Population Synthesis Handling Three Geographical Resolutions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bezirkssozialarbeit – Hilfe Und Beratung
Unser Angebot Ihr Anspruch Auch Sie können helfen Bezirkssozialarbeit – Hilfe und Beratung Wir beraten und unterstützen Sie bei Liebe Bürger*innen, Verständigen Sie uns, wenn Sie einen Menschen in Not kennen und selbst keine Hilfe leisten können. > persönlichen und wirtschaftlichen Notsituationen Sie brauchen Informationen, Beratung und Hilfe Wir nehmen Kontakt zu den Betroffenen auf und > Familien- und Partnerkonflikten in Ihrer persönlichen Lebenssituation? leiten notwendige Hilfen ein. > Schwierigkeiten in der Versorgung und Wir, die Bezirkssozialarbeit, sind der kommu- Erziehung von Kindern nale Sozialdienst der Stadt München in den Sie erreichen uns in den Sozialbürgerhäusern > Fragen zu Trennung / Ehescheidung und Sorge- Münchner Sozialbürgerhäusern und der Abtei- (SBH) Ihres Stadtbezirks. rechtsregelung lung Wohnungslosenhilfe und Prävention. > Wohnproblemen und drohender Wohnungs- losigkeit Wir bieten Ihnen durch Sozialpädagog*innen Ihre Bezirkssozialarbeit > Lebenskrisen und psychischen Belastungen unsere Unterstützung an. > sozialen Problemen in Folge von Alter Unsere Hilfe steht allen Münchnerinnen und bzw. Krankheit Münchnern unabhängig von Geschlecht, kultureller oder sozialer Herkunft, Alter, Religion, Weltan- Wir vermitteln Hilfen schauung, Behinderung, sexueller oder geschlecht- licher Identität zur Verfügung. > zur Versorgung von Familien in Notsituationen > nach dem Kinder- und Jugendhilfegesetz wie Wir beraten Sie kompetent, kostenlos und – Ehe-, Erziehungs- und Familienberatung vertraulich. Herausgegeben von: – Hilfen zur Erziehung Landeshauptstadt München, Sozialreferat Orleansplatz 11, 81667 München Wir sind München > Schuldnerberatung, Freiwillige Leistungen Wir unterstehen in unserer Arbeit der gesetzlichen für ein soziales Miteinander Schweigepflicht. Layout: Set K GmbH, Germering Wir sind Anlaufstelle und leiten Schutzmaßnahmen Fotos: Michael Nagy, Presse- und Informationsamt (1), istockphoto.com: diego cervo, Chris Schmidt (2), für Kinder, Jugendliche und Erwachsene ein, bei Bei Bedarf besuchen wir Sie auch zu Hause. -

Package 'Linreginteractive'
Package ‘LinRegInteractive’ February 8, 2020 Type Package Title Interactive Interpretation of Linear Regression Models Version 0.3-3 Date 2020-02-08 Author Martin Meermeyer Maintainer Martin Meermeyer <[email protected]> Description Interactive visualization of effects, response functions and marginal effects for different kinds of regression models. In this version linear regression models, generalized linear models, generalized additive models and linear mixed-effects models are supported. Major features are the interactive approach and the handling of the effects of categorical covari- ates: if two or more factors are used as covariates every combination of the levels of each factor is treated separately. The automatic calculation of marginal effects and a number of possibilities to customize the graphical output are useful features as well. License GPL-2 Depends R (>= 3.0.0), rpanel (>= 1.1-4), xtable Suggests AER, gam, mgcv, nlme NeedsCompilation no Repository CRAN Date/Publication 2020-02-08 17:00:02 UTC R topics documented: LinRegInteractive-package . .2 creditdata . .3 factorCombinations . .5 fxInteractive . .6 fxInteractive.glm . .8 fxInteractive.lm . 15 fxInteractive.lme . 21 munichrent03 . 26 1 2 LinRegInteractive-package Index 28 LinRegInteractive-package Interactive Interpretation of Linear Regression Models Description The implementation is based on the package rpanel and provides an interactive visualization of effects, response functions and marginal effects for different kinds of regression models. Major features are the interactive approach and the handling of the effects of categorical covariates: if two or more factors are used as covariates every combination of the levels of each factor (referred to as groups) is treated separately. The automatic calculation of marginal effects and a number of possibilities to customize the graphical output are useful features as well. -

Trudering-Riem
Stadtbezirk Trudering-Riem Informationen für Bürger und Gäste 1 Grußwort des Bezirksausschussvorsitzenden Verehrte Leserinnen, verehrte Leser, nach einer langen Pause von 13 Jahren gibt es wieder einen "Trudering-Riem-Führer". Mein erster Dank gilt dem WEKA-Verlag und den zahlreichen Inserenten, die diesen kostenlosen Führer ermöglicht haben. Unser Part war es, zusammenzustellen, was für Sie an Informationen über unseren Stadtbezirk interessant sein könnte. Neben häufig benötigten Service-Telefonnum- mern der Stadt München und anderer Einrichtungen sind dies vor allem die Kontaktdaten unserer Kirchengemein- den, Schulen, Kindertagesstätten und der verschiedenen Dr.-Ing. Georg Kronawitter Vereine und Initiativen. Die Fülle zeigt, dass in Trudering- Vorsitzender des Bezirksausschusses Riem bürgerschaftliches Engagement einen hohen Stel- Trudering-Riem lenwert besitzt. Ich hoffe, dass dieser Stadtteilführer Ihnen nützt - auch wenn er sicherlich nicht perfekt sein kann. Anregungen nimmt der Bezirksausschuss Trudering-Riem gerne entgegen. Und noch etwas: Bitte berücksichtigen Sie bei Ihren Ent- scheidungen die Inserenten. Sie tragen damit dazu bei, dass in Ihrem Umfeld ein reichhaltiges Angebot erhalten bleibt. Ihr Dr. Ing. Georg Kronawitter Vorsitzender des Bezirksausschusses Trudering-Riem 2 Inhaltsverzeichnis Bezeichnung Seite Grusswort des Bezirksausschussvorsitzenden 1 Zum Einstieg: Trudering- Riem - Münchens dynamischer Osten 4-5 Branchenverzeichnis 7 Stadtverwaltung /Behörden/Post/Banken und Sparkassen 8-11 Kindertagesstätten 12-13 Schulen 14-15 Jugendangebote 17 Soziales und bürgerschaftliches Leben 19-21 Kirchen in Trudering-Riem 23 Kunst und Kultur in Trudering-Riem 25-27 Sport in Trudering-Riem 29 Politik & Gremien 30-33 Kleine Geschichte von Trudering und Riem 35-37 Notfallnummern / Quellen 40 Impressum 40 Ortsplan Heftmitte Kirchtrudering: Kirche St. Peter und Paul Im Münchner Osten immer für Sie da! ls regional verwurzelte Bank bieten wir AIhnen einen umfassenden Service in allen Bereichen rund um das Thema Geld. -

Wohn- & Geschäftshäuser · Residential Investment Marktreport 2019/2020 · München
Wohn- & Geschäftshäuser · Residential Investment Marktreport 2019/2020 · München MÜNCHEN 1. 5 4 2 . 211 33.395 EUR 9.351 0,2 % 18,28 EUR/m² Bevölkerung Kaufkraft pro Kopf Baufertigstellungen Leerstandsquote Ø-Angebotsmiete + 5,3 % (zu 2013) 139,1 (Kaufkraftindex) + 12,1 % (zu 2017) 6,6 (Leerstandsindex) + 4,3 % (zu 2018) Transaktionen Rendite versus Inflation 2250 157 175 6 145 4,3 4,2 4,2 1800 122 125 125 140 3,9 120 4 3,6 3,4 3,8 3,7 3,7 3,4 1350 183 115 105 162 . 3,1 1 3,0 1 .065 .010 1 1 2 in % 917 900 70 Anzahl in Mio. EUR 1.200 0 450 35 1.100 – 1.100 0 0 – 2 2014 2015 2016 2017 2018 2019* 2014 2015 2016 2017 2018 2019 Transaktionsvolumen Transaktionsanzahl gute Lage mittlere Lage * Prognosespanne Inflationsrate Pfandbriefe (10 J.) Quelle: Gutachterausschuss München, Engel & Völkers Commercial Quelle: Destatis, Bundesbank, Engel & Völkers Commercial Angebotsmieten 2019* Anzahl der Ø-Kaltmiete (Bestand) Spanne der Kaltmieten Ø-Kaltmiete (Neubau) Stadtbezirk Wohnungsangebote in EUR/m2 (zu 2018) (Bestand) in EUR/m2 in EUR/m2 Ludwigsvorstadt-Isarvorstadt 357 20,92 (+ 6,7 %) 14,80 – 28,10 25,52 Maxvorstadt, Schwabing-West, Schwabing-Freimann 1.080 19,91 (+ 4,3 %) 12,90 – 28,30 23,46 Au-Haidhausen 311 19,49 (+ 6,3 %) 13,80 – 26,30 24,10 Altstadt-Lehel, Bogenhausen 879 19,30 (+ 4,5 %) 11,30 – 26,20 21,75 Neuhausen-Nymphenburg, Laim, Hadern, Schwanthalerhöhe 1.122 17,37 (+ 2,9 %) 12,10 – 23,50 21,03 Obergiesing-Fasangarten, Untergiesing-Harlaching 553 17,21 (+ 2,6 %) 11,60 – 23,00 21,32 Sendling, Sendling-Westpark, Thalkirchen-Obersendling- Forstenried-Fürstenried-Solln 1.038 17,06 (+ 4,1 %) 12,00 – 24,00 19,78 Moosach, Milbertshofen-Am Hart, Feldmoching-Hasenbergl 686 16,74 (+ 3,4 %) 11,60 – 23,30 19,66 Allach-Untermenzing, Pasing-Obermenzing, Aubing-Lochhausen-Langwied 805 16,27 (+ 5,6 %) 11,10 – 22,40 19,17 Berg am Laim, Ramersdorf- Perlach, Trudering-Riem 1.122 15,91 (+ 3,9 %) 11,40 – 22,50 18,68 Quelle: empirica-systeme, Engel & Völkers Commercial * bezogen auf das 1. -

City-Map-2017.Pdf
3 New Town Hall 11 Hofbräuhaus The Kunstareal (art quarter) Our Service Practical Tips Located in walking distance to one another, the rich variety contained in the museums and galleries in immediate proximity to world-renowned München Tourismus offers a wide range of services – personal and Arrival universities and cultural institutions in the art quarter is a unique multilingual – to help you plan and enjoy your stay with various By plane: Franz-Josef-Strauß Airport MUC. Transfer to the City by treasure. Cultural experience is embedded in a vivacious urban space offers for leisure time, art and culture, relaxation and enjoyment S-Bahn S1, S8 (travel time about 40 min). Airport bus to main train featuring hip catering and terrific parks. In the Alte Pinakothek 1 , in the best Munich way. station (travel time about 45 min). Taxi. Neue Pinakothek 2 and Pinakothek der Moderne 3 , Museum By railroad: Munich Hauptbahnhof, Ostbahnhof, Pasing Brandhorst 4 and the Egpytian Museum 5 as well as in the art By car: A8, A9, A92, A95, A96. Since 2008 there has been a low-emission galleries around Königsplatz 6 – the Municipal Gallery in Lenbach- Information about Munich/ zone in Munich. It covers the downtown area within the “Mittlerer Ring” haus 7 , the State Collections of Antiques 8 , the Glyptothek 9 and Hotel Reservation but not the ring itself. Access is only granted to vehicles displaying the the Documentation Center for the History of National Socialism 10 appropriate emission-control sticker valid all over Germany. – a unique range of art, culture and knowledge from more than 5,000 Mon-Fr 9am-5pm Phone +49 89 233-96500 www.muenchen.de/umweltzone 9 Church of Our Lady 6 Viktualienmarkt 6 Königsplatz years of human history can be explored. -

Referat Für Stadtplanung Und Bauordnung Beauftragt, Insgesamt Sechs Rahmenplanungen Durchzuführen
Telefon: 233 – 22854233 – 22854 Referat für Stadtplanung 233 – 23226233 – 23226 und Bauordnung 233 – 22904233 – 22904 Stadtplanung Telefax: 233 – 22868233 – 22868 HA II/63P HA II/56 HA II/60V A) Gartenstädte – Erhalt des Charakters und bauliche Entwicklung Rahmenplanungen – Beschlussfassung B) Empfehlungen Überarbeitung der Baulinien Im Rahmenplan Empfehlung Nr. 14-20 / E 02330 der Bürgerversammlung des Stadtbezirks 18 – Untergiesing-Harlaching am 15.11.2018 Überarbeitung der Rahmenplanung „Reichsheim-Siedlung Laim“ Empfehlung Nr. 14-20 / E 02419 der Bürgerversammlung des Stadtbezirks 25 – Laim am 20.11.2018 C) Stellungnahmen des Bündnisses Gartenstadt vom 21.01.2019 und 23.01.2019 Stadtbezirk 7 Sendling-Westpark Stadtbezirk 15 Trudering-Riem Stadtbezirk 16 Ramersdorf-Perlach Stadtbezirk 18 Untergiesing-Harlaching Stadtbezirk 20 Hadern Stadtbezirk 21 Pasing-Obermenzing Stadtbezirk 25 Laim Sitzungsvorlage Nr. 14-20 / V 12716 Beschluss des Ausschusses für Stadtplanung und Bauordnung vom 22.05.2019 (VB) Öffentliche Sitzung Kurzübersicht zur beiliegenden Beschlussvorlage Anlass Beschluss vom 29.04.2015, Sitzungsvorlage Nr. 14-20 / V 00909 (Gartenstädte – Erhalt des Charakters und bauliche Entwicklung – Stand und Ausblick) Inhalt Bericht der Rahmenplanung Gartenstädte, Reichweite und Übertragbarkeit der Ergebnisse der Rahmenplanungen und weitere Vorgehensweise in den Gartenstädten. Gesamtkosten/ -/- Gesamterlöse Entscheidungs- - Beschluss der sechs Rahmenplanungen vorschlag - Evaluierung des Steuerungsinstruments Rahmenplanung - Durchführung -

The Effects of the Design and Land-Use Diversity of the Built Environment on Cycling in Munich
Technical University of Munich – Professor for Modeling Spatial Mobility Prof. Dr.-Ing. Rolf Moeckel Arcisstraße 21, 80333 München, www.msm.bgu.tum.de Master’s Thesis The Effects of the Design and Land-Use Diversity of the Built Environment on Cycling in Munich Author: Thomas M. Scriba Supervision: Prof. Dr.-Ing. Rolf Moeckel Date of Submission: March 19, 2018 Declaration I hereby confirm that this thesis is presented for the degree of Master of Science in Transportation Systems at the Technical University of Munich (Technische Universität München). This thesis has been composed entirely by myself and is based solely on the results of my own work, unless stated otherwise. No other person’s work has been used without due acknowledgement. This thesis has not been submitted for any other degree or professional qualification. ________________________________ Thomas M. Scriba ABSTRACT This thesis investigates the influences the built environment in Munich has on the rates of cycling exhibited by the various 25 city districts. As cities strive to reduce congestions and commute times, many of them, including Munich, have looked to the bicycle as a solution. Previous research shows that increased shared of cycling are associated with better living conditions and lower rates of air pollution. The City of Munich has done much to support cycling in recent decades. Cycling infrastructure has been built up, routes throughout the city marked with new signage, pavement marking improved to increase motorists’ awareness, and organizations supporting cycling have run publicity and informational campaigns and events to raise the public profile of cycling. This thesis utilizes a mixed-method approach combining a quantitative analysis of geographic built environment and demographic/social data with a qualitative study comprised of field surveys in 6 of the 25 districts. -
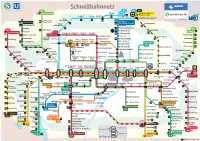
Schnellbahnnetz
Schnellbahnnetz Petershausen Pulling Freising Flughafen München Munich Airport Lohhof Eching Neufahrn Flughafen Besucherpark Unter- Partner im Vierkirchen- schleißheim Altomünster Esterhofen Garching- Ober- Forschungszentrum Hallbergmoos Kleinberghofen schleißheim Garching Erdweg Garching-Hochbrück Röhrmoos Ismaning Fröttmaning Erding Mammendorf Arnbach Hasenbergl Dülferstr. Harthof Am Hart Kieferngarten Markt Indersdorf Feldmoching Altenerding Frankfurter Ring Freimann Unterföhring Heberts- Niederroth Fasanerie Moosacher Milbertshofen Studentenstadt Aufhausen Malching hausen St.-Martins- Ober- Olympia- Petuel- Schwabhausen Platz OEZ wiesenfeld zentrum ring Bonner Platz Alte Heide Arabellapark St. Koloman Moosach Nordfriedhof Bachern Dachau Stadt in Bau Scheidplatz Olympiapark Ottenhofen Maisach Georg-Brauchle- Dietlindenstr. Johanneskirchen Dachau Hohenzollernplatz Ring Münchner Freiheit Richard-Strauss-Str. Markt Schwaben Gernlinden Karlsfeld Westfriedhof Josephsplatz Giselastr. Chinesischer Allach Turm Böhmerwaldplatz Poing Esting Gern Englschalking Rotkreuz- Maillinger-Stiglmaier- Theresien- Universität Grub str. Prinzregentenplatz Untermenzing platz str. platz Olching Odeonsplatz Lehel Max-Weber-Pl. Heimstetten Obermenzing Königs- Gröbenzell platz Daglfing Feldkirchen Lochhausen Donnersberger- Hacker- Hauptbahnhof Riem brücke Marienplatz Rosenheimer Pasing brücke Central Station Karlsplatz Messestadt- Laim (Stachus) City Center Isartor Platz Ostbahnhof Berg am Laim West Langwied Moos- feld Aubing Leienfelsstr. Messestadt- Leuchtenberg- -
Flyer-Umstellung-Heizwassernetze.Pdf
M / Fernwärme Modernisierung des Fernwärmenetzes Wer umweltfreundliche Fernwärme aus Geothermie bezieht, unterstützt aktiv die Energiewende. 2 M / Fernwärme M / Fernwärme 3 Umweltfreundliche Fernwärme Denn momentan betreiben wir zwei unterschiedliche Systeme: ein seit 1908 gewachsenes Dampfnetz innerhalb des Mittleren für München Rings und die später entstandenen Heizwassernetze, unter anderem in Sendling, Perlach und Freimann. Geothermie liefert „nur“ ca. 120 Grad Celsius heißes Wasser, das nicht in das bestehende Dampfnetz eingebunden werden kann. Daher Mit der Entscheidung für eine Wärmeversorgung Ihrer werden wir die noch vorhandenen Dampfnetzgebiete auf Immobilie durch M-Fernwärme haben Sie bereits die richtige ein zeit gemäßes Heizwassernetz umstellen. Eine wichtige Wahl getroen: Fernwärme ist preiswert und bequem. Entscheidung für mehr Umwelt- und Klimaschutz. Zudem leisten Sie einen wesentlichen Beitrag zum Klimaschutz und zur Reinhaltung der Luft. Für Ihr Vertrauen bedanken wir uns. Zugleich sehen wir dies als unsere Verpflichtung an, die Austausch und optimaler Betrieb der Fernwärme fit für die Zukunft zu machen. Kundenanlagen nötig Die Umstellung auf Heizwasser erfordert zwei aufeinander Zukunftsprojekt Wärmewende abgestimmte Maßnahmen. Für die Modernisierung der Fern- wärmeleitungen in Straßen und Gehwegen bis zur Übergabe- Derzeit erzeugen wir die Fernwärme zum größten Teil in stelle in den Heizungsräumen sind die SWM verantwortlich. sehr energieezienten Anlagen mit Kraft-Wärme-Kopplung (KWK), die Strom und Fernwärme gleichzeitig -

Das Zusammenleben Zwischen Deutschen Und Ausländern in München
Hauptbeitrag Münchner Statistik, 4. Quartalsheft, Jahrgang 2009 Autor: Dr. Walter Kuhn, Ludwig-Maximilians-Universität, München Grafiken und Karten: Statistisches Amt München Das Zusammenleben zwischen Deutschen und Ausländern in München. Untersuchungen zur innerstädtischen Wohnstandortverteilung verschiedener ethnischer Gruppen. München mit höchstem Unter allen deutschen Großstädten mit über 500 000 Einwohnern hatte die Ausländeranteil unter den bayerische Landeshauptstadt Ende 2008 den höchsten Ausländeranteil deutschen Großstädten (23,4%1)). Auch wenn Berlin häufig als die Stadt mit dem auffallendsten multikulturellen Erscheinungsbild angesehen wird, so sind Ausländer dort doch lediglich mit 14 Prozent vertreten, und selbst der Berliner Bezirk Friedrichshain/Kreuzberg erreicht gerade einmal den Münchner Durch- schnittswert. Absolut gesehen ist Berlin natürlich dennoch die Stadt mit der größten Ausländerpopulation. Grafik 1 Die Einwohner und der Ausländeranteil deutscher Großstädte über 500 000 Einwohner am 31.12.2008 4 000 000 40,0% Einwohner Ausländer in % 3 500 000 35,0% 3 000 000 30,0% 23,4 22,9 2 500 000 25,0% 20,7 2 000 000 18,1 20,0% 16,8 16,6 16,5 15,9 14,5 14,0 13,8 1 500 000 12,7 15,0% 12,1 Einwohner/innen 1 000 000 10,0% 6,5 4,7 500 000 5,0% 0 0,0% Köln Berlin Essen Leipzig Bremen Dresden Stuttgart Duisburg München Hamburg Nürnberg Hannover Dortmund Düsseldorf Frankfurt a. M. ___________ Quelle: Statistische Landesämter © Statistisches Amt München Bevor die Verteilung der ausländischen Bevölkerung innerhalb der Stadt dargestellt werden soll, und dabei der Frage nachgegangen wird, ob es Unterschiede in den Wohnstandorten bestimmter Bevölkerungsgruppen gibt, sei zunächst einmal ein kurzer Abriss der jüngeren Migrationsgeschichte vorangestellt. -

Bezirksausschuss Des 20. Stadtbezirkes Landeshauptstadt Hadern München
Bezirksausschuss des 20. Stadtbezirkes Landeshauptstadt Hadern München Vorsitzender Johann Stadler BA-Geschäftsstelle West Landsberger Str. 486, 81241 München Privat: E-Mail: [email protected] Einladung Geschäftsstelle West: Landsberger Str. 486, 81241 München Telefon: 089 – 233 37352 Zur 64. Sitzung des Bezirksausschusses Telefax: 089 – 233 37356 E-Mail: [email protected] des 20. Stadtbezirkes - Hadern - am Montag, den 12.08.2019 um 19.30 Uhr, Gaststätte „Mehlfeld's“, Guardinistraße 98 a München, 08.08.2019 Nachtragstagesordnung: 1 Die Bürgerinnen und Bürger haben das Wort 1. Antrag auf Einführung von Schrittgeschwindigkeit im Lobelienweg 2. Verkehrslärm in der Nacht in der Fürstenrieder Straße 3. Parksituation Kriegerheimstraße (N) - 4. Aufstellung von Sitzbänken und den Straßen Am Hedernfeld und Haderunstraße (N) – 5. Klinikum Großhadern – Anträge der Bürgerinitiative Großhadern (BIG) 2 Genehmigung der Niederschrift der letzten Sitzung 3. Ausschussberichte und Berichte zu Informationsveranstaltungen städtischer Referate 1. UA Kinder / Jugend / Schule / Sport (N) - 2. Spielplatzsituation Stiftsbogen 152 - 166 (N) - 3. UA Bau und Wohnen 4. Anträge, Anfragen und Schreiben an die Stadtverwaltung 1. Ampelanlage an der Zöllerstraße (Frau Hofmann, Frau Hegnauer-Schattenhofer, Herr Winklmeier) (BSL) (N) - 2. Budgetanträge bezüglich Trainingskleidung (Grünen-Fraktion) 2 (N) - 3. Organisatorische Änderungen zum Baumschutz und Bauvorhaben im BA 20 Hadern (Grünen-Fraktion) 5. Entscheidungsfälle 1. Stadtbezirksbudget, Initiative "Buchpublikation Never Forget - Never Again", Buchpublikation "Never Forget - Never Again" im September 2019, 500,- € (Direktorium, 09.07.19) Sitzungsvorlage Nr. 14-20 / V 15600 2. Stadtbezirksbudget, Förderverein der Mittelschule an der Guardinistraße e.V., Verbesserung des Bolzplatzes am 04.10.2019, 1.000,- € (Direktorium, 19.07.19) Sitzungsvorlage Nr. 14-20 / V 15552 3. -

Munich Industrial Centers and the Munich Technology Center (MTZ)
Commercial space info May 2021 The Munich Industrial Centers and the Munich Technology Center (MTZ) An engine for SMEs and a nucleus for technology start-ups - The Munich Industrial Center program - IC Nord MTZ Moosach IC Frankfurter Ring IC Westend IC Ostbahnhof IC Laim IC Freiham IC Perlach IC Westpark IC Sendling IC Giesing Published by: City of Munich, Department of Labor and Economic Development Herzog-Wilhelm-Straße 15, 80331 Munich, Germany, http://www.munich.de/business Editor: Andreas Götzendorfer, Tel. +49 (0)89 233-24642 Fax +49 (0)89 233- 27966, mailto: [email protected] May 2021 The Munich Industrial Centers have been an integral component of Munich's economic policy – and a successful example of dedicated development for small and medium-sized businesses (SMEs) – for almost 40 years. The Industrial Centers provide space for small skilled craft firms and small businesses. The long-term objective is to establish a seamless, city-wide network of these centers. A compact design allows the Industrial Centers to optimize their use of land and thereby cut costs, to preserve a healthy mix of living and working opportunities in urban agglomerations, and to improve growth and development prospects for the companies they host. Long-term rental contracts with consistently attractive terms and conditions enable tenants to plan reliably for the future. Premises are initially let as an extended shell to maximize companies' flexibility to tailor the interior to their specific requirements. At the same time, the presence of these centers around the city provides local residence with the guarantee of nearby skilled craft services, as well as preventing lengthy journeys to and from customers.