An Exhaustive Power Comparison of Normality Tests
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
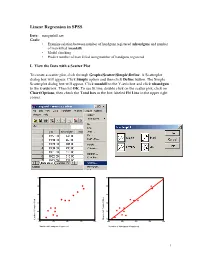
Linear Regression in SPSS
Linear Regression in SPSS Data: mangunkill.sav Goals: • Examine relation between number of handguns registered (nhandgun) and number of man killed (mankill) • Model checking • Predict number of man killed using number of handguns registered I. View the Data with a Scatter Plot To create a scatter plot, click through Graphs\Scatter\Simple\Define. A Scatterplot dialog box will appear. Click Simple option and then click Define button. The Simple Scatterplot dialog box will appear. Click mankill to the Y-axis box and click nhandgun to the x-axis box. Then hit OK. To see fit line, double click on the scatter plot, click on Chart\Options, then check the Total box in the box labeled Fit Line in the upper right corner. 60 60 50 50 40 40 30 30 20 20 10 10 Killed of People Number Number of People Killed 400 500 600 700 800 400 500 600 700 800 Number of Handguns Registered Number of Handguns Registered 1 Click the target button on the left end of the tool bar, the mouse pointer will change shape. Move the target pointer to the data point and click the left mouse button, the case number of the data point will appear on the chart. This will help you to identify the data point in your data sheet. II. Regression Analysis To perform the regression, click on Analyze\Regression\Linear. Place nhandgun in the Dependent box and place mankill in the Independent box. To obtain the 95% confidence interval for the slope, click on the Statistics button at the bottom and then put a check in the box for Confidence Intervals. -

On the Meaning and Use of Kurtosis
Psychological Methods Copyright 1997 by the American Psychological Association, Inc. 1997, Vol. 2, No. 3,292-307 1082-989X/97/$3.00 On the Meaning and Use of Kurtosis Lawrence T. DeCarlo Fordham University For symmetric unimodal distributions, positive kurtosis indicates heavy tails and peakedness relative to the normal distribution, whereas negative kurtosis indicates light tails and flatness. Many textbooks, however, describe or illustrate kurtosis incompletely or incorrectly. In this article, kurtosis is illustrated with well-known distributions, and aspects of its interpretation and misinterpretation are discussed. The role of kurtosis in testing univariate and multivariate normality; as a measure of departures from normality; in issues of robustness, outliers, and bimodality; in generalized tests and estimators, as well as limitations of and alternatives to the kurtosis measure [32, are discussed. It is typically noted in introductory statistics standard deviation. The normal distribution has a kur- courses that distributions can be characterized in tosis of 3, and 132 - 3 is often used so that the refer- terms of central tendency, variability, and shape. With ence normal distribution has a kurtosis of zero (132 - respect to shape, virtually every textbook defines and 3 is sometimes denoted as Y2)- A sample counterpart illustrates skewness. On the other hand, another as- to 132 can be obtained by replacing the population pect of shape, which is kurtosis, is either not discussed moments with the sample moments, which gives or, worse yet, is often described or illustrated incor- rectly. Kurtosis is also frequently not reported in re- ~(X i -- S)4/n search articles, in spite of the fact that virtually every b2 (•(X i - ~')2/n)2' statistical package provides a measure of kurtosis. -

The Probability Lifesaver: Order Statistics and the Median Theorem
The Probability Lifesaver: Order Statistics and the Median Theorem Steven J. Miller December 30, 2015 Contents 1 Order Statistics and the Median Theorem 3 1.1 Definition of the Median 5 1.2 Order Statistics 10 1.3 Examples of Order Statistics 15 1.4 TheSampleDistributionoftheMedian 17 1.5 TechnicalboundsforproofofMedianTheorem 20 1.6 TheMedianofNormalRandomVariables 22 2 • Greetings again! In this supplemental chapter we develop the theory of order statistics in order to prove The Median Theorem. This is a beautiful result in its own, but also extremely important as a substitute for the Central Limit Theorem, and allows us to say non- trivial things when the CLT is unavailable. Chapter 1 Order Statistics and the Median Theorem The Central Limit Theorem is one of the gems of probability. It’s easy to use and its hypotheses are satisfied in a wealth of problems. Many courses build towards a proof of this beautiful and powerful result, as it truly is ‘central’ to the entire subject. Not to detract from the majesty of this wonderful result, however, what happens in those instances where it’s unavailable? For example, one of the key assumptions that must be met is that our random variables need to have finite higher moments, or at the very least a finite variance. What if we were to consider sums of Cauchy random variables? Is there anything we can say? This is not just a question of theoretical interest, of mathematicians generalizing for the sake of generalization. The following example from economics highlights why this chapter is more than just of theoretical interest. -

05 36534Nys130620 31
Monte Carlos study on Power Rates of Some Heteroscedasticity detection Methods in Linear Regression Model with multicollinearity problem O.O. Alabi, Kayode Ayinde, O. E. Babalola, and H.A. Bello Department of Statistics, Federal University of Technology, P.M.B. 704, Akure, Ondo State, Nigeria Corresponding Author: O. O. Alabi, [email protected] Abstract: This paper examined the power rate exhibit by some heteroscedasticity detection methods in a linear regression model with multicollinearity problem. Violation of unequal error variance assumption in any linear regression model leads to the problem of heteroscedasticity, while violation of the assumption of non linear dependency between the exogenous variables leads to multicollinearity problem. Whenever these two problems exist one would faced with estimation and hypothesis problem. in order to overcome these hurdles, one needs to determine the best method of heteroscedasticity detection in other to avoid taking a wrong decision under hypothesis testing. This then leads us to the way and manner to determine the best heteroscedasticity detection method in a linear regression model with multicollinearity problem via power rate. In practices, variance of error terms are unequal and unknown in nature, but there is need to determine the presence or absence of this problem that do exist in unknown error term as a preliminary diagnosis on the set of data we are to analyze or perform hypothesis testing on. Although, there are several forms of heteroscedasticity and several detection methods of heteroscedasticity, but for any researcher to arrive at a reasonable and correct decision, best and consistent performed methods of heteroscedasticity detection under any forms or structured of heteroscedasticity must be determined. -

The Effects of Simplifying Assumptions in Power Analysis
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Public Access Theses and Dissertations from Education and Human Sciences, College of the College of Education and Human Sciences (CEHS) 4-2011 The Effects of Simplifying Assumptions in Power Analysis Kevin A. Kupzyk University of Nebraska-Lincoln, [email protected] Follow this and additional works at: https://digitalcommons.unl.edu/cehsdiss Part of the Educational Psychology Commons Kupzyk, Kevin A., "The Effects of Simplifying Assumptions in Power Analysis" (2011). Public Access Theses and Dissertations from the College of Education and Human Sciences. 106. https://digitalcommons.unl.edu/cehsdiss/106 This Article is brought to you for free and open access by the Education and Human Sciences, College of (CEHS) at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Public Access Theses and Dissertations from the College of Education and Human Sciences by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Kupzyk - i THE EFFECTS OF SIMPLIFYING ASSUMPTIONS IN POWER ANALYSIS by Kevin A. Kupzyk A DISSERTATION Presented to the Faculty of The Graduate College at the University of Nebraska In Partial Fulfillment of Requirements For the Degree of Doctor of Philosophy Major: Psychological Studies in Education Under the Supervision of Professor James A. Bovaird Lincoln, Nebraska April, 2011 Kupzyk - i THE EFFECTS OF SIMPLIFYING ASSUMPTIONS IN POWER ANALYSIS Kevin A. Kupzyk, Ph.D. University of Nebraska, 2011 Adviser: James A. Bovaird In experimental research, planning studies that have sufficient probability of detecting important effects is critical. Carrying out an experiment with an inadequate sample size may result in the inability to observe the effect of interest, wasting the resources spent on an experiment. -

Theoretical Statistics. Lecture 5. Peter Bartlett
Theoretical Statistics. Lecture 5. Peter Bartlett 1. U-statistics. 1 Outline of today’s lecture We’ll look at U-statistics, a family of estimators that includes many interesting examples. We’ll study their properties: unbiased, lower variance, concentration (via an application of the bounded differences inequality), asymptotic variance, asymptotic distribution. (See Chapter 12 of van der Vaart.) First, we’ll consider the standard unbiased estimate of variance—a special case of a U-statistic. 2 Variance estimates n 1 s2 = (X − X¯ )2 n n − 1 i n Xi=1 n n 1 = (X − X¯ )2 +(X − X¯ )2 2n(n − 1) i n j n Xi=1 Xj=1 n n 1 2 = (X − X¯ ) − (X − X¯ ) 2n(n − 1) i n j n Xi=1 Xj=1 n n 1 1 = (X − X )2 n(n − 1) 2 i j Xi=1 Xj=1 1 1 = (X − X )2 . n 2 i j 2 Xi<j 3 Variance estimates This is unbiased for i.i.d. data: 1 Es2 = E (X − X )2 n 2 1 2 1 = E ((X − EX ) − (X − EX ))2 2 1 1 2 2 1 2 2 = E (X1 − EX1) +(X2 − EX2) 2 2 = E (X1 − EX1) . 4 U-statistics Definition: A U-statistic of order r with kernel h is 1 U = n h(Xi1 ,...,Xir ), r iX⊆[n] where h is symmetric in its arguments. [If h is not symmetric in its arguments, we can also average over permutations.] “U” for “unbiased.” Introduced by Wassily Hoeffding in the 1940s. 5 U-statistics Theorem: [Halmos] θ (parameter, i.e., function defined on a family of distributions) admits an unbiased estimator (ie: for all sufficiently large n, some function of the i.i.d. -

Introduction to Hypothesis Testing
Introduction to Hypothesis Testing OPRE 6301 Motivation . The purpose of hypothesis testing is to determine whether there is enough statistical evidence in favor of a certain belief, or hypothesis, about a parameter. Examples: Is there statistical evidence, from a random sample of potential customers, to support the hypothesis that more than 10% of the potential customers will pur- chase a new product? Is a new drug effective in curing a certain disease? A sample of patients is randomly selected. Half of them are given the drug while the other half are given a placebo. The conditions of the patients are then mea- sured and compared. These questions/hypotheses are similar in spirit to the discrimination example studied earlier. Below, we pro- vide a basic introduction to hypothesis testing. 1 Criminal Trials . The basic concepts in hypothesis testing are actually quite analogous to those in a criminal trial. Consider a person on trial for a “criminal” offense in the United States. Under the US system a jury (or sometimes just the judge) must decide if the person is innocent or guilty while in fact the person may be innocent or guilty. These combinations are summarized in the table below. Person is: Innocent Guilty Jury Says: Innocent No Error Error Guilty Error No Error Notice that there are two types of errors. Are both of these errors equally important? Or, is it as bad to decide that a guilty person is innocent and let them go free as it is to decide an innocent person is guilty and punish them for the crime? Or, is a jury supposed to be totally objective, not assuming that the person is either innocent or guilty and make their decision based on the weight of the evidence one way or another? 2 In a criminal trial, there actually is a favored assump- tion, an initial bias if you will. -

Lecture 14 Testing for Kurtosis
9/8/2016 CHE384, From Data to Decisions: Measurement, Kurtosis Uncertainty, Analysis, and Modeling • For any distribution, the kurtosis (sometimes Lecture 14 called the excess kurtosis) is defined as Testing for Kurtosis 3 (old notation = ) • For a unimodal, symmetric distribution, Chris A. Mack – a positive kurtosis means “heavy tails” and a more Adjunct Associate Professor peaked center compared to a normal distribution – a negative kurtosis means “light tails” and a more spread center compared to a normal distribution http://www.lithoguru.com/scientist/statistics/ © Chris Mack, 2016Data to Decisions 1 © Chris Mack, 2016Data to Decisions 2 Kurtosis Examples One Impact of Excess Kurtosis • For the Student’s t • For a normal distribution, the sample distribution, the variance will have an expected value of s2, excess kurtosis is and a variance of 6 2 4 1 for DF > 4 ( for DF ≤ 4 the kurtosis is infinite) • For a distribution with excess kurtosis • For a uniform 2 1 1 distribution, 1 2 © Chris Mack, 2016Data to Decisions 3 © Chris Mack, 2016Data to Decisions 4 Sample Kurtosis Sample Kurtosis • For a sample of size n, the sample kurtosis is • An unbiased estimator of the sample excess 1 kurtosis is ∑ ̅ 1 3 3 1 6 1 2 3 ∑ ̅ Standard Error: • For large n, the sampling distribution of 1 24 2 1 approaches Normal with mean 0 and variance 2 1 of 24/n 3 5 • For small samples, this estimator is biased D. N. Joanes and C. A. Gill, “Comparing Measures of Sample Skewness and Kurtosis”, The Statistician, 47(1),183–189 (1998). -

Power of a Statistical Test
Power of a Statistical Test By Smita Skrivanek, Principal Statistician, MoreSteam.com LLC What is the power of a test? The power of a statistical test gives the likelihood of rejecting the null hypothesis when the null hypothesis is false. Just as the significance level (alpha) of a test gives the probability that the null hypothesis will be rejected when it is actually true (a wrong decision), power quantifies the chance that the null hypothesis will be rejected when it is actually false (a correct decision). Thus, power is the ability of a test to correctly reject the null hypothesis. Why is it important? Although you can conduct a hypothesis test without it, calculating the power of a test beforehand will help you ensure that the sample size is large enough for the purpose of the test. Otherwise, the test may be inconclusive, leading to wasted resources. On rare occasions the power may be calculated after the test is performed, but this is not recommended except to determine an adequate sample size for a follow-up study (if a test failed to detect an effect, it was obviously underpowered – nothing new can be learned by calculating the power at this stage). How is it calculated? As an example, consider testing whether the average time per week spent watching TV is 4 hours versus the alternative that it is greater than 4 hours. We will calculate the power of the test for a specific value under the alternative hypothesis, say, 7 hours: The Null Hypothesis is H0: μ = 4 hours The Alternative Hypothesis is H1: μ = 6 hours Where μ = the average time per week spent watching TV. -

Confidence Intervals and Hypothesis Tests
Chapter 2 Confidence intervals and hypothesis tests This chapter focuses on how to draw conclusions about populations from sample data. We'll start by looking at binary data (e.g., polling), and learn how to estimate the true ratio of 1s and 0s with confidence intervals, and then test whether that ratio is significantly different from some baseline value using hypothesis testing. Then, we'll extend what we've learned to continuous measurements. 2.1 Binomial data Suppose we're conducting a yes/no survey of a few randomly sampled people 1, and we want to use the results of our survey to determine the answers for the overall population. 2.1.1 The estimator The obvious first choice is just the fraction of people who said yes. Formally, suppose we have samples x1,..., xn that can each be 0 or 1, and the probability that each xi is 1 is p (in frequentist style, we'll assume p is fixed but unknown: this is what we're interested in finding). We'll assume our samples are indendepent and identically distributed (i.i.d.), meaning that each one has no dependence on any of the others, and they all have the same probability p of being 1. Then our estimate for p, which we'll callp ^, or \p-hat" would be n 1 X p^ = x : n i i=1 Notice thatp ^ is a random quantity, since it depends on the random quantities xi. In statistical lingo,p ^ is known as an estimator for p. Also notice that except for the factor of 1=n in front, p^ is almost a binomial random variable (in particular, (np^) ∼ B(n; p)). -

A Robust Rescaled Moment Test for Normality in Regression
Journal of Mathematics and Statistics 5 (1): 54-62, 2009 ISSN 1549-3644 © 2009 Science Publications A Robust Rescaled Moment Test for Normality in Regression 1Md.Sohel Rana, 1Habshah Midi and 2A.H.M. Rahmatullah Imon 1Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, University Putra Malaysia, 43400 Serdang, Selangor, Malaysia 2Department of Mathematical Sciences, Ball State University, Muncie, IN 47306, USA Abstract: Problem statement: Most of the statistical procedures heavily depend on normality assumption of observations. In regression, we assumed that the random disturbances were normally distributed. Since the disturbances were unobserved, normality tests were done on regression residuals. But it is now evident that normality tests on residuals suffer from superimposed normality and often possess very poor power. Approach: This study showed that normality tests suffer huge set back in the presence of outliers. We proposed a new robust omnibus test based on rescaled moments and coefficients of skewness and kurtosis of residuals that we call robust rescaled moment test. Results: Numerical examples and Monte Carlo simulations showed that this proposed test performs better than the existing tests for normality in the presence of outliers. Conclusion/Recommendation: We recommend using our proposed omnibus test instead of the existing tests for checking the normality of the regression residuals. Key words: Regression residuals, outlier, rescaled moments, skewness, kurtosis, jarque-bera test, robust rescaled moment test INTRODUCTION out that the powers of t and F tests are extremely sensitive to the hypothesized error distribution and may In regression analysis, it is a common practice over deteriorate very rapidly as the error distribution the years to use the Ordinary Least Squares (OLS) becomes long-tailed. -

Robustbase: Basic Robust Statistics
Package ‘robustbase’ June 2, 2021 Version 0.93-8 VersionNote Released 0.93-7 on 2021-01-04 to CRAN Date 2021-06-01 Title Basic Robust Statistics URL http://robustbase.r-forge.r-project.org/ Description ``Essential'' Robust Statistics. Tools allowing to analyze data with robust methods. This includes regression methodology including model selections and multivariate statistics where we strive to cover the book ``Robust Statistics, Theory and Methods'' by 'Maronna, Martin and Yohai'; Wiley 2006. Depends R (>= 3.5.0) Imports stats, graphics, utils, methods, DEoptimR Suggests grid, MASS, lattice, boot, cluster, Matrix, robust, fit.models, MPV, xtable, ggplot2, GGally, RColorBrewer, reshape2, sfsmisc, catdata, doParallel, foreach, skewt SuggestsNote mostly only because of vignette graphics and simulation Enhances robustX, rrcov, matrixStats, quantreg, Hmisc EnhancesNote linked to in man/*.Rd LazyData yes NeedsCompilation yes License GPL (>= 2) Author Martin Maechler [aut, cre] (<https://orcid.org/0000-0002-8685-9910>), Peter Rousseeuw [ctb] (Qn and Sn), Christophe Croux [ctb] (Qn and Sn), Valentin Todorov [aut] (most robust Cov), Andreas Ruckstuhl [aut] (nlrob, anova, glmrob), Matias Salibian-Barrera [aut] (lmrob orig.), Tobias Verbeke [ctb, fnd] (mc, adjbox), Manuel Koller [aut] (mc, lmrob, psi-func.), Eduardo L. T. Conceicao [aut] (MM-, tau-, CM-, and MTL- nlrob), Maria Anna di Palma [ctb] (initial version of Comedian) 1 2 R topics documented: Maintainer Martin Maechler <[email protected]> Repository CRAN Date/Publication 2021-06-02 10:20:02 UTC R topics documented: adjbox . .4 adjboxStats . .7 adjOutlyingness . .9 aircraft . 12 airmay . 13 alcohol . 14 ambientNOxCH . 15 Animals2 . 18 anova.glmrob . 19 anova.lmrob .