Arxiv:2108.00578V1 [Cs.CL] 2 Aug 2021
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Song List - by Song - Mr K Entertainment
Main Song List - By Song - Mr K Entertainment Title Artist Disc Track 02:00:00 AM Iron Maiden 1700 5 3 AM Matchbox 20 236 8 4:00 AM Our Lady Peace 1085 11 5:15 Who, The 167 9 3 Spears, Britney 1400 2 7 Prince & The New Power Generation 1166 11 11 Pope, Cassadee 1657 4 17 Cross Canadian Ragweed 803 12 22 Allen, Lily 1413 3 22 Swift, Taylor 1646 15 23 Mike Will Made It & Miley Cyrus 1667 16 33 Smashing Pumpkins 1662 11 45 Shinedown 1190 19 98.6 Keith 1096 4 99 Toto 1150 20 409 Beach Boys, The 989 7 911 Jean, Wyclef & Mary J. Blige 725 4 1215 Strokes 1685 12 1234 Feist 1125 12 1929 Deana Carter 1636 15 1959 Anderson, John 1416 7 1963 New Order 1313 1 1969 Stegall, Keith 1004 13 1973 Blunt, James 1294 16 1979 Smashing Pumpkins 820 4 1982 Estefan, Gloria 153 1 1982 Travis, Randy 367 5 1983 Neon Trees 1522 14 1984 Bowie, David 1455 14 1985 Bowling For Soup 670 5 1994 Aldean, Jason 1647 15 1999 Prince 182 9 Dec-43 Montgomery, John Michael 1715 4 1-2-3 Berry, Len 46 13 # Dream Lennon, John 1154 3 #1 Crush Garbage 215 12 #Selfie Chainsmokers 1666 6 Check Us Out Online at: www.AustinKaraoke.com Main Song List - By Song - Mr K Entertainment (I Know) I'm Losing You Temptations 1199 5 (Love Is Like A) Heatwave Reeves, Martha And The Vandellas 1199 6 (Your(The Angels Love Keeps Wanna Lifting Wear Me) My) Higher Red Shoes And Costello, Elvis 1209 4 Higher Wilson, Jackie 1199 8 (You're My) Soul & Inspiration Righteous Brothers 963 7 (You're) Adorable Martin, Dean 1375 11 1 2 3 4 Feist 939 14 1 Luv E40 & Leviti 1499 9 1, 2 Step Ciara & Missy Elliott 746 5 1, 2, 3 Redlight 1910 Fruitgum Co. -

Complaint For: 14
Electronically FILED by Superior Court of California, County of Los Angeles on 07/09/2021 11:58 AM Sherri R. Carter, Executive Officer/Clerk of Court, by R. Perez,Deputy Clerk 21STCV25257 Assigned for all purposes to: Stanley Mosk Courthouse, Judicial Officer: Rupert Byrdsong 1 David M. Given (SBN 142375) Robert Carroll III (SBN 314345) 2 PHILLIPS, ERLEWINE, GIVEN & CARLIN LLP 39 Mesa Street, Suite 201 - The Presidio 3 San Francisco, CA 94129 Telephone: 415-398-0900 4 Fax: 415-398-0911 5 Email: [email protected] [email protected] 6 7 Attorneys for Plaintiffs 8 9 SUPERIOR COURT OF THE STATE OF CALIFORNIA 10 COUNTY OF LOS ANGELES 11 12 DOUGLAS CAMPBELL THOMSON; JOHN Case No. ARLIN LLP ANTHONY HELLIWELL; and ROBERT C 13 LAYNE SIEBENBERG, 0900 & - The Presidio – COMPLAINT FOR: 14 IVEN IVEN Plaintiffs, G , vs. (1) BREACH OF CONTRACT; 15 (2) BREACH OF IMPLIED COVENANT CHARLES ROGER POMFRET HODGSON, 16 OF GOOD FAITH AND FAIR RLEWINE a/k/a ROGER HODGSON; RICHARD San Francisco, CA 94129 Telephone: (415) 398 E DEALING; , 17 DAVIES; DELICATE MUSIC, a California general partnership; UNIVERSAL MUSIC (3) CONVERSION; 39 Mesa39 Street, 201 Suite CORP., a Delaware Corporation, d/b/a (4) OPEN BOOK ACCOUNT; HILLIPS 18 P UNVERSAL MUSIC PUBLISHING (5) MONEY HAD AND RECEIVED; 19 GROUP; THE AMERICAN SOCIETY OF AND COMPOSERS, AUTHORS AND (6) DECLARATORY RELIEF 20 PUBLISHERS, a New York not-for-profit performing rights organization; and DOES 1- DEMAND FOR JURY TRIAL 21 20, inclusive, 22 Defendants. 23 24 Plaintiffs allege: 1. This lawsuit involves the business dealings of the multi-platinum band 25 Supertramp. -

Karaoke Song Book Karaoke Nights Frankfurt’S #1 Karaoke
KARAOKE SONG BOOK KARAOKE NIGHTS FRANKFURT’S #1 KARAOKE SONGS BY TITLE THERE’S NO PARTY LIKE AN WAXY’S PARTY! Want to sing? Simply find a song and give it to our DJ or host! If the song isn’t in the book, just ask we may have it! We do get busy, so we may only be able to take 1 song! Sing, dance and be merry, but please take care of your belongings! Are you celebrating something? Let us know! Enjoying the party? Fancy trying out hosting or KJ (karaoke jockey)? Then speak to a member of our karaoke team. Most importantly grab a drink, be yourself and have fun! Contact [email protected] for any other information... YYOUOU AARERE THETHE GINGIN TOTO MY MY TONICTONIC A I L C S E P - S F - I S S H B I & R C - H S I P D S A - L B IRISH PUB A U - S R G E R S o'reilly's Englische Titel / English Songs 10CC 30H!3 & Ke$ha A Perfect Circle Donna Blah Blah Blah A Stranger Dreadlock Holiday My First Kiss Pet I'm Mandy 311 The Noose I'm Not In Love Beyond The Gray Sky A Tribe Called Quest Rubber Bullets 3Oh!3 & Katy Perry Can I Kick It Things We Do For Love Starstrukk A1 Wall Street Shuffle 3OH!3 & Ke$ha Caught In Middle 1910 Fruitgum Factory My First Kiss Caught In The Middle Simon Says 3T Everytime 1975 Anything Like A Rose Girls 4 Non Blondes Make It Good Robbers What's Up No More Sex.... -

Tribute to Supertramp Coming to Hht
PRESS RELEASE – August 27, 2018 Susan Carrier (951) 551-5363 [email protected] TRIBUTE TO SUPERTRAMP COMING TO HHT The Historic Hemet Theatre launches Season Three of their Tribute Mania Concert Series on Saturday September 8th with a Tribute to Supertramp by Fools Logic. Back in the 1970's, Supertramp followed an unusual path to success, fusing the style and instrumental dexterity of progressive rock with the wit and melodies of British pop. The results made them one of the most popular British bands of the '70s, topping the charts and filling arenas around the world at a time when their style of music was supposed to have fallen out of fashion. Supertramp's long list of hits include "Give a Little Bit," "Goodbye Stranger," "Take the Long Way Home," "Breakfast in America," "Bloody Well Right," "The Logical Song" and "Dreamer." These days, the legacy of Supertramp lives on through the passion and dedication of Fools Logic. Based in Thousand Oaks, the band travels the west coast, reliving the classic hits of Supertramp founders Rick Davies and Roger Hodgson. Fools Logic band members are Jeff Bryan (keyboards, guitar, vocals), David Druxman (bass, vocals), Ron Hougardy (keyboards, vocals), Patrick Martin (sax, harmonica, clarinet), Adam "Smitty" Smith (drums, vocals), Tom Logic (guitar, vocals). Showtime for all Tribute Mania concerts is 7:00 pm, with doors open at 6:15 pm. Tickets are $22 presale / $25 day of show. Tickets for the Tribute to Supertramp are selling quickly but are expected to be available through day of show. The Tribute Mania Concert Series continues with Tribute to Three Dog Night featuring 3DN (Sept 22), Tribute to The Cars with Heartbeat City (Oct 6), Tribute to Foreigner featuring 4NR (Oct 20), Tribute to Creedence Clearwater Revival with Fortunate Son (Nov 3), Tribute to Neil Diamond with Dean Colley and Hot August Night (Nov 17), Tribute to Queen featuring Queen Nation (Dec 8), and Cash, Killer and the King: a tribute to Johnny Cash, Jerry Lee Lewis and Elvis (Dec 15). -

Goodbye, Stranger Matt Bondurant
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2003 Goodbye, Stranger Matt Bondurant Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] THE FLORIDA STATE UNIVERSITY COLLEGE OF ARTS AND SCIENCES GOODBYE, STRANGER By MATT BONDURANT A Dissertation submitted to the English Department in partial fulfillment of the requirements for the degree of Doctor of Philosophy Degree Awarded: Spring Semester, 2003 Copyright © 2003 Matt Bondurant All Rights Reserved The Members of the Committee approve the dissertation of Matt Bondurant defended on March 29th, 2003. ___________________________ Mark Winegardner Professor Directing Dissertation ___________________________ Leon Golden Outside Committee Member ___________________________ Elizabeth Stuckey-French Committee Member ___________________________ Anne Rowe Committee Member Approved: ______________________________________________________ Hunt Hawkins, Chair, English Department ______________________________________________________ Donald Foss, Dean, College of Arts & Sciences The Office of Graduate Studies has verified and approved the above named committee members. ii For Jane Springer, Seth Tucker, & Stacy Dianne Lowe iii ACKNOWLEDGMENTS Thank you to my director and mentor Mark Winegardner and to the rest of my committee: Anne Rowe, Leon Golden, Elizabeth Stuckey-French. Thank you to the English Department at Florida State University and the Creative Writing Program, my readers including -
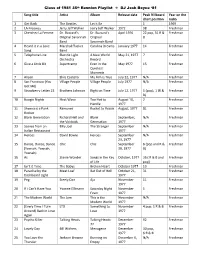
Class of 1981 35Th Reunion Playlist DJ Josh Boyce '81 Song Title Artist
Class of 1981 35th Reunion Playlist DJ Josh Boyce ‘81 Song title Artist Album Release date Peak Billboard Year on the chart position radio 1 Get Back The Beatles Let it Be 1 1969 2 LA Freeway Jerry Jeff Walker Jerry Jeff Walker 1972 98 Freshman 3 Cherchez La Femme Dr. Buzzard’s Dr. Buzzard’s April 1976 22 pop, 31 R & Freshman Original Savannah Original B Band Savannah Band 4 Heard it in a Love Marshall Tucker Carolina Dreams January 1977 14 Freshman Song Band 5 Telephone Line Electric Light A New World May 21, 1977 7 Freshman Orchestra Record 6 Give a Little Bit Supertramp Even in the May 1977 15 Freshman Quietest Moments 7 Alison Elvis Costello My Aim is True July 22, 1977 N/A Freshman 8 San Francisco (You Village People Village People July 1977 N/A Freshman Got Me) 9 Strawberry Letter 23 Brothers Johnson Right on Time July 12, 1977 5 (pop), 1 (R & Freshman B) 10 Boogie Nights Heat Wave Too Hot to August 10, 2 Freshman Handle 1977 11 Sheena is a Punk Ramones Rocket to Russia August, 1977 81 Freshman Rocker 12 Blank Generation Richard Hell and Blank September, N/A Freshman the Voidoids Generation 1977 13 Scenes from an Billy Joel The Stranger September N/A Freshman Italian Restaurant 1977 14 Heroes David Bowie Heroes September N/A Freshman 23, 1977 15 Dance, Dance, Dance Chic Chic September 6 (pop and R & Freshman (Yowsah, Yowsah, 30, 1977 B) Yowsah) 16 As Stevie Wonder Songs in the Key October, 1977 36 ( R & B and Freshman of Life pop) 17 Isn’t it Time The Babys Broken Heart October 1977 13 Freshman 18 Paradise by the Meat Loaf Bat -

Polygram 1983-1992
AUSTRALIAN RECORD LABELS PolyGram 7”, 12” singles & LP’s 1983 to 1992 COMPILED BY MICHAEL DE LOOPER © BIG THREE PUBLICATIONS, MAY 2019 POLYGRAM 7”, 12” SINGLES & LP’S, 1983–1992 POLYGRAM PRODUCT GUIDE –1 = 12” SINGLES, LP’S –2 = CD SINGLES, CD’S (NOT LISTED) –3 = VHS VIDEO (NOT LISTED) –4 = CASSETTE SINGLES, CASSETTES (NOT LISTED) –7 = 7” SINGLES 370, 377—WINDHAM HILL 370 111-1 TEARS OF JOY TUCK & PATTI 1.90 377 008-1 LOVE WARRIORS TUCK & PATTI 1.90 390–397—A & M 390 419-7 LOVE SCARED / LOVE SCARED PART II (LET’S TALK IT OVER) LANCE ELLINGTON 3.91 390 460-7 STONE COLD SOBER / THE RETURN OF MAGGIE BROWN DEL AMITRI 7.90 390 462-7 THE MESSAGE IS LOVE (2 VERSIONS) ARTHUR BAKER 3.90 390 462-1 THE MESSAGE IS LOVE (2 VERSIONS) / THE MESSAGE IS CLUB ARTHUR BAKER 3.90 390 466-7 DIAMOND IN THE DARK / LAST NIGHT CHRIS DE BURGH 6.90 390 471-7 LOVE TOGETHER (2 VERSIONS) L.A. MIX 7.90 390 471-1 LOVE TOGETHER (2 VERSIONS) L.A. MIX 7.90 390 472-7 PERFECT VIEW / WE NEVER MET THE GRACES 3.90 390 474-7 NOTHING EVER HAPPENS / NO HOLDING ON DEL AMITRI 4.90 390 474-1 NOTHING EVER HAPPENS / NO HOLDING ON / SLOWLY, IT’S COMING BACK DEL AMITRI 5.90 390 475-7 I’M A BELIEVER / NO WAY OUT GIANT 6.90 390 476-7 INSIDE OUT / BACK TO WHERE WE STARTED GUN 4.90 390 477-7 WITH A LITTLE LOVE / WINDOW PEOPLE SAM BROWN 4.90 390 477-1 WITH A LITTLE LOVE / WINDOW PEOPLE / DOLLY MIXTURE SAM BROWN 4.90 390 480-7 A CHANGE IS GONNA COME / MY BLOOD THE NEVILLE BROTHERS 3.90 390 484-1 SUPER LOVER (2 VERSIONS) / WHEN WILL I SEE YOU AGAIN BARRY WHITE 6.90 390 486-7 TWO TO MAKE IT RIGHT -

Supertramp (From the 1979 Album BREAKFAST in AMERICA) Transcribed by Tone Jones Words and Music by Rick Davies and Rodger Hodgson
GOODBYE STRANGER As recorded by Supertramp (From the 1979 Album BREAKFAST IN AMERICA) Transcribed by Tone Jones Words and Music by Rick Davies and Rodger Hodgson A D°/A B m7/A A /G D B m Fm D /F ` 4 fr. xx ` 4 fr. xx` ` 4 fr. xx ` ` 4 fr. x ` 4 fr. x ` x 13 fr. x x` 4 fr. A Intro Moderately = 116 A P 8va` 8va 8va 8va 8va 8va 8va 8va 8va 8va 1 e VV VV VV V VV VV VV VV V VV Ie ee4 V V V V V V V V V V V V V V V V V V V V V V V V V Gtr I Rick Davies - Wurlitzer 4 4 4 4 4 4 4 4 4 4 T 4 4 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 A 6 6 6 6 6 6 6 6 B 4 4 4 4 4 4 4 4 B Verse A D°/A B m7/A 8va` 8va ` 8va `8va ` 5 e VV VV VV V VV VV Ie ee V V V V V V V 42 V V V V V V 4 4 4 4 4 4 T 4 6 6 6 6 6 5 5 7 7 7 5 6 6 A 6 6 6 8 8 B 4 4 4 4 4 A D°/A 8va` 8va 8va 8va 8va 8va ` 8 e VV VV VV V VV VV VV Ie ee4 V V V V V V V V V V V V V V V V V 4 4 4 4 4 4 4 T 4 4 4 4 4 4 6 5 5 5 5 5 5 5 5 5 5 7 A 6 6 6 6 6 6 B 4 4 4 4 4 4 B m7/A A 8va 8va `8va ` ` 8va 8va 8va 8va 11 e VV V VV VV VV VV VV V VV Ie ee V V V V 42 V 4 V V V V V V V V V V V V V V V 4 4 4 4 4 4 4 4 4 T 6 6 6 6 4 4 4 4 4 7 7 5 6 6 5 5 5 5 5 5 5 5 A 6 8 8 6 6 6 6 B 4 4 4 4 4 4 4 1979 Generated using the Power Tab Editor by Brad Larsen. -

University of Southampton Research Repository Eprints Soton
University of Southampton Research Repository ePrints Soton Copyright © and Moral Rights for this thesis are retained by the author and/or other copyright owners. A copy can be downloaded for personal non-commercial research or study, without prior permission or charge. This thesis cannot be reproduced or quoted extensively from without first obtaining permission in writing from the copyright holder/s. The content must not be changed in any way or sold commercially in any format or medium without the formal permission of the copyright holders. When referring to this work, full bibliographic details including the author, title, awarding institution and date of the thesis must be given e.g. AUTHOR (year of submission) "Full thesis title", University of Southampton, name of the University School or Department, PhD Thesis, pagination http://eprints.soton.ac.uk UNIVERSITY OF SOUTHAMPTON FACULTY OF HUMANITIES INTERACTIONS BETWEEN CONTEMPORARY AMERICAN INDEPENDENT CINEMA AND POPULAR MUSIC CULTURE By Matthew William Nicholls For the degree of Doctor of Philosophy July 2011 UNIVERSITY OF SOUTHAMPTON ABSTRACT FACULTY OF HUMANITIES Doctor of Philosophy INTERACTIONS BETWEEN CONTEMPORARY AMERICAN INDEPEND- ENT CINEMA AND POPULAR MUSIC CULTURE By Matthew Nicholls In recent years, many American independent films have become increasingly en- gaged with popular music culture and have used various forms of pop music in their soundtracks to various effects. Disparate films from a variety of genres use different forms of popular music in different ways, however these negotiations with pop music and its cultural surroundings have one true implication: that the 'inde- pendentness' (or 'indieness') of these movies is informed, anchored and embellished by their relationships with their soundtracks and/or the representations of or posi- tioning within wider popular music subcultures. -

Elite Karaoke Draft by Artist 2 Pistols Feat
Elite Karaoke Draft by Artist 2 Pistols Feat. Ray J You Know Me (Hed) Planet Earth 2 Pistols Feat. T-Pain & Tay Bartender Dizm Blackout She Got It Other Side 2 Play Feat. Thomas Jules & Renegade Jucxi D 10 Years Careless Whisper Actions & Motives 2 Unlimited Beautiful No Limit Drug Of Choice Twilight Zone Fix Me 20 Fingers Fix Me (Acoustic) Short Dick Man Shoot It Out 21 Demands Through The Iris Give Me A Minute Wasteland 21 Savage Feat. Offset, Metro 10,000 Maniacs Boomin & Travis Scott Because The Night Ghostface Killers Candy Everybody Wants 2Pac Like The Weather Changes More Than This Dear Mama These Are The Days How Do You Want It Trouble Me I Get Around 100 Proof (Aged In Soul) So Many Tears Somebody's Been Sleeping Until The End Of Time 101 Dalmations 2Pac Feat. Dr. Dre Cruella De Vil California Love 10cc 2Pac Feat. Elton John Dreadlock Holiday Ghetto Gospel Good Morning Judge 2Pac Feat. Eminem I'm Not In Love One Day At A Time The Things We Do For Love 2Pac Feat. Eric Williams Things We Do For Love Do For Love 112 2Pac Feat. Notorious B.I.G. Dance With Me Runnin' Peaches & Cream 3 Doors Down Right Here For You Away From The Sun U Already Know Be Like That 112 Feat. Ludacris Behind Those Eyes Hot & Wet Citizen Soldier 112 Feat. Super Cat Dangerous Game Na Na Na Duck & Run 12 Gauge Every Time You Go Dunkie Butt Going Down In Flames 12 Stones Here By Me Arms Of A Stranger Here Without You Far Away It's Not My Time (I Won't Go) Shadows Kryptonite We Are One Landing In London 1910 Fruitgum Co. -
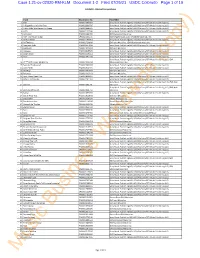
Case 1:21-Cv-02020-RM-KLM Document 1-2 Filed 07/26/21 USDC Colorado Page 1 of 19
Case 1:21-cv-02020-RM-KLM Document 1-2 Filed 07/26/21 USDC Colorado Page 1 of 19 Exhibit B - Musical Compositions Track Registration No. Plaintiff(s) 1 100 PA0001967787 Sony Music Publishing (US) LLC (f/k/a Sony/ATV Music Publishing LLC) 2 A Bigger Picture Called Free PA0002086726 Sony Music Publishing (US) LLC (f/k/a Sony/ATV Music Publishing LLC) 3 A Man Who Was Gonna Die Young PA0001998305 Sony Music Publishing (US) LLC (f/k/a Sony/ATV Music Publishing LLC) 4 A-YO PA0002127346 Sony Music Publishing (US) LLC (f/k/a Sony/ATV Music Publishing LLC) 5 Addiction PA0001162450 EMI Blackwood Music Inc. 6 Ain't Too Proud To Beg EP0000216556 Stone Agate Music, a div. of Jobete Music Co., Inc. 7 All Falls Down PA0001159061 Sony Music Publishing (US) LLC (f/k/a Sony/ATV Music Publishing LLC) 8 All The Boys PA0001729608 EMI April Music Inc. / EMI Blackwood Music Inc. 9 American Ride PA0001657819 Sony Music Publishing (US) LLC (f/k/a Sony/ATV Music Publishing LLC) 10 Amityville PA0001022418 EMI April Music Inc. 11 Amnesia PA0002014595 Sony Music Publishing (US) LLC (f/k/a Sony/ATV Music Publishing LLC) 12 Angel Down PA0002119051 Sony Music Publishing (US) LLC (f/k/a Sony/ATV Music Publishing LLC) 13 Aura PA0001941105 Sony Music Publishing (US) LLC (f/k/a Sony/ATV Music Publishing LLC) Sony Music Publishing (US) LLC (f/k/a Sony/ATV Music Publishing LLC) / EMI 14 B**** Better Have My Money PA0001996394 Blackwood Music Inc. 15 Back On The Ground PA0001909418 Sony Music Publishing (US) LLC (f/k/a Sony/ATV Music Publishing LLC) 16 Back Porch PA0001950797 Sony Music Publishing (US) LLC (f/k/a Sony/ATV Music Publishing LLC) 17 Bad Guy PA0001961425 EMI April Music Inc. -

Schedule Quickprint TKRN-FM
Schedule QuickPrint TKRN-FM 5/15/2021 4AM through 5/15/2021 8AM s: AirTime s: Runtime Schedule: Description 04:00:00a 00:00 Saturday, May 15, 2021 4AM 04:00:00a 02:58 ROCK N' ME / STEVE MILLER BAND 04:02:58a 03:29 WILD NIGHT / VAN MORRISON 04:06:27a 04:02 ESCAPE (THE PINA COLADA SONG) / RUPERT HOLMES 04:10:29a 03:23 VENTURA HIGHWAY / AMERICA 04:13:52a 04:24 ONE OF THESE NIGHTS (ALBUM) / EAGLES 04:18:16a 03:05 HI HI HI / PAUL MC CARTNEY & WINGS 04:21:21a 03:45 STILL THE ONE / ORLEANS 04:25:06a 04:16 LEAN ON ME / BILL WITHERS 04:29:26a 03:30 STOP-SET 04:36:12a 04:22 GOODBYE STRANGER / SUPERTRAMP 04:40:34a 02:45 GET READY / RARE EARTH 04:43:19a 03:45 CROCODILE ROCK / ELTON JOHN 04:47:04a 02:27 EVERLASTING LOVE / CARL CARLTON 04:49:31a 03:05 FEELS LIKE THE FIRST TIME / FOREIGNER 04:52:36a 03:30 STOP-SET 05:00:00a 00:00 Saturday, May 15, 2021 5AM 05:00:00a 03:10 PLAY THAT FUNKY MUSIC / WILD CHERRY 05:03:10a 04:25 SUPERSTITION / STEVIE WONDER 05:07:35a 03:05 DON'T STOP / FLEETWOOD MAC 05:10:40a 04:37 YOU MAKE ME FEEL BRAND NEW / STYLISTICS 05:15:17a 03:29 LET'S GO / CARS 05:18:46a 03:00 MOTHER AND CHILD REUNION / PAUL SIMON 05:21:46a 03:49 DRIFT AWAY / DOBIE GRAY 05:25:35a 03:49 YOU AIN'T SEEN NOTHING YET / BACHMAN-TURNER OVERDRIVE 05:29:28a 03:30 STOP-SET 05:36:14a 04:32 MY LIFE (ALBUM) / BILLY JOEL 05:40:46a 02:30 TEMPTATION EYES / GRASS ROOTS 05:43:16a 03:20 BRICK HOUSE / COMMODORES 05:46:36a 02:28 LOOKIN' OUT MY BACK DOOR / CREEDENCE CLEARWATER REVIVAL 05:49:04a 03:45 DANCING QUEEN / ABBA 05:52:49a 03:30 STOP-SET 06:00:00a 00:00 Saturday,