Ocr: a Statistical Model of Multi-Engine Ocr Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Advanced OCR with Omnipage and Finereader
AAddvvHighaa Technn Centerccee Trainingdd UnitOO CCRR 21050 McClellan Rd. Cupertino, CA 95014 www.htctu.net Foothill – De Anza Community College District California Community Colleges Advanced OCR with OmniPage and FineReader 10:00 A.M. Introductions and Expectations FineReader in Kurzweil Basic differences: cost Abbyy $300, OmniPage Pro $150/Pro Office $600; automating; crashing; graphic vs. text 10:30 A.M. OCR program: Abbyy FineReader www.abbyy.com Looking at options Working with TIFF files Opening the file Zoom window Running OCR layout preview modifying spell check looks for barcodes Blocks Block types Adding to blocks Subtracting from blocks Reordering blocks Customize toolbars Adding reordering shortcut to the tool bar Save and load blocks Eraser Saving Types of documents Save to file Formats settings Optional hyphen in Word remove optional hyphen (Tools > Format Settings) Tables manipulating Languages Training 11:45 A.M. Lunch 1:00 P.M. OCR program: ScanSoft OmniPage www.scansoft.com Looking at options Languages Working with TIFF files SET Tools (see handout) www.htctu.net rev. 9/27/2011 Opening the file View toolbar with shortcut keys (View > Toolbar) Running OCR On-the-fly zoning modifying spell check Zone type Resizing zones Reordering zones Enlargement tool Ungroup Templates Saving Save individual pages Save all files in one document One image, one document Training Format types Use true page for PDF, not Word Use flowing page or retain fronts and paragraphs for Word Optional hyphen in Word Tables manipulating Scheduler/Batch manager: Workflow Speech Saving speech files (WAV) Creating a Workflow 2:30 P.M. Break 2:45 P.M. -

Visual Research Universal Communication Communication of Selling the Narrow Column Square Span Text in Color Change of Impact New Slaves
VISUAL RESEARCH UNIVERSAL COMMUNICATION COMMUNICATION OF SELLING THE NARROW COLUMN SQUARE SPAN TEXT IN COLOR CHANGE OF IMPACT NEW SLAVES ON TYPOGRAPHY by Herbert Bayer Typography is a service art, not a fine art, however pure and elemental the discipline may be. The graphic designer today seems to feel that the typographic means at his disposal have been exhausted. Accelerated by the speed of our time, a wish for new excitement is in the air. “New styles” are hopefully expected to appear. Nothing is more constructive than to look the facts in the face. What are they? The fact that nothing new has developed in recent decades? The boredom of the dead end without signs for a renewal? Or is it the realization that a forced change in search of a “new style” can only bring superficial gain? It seems appropriate at this point to recall the essence of statements made by progressive typographers of the 1920s: Previously used largely as a medium for making language visible, typographic material was discovered to have distinctive optical properties of its own, pointing toward specifically typographic expression. Typographers envisioned possibilities of deeper visual experiences from a new exploitation of the typographic material itself. Typography was for the first time seen not as an isolated discipline and technique, but in context with the ever-widening visual experiences that the picture symbol, photo, film, and television brought. They called for clarity, conciseness, precision; for more articulation, contrast, tension in the color and black and white values of the typographic page. They recognized that in all human endeavors a technology had adjusted to man’s demands; while no marked change or improvement had taken place in man’s most profound invention, printing-writing, since Gutenberg. -

OCR Pwds and Assistive Qatari Using OCR Issue No
Arabic Optical State of the Smart Character Art in Arabic Apps for Recognition OCR PWDs and Assistive Qatari using OCR Issue no. 15 Technology Research Nafath Efforts Page 04 Page 07 Page 27 Machine Learning, Deep Learning and OCR Revitalizing Technology Arabic Optical Character Recognition (OCR) Technology at Qatar National Library Overview of Arabic OCR and Related Applications www.mada.org.qa Nafath About AboutIssue 15 Content Mada Nafath3 Page Nafath aims to be a key information 04 Arabic Optical Character resource for disseminating the facts about Recognition and Assistive Mada Center is a private institution for public benefit, which latest trends and innovation in the field of Technology was founded in 2010 as an initiative that aims at promoting ICT Accessibility. It is published in English digital inclusion and building a technology-based community and Arabic languages on a quarterly basis 07 State of the Art in Arabic OCR that meets the needs of persons with functional limitations and intends to be a window of information Qatari Research Efforts (PFLs) – persons with disabilities (PWDs) and the elderly in to the world, highlighting the pioneering Qatar. Mada today is the world’s Center of Excellence in digital work done in our field to meet the growing access in Arabic. Overview of Arabic demands of ICT Accessibility and Assistive 11 OCR and Related Through strategic partnerships, the center works to Technology products and services in Qatar Applications enable the education, culture and community sectors and the Arab region. through ICT to achieve an inclusive community and educational system. The Center achieves its goals 14 Examples of Optical by building partners’ capabilities and supporting the Character Recognition Tools development and accreditation of digital platforms in accordance with international standards of digital access. -

ABBYY Finereader Engine OCR
ABBYY FineReader Engine Performance Guide Integrating optical character recognition (OCR) technology will effectively extend the functionality of your application. Excellent performance of the OCR component is one of the key factors for high customer satisfaction. This document provides information on general OCR performance factors and the possibilities to optimize them in the Software Development Kit ABBYY FineReader Engine. By utilizing its advanced capabilities and options, the high OCR performance can be improved even further for optimal customer experience. When measuring OCR performance, there are two major parameters to consider: RECOGNITION ACCURACY PROCESSING SPEED Which Factors Influence the OCR Accuracy and Processing Speed? Image type and Image image source quality OCR accuracy and Processing System settings processing resources speed Document Application languages architecture Recognition speed and recognition accuracy can be significantly improved by using the right parameters in ABBYY FineReader Engine. Image Type and Image Quality Images can come from different sources. Digitally created PDFs, screenshots of computer and tablet devices, image Key factor files created by scanners, fax servers, digital cameras Image for OCR or smartphones – various image sources will lead to quality = different image types with different level of image quality. performance For example, using the wrong scanner settings can cause “noise” on the image, like random black dots or speckles, blurred and uneven letters, or skewed lines and shifted On the other hand, processing ‘high-quality images’ with- table borders. In terms of OCR, this is a ‘low-quality out distortions reduces the processing time. Additionally, image’. reading high-quality images leads to higher accuracy results. Processing low-quality images requires high computing power, increases the overall processing time and deterio- Therefore, it is recommended to use high-quality images rates the recognition results. -

Smooth Writing with In-Line Formatting Louise S
NESUG 2007 Posters Smooth Writing with In-Line Formatting Louise S. Hadden, Abt Associates Inc., Cambridge, MA ABSTRACT PROC TEMPLATE and ODS provide SAS® programmers with the tools to create customized reports and tables that can be used multiple times, for multiple projects. For ad hoc reporting or the exploratory or design phase of creating custom reports and tables, SAS® provides us with an easy option: in-line formatting. There will be a greater range of in-line formatting available in SAS 9.2, but the technique is still useful today in SAS versions 8.2 and 9.1, in a variety of procedures and output destinations. Several examples of in-line formatting will be presented, including formatting titles, footnotes and specific cells, bolding specified lines, shading specified lines, and publishing with a custom font. INTRODUCTION In-line formatting within procedural output is generally limited to three procedures: PROC PRINT, PROC REPORT and PROC TABULATE. The exception to this rule is in-line formatting with the use of ODS ESCAPECHAR, which will be briefly discussed in this paper. Even without the use of ODSESCAPECHAR, the number of options with in- line formatting is still exciting and almost overwhelming. As I was preparing to write this paper, I found that I kept thinking of more ways to customize output than would be possible to explore at any given time. The scope of the paper therefore will be limited to a few examples outputting to two destination “families”, ODS PRINTER (RTF and PDF) and ODS HTML (HTML4). The examples presented are produced using SAS 9.1.3 (SP4) on a Microsoft XP operating system. -

Multimedia Foundations Glossary of Terms Chapter 5 – Page Layout
Multimedia Foundations Glossary of Terms Chapter 5 – Page Layout Body Copy The main text of a published document or advertisement. Border A visible outline or stroke denoting the outer frame of a design element such as a table cell, text box, or graphic. A border’s width and style can vary according to the aesthetic needs or preferences of the designer. Box Model Or CSS Box Model. A layout and design convention used in CSS for wrapping HTML text and images in a definable box consisting of: margins, borders, and padding. Cell The editable region of a data table or grid defined by the intersection of a row and column. Chunking The visual consolidation of related sentences or ideas into small blocks of information that can be quickly and easily digested (e.g. paragraphs, lists, callouts, text boxes, etc.). Column The vertically aligned cells in a data table or grid. Dynamic Page A multimedia page with content that changes (often) over time or with each individual viewing experience. F-Layout A layout design where the reader’s gaze is directed through the page in a pattern that resembles the letter F. Fixed Layout A multimedia layout where the width of the page (or wrapper) is constrained to a predetermined width and/or height. Floating Graphic The layout of a graphic on a page whereby the adjacent text wraps around it to the left and/or right. Fluid Layout Or liquid layout. A multimedia layout where the width of the page (or wrapper) is set to a percentage of the current user’s browser window size. -

2010 Type Quiz
Text TypeCon 2010 Typographic Quiz Here’s How It Works 30+ Questions to Test Your Typographic Smarts Divided Into Two Parts Part One • 12 Questions (OK, 17) • First right answer to each question wins a prize • Your proctor is the arbiter of answer correctness Part Two • 18 Questions • Answers should be put on “quiz” sheets • Every correct answer to a multiple part question counts as a point • 33 Possible right answers What’s it worth? • There are the bragging rights... • How about the the Grand Prize of the complete Monotype OpenType Library of over 1000 fonts? There’s More... • Something special from FontShop • Gimme hats from Font Bureau • Industrial strength prizes from House Industries • TDC annual complements of the TDC And Even More... • Posters from Hamilton Wood Type Museum • Complete OpenType Font families from Fonts.com • Books from Mark Batty Publisher • Fantastic stuff from P22 And Even More... • Fonts & books & lots of great things from Linotype • Great Prizes from Veer – including the very desirable “Kern” sweatshirt • Font packs and comics from Active Images Over 80 prizes Just about everyone can win something Some great companies • Active Images • Font Bureau • Font Shop • Hamilton Wood Type Museum • House Industries • Linotype • Mark Batty Publisher • Monotype Imaging • P22 • Type Directors Club • Veer Awards • Typophile of the Year • The Doyald Young Typographic Powerhouse Award • The Fred Goudy Honorable Mention • Typographer’s Apprentice (Nice Try) • Typographically Challenged Note: we’re in L.A., so some questions may -

Draft Student Name: Teacher
Draft Student Name: ______________________ Teacher: ______________________ Date: ___________ District: Johnston Assessment: 9_12 Business and IT BM10 - Microsoft Word and PowerPoint Test 1 Description: Quiz 3 Form: 501 Draft 1. What is the process of changing the way characters appear, both on screen and in print, to improve document readability? A. Text formatting B. Paragraph formatting C. Character formatting D. Document formatting 2. To make text appear in a smaller font size below the middle point of the line, which character formatting effect is applied? A. Superscript B. Strikethrough C. Subscript D. Italic 3. In Microsoft Word, what is the name of the group formatting characteristics called? A. Style B. Effects C. Cluster D. Group 4. Which option on the Apply Styles dialog box changes the settings for a selected style? A. Change Styles B. Edit C. Modify D. New Style 5. How are different underline styles selected when applying the underline font format to selected text? A. Choose the Underline drop-down arrow on the Home Ribbon to select various underline styles B. Right-click underlined text and choose underline styles from the Shortcut Menu C. Select the underlined text, then choose Underline Styles from the Insert Ribbon D. Double-click underlined text and choose Underline Styles from the Shortcut Menu 6. Which command on the Home Ribbon applies a shadow, glow, or reflection to selected text or paragraphs? A. Text Effects B. Text Highlight Color C. Shading D. Color 7. Which command on the Home Ribbon allows a user to change the case of selected text to all uppercase, lowercase, sentence case, toggle case, or capitalize each word? A. -
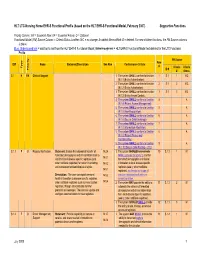
HL7 LTC-Nursing Home EHR-S Functional Profile (Based on the HL7 EHR-S Functional Model, February 2007) Supportive Functions
HL7 LTC-Nursing Home EHR-S Functional Profile (based on the HL7 EHR-S Functional Model, February 2007) Supportive Functions Priority Column: EN = Essential Now; EF = Essential Future; O = Optional Functional Model (FM) Source Column -- Criteria Status is either: N/C = no change; A=added; M=modified; D = deleted. For new children functions, the FM Source columns is blank. Blue, Underscored text = addition to text from the HL7 EHR-S Functional Model; Strikethrough text = HL7 EHR-S Functional Model text deleted for the LTC Functional Profile FM Source Row ID# Name Statement/Description See Also Conformance Criteria # Type Criteria Criteria Priority ID # # Status S.1 H EN Clinical Support 1. The system SHALL conform to function 1 S.1 1 N/C IN.1.1 (Entity Authentication). 2. The system SHALL conform to function 2 S.1 2 N/C IN.1.2 (Entity Authorization). 3. The system SHALL conform to function 3 S.1 3 N/C IN.1.3 (Entity Access Control). 4. The system SHALL conform to function 4 A IN.1.4 (Patient Access Management) 5. The system SHALL conform to function 5 A IN.1.5 (Non-Repudiation) 6. The system SHALL conform to function 6 A IN.1.6 (Secure Data Exchange) 7. The system SHALL conform to function 7 A IN.1.8 (Information Attestation) 8. The system SHALL conform to function 8 A IN.1.9 (Patient Privacy and Confidentiality) 9. The system SHALL conform to function 9 A IN.1.10 (Secure Data Routing – LTC) S.1.1 F O Registry Notification Statement: Enable the automated transfer of IN.2.4 1. -

INTERNATIONAL TYPEFACE CORPORATION, to an Insightful 866 SECOND AVENUE, 18 Editorial Mix
INTERNATIONAL CORPORATION TYPEFACE UPPER AND LOWER CASE , THE INTERNATIONAL JOURNAL OF T YPE AND GRAPHI C DESIGN , PUBLI SHED BY I NTE RN ATIONAL TYPEFAC E CORPORATION . VO LUME 2 0 , NUMBER 4 , SPRING 1994 . $5 .00 U .S . $9 .90 AUD Adobe, Bitstream &AutologicTogether On One CD-ROM. C5tta 15000L Juniper, Wm Utopia, A d a, :Viabe Fort Collection. Birc , Btarkaok, On, Pcetita Nadel-ma, Poplar. Telma, Willow are tradmarks of Adobe System 1 *animated oh. • be oglitered nt certain Mrisdictions. Agfa, Boris and Cali Graphic ate registered te a Ten fonts non is a trademark of AGFA Elaision Miles in Womb* is a ma alkali of Alpha lanida is a registered trademark of Bigelow and Holmes. Charm. Ea ha Fowl Is. sent With the purchase of the Autologic APS- Stempel Schnei Ilk and Weiss are registimi trademarks afF mdi riot 11 atea hmthille TypeScriber CD from FontHaus, you can - Berthold Easkertille Rook, Berthold Bodoni. Berthold Coy, Bertha', d i i Book, Chottiana. Colas Larger. Fermata, Berthold Garauannt, Berthold Imago a nd Noire! end tradematts of Bern select 10 FREE FONTS from the over 130 outs Berthold Bodoni Old Face. AG Book Rounded, Imaleaa rd, forma* a. Comas. AG Old Face, Poppl Autologic typefaces available. Below is Post liedimiti, AG Sitoploal, Berthold Sr tapt sad Berthold IS albami Book art tr just a sampling of this range. Itt, .11, Armed is a trademark of Haas. ITC American T}pewmer ITi A, 31n. Garde at. Bantam, ITC Reogutat. Bmigmat Buick Cad Malt, HY Bis.5155a5, ITC Caslot '2114, (11 imam. -

2.1 Typography
Working With Type FUN ROB MELTON BENSON POLYTECHNIC HIGH SCHOOL WITH PORTLAND, OREGON TYPE Points and picas If you are trying to measure something very short or very thin, then inches are not precise enough. Originally English printers devised picas to precisely measure the width of type and points to precise- ly measure the height of type. Now those terms are used interchangeably. There are 12 points in one pica, 6 picas in one inch — or 72 points in one inch. This is a 1-point line (or rule). 72 of these would be one inch thick. This is a 12-point rule. It is 1 pica thick. Six of these would be one inch thick. POINTS PICAS INCHES Thickness of rules I Lengths of rules Lengths of stories I Sizes of type (headlines, text, IWidths of text, photos, cutlines, IDepths of photos and ads cutlines, etc.) gutters, etc. (though some publications use IAll measurements smaller than picas for photo depths) a pica. Type sizes Type is measured in points. Body type is 7–12 point type, while display type starts at 14 point and goes to 127 point type. Traditionally, standard point sizes are 14, 18, 24, 30, 36, 42, 48, 54, 60 and 72. Using a personal computer, you can create headlines in one-point increments beginning at 4 point and going up to 650 point. Most page designers still begin with these standard sizes. The biggest headline you are likely to see is a 72 pt. head and it is generally reserved for big stories on broadsheet newspapers. -
![Journal of the Text Encoding Initiative, Issue 5 | June 2013, « TEI Infrastructures » [Online], Online Since 19 April 2013, Connection on 04 March 2020](https://docslib.b-cdn.net/cover/4642/journal-of-the-text-encoding-initiative-issue-5-june-2013-%C2%AB-tei-infrastructures-%C2%BB-online-online-since-19-april-2013-connection-on-04-march-2020-1254642.webp)
Journal of the Text Encoding Initiative, Issue 5 | June 2013, « TEI Infrastructures » [Online], Online Since 19 April 2013, Connection on 04 March 2020
Journal of the Text Encoding Initiative Issue 5 | June 2013 TEI Infrastructures Tobias Blanke and Laurent Romary (dir.) Electronic version URL: http://journals.openedition.org/jtei/772 DOI: 10.4000/jtei.772 ISSN: 2162-5603 Publisher TEI Consortium Electronic reference Tobias Blanke and Laurent Romary (dir.), Journal of the Text Encoding Initiative, Issue 5 | June 2013, « TEI Infrastructures » [Online], Online since 19 April 2013, connection on 04 March 2020. URL : http:// journals.openedition.org/jtei/772 ; DOI : https://doi.org/10.4000/jtei.772 This text was automatically generated on 4 March 2020. TEI Consortium 2011 (Creative Commons Attribution-NoDerivs 3.0 Unported License) 1 TABLE OF CONTENTS Editorial Introduction to the Fifth Issue Tobias Blanke and Laurent Romary PhiloLogic4: An Abstract TEI Query System Timothy Allen, Clovis Gladstone and Richard Whaling TAPAS: Building a TEI Publishing and Repository Service Julia Flanders and Scott Hamlin Islandora and TEI: Current and Emerging Applications/Approaches Kirsta Stapelfeldt and Donald Moses TEI and Project Bamboo Quinn Dombrowski and Seth Denbo TextGrid, TEXTvre, and DARIAH: Sustainability of Infrastructures for Textual Scholarship Mark Hedges, Heike Neuroth, Kathleen M. Smith, Tobias Blanke, Laurent Romary, Marc Küster and Malcolm Illingworth The Evolution of the Text Encoding Initiative: From Research Project to Research Infrastructure Lou Burnard Journal of the Text Encoding Initiative, Issue 5 | June 2013 2 Editorial Introduction to the Fifth Issue Tobias Blanke and Laurent Romary 1 In recent years, European governments and funders, universities and academic societies have increasingly discovered the digital humanities as a new and exciting field that promises new discoveries in humanities research.