Lee 2, David Lupien Saint-Pierre 3, Olivier Teytaud 4, Mei-Hui Wang 2, Li-Wen Wu 2 and Shi-Jim Yen 2 1Dept. of Computer Science and Information Engineering NDHU, Hualian, Taiwan 2Dept. of Computer Science and Information Engineering National University of Tainan, Taiwan 3Montefiore Institute Universit´ede Li`ege, Belgium 4TAO (Inria), LRI, UMR 8623(CNRS - Univ. Paris-Sud) bat 490 Univ. Paris-Sud 91405 Orsay, France November 17, 2012 Abstract In many decision problems, there are two levels of choice: The first one is strategic and the second is tactical. -
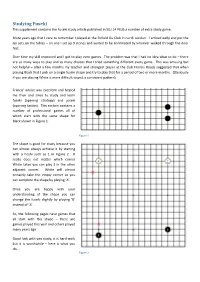
Fuseki Study Article Published in SGJ 14 PLUS a Number of Extra Study Game
Studying Fuseki This supplement contains the Fuseki study article published in SGJ 14 PLUS a number of extra study game. More years ago that I care to remember I played at the Enfield Go Club in north London. I arrived early and put the Go sets on the tables – on one I set up 9 stones and waited to be annihilated by whoever walked through the door first. Over time my skill improved and I got to play even games. The problem was that I had no idea what to do – there are so many ways to play and so many choices that I tried something different every game. This was amusing but not helpful – after a few months my teacher and strongest player at the club Francis Roads suggested that when playing Black that I pick on a single fuseki shape and try to play that for a period of two or more months. (Obviously if you are playing White is more difficult to pick a consistent pattern). Francis’ advise was excellent and helped me then and since to study and learn fuseki (opening strategy) and joseki (opening tactics). This section contains a number of professional games all of which start with the same shape for Black shown in Figure 1. Figure 1 The shape is good for study because you can almost always achieve it by starting with a hoshi such as 1 in Figure 2. It really does not matter which corner White takes you can play 3 in the other adjacent corner. White will almost certainly take the empty corner so you can complete the shape by playing ‘A’. -

Complementing, Not Competing
Complementing, Not Competing An Ethnographic Study of the Internet and American Go Communities Drew Harry Sean Munson May 2005 Culture, Knowledge, and Creativity 2 Table of Contents Table of Contents ........................................................................................................................................... 2 Introduction..................................................................................................................................................... 4 Background and Context ............................................................................................................................ 6 Introduction to Go ......................................................................................................................................... 7 The Massachusetts Go Association.............................................................................................................. 9 Internet Go.................................................................................................................................................... 10 Research Methods........................................................................................................................................13 Interview Profiles......................................................................................................................................... 14 Interview Analysis...................................................................................................................................... -

On Competency of Go Players: a Computational Approach
On Competency of Go Players: A Computational Approach Amr Ahmed Sabry Abdel-Rahman Ghoneim B.Sc. (Computer Science & Information Systems) Helwan University, Cairo - Egypt M.Sc. (Computer Science) Helwan University, Cairo - Egypt A thesis submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at the School of Engineering & Information Technology the University of New South Wales at the Australian Defence Force Academy March 2012 ii [This Page is Intentionally Left Blank] iii Abstract Abstract Complex situations are very much context dependent, thus agents – whether human or artificial – need to attain an awareness based on their present situation. An essential part of that awareness is the accurate and effective perception and understanding of the set of knowledge, skills, and characteristics that are needed to allow an agent to perform a specific task with high performance, or what we would like to name, Competency Awareness. The development of this awareness is essential for any further development of an agent’s capabilities. This can be assisted by identifying the limitations in the so far developed expertise and consequently engaging in training processes that add the necessary knowledge to overcome those limitations. However, current approaches of competency and situation awareness rely on manual, lengthy, subjective, and intrusive techniques, rendering those approaches as extremely troublesome and ineffective when it comes to developing computerized agents within complex scenarios. Within the context of computer Go, which is currently a grand challenge to Artificial Intelligence, these issues have led to substantial bottlenecks that need to be addressed in order to achieve further improvements. -

9 8 7 6 5 4 2 3 a 4 7 6 1 2 5 3 C
H9 Note di Go CENNI DI TATTICA V - A I JOSEKI DI HANDICAP Dopo aver visto le nozioni di strategia riguardanti il gioco a handicap, vediamo ora alcuni Joseki. Iniziamo con il dire che, mentre un Joseki "normale" dà un risultato equo, un Joseki "di handicap" (specialmente ad alti handicap) dà un risultato migliore per il Nero. Questo perchè il risultato del Joseki va aggiunto alla precedente influenza nera. Si studiano i Joseki per due motivi fondamentali: primo perchè lo studiarli è il primo passo verso la comprensione del Fuseki e perciò del miglioramento in generale; secondo perchè conoscere i Joseki vuol dire "punire" le mosse bianche abusive. Come si studia un Joseki? Il Joseki per definizione è una sequenza di mosse che come risultato dà una spartizione equa delle variabili territorio/influenza tra i due giocatori nel contesto locale, ne consegue che se uno dei due giocatori opta per un Tenuki o gioca diversamente ottiene localmente un risultato peggiore, sempre che l’avversario sappia come trarne vantaggio. Vorrei far notare che ciò che ho affermato è vero per definizione perchè‚ se ci fosse una sequenza che desse un risultato migliore per uno dei due giocatori non parleremmo di Joseki. Nella mia esposizione inizierò con il dare l’intera sequenza commentandola. Fatto ciò esaminerò le possibili variazioni da tale schema, analizzando i motivi ed i risultati di tali variazioni. Nell’analisi qui fatta ho considerato partite e sequenze ad alti handicap. Partite in cui il Nero parte in una situazione di forte predominio dove può tralasciare un analisi "puntuale" del Fuseki e concentrarsi esclusivamente sull’attacco locale. -

Adaptive Neural Network Usage in Computer Go
Adaptive Neural Network Usage in Computer Go A Major Qualifying Project Report: Submitted to the Faculty Of the WORCESTER POLYTECHNIC INSTITUTE In partial fulfillment of the requirements for the Degree of Bachelor of Science by Alexi Kessler Ian Shusdock Date: Approved: ___________________________________ Prof. Gabor Sarkozy, Major Advisor 1 Abstract For decades, computer scientists have worked to develop an artificial intelligence for the game of Go intelligent enough to beat skilled human players. In 2016, Google accomplished just that with their program, AlphaGo. AlphaGo was a huge leap forward in artificial intelligence, but required quite a lot of computational power to run. The goal of our project was to take some of the techniques that make AlphaGo so powerful, and integrate them with a less resource intensive artificial intelligence. Specifically, we expanded on the work of last year’s MQP of integrating a neural network into an existing Go AI, Pachi. We rigorously tested the resultant program’s performance. We also used SPSA training to determine an adaptive value function so as to make the best use of the neural network. 2 Table of Contents Abstract 2 Table of Contents 3 Acknowledgements 4 1. Introduction 5 1.1 - Artificial Players, Real Results 5 1.2 - Learning From AlphaGo 6 2. Background 8 2.1 - The Game Of Go 8 2.1.1 - Introduction 8 2.1.2 - Rules 9 2.1.3 - Ranking 11 2.1.4 - Why Study Go? 12 2.2. Existing Techniques 13 2.2.1 - Monte Carlo Tree Search 13 2.2.2 - Deep Convolutional Neural Networks 18 2.2.3 - Alpha Go 22 2.2.4 - Pachi with Neural Network 24 3.