Principles of Programming Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 More on Type Checking Type Checking Done at Compile Time Is
More on Type Checking Type Checking done at compile time is said to be static type checking. Type Checking done at run time is said to be dynamic type checking. Dynamic type checking is usually performed immediately before the execution of a particular operation. Dynamic type checking is usually implemented by storing a type tag in each data object that indicates the data type of the object. Dynamic type checking languages include SNOBOL4, LISP, APL, PERL, Visual BASIC, Ruby, and Python. Dynamic type checking is more often used in interpreted languages, whereas static type checking is used in compiled languages. Static type checking languages include C, Java, ML, FORTRAN, PL/I and Haskell. Static and Dynamic Type Checking The choice between static and dynamic typing requires some trade-offs. Many programmers strongly favor one over the other; some to the point of considering languages following the disfavored system to be unusable or crippled. Static typing finds type errors reliably and at compile time. This should increase the reliability of delivered program. However, programmers disagree over how common type errors are, and thus what proportion of those bugs which are written would be caught by static typing. Static typing advocates believe programs are more reliable when they have been type-checked, while dynamic typing advocates point to distributed code that has proven reliable and to small bug databases. The value of static typing, then, presumably increases as the strength of the type system is inc reased. Advocates of languages such as ML and Haskell have suggested that almost all bugs can be considered type errors, if the types used in a program are sufficiently well declared by the programmer or inferred by the compiler. -

Automating Testing with Autofixture, Xunit.Net & Specflow
Design Patterns Michael Heitland Oct 2015 Creational Patterns • Abstract Factory • Builder • Factory Method • Object Pool* • Prototype • Simple Factory* • Singleton (* this pattern got added later by others) Structural Patterns ● Adapter ● Bridge ● Composite ● Decorator ● Facade ● Flyweight ● Proxy Behavioural Patterns 1 ● Chain of Responsibility ● Command ● Interpreter ● Iterator ● Mediator ● Memento Behavioural Patterns 2 ● Null Object * ● Observer ● State ● Strategy ● Template Method ● Visitor Initial Acronym Concept Single responsibility principle: A class should have only a single responsibility (i.e. only one potential change in the S SRP software's specification should be able to affect the specification of the class) Open/closed principle: “Software entities … should be open O OCP for extension, but closed for modification.” Liskov substitution principle: “Objects in a program should be L LSP replaceable with instances of their subtypes without altering the correctness of that program.” See also design by contract. Interface segregation principle: “Many client-specific I ISP interfaces are better than one general-purpose interface.”[8] Dependency inversion principle: One should “Depend upon D DIP Abstractions. Do not depend upon concretions.”[8] Creational Patterns Simple Factory* Encapsulating object creation. Clients will use object interfaces. Abstract Factory Provide an interface for creating families of related or dependent objects without specifying their concrete classes. Inject the factory into the object. Dependency Inversion Principle Depend upon abstractions. Do not depend upon concrete classes. Our high-level components should not depend on our low-level components; rather, they should both depend on abstractions. Builder Separate the construction of a complex object from its implementation so that the two can vary independently. The same construction process can create different representations. -

Concepts in Programming Languages Supervision 1 – 18/19 V1 Supervisor: Joe Isaacs (Josi2)
Concepts in Programming Languages Supervision 1 { 18/19 v1 Supervisor: Joe Isaacs (josi2). All work should be submitted in PDF form 24 hours before the supervision to the email [email protected], ideally written in LATEX. If you have any questions on the course please include these at the top of the supervision work and we can talk about them in the supervision. Note: there is a revision guide http://www.cl.cam.ac.uk/teaching/1718/ConceptsPL/RG. pdf for this course. 1. What is the different between a static and dynamic typing. Give with justification which languages and static or dynamic. 2. What is the different between strong and weak typing. 3. What is type safety. How are type safety and type soundness distinct? 4. What type system does LISP have what are the basic types?, where have you seen a similar type system before. 5. What is a abstract machine, why are they useful? Where have you seen or used them before? 6. Name at least six different function calling schemes and which languages use each of them. 7. Give an overview of block-structured languages, include which ideas were first introduced in a programming language and how they influenced each other. Making sure to list the main characteristics of each language. You should talk about three distinct languages, then for each language make sure to make distinctions between different version of each language. Make a timeline using pen and paper or a diagram tool. 8. Using the type inference algorithm given in the notes (a typing checker with constraints) find the most general type for fn x ) fn y ) y x 9. -

From Perl to Python
From Perl to Python Fernando Pineda 140.636 Oct. 11, 2017 version 0.1 3. Strong/Weak Dynamic typing The notion of strong and weak typing is a little murky, but I will provide some examples that provide insight most. Strong vs Weak typing To be strongly typed means that the type of data that a variable can hold is fixed and cannot be changed. To be weakly typed means that a variable can hold different types of data, e.g. at one point in the code it might hold an int at another point in the code it might hold a float . Static vs Dynamic typing To be statically typed means that the type of a variable is determined at compile time . Type checking is done by the compiler prior to execution of any code. To be dynamically typed means that the type of variable is determined at run-time. Type checking (if there is any) is done when the statement is executed. C is a strongly and statically language. float x; int y; # you can define your own types with the typedef statement typedef mytype int; mytype z; typedef struct Books { int book_id; char book_name[256] } Perl is a weakly and dynamically typed language. The type of a variable is set when it's value is first set Type checking is performed at run-time. Here is an example from stackoverflow.com that shows how the type of a variable is set to 'integer' at run-time (hence dynamically typed). $value is subsequently cast back and forth between string and a numeric types (hence weakly typed). -

(MVC) Design Pattern Untuk Aplikasi Perangkat Bergerak Berbasis Java
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Diponegoro University Institutional Repository Model-View-Controller (MVC) Design Pattern Untuk Aplikasi Perangkat Bergerak Berbasis Java Panji Wisnu Wirawan Program Studi Teknik Informatika, Universitas Diponegoro [email protected] Abstrak Design pattern merupakan salah satu teknik mendesain komponen perangkat lunak yang bisa digunakan kembali. MVC design pattern merupakan design pattern untuk komponen perangkat lunak yang memisahkan secara tegas antara model data, tampilan, dan kendali perangkat lunak. Artikel ini akan membahas MVC design pattern disertai kesesuaiannya dengan aplikasi perangkat bergerak berbasis Java. Bagian akhir artikel ini menunjukkan bagaimana MVC design pattern untuk aplikasi bergerak berbasis Java. Kata Kunci : MVC, design pattern , aplikasi perangkat bergerak berbasis Java ulang sehingga dapat meminimalkan usaha 1. Pendahuluan pengembangan aplikasi perangkat bergerak. Pada umumnya, aplikasi perangkat bergerak menggunakan Komponen perangkat lunak sudah semestinya GUI. Penggunaan MVC diharapkan bermanfaat untuk didesain dan diimplementasikan sehingga bisa pembuatan komponen perangkat lunak untuk aplikasi digunakan ulang ( reused ) pada perangkat lunak yang bergerak yang bisa digunakan ulang. [6] lain . Sebagai contoh penggunaan komponen perangkat lunak yang dapat digunakan ulang adalah Salah satu penelitian mengenai design pattern penggunaan text box , drop down menu dan untuk aplikasi perangkat bergerak berbasis Java telah sebagainya. dilakukan oleh Narsoo dan Mohamudally (2008). Narsoo dan Mohamudally (2008) melakukan Contoh lain dari komponen perangkat lunak identifikasi design pattern untuk mobile services adalah pola-pola tertentu untuk menyelesaikan menggunakan Java 2 Mobile Edition (J2ME). Mobile masalah yang disebut sebagai design pattern . Pola- services tersebut termasuk dalam behavioral pattern pola tersebut akan tetap sama untuk aplikasi yang yaitu add , edit , erase dan search . -

TH`ESE DE DOCTORAT Software Engineering Techniques For
THESE` DE DOCTORAT de L’UNIVERSITE´ DE NICE – SOPHIA ANTIPOLIS Sp´ecialit´e SYSTEMES` INFORMATIQUES pr´esent´ee par Matthias Jung pour obtenir le grade de DOCTEUR de l’UNIVERSITE´ DE NICE – SOPHIA ANTIPOLIS Sujet de la th`ese: Software Engineering Techniques for Support of Communication Protocol Implementation Soutenu le 3 Octobre 2000 devant le jury compos´e de: Pr´esident Dr. Walid Dabbous Directeur de Recherche, INRIA Rapporteurs Dr. Wolfgang Effelsberg Professeur, Universit´e de Mannheim Dr. B´eatrice Paillassa Maˆıtre de Conf´erence, ENSEEIHT Membre Invit´e Dr. Vincent Roca Charg´e de Recherche, INRIA Directeur de Th`ese Dr. Ernst W. Biersack Professeur, Institut Eur´ecom ii Acknowledgements Thanks to my supervisor Ernst Biersack for his trust and his honesty, his encouragement, and the many things I’ve learned during the last three years. Thanks to Stefan B¨ocking and the people from Siemens Research (ZT IK2) for their financial support, which gave me the opportunity to follow my PhD studies at Eur´ecom. Thanks to the members of my jury – Walid Dabbous, Wolfgang Effelsberg, B´eatrice Paillassa, and Vincent Roca – for the time they spent to read and comment my work. Thanks to Didier Loisel and David Tr´emouillac for their permanent cooperation and competent help concerning hardware and software administration. Thanks to Evelyne Biersack, Morsy Cheikhrouhou, Pierre Conti, and Yves Roudier for reading and correcting the french part of my dissertation. Thanks to the btroup members and to all people at Eur´ecom who contributed to this unique atmosphere of amity and inspiration. Thanks to Sergio for his open ear and for never running out of cookies. -

Resilience Design Patterns a Structured Approach to Resilience at Extreme Scale - Version 1.0
ORNL/TM-2016/687 Resilience Design Patterns A Structured Approach to Resilience at Extreme Scale - version 1.0 Saurabh Hukerikar Christian Engelmann Approved for public release. October 2016 Distribution is unlimited. DOCUMENT AVAILABILITY Reports produced after January 1, 1996, are generally available free via US Department of Energy (DOE) SciTech Connect. Website: http://www.osti.gov/scitech/ Reports produced before January 1, 1996, may be purchased by members of the public from the following source: National Technical Information Service 5285 Port Royal Road Springfield, VA 22161 Telephone: 703-605-6000 (1-800-553-6847) TDD: 703-487-4639 Fax: 703-605-6900 E-mail: [email protected] Website: http://classic.ntis.gov/ Reports are available to DOE employees, DOE contractors, Energy Technology Data Ex- change representatives, and International Nuclear Information System representatives from the following source: Office of Scientific and Technical Information PO Box 62 Oak Ridge, TN 37831 Telephone: 865-576-8401 Fax: 865-576-5728 E-mail: [email protected] Website: http://www.osti.gov/contact.html This report was prepared as an account of work sponsored by an agency of the United States Government. Neither the United States Government nor any agency thereof, nor any of their employees, makes any warranty, express or implied, or assumes any legal lia- bility or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or rep- resents that its use would not infringe privately owned rights. Refer- ence herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise, does not nec- essarily constitute or imply its endorsement, recommendation, or fa- voring by the United States Government or any agency thereof. -
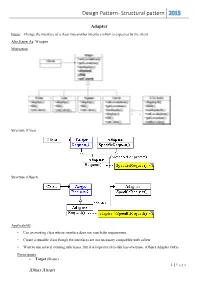
Design Pattern- Structural Pattern 2015
Design Pattern- Structural pattern 2015 Adapter Intent: Change the interface of a class into another interface which is expected by the client. Also Know As: Wrapper Motivation Structure (Class) Structure (Object) Applicability • Use an existing class whose interface does not match the requirement • Create a reusable class though the interfaces are not necessary compatible with callers • Want to use several existing subclasses, but it is impractical to subclass everyone. (Object Adapter Only) Participants Target (Shape) 1 | P a g e Almas Ansari Design Pattern- Structural pattern 2015 defines the domain-specific interface that Client uses. Client (DrawingEditor) collaborates with objects conforming to the Target interface. Adaptee (TextView) defines an existing interface that needs adapting. Adapter (TextShape) adapts the interface of Adaptee to the Target interface. Collaborations Clients call operations on an Adapter instance. In turn, the adapter calls Adaptee operations that carry out the request. Consequences Here are other issues to consider when using the Adapter pattern: 1. How much adapting does Adapter do? Adapters vary in the amount of work they do to adapt Adaptee to the Target interface. 2. Pluggable adapters. A class is more reusable when you minimize the assumptions other classes must make to use it. 3. Using two-way adapters to provide transparency. A potential problem with adapters is that they aren't transparent to all clients. Implementation 1. Implementing class adapters in C++. In a C++ implementation of a class adapter, Adapter would inherit publicly from Target and privately from Adaptee. Thus Adapter would be a subtype of Target but not of Adaptee. 2. -

UNIT-I TUTORIAL QUESTIONS 1. Explain the Concept of Design Pattern? 2
UNIT-I TUTORIAL QUESTIONS 1. Explain the concept of design pattern? 2. Explain the advantages and disadvantages of structural patterns? 3. Explain proxy design pattern in detail? 4. Explain the concept of design pattern relationship? 5. Explain the state pattern in detail? UNIT-I UNIVERSITY QUESTIONS 1. Explain the template of a design pattern? 2. Explain the state pattern in detail? 3. Explain proxy design pattern in detail? 4. Explain the features of structural pattern? 5. Explain the concept of design pattern relationship? UNIT-I DESCRIPTIVE QUESTIONS 1. Explain the template of a design pattern? 2. Explain the state pattern in detail? 3. Explain proxy design pattern in detail? 4. Explain the features of structural pattern? 5. Explain the concept of design pattern relationship? UNIT-I ASSIGNMENT QUESTIONS 1. Explain the template of a design pattern? 2. Explain the state pattern in detail? 3. Explain proxy design pattern in detail? 4. Explain the features of structural pattern? 5. Explain the concept of design pattern relationship? UNIT-I OBJECTIVE QUESTIONS 1. A pattern in general refers to layout 2. A Design pattern can be considered as Reusable solution 3. The concept of design pattern was introduced by Christopher Alexander 4. Essential elements of D.P are Pattern Name,Problem,Solution,Consequences 5. Catalog consists of Abstract factory,Adapter,Bridge 6. Creation Patterns are Factory method, Builder, Prototype 7. Structural Patterns are Factory method, Builder, Prototype 8. Design Patterns specify Object implementation 9. Design Patterns specify Object Interfaces 10. Design Patterns specify Appropriate Objects UNIT-I SEMINAR TOPICS 1. Template of D.P 2. -

CS442 Module 4: Types
CS442 Module 4: Types University of Waterloo Winter 2021 1 Getting Stuck In Module 2, we studied the λ-calculus as a model for programming. We showed how many of the elements of “real-world” programming languages can be built from λ-expressions. But, because these “real-world” constructs were all modelled as λ-expressions, we can combine them in any way we like without regard for “what makes sense”. When we added semantics, in Module 3, we also added direct (“primitive”) semantic implementations of particular patterns, such as booleans, rather than expressing them directly as λ-expressions. That change introduces a similar problem: what happens when you try to use a primitive in a way that makes no sense? For instance, what happens if we try to add two lists as if they were numbers? Well, let’s work out an example that tries to do that, using the semantics of AOE, plus numbers and lists, from Module 3, and the expression (+ (cons 1 (cons 2 empty)) (cons 3 (cons 4 empty))): • The only semantic rule for + that matches is to reduce the first argument. After several steps, it reduces to [1, 2], so our expression is now (+ [1, 2] (cons 3 (cons 4 empty))). • The rule for + to reduce the first argument no longer matches, because the first argument is not reducible. But, the rule to reduce the second argument doesn’t match, because the first argument is not a number1. No rules match, so we can reduce no further. What happens next? The answer is that nothing happens next! There’s no semantic rule that matches the current state of our program, so we can’t take another step. -

Java Design Patterns I
Java Design Patterns i Java Design Patterns Java Design Patterns ii Contents 1 Introduction to Design Patterns 1 1.1 Introduction......................................................1 1.2 What are Design Patterns...............................................1 1.3 Why use them.....................................................2 1.4 How to select and use one...............................................2 1.5 Categorization of patterns...............................................3 1.5.1 Creational patterns..............................................3 1.5.2 Structural patterns..............................................3 1.5.3 Behavior patterns...............................................3 2 Adapter Design Pattern 5 2.1 Adapter Pattern....................................................5 2.2 An Adapter to rescue.................................................6 2.3 Solution to the problem................................................7 2.4 Class Adapter..................................................... 11 2.5 When to use Adapter Pattern............................................. 12 2.6 Download the Source Code.............................................. 12 3 Facade Design Pattern 13 3.1 Introduction...................................................... 13 3.2 What is the Facade Pattern.............................................. 13 3.3 Solution to the problem................................................ 14 3.4 Use of the Facade Pattern............................................... 16 3.5 Download the Source Code............................................. -

Skin Vs. Guts: Introducing Design Patterns in the MIS Curriculum Elizabeth Towell and John Towell Carroll College, Waukesha, WI, USA
Journal of Information Technology Education Volume 1 No. 4, 2002 Skin vs. Guts: Introducing Design Patterns in the MIS Curriculum Elizabeth Towell and John Towell Carroll College, Waukesha, WI, USA [email protected] [email protected] Executive Summary Significant evidence suggests that there is increasing demand for information technology oriented stu- dents who have exposure to Object-Oriented (OO) methodologies and who have knowledge of the Uni- fied Modeling Language (UML). Object-oriented development has moved into the mainstream as the value of reusable program modules is becoming more evident. Building blocks such as software com- ponents and application frameworks allow organizations to bring products to market faster and to adapt to changes more quickly. When only one analysis and design course is required, the study of object-oriented analysis and design is often minimal or left out of the Management Information Systems curriculum. This paper argues for an increased emphasis on object-oriented techniques in the introductory Systems Analysis and Design course. Specifically, it provides guidance for faculty who are considering adding object-orientation to a systems analysis and design course where existing content leaves little time for new topics. In particular, the authors recommend the introduction of two successful, generalized design patterns in the context of adaptation of a software development framework. Where time is limited, coverage of such recurring software problems cannot be comprehensive so it is proposed that students explore two design patterns in depth as opposed to a cursory review of more patterns. Students must first learn or review the OO vocabulary including terms such as classes, inheritance, and aggregation so that the ap- propriate term can be used to discuss the UML relationships among the object model components.