A Reference Database for the 23S Rrna Gene of Eukaryotic
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

First Record of Marine Phytoplankton, Picochlorum Maculatum in the Southeastern Coast of India
Indian Journal of Geo Marine Sciences Vol. 46 (04), April 2017, pp. 791-796 First record of marine phytoplankton, Picochlorum maculatum in the Southeastern coast of India Dinesh Kumar, S1. S. Ananth1, P. Santhanam1*, K. Kaleshkumar2 & R. Rajaram2 1Marine Planktonology & Aquaculture Lab., 2DNA Barcoding and Marine Genomics Lab., Department of Marine Science, School of Marine Sciences, Bharathidasan University, Tiruchirappalli- 620 024, Tamil Nadu, India. * [E-mail: [email protected], [email protected]] Received 20 October 2014 ; revised 02 January 2015 The marine phytoplankton Picochlorum maculatum (Chlorophyta:Trebouxiophyceae) is recorded for the first time in the Southeastern coast of India. In this study, marine phytoplankton were collected at Muthukkuda mangrove waters, Tamil Nadu, Southeast coast of India which was then isolated, purified and identified with rDNA sequencing. Recurrence component analysis of marine phytoplankton P. maculatum indicated that the peptides were composed of Beta structure, comprising alpha-helix, extended strand and random coil. The number of amino acids and chemical properties from the marine microalgae P. maculatum are calculated and having composition of Neutral (82.69%), Acidic (10.72%) and Basic (6.57%) amino acids. This species may be introduced by way of shipping and other transport mechanisms where organisms are inadvertently moved out of their home range, e.g., ballast water exchange. [Keywords: Microalgae, Picochlorum maculatum, Genetic Distance, Open Reading Frame, Poly A signals] Introduction The genus Picochlorum maculatum was in Indian coastal waters. There are five Picochlorum established by Henley et. al.1 based on Nannochloris were reported in species level from Japan maculta Butcher, 1952. The currently accepted name (Picochlorum atomus, Picochlorum eukaryotum, P. -

Red Algae (Bangia Atropurpurea) Ecological Risk Screening Summary
Red Algae (Bangia atropurpurea) Ecological Risk Screening Summary U.S. Fish & Wildlife Service, February 2014 Revised, March 2016, September 2017, October 2017 Web Version, 6/25/2018 1 Native Range and Status in the United States Native Range From NOAA and USGS (2016): “Bangia atropurpurea has a widespread amphi-Atlantic range, which includes the Atlantic coast of North America […]” Status in the United States From Mills et al. (1991): “This filamentous red alga native to the Atlantic Coast was observed in Lake Erie in 1964 (Lin and Blum 1977). After this sighting, records for Lake Ontario (Damann 1979), Lake Michigan (Weik 1977), Lake Simcoe (Jackson 1985) and Lake Huron (Sheath 1987) were reported. It has become a major species of the littoral flora of these lakes, generally occupying the littoral zone with Cladophora and Ulothrix (Blum 1982). Earliest records of this algae in the basin, however, go back to the 1940s when Smith and Moyle (1944) found the alga in Lake Superior tributaries. Matthews (1932) found the alga in Quaker Run in the Allegheny drainage basin. Smith and 1 Moyle’s records must have not resulted in spreading populations since the alga was not known in Lake Superior as of 1987. Kishler and Taft (1970) were the most recent workers to refer to the records of Smith and Moyle (1944) and Matthews (1932).” From NOAA and USGS (2016): “Established where recorded except in Lake Superior. The distribution in Lake Simcoe is limited (Jackson 1985).” From Kipp et al. (2017): “Bangia atropurpurea was first recorded from Lake Erie in 1964. During the 1960s–1980s, it was recorded from Lake Huron, Lake Michigan, Lake Ontario, and Lake Simcoe (part of the Lake Ontario drainage). -

Seed Plant Models
Review Tansley insight Why we need more non-seed plant models Author for correspondence: Stefan A. Rensing1,2 Stefan A. Rensing 1 2 Tel: +49 6421 28 21940 Faculty of Biology, University of Marburg, Karl-von-Frisch-Str. 8, 35043 Marburg, Germany; BIOSS Biological Signalling Studies, Email: stefan.rensing@biologie. University of Freiburg, Sch€anzlestraße 18, 79104 Freiburg, Germany uni-marburg.de Received: 30 October 2016 Accepted: 18 December 2016 Contents Summary 1 V. What do we need? 4 I. Introduction 1 VI. Conclusions 5 II. Evo-devo: inference of how plants evolved 2 Acknowledgements 5 III. We need more diversity 2 References 5 IV. Genomes are necessary, but not sufficient 3 Summary New Phytologist (2017) Out of a hundred sequenced and published land plant genomes, four are not of flowering plants. doi: 10.1111/nph.14464 This severely skewed taxonomic sampling hinders our comprehension of land plant evolution at large. Moreover, most genetically accessible model species are flowering plants as well. If we are Key words: Charophyta, evolution, fern, to gain a deeper understanding of how plants evolved and still evolve, and which of their hornwort, liverwort, moss, Streptophyta. developmental patterns are ancestral or derived, we need to study a more diverse set of plants. Here, I thus argue that we need to sequence genomes of so far neglected lineages, and that we need to develop more non-seed plant model species. revealed much, the exact branching order and evolution of the I. Introduction nonbilaterian lineages is still disputed (Lanna, 2015). Research on animals has for a long time relied on a number of The first (small) plant genome to be sequenced was of THE traditional model organisms, such as mouse, fruit fly, zebrafish or model plant, the weed Arabidopsis thaliana (c. -

University of Oklahoma
UNIVERSITY OF OKLAHOMA GRADUATE COLLEGE MACRONUTRIENTS SHAPE MICROBIAL COMMUNITIES, GENE EXPRESSION AND PROTEIN EVOLUTION A DISSERTATION SUBMITTED TO THE GRADUATE FACULTY in partial fulfillment of the requirements for the Degree of DOCTOR OF PHILOSOPHY By JOSHUA THOMAS COOPER Norman, Oklahoma 2017 MACRONUTRIENTS SHAPE MICROBIAL COMMUNITIES, GENE EXPRESSION AND PROTEIN EVOLUTION A DISSERTATION APPROVED FOR THE DEPARTMENT OF MICROBIOLOGY AND PLANT BIOLOGY BY ______________________________ Dr. Boris Wawrik, Chair ______________________________ Dr. J. Phil Gibson ______________________________ Dr. Anne K. Dunn ______________________________ Dr. John Paul Masly ______________________________ Dr. K. David Hambright ii © Copyright by JOSHUA THOMAS COOPER 2017 All Rights Reserved. iii Acknowledgments I would like to thank my two advisors Dr. Boris Wawrik and Dr. J. Phil Gibson for helping me become a better scientist and better educator. I would also like to thank my committee members Dr. Anne K. Dunn, Dr. K. David Hambright, and Dr. J.P. Masly for providing valuable inputs that lead me to carefully consider my research questions. I would also like to thank Dr. J.P. Masly for the opportunity to coauthor a book chapter on the speciation of diatoms. It is still such a privilege that you believed in me and my crazy diatom ideas to form a concise chapter in addition to learn your style of writing has been a benefit to my professional development. I’m also thankful for my first undergraduate research mentor, Dr. Miriam Steinitz-Kannan, now retired from Northern Kentucky University, who was the first to show the amazing wonders of pond scum. Who knew that studying diatoms and algae as an undergraduate would lead me all the way to a Ph.D. -
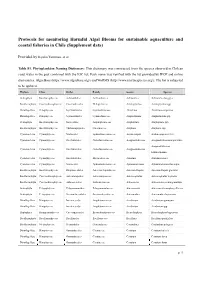
Protocols for Monitoring Harmful Algal Blooms for Sustainable Aquaculture and Coastal Fisheries in Chile (Supplement Data)
Protocols for monitoring Harmful Algal Blooms for sustainable aquaculture and coastal fisheries in Chile (Supplement data) Provided by Kyoko Yarimizu, et al. Table S1. Phytoplankton Naming Dictionary: This dictionary was constructed from the species observed in Chilean coast water in the past combined with the IOC list. Each name was verified with the list provided by IFOP and online dictionaries, AlgaeBase (https://www.algaebase.org/) and WoRMS (http://www.marinespecies.org/). The list is subjected to be updated. Phylum Class Order Family Genus Species Ochrophyta Bacillariophyceae Achnanthales Achnanthaceae Achnanthes Achnanthes longipes Bacillariophyta Coscinodiscophyceae Coscinodiscales Heliopeltaceae Actinoptychus Actinoptychus spp. Dinoflagellata Dinophyceae Gymnodiniales Gymnodiniaceae Akashiwo Akashiwo sanguinea Dinoflagellata Dinophyceae Gymnodiniales Gymnodiniaceae Amphidinium Amphidinium spp. Ochrophyta Bacillariophyceae Naviculales Amphipleuraceae Amphiprora Amphiprora spp. Bacillariophyta Bacillariophyceae Thalassiophysales Catenulaceae Amphora Amphora spp. Cyanobacteria Cyanophyceae Nostocales Aphanizomenonaceae Anabaenopsis Anabaenopsis milleri Cyanobacteria Cyanophyceae Oscillatoriales Coleofasciculaceae Anagnostidinema Anagnostidinema amphibium Anagnostidinema Cyanobacteria Cyanophyceae Oscillatoriales Coleofasciculaceae Anagnostidinema lemmermannii Cyanobacteria Cyanophyceae Oscillatoriales Microcoleaceae Annamia Annamia toxica Cyanobacteria Cyanophyceae Nostocales Aphanizomenonaceae Aphanizomenon Aphanizomenon flos-aquae -

Phylogenetic Placement of Botryococcus Braunii (Trebouxiophyceae) and Botryococcus Sudeticus Isolate Utex 2629 (Chlorophyceae)1
J. Phycol. 40, 412–423 (2004) r 2004 Phycological Society of America DOI: 10.1046/j.1529-8817.2004.03173.x PHYLOGENETIC PLACEMENT OF BOTRYOCOCCUS BRAUNII (TREBOUXIOPHYCEAE) AND BOTRYOCOCCUS SUDETICUS ISOLATE UTEX 2629 (CHLOROPHYCEAE)1 Hoda H. Senousy, Gordon W. Beakes, and Ethan Hack2 School of Biology, University of Newcastle upon Tyne, Newcastle upon Tyne NE1 7RU, UK The phylogenetic placement of four isolates of a potential source of renewable energy in the form of Botryococcus braunii Ku¨tzing and of Botryococcus hydrocarbon fuels (Metzger et al. 1991, Metzger and sudeticus Lemmermann isolate UTEX 2629 was Largeau 1999, Banerjee et al. 2002). The best known investigated using sequences of the nuclear small species is Botryococcus braunii Ku¨tzing. This organism subunit (18S) rRNA gene. The B. braunii isolates has a worldwide distribution in fresh and brackish represent the A (two isolates), B, and L chemical water and is occasionally found in salt water. Although races. One isolate of B. braunii (CCAP 807/1; A race) it grows relatively slowly, it sometimes forms massive has a group I intron at Escherichia coli position 1046 blooms (Metzger et al. 1991, Tyson 1995). Botryococcus and isolate UTEX 2629 has group I introns at E. coli braunii strains differ in the hydrocarbons that they positions 516 and 1512. The rRNA sequences were accumulate, and they have been classified into three aligned with 53 previously reported rRNA se- chemical races, called A, B, and L. Strains in the A race quences from members of the Chlorophyta, includ- accumulate alkadienes; strains in the B race accumulate ing one reported for B. -

2019 Project Peer Review
Functional Characterization of Cellular Metabolism U.S. Department of Energy (DOE) Bioenergy Technologies Office (BETO) 2019 Project Peer Review Advanced Algal Systems Scott Twary March 5, 2019 This presentation does not contain any proprietary, confidential, or otherwise restricted information Managed by Triad National Security, LLC for the U.S. Department of Energy’s NNSA LA-UR-19-20466 Goal Statement Goal Design an integrated strain improvement platform utilizing environmental, epigenetic, and genetic factors for targeted advances with rapid, comprehensive phenotyping leading to greater understanding of these modifications. Outcomes & Relevance Define the genetic pathway regulating nitrogen (N) sensing and signaling to produce an improved algae line with faster production due to rapid N assimilation and potentially uncouple N stress induction of lipid accumulation. Novel capability development • Integrated strain improvement strategy • Expanded suite of flow cytometry physiological assays • CRISPR/Cas genome engineering toolbox for Nannochloropsis salina • Epigenetic profiling and specific gene responses to environmental stress • EpiEffector modification and regulation of genome Los Alamos National Laboratory 3/05/19 | 2 Quad Chart Overview Barriers addressed Timeline: Ongoing Project Aft‐C. Biomass Genetics and • Current merit review period: Development: • October 1, 2017-September 30, 2020 • 33% complete Creation of novel integrated strain improvement methods and new tool applications. Total FY 17 FY 18 Total Costs Pre Costs Costs Planned Objective FY17** Funding (FY 19-Project To integrate flow cytometry, End Date) epigenome regulation, and genome engineering for elucidation of N DOE 2,200 K 650 K 1,100 K 1,334 K stress sensing and signaling and Funded application towards novel line improvement strategies Project Cost N/A End of Project Goal Share* An improved algae line with increased productivity over 30% of baseline. -

Seasonal and Interannual Changes in Ciliate and Dinoflagellate
ORIGINAL RESEARCH published: 07 February 2017 doi: 10.3389/fmars.2017.00016 Seasonal and Interannual Changes in Ciliate and Dinoflagellate Species Assemblages in the Arctic Ocean (Amundsen Gulf, Beaufort Sea, Canada) Edited by: Deo F. L. Onda 1, 2, 3, Emmanuelle Medrinal 1, 3, André M. Comeau 1, 3 †, Mary Thaler 1, 2, 3, George S. Bullerjahn, Marcel Babin 1, 2 and Connie Lovejoy 1, 2, 3* Bowling Green State University, USA Reviewed by: 1 Département de Biologie and Québec-Océan, Université Laval, Quebec, QC, Canada, 2 Takuvik, Joint International Rebecca Gast, Laboratory, UMI 3376, Centre National de la Recherche Scientifique (CNRS, France) and Université Laval, Québec, QC, Woods Hole Oceanographic Canada, 3 Institut de Biologie Intégrative et des Systèmes, Université Laval, Quebec, QC, Canada Institution, USA Alison Clare Cleary, Independent Researcher, San Recent studies have focused on how climate change could drive changes in Francisco, United States phytoplankton communities in the Arctic. In contrast, ciliates and dinoflagellates that can *Correspondence: contribute substantially to the mortality of phytoplankton have received less attention. Connie Lovejoy Some dinoflagellate and ciliate species can also contribute to net photosynthesis, [email protected] which suggests that species composition could reflect food web complexity. To identify †Present Address: André M. Comeau, potential seasonal and annual species occurrence patterns and to link species with Centre for Comparative Genomics and environmental conditions, we first examined the seasonal pattern of microzooplankton Evolutionary Bioinformatics-Integrated Microbiome Resource, Department of and then performed an in-depth analysis of interannual species variability. We used Pharmacology, Dalhousie University, high-throughput amplicon sequencing to identify ciliates and dinoflagellates to the lowest Canada taxonomic level using a curated Arctic 18S rRNA gene database. -

Introduction to Botany. Lecture 31
Questions and answers Kingdom Vegetabilia: plants Introduction to Botany. Lecture 31 Alexey Shipunov Minot State University November 16, 2011 Shipunov BIOL 154.31 Questions and answers Kingdom Vegetabilia: plants Outline 1 Questions and answers 2 Kingdom Vegetabilia: plants Bryophyta: mosses Shipunov BIOL 154.31 Questions and answers Kingdom Vegetabilia: plants Outline 1 Questions and answers 2 Kingdom Vegetabilia: plants Bryophyta: mosses Shipunov BIOL 154.31 2 Questions and answers Kingdom Vegetabilia: plants Previous final question: the answer 1 Arabidopsis thaliana (L.) Heynh 2 Citrus 3 Piperaceae Where is a genus name? Shipunov BIOL 154.31 Questions and answers Kingdom Vegetabilia: plants Previous final question: the answer 1 Arabidopsis thaliana (L.) Heynh 2 Citrus 3 Piperaceae Where is a genus name? 2 Shipunov BIOL 154.31 Questions and answers Kingdom Vegetabilia: plants Results of Exam 3 (statistical summary) Summary: Min. 1st Qu. Median Mean 3rd Qu. Max. NA’s 43.00 67.00 79.00 78.36 92.00 108.00 5.00 Grades: F D C B max 61 72 82 92 102 Shipunov BIOL 154.31 Questions and answers Kingdom Vegetabilia: plants Results of Exam 3 (the curve) Density estimation for Exam 3 (Biol 154) 61 92 (F) (B) Points Shipunov BIOL 154.31 Questions and answers Bryophyta: mosses Kingdom Vegetabilia: plants Kingdom Vegetabilia: plants Bryophyta: mosses Shipunov BIOL 154.31 Questions and answers Bryophyta: mosses Kingdom Vegetabilia: plants Three main phyla Bryophyta: gametophyte predominance Pteridophyta: sporophyte predominance, no seed Spermatophyta: -

Transcriptional Landscapes of Lipid Producing Microalgae Benoît M
Transcriptional landscapes of lipid producing microalgae Benoît M. Carrères 2019 Transcriptional landscapes of lipid producing microalgae Benoî[email protected]:~$ ▮ Transcriptional landscapes of lipid producing microalgae Benoît Manuel Carrères Thesis committee Promotors Prof. Dr Vitor A. P. Martins dos Santos Professor of Systems and Synthetic Biology Wageningen University & Research Prof. Dr René H. Wij$els Professor of Bioprocess Engineering Wageningen University & Research Co-promotors Dr Peter J. Schaa% Associate professor* Systems and Synthetic Biology Wageningen University & Research Dr Dirk E. Martens Associate professor* Bioprocess Engineering Wageningen University & Research ,ther mem-ers Prof. Dr Alison Smith* University of Cam-ridge Prof. Dr. Dic+ de Ridder* Wageningen University & Research Dr Aalt D.). van Di#+* Wageningen University & Research Dr Ga-ino Sanche/(Pere/* Genetwister* Wageningen This research 0as cond1cted under the auspices of the .rad1ate School V2A. 3Advanced studies in Food Technology* Agro-iotechnology* Nutrition and Health Sciences). Transcriptional landscapes of lipid producing microalgae Benoît Manuel Carrères Thesis su-mitted in ful8lment of the re9uirements for the degree of doctor at Wageningen University -y the authority of the Rector Magnificus, Prof. Dr A.P.). Mol* in the presence of the Thesis' ommittee a%%ointed by the Academic Board to be defended in pu-lic on Wednesday 2; Novem-er 2;<= at 1.>; p.m in the Aula. Benoît Manuel Carrères 5ranscriptional landsca%es of lipid producing -

Why the –Omic Future of Apicomplexa Should Include Gregarines Julie Boisard, Isabelle Florent
Why the –omic future of Apicomplexa should include Gregarines Julie Boisard, Isabelle Florent To cite this version: Julie Boisard, Isabelle Florent. Why the –omic future of Apicomplexa should include Gregarines. Biology of the Cell, Wiley, 2020, 10.1111/boc.202000006. hal-02553206 HAL Id: hal-02553206 https://hal.archives-ouvertes.fr/hal-02553206 Submitted on 24 Apr 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Article title: Why the –omic future of Apicomplexa should include Gregarines. Names of authors: Julie BOISARD1,2 and Isabelle FLORENT1 Authors affiliations: 1. Molécules de Communication et Adaptation des Microorganismes (MCAM, UMR 7245), Département Adaptations du Vivant (AVIV), Muséum National d’Histoire Naturelle, CNRS, CP52, 57 rue Cuvier 75231 Paris Cedex 05, France. 2. Structure et instabilité des génomes (STRING UMR 7196 CNRS / INSERM U1154), Département Adaptations du vivant (AVIV), Muséum National d'Histoire Naturelle, CP 26, 57 rue Cuvier 75231 Paris Cedex 05, France. Short Title: Gregarines –omics for Apicomplexa studies -

Altitudinal Zonation of Green Algae Biodiversity in the French Alps
Altitudinal Zonation of Green Algae Biodiversity in the French Alps Adeline Stewart, Delphine Rioux, Fréderic Boyer, Ludovic Gielly, François Pompanon, Amélie Saillard, Wilfried Thuiller, Jean-Gabriel Valay, Eric Marechal, Eric Coissac To cite this version: Adeline Stewart, Delphine Rioux, Fréderic Boyer, Ludovic Gielly, François Pompanon, et al.. Altitu- dinal Zonation of Green Algae Biodiversity in the French Alps. Frontiers in Plant Science, Frontiers, 2021, 12, pp.679428. 10.3389/fpls.2021.679428. hal-03258608 HAL Id: hal-03258608 https://hal.archives-ouvertes.fr/hal-03258608 Submitted on 11 Jun 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. fpls-12-679428 June 4, 2021 Time: 14:28 # 1 ORIGINAL RESEARCH published: 07 June 2021 doi: 10.3389/fpls.2021.679428 Altitudinal Zonation of Green Algae Biodiversity in the French Alps Adeline Stewart1,2,3, Delphine Rioux3, Fréderic Boyer3, Ludovic Gielly3, François Pompanon3, Amélie Saillard3, Wilfried Thuiller3, Jean-Gabriel Valay2, Eric Maréchal1* and Eric Coissac3* on behalf of The ORCHAMP Consortium 1 Laboratoire de Physiologie Cellulaire et Végétale, CEA, CNRS, INRAE, IRIG, Université Grenoble Alpes, Grenoble, France, 2 Jardin du Lautaret, CNRS, Université Grenoble Alpes, Grenoble, France, 3 Université Grenoble Alpes, Université Savoie Mont Blanc, CNRS, LECA, Grenoble, France Mountain environments are marked by an altitudinal zonation of habitat types.