Understanding Affective Content of Music Videos Through Learned Representations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Exam Preparation Through Directed Video Blogging Using Electronically-Mediated Realtime Classroom Interaction
2016 ASEE Southeast Section Conference Exam Preparation through Directed Video Blogging and Electronically-Mediated Realtime Classroom Interaction Ronald F. DeMara, Soheil Salehi, and Sindhu Muttineni Department of Electrical and Computer Engineering University of Central Florida, Orlando, FL 32816-2362 e-mail: [email protected] Abstract A structured approach to video blogging (“vlogging”) has been piloted at the University of Central Florida (UCF) as a pedagogical tool to increase engagement in large-enrollment undergraduate courses. This two-phased activity enables a “risk-free” approach of increasing participation from all students enrolled in the course, as well as the opportunity for students who volunteer to advance their technical exposition soft-skills through professional video composition. A review of subject matter content without requiring the viewing of an excessive quantity of vlogs along with a rubric supporting automated grading mechanisms in real-time are some of the objectives that will be met through the implementation of this pedagogical tool. The resulting Learner Video Thumbnailing (LVT) hybrid individual/group exercise offers a highly- engaging interactive means for all students to review course topics in preparation for larger objective formative assessments. Keywords Formative Assessment, Cyberlearning, Student Engagement, vlog, YouTube Introduction Video Blog postings, also known as vlogs in a shared online environment can facilitate learners’ reflective thinking1. In addition, it can provide a medium to express the students’ understanding, triggering a meaning-making process thereby making it a significant aspect of formative assessment in online higher education1, 4, 5, 6, 7. A vlog can be defined as a blog in which the postings are in video format2. -

The Musicless Music Video As a Spreadable Meme Video: Format, User Interaction, and Meaning on Youtube
International Journal of Communication 11(2017), 3634–3654 1932–8036/20170005 The Musicless Music Video as a Spreadable Meme Video: Format, User Interaction, and Meaning on YouTube CANDE SÁNCHEZ-OLMOS1 University of Alicante, Spain EDUARDO VIÑUELA University of Oviedo, Spain The aim of this article is to analyze the musicless music video—that is, a user-generated parodic musicless of the official music video circulated in the context of online participatory culture. We understand musicless videos as spreadable content that resignifies the consumption of the music video genre, whose narrative is normally structured around music patterns. Based on the analysis of the 22 most viewed musicless videos (with more than 1 million views) on YouTube, we aim, first, to identify the formal features of this meme video format and the characteristics of the online channels that host these videos. Second, we study whether the musicless video generates more likes, dislikes, and comments than the official music video. Finally, we examine how the musicless video changes the multimedia relations of the official music video and gives way to new relations among music, image, and text to generate new meanings. Keywords: music video, music meme, YouTube, participatory culture, spreadable media, interaction For the purposes of this research, the musicless video is considered as a user-generated memetic video that alters and parodies an official music video and is spread across social networks. The musicless video modifies the original meaning of the official-version music video, a genre with one of the greatest impacts on the transformation of the audiovisual landscape in the past 10 years. -
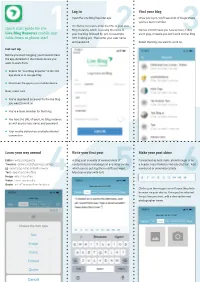
Quick Start Guide for the Live Blog Reporter Mobile
1 Log in 2 Find your blog 3 Open the Live Blog Reporter app. Once you log in, you’ll see a list of blogs where you’re a team member. On the log-in screen, enter the URL of your Live Quick start guide for the Blog instance, which is usually the name of Names in bold mean you have access; if they Live Blog Reporter mobile1 app: your live blog followed by .pro, for example:2 are in grey, it means you can’t work on3 that blog. folds down to phone size! DPA.liveblog.pro. Then enter your user name and password. Select the blog you want to work on. Get set up Before you start blogging, you’ll need to have the app installed on the mobile device you want to work from. Search for “Live Blog Reporter” in the iOS app store or in Google Play Download the app to your mobile device Next, make sure: You’re registered as a user for the live blog you want to work on You’re a team member for that blog You have the URL of your Live Blog instance as well as your user name and password Your mobile device has a reliable internet connection Learn your way around 4 Write your first post 5 Make your post shine 6 Editor - write a blog entry A blog post consists of various kinds of Format text as bold, italic, strikethrough or as Timeline - show a list of previous entries content blocks, including text and other media, a header. -

Youtube Report Draft V4
MONDAY, JULY 16 YouTube & News A new kind of visual journalism FOR FUTHER INFORMATION: Tom Rosenstiel, Director, Pew Research Center’s Project for Excellence in Journalism Amy Mitchell, Deputy Director, Pew Research Center’s Project for Excellence in Journalism (202) 419-3650 1515 L St, N.W., Suite 700 Washington, D.C. 20036 www.journalism.org YouTube & News: A New Kind of Visual Journalism Introduction On March 11, 2011, an earthquake registering 9.0 on the Richter scale struck the coast of northeastern Japan, triggering a tsunami that would kill more than 18,000 people and leave an estimated $180 billion in damage. The news media worldwide provided extensive coverage of the disaster and its aftermath, but millions of people also turned to the web to learn about the event on the video sharing website YouTube. 1 In the seven days following the disaster (March 11-18), the 20 most viewed news-related videos on YouTube all focused on the tragedy—and were viewed more than 96 million times. What people saw in these videos also represented a new kind of visual journalism. Most of that footage was recorded by citizen eyewitnesses who found themselves caught in the tragedy. Some of that video was posted by the citizens themselves. Most of this citizen-footage, however, was posted by news organizations incorporating user-generated content into their news offerings. The most watched video of all was shot by what appeared to be fixed closed-circuit surveillance camera at the Sendai airport. Link: http://www.youtube.com/watch?v=-DSSssHxm4Y The disaster in Japan was hardly a unique case. -

WILL Youtube SAIL INTO the DMCA's SAFE HARBOR OR SINK for INTERNET PIRACY?
THE JOHN MARSHALL REVIEW OF INTELLECTUAL PROPERTY LAW WILL YoUTUBE SAIL INTO THE DMCA's SAFE HARBOR OR SINK FOR INTERNET PIRACY? MICHAEL DRISCOLL ABSTRACT Is YouTube, the popular video sharing website, a new revolution in information sharing or a profitable clearing-house for unauthorized distribution of copyrighted material? YouTube's critics claim that it falls within the latter category, in line with Napster and Grokster. This comment, however, determines that YouTube is fundamentally different from past infringers in that it complies with statutory provisions concerning the removal of copyrighted materials. Furthermore, YouTube's central server architecture distinguishes it from peer-to-peer file sharing websites. This comment concludes that any comparison to Napster or Grokster is superficial, and overlooks the potential benefits of YouTube to copyright owners and to society at large. Copyright © 2007 The John Marshall Law School Cite as Michael Driscoll, Will YouTube Sail into the DMCA's Safe Harboror Sink for Internet Piracy?, 6 J. MARSHALL REV. INTELL. PROP. L. 550 (2007). WILL YoUTUBE SAIL INTO THE DMCA's SAFE HARBOR OR SINK FOR INTERNET PIRACY? MICHAEL DRISCOLL* 'A sorry agreement is better than a good suit in law." English Proverb1 INTRODUCTION The year 2006 proved a banner year for YouTube, Inc. ("YouTube"), a well- known Internet video sharing service, so much so that Time Magazine credited YouTube for making "You" the Person of the Year. 2 Despite this seemingly positive development for such a young company, the possibility of massive copyright 3 infringement litigation looms over YouTube's future. For months, YouTube was walking a virtual tightrope by obtaining licensing agreements with major copyright owners, yet increasingly gaining popularity through its endless video selection, both legal and otherwise. -

5 Proven Blog Post Templates
5 PROVEN BLOG POST TEMPLATES 5 Traffic Generation Blog Posts A blog without fresh content is like a grocery store selling expired vegetables, it just won’t work and the shopper (a.k.a. visitor) is not likely to return. In order to drive traffic to your blog, you will need fresh, fun and interesting content that attracts visitors. The Kudani team is all about content and we understand that creating it can be difficult. These templates were designed to help you create awesome content without having to write it all yourself, saving you a huge amount of time. The List Post The list post is arguably the easiest post to write and one of the most shared. The best way to explain this post style is to give you examples of titles and an outline / format that is easy to follow. Here are some example list post headlines: . The top three places to visit in Europe . The 9 things you need to do before your next interview . 7 ways to save money while grocery shopping . 5 blog post templates to get you started We have been trained by media outlets, teachers and parents to track lists, rank items and organize information. List posts are very easy and readers love them because it fits the way we are trained to think. And the topic predicts what the content will be which makes writing this post stress-free. The basic structure to follow would look something like this: 1. Powerful headline perhaps created with our headlinr tool 2. Introduction of the list subject and how items were selected or ranked. -

American Cuisine Educational Training and Promotion China
THIS REPORT CONTAINS ASSESSMENTS OF COMMODITY AND TRADE ISSUES MADE BY USDA STAFF AND NOT NECESSARILY STATEMENTS OF OFFICIAL U.S. GOVERNMENT POLICY Voluntary - Public Date: 11/10/2011 GAIN Report Number: CH11626 China - Peoples Republic of Post: Guangzhou American Cuisine Educational Training and Promotion Report Categories: Market Development Reports Approved By: Jorge Sanchez Prepared By: Jericho Li Report Highlights: On September 26-27, 2011, ATO Guangzhou launched a major American Cuisine Chef Training with Starwood Hotels and Resorts Asia Pacific Food and Beverage China Sub-council in Guangzhou’s newly opened Sheraton Hotel. ATO Guangzhou was instrumental in cooperating with the Culinary Institute of America to conduct a two-day training workshop for 20 experienced chefs from the Starwood hotel chain. The training included basic knowledge of American regional cuisine as well as a hands-on cooking experience and recipe development workshop. This educational opportunity for Starwood chefs increased their knowledge of American Cuisine putting them in contact with local vendors that source U.S. ingredients. In addition, a promotion for the purpose of increasing consumer awareness of American food items was conducted through the most popular and widely used social communication platform in China (Sina Weibo). Background on the American Cuisine Chef Training Program for the Starwood Hotel Chain China is one of the Starwood chain’s most important overseas market, with 160 hotels nationwide and 93 scheduled to open in the next five years. This year, Starwood China is focusing on promoting their food and beverage preparation prowess. The group is interested in working with ATO Guangzhou to improve their chefs’ understanding of American cuisine and increase the usage of U.S. -

The French Lieutenant's Woman
1993/ /2014 Whose Story?: The Screen Adaptation of John Fowles’s The French Lieutenant’s Woman Sara Martín Alegre Tesina/(MA) Dissertation Programa de Doctorat en Filologia Anglesa Departament de Filologia Anglesa i de Germanística Universitat Autònoma de Barcelona Contents Abstract ........................................................................................................................ 1 1. Introduction: Establishing the Ownership of Stories ................................................... 1 1.1. Reconsidering the Role of the Screen Playwright ................................................ 4 1.2. Reconsidering Screen Adaptations .................................................................... 13 2.The Novel and the Novelist: Obsessive Authorial Control ......................................... 19 2.1. Vindicating the Victorian Author: The Problem of Controlling the Female Protagonist .............................................................................................................. 19 2.2. The French Lieutenant’s Woman in Conversation with Other Texts: Overcoming the Need for a Husband ........................................................................................... 30 3. The Novel and the Screenwriter: Rewriting from Scratch......................................... 41 3.1. Between Stage and Screen: Harold Pinter ......................................................... 41 3.2. From Project to Film: Selling The French Lieutenant’s Woman to American Audiences ............................................................................................................... -

Využití Krátkých Videoklipů Ve Výuce Anglického Jazyka
Západočeská univerzita v Plzni Fakulta pedagogická Katedra anglického jazyka Diplomová práce VYUŽITÍ KRÁTKÝCH VIDEOKLIPŮ VE VÝUCE ANGLICKÉHO JAZYKA Jan Vysloužil Plzeň 2017 University of West Bohemia Faculty of Education Department of English Thesis THE USE OF SHORT VIDEO CLIPS IN ENGLISH LANGUAGE TEACHING Jan Vysloužil Plzeň 2017 Tato stránka bude ve svázané práci Váš původní formulář Zadáni dipl. práce (k vyzvednutí u sekretářky KAN) Prohlašuji, že jsem práci vypracoval samostatně s použitím uvedené literatury a zdrojů informací. V Plzni dne 30. Června 2017 ……………………………. Jan Vysloužil ACKNOWLEDGMENTS I would like to express my sincere gratitude to my supervisor Mgr. Gabriela Klečková, PhD. for help and valuable advice. I would also like to thank my family and especially my parents for their support. ABSTRACT Vysloužil, Jan. University of West Bohemia. June, 2017. The use of short video clips in English language teaching. Supervisor: Mgr. Gabriela Klečková, Ph.D This thesis is focused on the use of short video clips in English language teaching. It provides the terminology concerning digital video clips and explains that technology has come far enough to allow teachers to work with video clips which they can find on the internet and incorporate them into the design of their lessons. The main challenge of using video clips is that students and teachers can have pre-conceived notions about them and may consider their main purpose to be only entertainment while video clips are in fact a perfectly viable tool to be used in the classrooms. One of the most compelling reasons for using short video clips is that they can offer not only the opportunity to practice language skills but they can also provide rich visual imagery resulting in a complex audio visual package. -

Music Television 1/27/03 5:30 PM
Music Television 1/27/03 5:30 PM MUSIC TELEVISION MTV (Music Television) is the oldest and most influential American cable network specializing in music?related programming. It was launched on August 1, 1981, with the words "Ladies and gentlemen, rock and roll," spoken on camera by John Lack, one of the creators of MTV. This introduction was immediately followed by the music?video clip Video Killed the Radio Star, featuring a band called the Buggles. The title proved somewhat prophetic as MTV greatly transformed the nature of music?industry stardom over the next several years. At the same time, MTV became a major presence in the cable?TV industry and in fact in the overall American cultural landscape. One of the earliest and greatest cable success stories, MTV was established by Warner Amex Satellite Courtesy of MTV Entertainment Company (WASEC) after extensive marketing research. The key to MTV's viability, at least Some of the displaced musical content of MTV, initially, was the availability of low-cost programming in especially soft rock and other "adult" music, has landed the form of music videos. Originally these were provided on VH1 (Video Hits 1), a second video channel owned by free by record companies, which thought of them as MTV. Launched in 1985, VH?1 (hyphenated until 1994) advertising for their records and performers. quickly acquired a reputation as "video valium" for yuppies. Otherwise, the channel has had an indistinct MTV presented one video after another in a constant image and has languished in the shadow of MTV. "flow" that contrasted with the discrete individual Makeovers in 1989 and (especially) 1994 raised the programs found on other television networks. -

Emerging Technologies Youtube for Foreign Languages: You Have to See This Video
Language Learning & Technology February 2011, Volume 15, Number 1 http://llt.msu.edu/issues/february2011/emerging.pdf pp. 10–16 EMERGING TECHNOLOGIES YOUTUBE FOR FOREIGN LANGUAGES: YOU HAVE TO SEE THIS VIDEO Joseph M. Terantino Kennesaw State University INTRODUCTION “Have you seen this video?” “You have to see this video.” For the students belonging to the digital natives (Prensky, 2001), these phrases are used frequently to express their enthusiasm and overwhelming interest in new and fascinating videos that they have found via the Internet. These commonplace phrases also demonstrate their genuine desire to share and discuss what they have found. Inspired by Chinnery’s (2008) column in which he describes Google-Assisted Language Learning, this column aims to accomplish a similar feat with regard to YouTube. The descriptions offered here are geared towards integrating the practice of creating, watching, and sharing YouTube videos, which appeals to the current generation of students, into foreign language teaching and learning. To accomplish this, there is a description of the brief history of YouTube and its impact on society, and of the defining characteristics of the digital natives and their unique educational needs. This is followed by an explanation of how YouTube can be used to bridge the gap between satisfying the particular educational needs of the students and meeting the demands of foreign language education. THE HISTORY OF YOUTUBE In February of 2005, Steve Chen, Chad Hurley, and Jawed Karim founded YouTube with the domain name http://www.youtube.com. The site was created as a forum for people to create and share short video clips online. -

Youtube for Foreign Languages: You Have to See This Video Joseph M
Kennesaw State University DigitalCommons@Kennesaw State University Faculty Publications 2-2011 Youtube for Foreign Languages: You Have to See This Video Joseph M. Terantino Kennesaw State University, [email protected] Follow this and additional works at: http://digitalcommons.kennesaw.edu/facpubs Part of the Bilingual, Multilingual, and Multicultural Education Commons Recommended Citation Terantino, Joseph M. "YouTube for Foreign Languages: You Have to See this Video." Language Learning & Technology 15.1 (2011): 10-16. This Article is brought to you for free and open access by DigitalCommons@Kennesaw State University. It has been accepted for inclusion in Faculty Publications by an authorized administrator of DigitalCommons@Kennesaw State University. For more information, please contact [email protected]. Language Learning & Technology February 2011, Volume 15, Number 1 http://llt.msu.edu/issues/february2011/emerging.pdf pp. 10–16 EMERGING TECHNOLOGIES YOUTUBE FOR FOREIGN LANGUAGES: YOU HAVE TO SEE THIS VIDEO Joseph M. Terantino Kennesaw State University INTRODUCTION “Have you seen this video?” “You have to see this video.” For the students belonging to the digital natives (Prensky, 2001), these phrases are used frequently to express their enthusiasm and overwhelming interest in new and fascinating videos that they have found via the Internet. These commonplace phrases also demonstrate their genuine desire to share and discuss what they have found. Inspired by Chinnery’s (2008) column in which he describes Google-Assisted Language Learning, this column aims to accomplish a similar feat with regard to YouTube. The descriptions offered here are geared towards integrating the practice of creating, watching, and sharing YouTube videos, which appeals to the current generation of students, into foreign language teaching and learning.