TH`ESE DE DOCTORAT Software Engineering Techniques For
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Automating Testing with Autofixture, Xunit.Net & Specflow
Design Patterns Michael Heitland Oct 2015 Creational Patterns • Abstract Factory • Builder • Factory Method • Object Pool* • Prototype • Simple Factory* • Singleton (* this pattern got added later by others) Structural Patterns ● Adapter ● Bridge ● Composite ● Decorator ● Facade ● Flyweight ● Proxy Behavioural Patterns 1 ● Chain of Responsibility ● Command ● Interpreter ● Iterator ● Mediator ● Memento Behavioural Patterns 2 ● Null Object * ● Observer ● State ● Strategy ● Template Method ● Visitor Initial Acronym Concept Single responsibility principle: A class should have only a single responsibility (i.e. only one potential change in the S SRP software's specification should be able to affect the specification of the class) Open/closed principle: “Software entities … should be open O OCP for extension, but closed for modification.” Liskov substitution principle: “Objects in a program should be L LSP replaceable with instances of their subtypes without altering the correctness of that program.” See also design by contract. Interface segregation principle: “Many client-specific I ISP interfaces are better than one general-purpose interface.”[8] Dependency inversion principle: One should “Depend upon D DIP Abstractions. Do not depend upon concretions.”[8] Creational Patterns Simple Factory* Encapsulating object creation. Clients will use object interfaces. Abstract Factory Provide an interface for creating families of related or dependent objects without specifying their concrete classes. Inject the factory into the object. Dependency Inversion Principle Depend upon abstractions. Do not depend upon concrete classes. Our high-level components should not depend on our low-level components; rather, they should both depend on abstractions. Builder Separate the construction of a complex object from its implementation so that the two can vary independently. The same construction process can create different representations. -

(MVC) Design Pattern Untuk Aplikasi Perangkat Bergerak Berbasis Java
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Diponegoro University Institutional Repository Model-View-Controller (MVC) Design Pattern Untuk Aplikasi Perangkat Bergerak Berbasis Java Panji Wisnu Wirawan Program Studi Teknik Informatika, Universitas Diponegoro [email protected] Abstrak Design pattern merupakan salah satu teknik mendesain komponen perangkat lunak yang bisa digunakan kembali. MVC design pattern merupakan design pattern untuk komponen perangkat lunak yang memisahkan secara tegas antara model data, tampilan, dan kendali perangkat lunak. Artikel ini akan membahas MVC design pattern disertai kesesuaiannya dengan aplikasi perangkat bergerak berbasis Java. Bagian akhir artikel ini menunjukkan bagaimana MVC design pattern untuk aplikasi bergerak berbasis Java. Kata Kunci : MVC, design pattern , aplikasi perangkat bergerak berbasis Java ulang sehingga dapat meminimalkan usaha 1. Pendahuluan pengembangan aplikasi perangkat bergerak. Pada umumnya, aplikasi perangkat bergerak menggunakan Komponen perangkat lunak sudah semestinya GUI. Penggunaan MVC diharapkan bermanfaat untuk didesain dan diimplementasikan sehingga bisa pembuatan komponen perangkat lunak untuk aplikasi digunakan ulang ( reused ) pada perangkat lunak yang bergerak yang bisa digunakan ulang. [6] lain . Sebagai contoh penggunaan komponen perangkat lunak yang dapat digunakan ulang adalah Salah satu penelitian mengenai design pattern penggunaan text box , drop down menu dan untuk aplikasi perangkat bergerak berbasis Java telah sebagainya. dilakukan oleh Narsoo dan Mohamudally (2008). Narsoo dan Mohamudally (2008) melakukan Contoh lain dari komponen perangkat lunak identifikasi design pattern untuk mobile services adalah pola-pola tertentu untuk menyelesaikan menggunakan Java 2 Mobile Edition (J2ME). Mobile masalah yang disebut sebagai design pattern . Pola- services tersebut termasuk dalam behavioral pattern pola tersebut akan tetap sama untuk aplikasi yang yaitu add , edit , erase dan search . -

Principles of Programming Languages
David Liu Principles of Programming Languages Lecture Notes for CSC324 (Version 2.1) Department of Computer Science University of Toronto principles of programming languages 3 Many thanks to Alexander Biggs, Peter Chen, Rohan Das, Ozan Erdem, Itai David Hass, Hengwei Guo, Kasra Kyanzadeh, Jasmin Lantos, Jason Mai, Sina Rezaeizadeh, Ian Stewart-Binks, Ivan Topolcic, Anthony Vandikas, Lisa Zhang, and many anonymous students for their helpful comments and error-spotting in earlier versions of these notes. Dan Zingaro made substantial contributions to this version of the notes. Contents Prelude: The Study of Programming Languages 7 Programs and programming languages 7 Models of computation 11 A paradigm shift in you 14 Course overview 15 1 Functional Programming: Theory and Practice 17 The baseline: “universal” built-ins 18 Function expressions 18 Function application 19 Function purity 21 Name bindings 22 Lists and structural recursion 26 Pattern-matching 28 Higher-order functions 35 Programming with abstract syntax trees 42 Undefined programs and evaluation order 44 Lexical closures 50 Summary 56 6 david liu 2 Macros, Objects, and Backtracking 57 Object-oriented programming: a re-introduction 58 Pattern-based macros 61 Objects revisited 74 The problem of self 78 Manipulating control flow I: streams 83 Manipulating control flow II: the ambiguous operator -< 87 Continuations 90 Using continuations in -< 93 Using choices as subexpressions 94 Branching choices 98 Towards declarative programming 101 3 Type systems 109 Describing type systems 110 -

Resilience Design Patterns a Structured Approach to Resilience at Extreme Scale - Version 1.0
ORNL/TM-2016/687 Resilience Design Patterns A Structured Approach to Resilience at Extreme Scale - version 1.0 Saurabh Hukerikar Christian Engelmann Approved for public release. October 2016 Distribution is unlimited. DOCUMENT AVAILABILITY Reports produced after January 1, 1996, are generally available free via US Department of Energy (DOE) SciTech Connect. Website: http://www.osti.gov/scitech/ Reports produced before January 1, 1996, may be purchased by members of the public from the following source: National Technical Information Service 5285 Port Royal Road Springfield, VA 22161 Telephone: 703-605-6000 (1-800-553-6847) TDD: 703-487-4639 Fax: 703-605-6900 E-mail: [email protected] Website: http://classic.ntis.gov/ Reports are available to DOE employees, DOE contractors, Energy Technology Data Ex- change representatives, and International Nuclear Information System representatives from the following source: Office of Scientific and Technical Information PO Box 62 Oak Ridge, TN 37831 Telephone: 865-576-8401 Fax: 865-576-5728 E-mail: [email protected] Website: http://www.osti.gov/contact.html This report was prepared as an account of work sponsored by an agency of the United States Government. Neither the United States Government nor any agency thereof, nor any of their employees, makes any warranty, express or implied, or assumes any legal lia- bility or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or rep- resents that its use would not infringe privately owned rights. Refer- ence herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise, does not nec- essarily constitute or imply its endorsement, recommendation, or fa- voring by the United States Government or any agency thereof. -
Design Pattern- Structural Pattern 2015
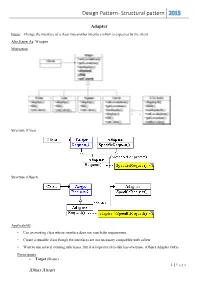
Design Pattern- Structural pattern 2015 Adapter Intent: Change the interface of a class into another interface which is expected by the client. Also Know As: Wrapper Motivation Structure (Class) Structure (Object) Applicability • Use an existing class whose interface does not match the requirement • Create a reusable class though the interfaces are not necessary compatible with callers • Want to use several existing subclasses, but it is impractical to subclass everyone. (Object Adapter Only) Participants Target (Shape) 1 | P a g e Almas Ansari Design Pattern- Structural pattern 2015 defines the domain-specific interface that Client uses. Client (DrawingEditor) collaborates with objects conforming to the Target interface. Adaptee (TextView) defines an existing interface that needs adapting. Adapter (TextShape) adapts the interface of Adaptee to the Target interface. Collaborations Clients call operations on an Adapter instance. In turn, the adapter calls Adaptee operations that carry out the request. Consequences Here are other issues to consider when using the Adapter pattern: 1. How much adapting does Adapter do? Adapters vary in the amount of work they do to adapt Adaptee to the Target interface. 2. Pluggable adapters. A class is more reusable when you minimize the assumptions other classes must make to use it. 3. Using two-way adapters to provide transparency. A potential problem with adapters is that they aren't transparent to all clients. Implementation 1. Implementing class adapters in C++. In a C++ implementation of a class adapter, Adapter would inherit publicly from Target and privately from Adaptee. Thus Adapter would be a subtype of Target but not of Adaptee. 2. -

UNIT-I TUTORIAL QUESTIONS 1. Explain the Concept of Design Pattern? 2
UNIT-I TUTORIAL QUESTIONS 1. Explain the concept of design pattern? 2. Explain the advantages and disadvantages of structural patterns? 3. Explain proxy design pattern in detail? 4. Explain the concept of design pattern relationship? 5. Explain the state pattern in detail? UNIT-I UNIVERSITY QUESTIONS 1. Explain the template of a design pattern? 2. Explain the state pattern in detail? 3. Explain proxy design pattern in detail? 4. Explain the features of structural pattern? 5. Explain the concept of design pattern relationship? UNIT-I DESCRIPTIVE QUESTIONS 1. Explain the template of a design pattern? 2. Explain the state pattern in detail? 3. Explain proxy design pattern in detail? 4. Explain the features of structural pattern? 5. Explain the concept of design pattern relationship? UNIT-I ASSIGNMENT QUESTIONS 1. Explain the template of a design pattern? 2. Explain the state pattern in detail? 3. Explain proxy design pattern in detail? 4. Explain the features of structural pattern? 5. Explain the concept of design pattern relationship? UNIT-I OBJECTIVE QUESTIONS 1. A pattern in general refers to layout 2. A Design pattern can be considered as Reusable solution 3. The concept of design pattern was introduced by Christopher Alexander 4. Essential elements of D.P are Pattern Name,Problem,Solution,Consequences 5. Catalog consists of Abstract factory,Adapter,Bridge 6. Creation Patterns are Factory method, Builder, Prototype 7. Structural Patterns are Factory method, Builder, Prototype 8. Design Patterns specify Object implementation 9. Design Patterns specify Object Interfaces 10. Design Patterns specify Appropriate Objects UNIT-I SEMINAR TOPICS 1. Template of D.P 2. -

Java Design Patterns I
Java Design Patterns i Java Design Patterns Java Design Patterns ii Contents 1 Introduction to Design Patterns 1 1.1 Introduction......................................................1 1.2 What are Design Patterns...............................................1 1.3 Why use them.....................................................2 1.4 How to select and use one...............................................2 1.5 Categorization of patterns...............................................3 1.5.1 Creational patterns..............................................3 1.5.2 Structural patterns..............................................3 1.5.3 Behavior patterns...............................................3 2 Adapter Design Pattern 5 2.1 Adapter Pattern....................................................5 2.2 An Adapter to rescue.................................................6 2.3 Solution to the problem................................................7 2.4 Class Adapter..................................................... 11 2.5 When to use Adapter Pattern............................................. 12 2.6 Download the Source Code.............................................. 12 3 Facade Design Pattern 13 3.1 Introduction...................................................... 13 3.2 What is the Facade Pattern.............................................. 13 3.3 Solution to the problem................................................ 14 3.4 Use of the Facade Pattern............................................... 16 3.5 Download the Source Code............................................. -

Skin Vs. Guts: Introducing Design Patterns in the MIS Curriculum Elizabeth Towell and John Towell Carroll College, Waukesha, WI, USA
Journal of Information Technology Education Volume 1 No. 4, 2002 Skin vs. Guts: Introducing Design Patterns in the MIS Curriculum Elizabeth Towell and John Towell Carroll College, Waukesha, WI, USA [email protected] [email protected] Executive Summary Significant evidence suggests that there is increasing demand for information technology oriented stu- dents who have exposure to Object-Oriented (OO) methodologies and who have knowledge of the Uni- fied Modeling Language (UML). Object-oriented development has moved into the mainstream as the value of reusable program modules is becoming more evident. Building blocks such as software com- ponents and application frameworks allow organizations to bring products to market faster and to adapt to changes more quickly. When only one analysis and design course is required, the study of object-oriented analysis and design is often minimal or left out of the Management Information Systems curriculum. This paper argues for an increased emphasis on object-oriented techniques in the introductory Systems Analysis and Design course. Specifically, it provides guidance for faculty who are considering adding object-orientation to a systems analysis and design course where existing content leaves little time for new topics. In particular, the authors recommend the introduction of two successful, generalized design patterns in the context of adaptation of a software development framework. Where time is limited, coverage of such recurring software problems cannot be comprehensive so it is proposed that students explore two design patterns in depth as opposed to a cursory review of more patterns. Students must first learn or review the OO vocabulary including terms such as classes, inheritance, and aggregation so that the ap- propriate term can be used to discuss the UML relationships among the object model components. -

Security Pattern Validation and Recognition
Security-Pattern Recognition and Validation Dissertation Submitted by Michaela Bunke on 12th December 2018 to the Universit¨atBremen Faculty of Mathematics and Computer Science in partial fulfillment of the requirements for the degree of Doktor der Ingenieurwissenschaften { Dr.-Ing. { Reviewed by Prof. Dr. Hans-J¨orgKreowski Universit¨atBremen, Germany and Dr. Karsten Sohr Universit¨atBremen, Germany In Memorial of Ilse Schlamilch Karl Schlamilch Manfred Friedrichs 21 November 1924 03 March 1927 29 August 1935 09 June 2017 19 June 2018 3 July 2017 ABSTRACT The increasing and diverse number of technologies that are connected to the Internet, such as distributed enterprise systems or small electronic devices like smartphones, brings the topic IT security to the foreground. We interact daily with these technologies and spend much trust on a well-established software development process. However, security vulnerabilities appear in software on all kinds of PC(- like) platforms, and more and more vulnerabilities are published, which compromise systems and their users. Thus, software has also to be modified due to changing requirements, bugs, and security flaws and software engineers must more and more face security issues during the software design; especially maintenance programmers must deal with such use cases after a software has been released. In the domain of software development, design patterns have been proposed as the best-known solutions for recurring problems in software design. Analogously, security patterns are best practices aiming at ensuring security. This thesis develops a deeper understanding of the nature of security patterns. It focuses on their validation and detection regarding the support of reviews and maintenance activities. -

1. Difference Between Factory Pattern and Abstract Factory Pattern S.No
1. Difference between Factory Pattern and Abstract Factory Pattern S.No Factory Pattern Abstract Factory Pattern 1 Create object through inheritance Create object through composition 2 Produce only one product Produce families of products 3 Implements code in the abstract creator Concrete factories implements factory that make use of the concrete type that method to create product sub class produces 2.Difference between Abstract Factory Pattern And Builder Pattern S.No Builder Pattern Abstract Factory Pattern 1 In Builder Pattern, there will be one Abstract Factory Pattern will return the Director class which will instruct Builder instance directly. class to build the different parts/properties of our object and finally retrieve the object. 2 It will have reference to the created It does not keep the track of it's created object. object. 3.Difference between Builder Pattern And Composite Pattern S.No Builder Pattern Composite Pattern 1 It is used to create group of objects of It creates Parent - Child relations between predefined types. our objects. 4.Difference between MVC and MVP S.No MVP MVC 1 MVP is a bit more complex to MVC is easier to implement than MVP. implement than MVC .Also, it has additional layer for view interfaces. 2 The request is always received by the The request is received by the controller View and delegated to the presenter which in turn gets the required data and which in turn gets the data does the loads up the appropriate view processing 3 The presentation and view logic an be The controller logic can be unit tested. -

Design Pattern Detection and Software Architecture Reconstruction: an Integrated Approach Based on Software Micro-Structures
Università degli Studi di Milano-Bicocca Dipartimento di Informatica, Sistemistica e Comunicazione Dottorato di Ricerca in Informatica – XXII Ciclo Design Pattern Detection and Software Architecture Reconstruction: an Integrated Approach based on Software Micro-structures Ph.D. Candidate: Stefano Maggioni Thesis advisor: Prof. Francesca Arcelli Fontana Thesis tutor: Prof. Francesco Tisato Academic Year 2008-2009 Table of Contents Chapter 1 - Introduction.................................................................................................................. 6 1.1. The research field ........................................................................................................................................... 6 1.1.1. Design pattern detection (DPD) ....................................................................................................................... 7 1.1.2. Software architecture reconstruction (SAR) ................................................................................................... 10 1.2. A brief overview on software micro-structures for DPD and SAR ....................................................... 12 1.2.1. Elemental design patterns ............................................................................................................................... 13 1.2.2. Design pattern clues ....................................................................................................................................... 13 1.2.3. Micro patterns ................................................................................................................................................ -

Design Patterns Chapter 3
A Brief Introduction to Design Patterns Jerod Weinman Department of Computer Science Grinnell College [email protected] Contents 1 Introduction 2 2 Creational Design Patterns 4 2.1 Introduction ...................................... 4 2.2 Factory ........................................ 4 2.3 Abstract Factory .................................... 5 2.4 Singleton ....................................... 8 2.5 Builder ........................................ 8 3 Structural Design Patterns 10 3.1 Introduction ...................................... 10 3.2 Adapter Pattern .................................... 10 3.3 Façade ......................................... 11 3.4 Flyweight ....................................... 12 3.5 Proxy ......................................... 13 3.6 Decorator ....................................... 14 4 Behavioral Design Patterns 20 4.1 Introduction ...................................... 20 4.2 Chain of Responsibility ................................ 20 4.3 Observer ........................................ 20 4.4 Visitor ......................................... 22 4.5 State .......................................... 25 1 Chapter 1 Introduction As you have probably experienced by now, writing correct computer programs can sometimes be quite a challenge. Writing the programs is fairly easy, it can be the “correct” part that maybe is a bit hard. One of the prime culprits is the challenge in understanding a great number of complex interactions. We all have probably experienced the crash of some application program