Notes to Readers: • This PDF Contains Both Slides and Notes. the Notes Contain Most of the Content
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Just Another Perl Hack Neil Bowers1 Canon Research Centre Europe
Weblint: Just Another Perl Hack Neil Bowers1 Canon Research Centre Europe Abstract Weblint is a utility for checking the syntax and style of HTML pages. It was inspired by lint [15], which performs a similar function for C and C++ programmers. Weblint does not aspire to be a strict SGML validator, but to provide helpful comments for humans. The importance of quality assurance for web sites is introduced, and one particular area, validation of HTML, is described in more detail. The bulk of the paper is devoted to weblint: what it is, how it is used, and the design and implementation of the current development version. 1. Introduction The conclusion opens with a summary of the information and opinions given in this paper. A Web sites are becoming an increasingly critical part of selection of the lessons learned over the last four years how many companies do business. For many companies is given, followed by plans for the future, and related web sites are their business. It is therefore critical that ideas. owners of web sites perform regular testing and analysis, to ensure quality of service. 2. Web Site Quality Assurance There are many different checks and analyses which The following are some of the questions you should be you can run on a site. For example, how usable is your asking yourself if you have a web presence. I have site when accessed via a modem? An incomplete list of limited the list to those points which are relevant to similar analyses are given at the start of Section 2. -
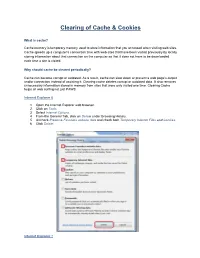
Clearing of Cache & Cookies
Clearing of Cache & Cookies What is cache? Cache memory is temporary memory used to store information that you accessed when visiting web sites. Cache speeds up a computer’s connection time with web sites that have been visited previously by locally storing information about that connection on the computer so that it does not have to be downloaded each time a site is visited. Why should cache be cleared periodically? Cache can become corrupt or outdated. As a result, cache can slow down or prevent a web page’s output and/or connection instead of assisting it. Clearing cache deletes corrupt or outdated data. It also removes unnecessary information stored in memory from sites that were only visited one time. Clearing Cache helps all web surfing not just PAWS. Internet Explorer 8 1. Open the Internet Explorer web browser. 2. Click on Tools. 3. Select Internet Options. 4. From the General Tab, click on Delete under Browsing History. 5. Uncheck Preserve Favorites website data and check both Temporary Internet Files and Cookies. 6. Click Delete. Internet Explorer 7 1. Open the Internet Explorer web browser. 2. Click on Tools. 3. Click on Internet Options. 4. Click on Delete under Browsing History. 5. Click Delete cookies. 6. When prompted, click Yes. 7. Click on Delete Internet Files. 8. When prompted, click Yes. 9. Click Close. 10. Click OK. 11. Close and reopen the browser for the changes to go into effect. Internet Explorer 6 1. Open the Internet Explorer web browser. 2. Click on Tools. 3. Click on Internet Options. 4. -
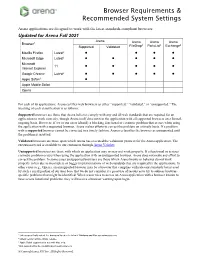
Browser Requirements & Recommended
Browser Requirements & Recommended System Settings Arena applications are designed to work with the latest standards-compliant browsers. Updated for Arena Fall 2021 Arena 1 Arena Arena Arena Browser 4 4 4 Supported Validated FileDrop PartsList Exchange Mozilla Firefox Latest2 l l l l Microsoft Edge Latest2 l l l l l Microsoft 11 l l l l l Internet Explorer Google Chrome Latest2 l l l l l Apple Safari3 l Apple Mobile Safari Opera For each of its applications, Arena certifies web browsers as either “supported,” “validated,” or “unsupported.” The meaning of each classification is as follows: Supported browsers are those that Arena believes comply with any and all web standards that are required for an application to work correctly, though Arena itself does not test the application with all supported browsers on a formal, ongoing basis. However, if we or our users identify a blocking functional or cosmetic problem that occurs when using the application with a supported browser, Arena makes efforts to correct the problem on a timely basis. If a problem with a supported browser cannot be corrected in a timely fashion, Arena reclassifies the browser as unsupported until the problem is resolved. Validated browsers are those upon which Arena has executed the validation protocol for the Arena application. The execution record is available to our customers through Arena Validate. Unsupported browsers are those with which an application may or may not work properly. If a functional or serious cosmetic problem occurs when using the application with an unsupported browser, Arena does not make any effort to correct the problem. -

Marcia Knous: My Name Is Marcia Knous
Olivia Ryan: Can you just state your name? Marcia Knous: My name is Marcia Knous. OR: Just give us your general background. How did you come to work at Mozilla and what do you do for Mozilla now? MK: Basically, I started with Mozilla back in the Netscape days. I started working with Mozilla.org shortly after AOL acquired Netscape which I believe was in like the ’99- 2000 timeframe. I started working at Netscape and then in one capacity in HR shortly after I moved working with Mitchell as part of my shared responsibility, I worked for Mozilla.org and sustaining engineering to sustain the communicator legacy code so I supported them administratively. That’s basically what I did for Mozilla. I did a lot of I guess what you kind of call of blue activities where we have a process whereby people get access to our CVS repository so I was the gatekeeper for all the CVS forms and handle all the bugs that were related to CVS requests, that kind of thing. Right now at Mozilla, I do quality assurance and I run both our domestic online store as well as our international store where we sell all of our Mozilla gear. Tom Scheinfeldt: Are you working generally alone in small groups? In large groups? How do you relate to other people working on the project? MK: Well, it’s a rather interesting project. My capacity as a QA person, we basically relate with the community quite a bit because we have a very small internal QA organization. -
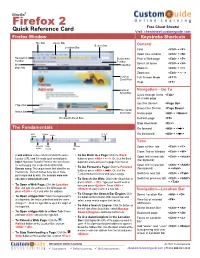
Firefox 2 Free Cheat Sheets! Quick Reference Card Visit: Cheatsheet.Customguide.Com Firefox Window Keystroke Shortcuts
® Mozilla Firefox 2 Free Cheat Sheets! Quick Reference Card Visit: cheatsheet.customguide.com Firefox Window Keystroke Shortcuts Title Bar Menu Bar Search bar General Location Bar Find <Ctrl> + <F> Open new window <Ctrl> + <N> Navigation Bookmarks Print a Web page <Ctrl> + <P> Toolbar Toolbar Select all items <Ctrl> + <A> Web Tabs Bar page tab Zoom in <Ctrl> + <+> Zoom out <Ctrl> + < - > Vertical Full Screen Mode <F11> Scroll Box Help <F1> Vertical Navigation—Go To Scroll Bar Cycle through items <Tab> on a web page Up One Screen <Page Up> Hyperlink Down One Screen <Page Down> Horizontal Status Bar Scroll Bar Home page <Alt> + <Home> Horizontal Scroll Box Refresh page <F5> Stop download <Esc> The Fundamentals Go forward <Alt> + < → > Back Search Reload Home Go backward <Alt> + < ← > button Bar Tabs Forward Stop Location Open a New Tab <Ctrl> + <T> button button Bar Close Tab or Window <Ctrl> + <W> • A web address is also called a Uniform Resource • To Go Back to a Page: Click the Back Open link in new tab <Ctrl> + <click> Locator (URL) and it is made up of several parts: button or press <Alt> + <←>. Or, click the Back (background) http:// Hypertext Transfer Protocol, the set of rules button list arrow and select a page from the list. for exchanging files on the World Wide Web. Open link in new tab <Ctrl> + <Shift> To Go Forward a Page: Click the Forward Domain name: The unique name that identifies an • (foreground) + <click> button or press <Alt> + <→>. Or, click the Internet site. Domain names have two or more Switch to next tab <Ctrl> + <Tab> parts separated by dots. -

Arena Training Guide for Administrators Table of Contents
Arena training guide for administrators Table of contents Preface 4 About this guide 4 Get to know Axiell 4 About Arena 5 Liferay 5 Portlets 5 Language handling 5 Styling 5 Arena architecture 6 Administration in Arena 7 Arena articles 7 Signing in to Arena 7 Signing in to Liferay 8 The Arena administration user interface 8 Accounts 11 User types in Arena 11 Permissions 12 Managing users in Liferay 14 Managing a roles in Liferay 16 Arena portal site administration 17 Admin: installation details 17 Site settings 19 Managing pages 21 Page permissions 21 Navigation 21 Configuring pages 21 Creating a page 22 Deleting a page 23 Arena Nova 25 Focus shortcuts 25 That’s how it works-articles 25 News articles 26 Event articles 26 Branch articles 26 FAQ articles 27 Image resources and image handling 27 Portlets in Arena 28 Symbols in the list of portlets 28 Portlets required for basic Arena functionality 28 Placement of portlets 29 Configuring portlets 30 The control toolbar 30 Look and feel 30 2 Assigning user permissions to portlets and pages 30 Liferay articles 32 Creating a Liferay article 32 Adding a Liferay article on a page 32 Arena articles 33 Approving articles 33 Handling abuse and reviews 34 Admin: moderation 34 Searching in catalogue records 36 Single words 36 Phrases 36 Multiple words 36 Truncation 36 Boolean operators 36 Fuzzy search and the similarity factor 36 Search parameters for catalogue records 37 Search parameters for Arena articles 40 Examples 40 Linking and syntaxes 41 Dynamic links 41 Syntax for similar titles 42 Syntax for other titles by the same author 42 Syntax for dynamic news list 42 3 Preface Simple, stylish and engaging, Arena is perfect for archives, libraries and museums to showcase and organize their collections in the public domain. -

Peer Participation and Software
Peer Participation and Software This report was made possible by the grants from the John D. and Cath- erine T. MacArthur Foundation in connection with its grant-making initiative on Digital Media and Learning. For more information on the initiative visit www.macfound.org. The John D. and Catherine T. MacArthur Foundation Reports on Digital Media and Learning Peer Participation and Software: What Mozilla Has to Teach Government by David R. Booth The Future of Learning Institutions in a Digital Age by Cathy N. Davidson and David Theo Goldberg with the assistance of Zoë Marie Jones The Future of Thinking: Learning Institutions in a Digital Age by Cathy N. Davidson and David Theo Goldberg with the assistance of Zoë Marie Jones New Digital Media and Learning as an Emerging Area and “Worked Examples” as One Way Forward by James Paul Gee Living and Learning with New Media: Summary of Findings from the Digital Youth Project by Mizuko Ito, Heather Horst, Matteo Bittanti, danah boyd, Becky Herr-Stephenson, Patricia G. Lange, C. J. Pascoe, and Laura Robinson with Sonja Baumer, Rachel Cody, Dilan Mahendran, Katynka Z. Martínez, Dan Perkel, Christo Sims, and Lisa Tripp Young People, Ethics, and the New Digital Media: A Synthesis from the GoodPlay Project by Carrie James with Katie Davis, Andrea Flores, John M. Francis, Lindsay Pettingill, Margaret Rundle, and Howard Gardner Confronting the Challenges of Participatory Culture: Media Education for the 21st Century by Henry Jenkins (P.I.) with Ravi Purushotma, Margaret Weigel, Katie Clinton, and Alice J. Robison The Civic Potential of Video Games by Joseph Kahne, Ellen Middaugh, and Chris Evans Peer Production and Software What Mozilla Has to Teach Government David R. -

Discontinued Browsers List
Discontinued Browsers List Look back into history at the fallen windows of yesteryear. Welcome to the dead pool. We include both officially discontinued, as well as those that have not updated. If you are interested in browsers that still work, try our big browser list. All links open in new windows. 1. Abaco (discontinued) http://lab-fgb.com/abaco 2. Acoo (last updated 2009) http://www.acoobrowser.com 3. Amaya (discontinued 2013) https://www.w3.org/Amaya 4. AOL Explorer (discontinued 2006) https://www.aol.com 5. AMosaic (discontinued in 2006) No website 6. Arachne (last updated 2013) http://www.glennmcc.org 7. Arena (discontinued in 1998) https://www.w3.org/Arena 8. Ariadna (discontinued in 1998) http://www.ariadna.ru 9. Arora (discontinued in 2011) https://github.com/Arora/arora 10. AWeb (last updated 2001) http://www.amitrix.com/aweb.html 11. Baidu (discontinued 2019) https://liulanqi.baidu.com 12. Beamrise (last updated 2014) http://www.sien.com 13. Beonex Communicator (discontinued in 2004) https://www.beonex.com 14. BlackHawk (last updated 2015) http://www.netgate.sk/blackhawk 15. Bolt (discontinued 2011) No website 16. Browse3d (last updated 2005) http://www.browse3d.com 17. Browzar (last updated 2013) http://www.browzar.com 18. Camino (discontinued in 2013) http://caminobrowser.org 19. Classilla (last updated 2014) https://www.floodgap.com/software/classilla 20. CometBird (discontinued 2015) http://www.cometbird.com 21. Conkeror (last updated 2016) http://conkeror.org 22. Crazy Browser (last updated 2013) No website 23. Deepnet Explorer (discontinued in 2006) http://www.deepnetexplorer.com 24. Enigma (last updated 2012) No website 25. -

Enabling TLS 1.2 in Major Browsers
Enabling TLS 1.2 in Major Browsers Table of Contents Updating Microsoft Internet Explorer ...................................................................................................................................................... 2 Enabling or Disabling TLS Protocols in Internet Explorer .................................................................................................................... 2 Updating Mozilla Firefox ........................................................................................................................................................................... 3 Enabling or Disabling TLS Protocols in Firefox .................................................................................................................................... 4 Updating Google Chrome ......................................................................................................................................................................... 5 Enabling or Disabling TLS Protocols in Chrome .................................................................................................................................. 5 Updating Apple Safari ............................................................................................................................................................................... 7 Enabling or Disabling TLS Protocols in Apple Safari ............................................................................................................................ 7 Appendix -

Development Production Line the Short Story
Development Production Line The Short Story Jene Jasper Copyright © 2007-2018 freedumbytes.dev.net (Free Dumb Bytes) Published 3 July 2018 4.0-beta Edition While every precaution has been taken in the preparation of this installation manual, the publisher and author assume no responsibility for errors or omissions, or for damages resulting from the use of the information contained herein. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. To get an idea of the Development Production Line take a look at the following Application Integration overview and Maven vs SonarQube Quality Assurance reports comparison. 1. Operating System ......................................................................................................... 1 1.1. Windows ........................................................................................................... 1 1.1.1. Resources ................................................................................................ 1 1.1.2. Desktop .................................................................................................. 1 1.1.3. Explorer .................................................................................................. 1 1.1.4. Windows 7 Start Menu ................................................................................ 2 1.1.5. Task Manager replacement ........................................................................... 3 1.1.6. Resource Monitor ..................................................................................... -

Unix Quickref.Dvi
Summary of UNIX commands Table of Contents df [dirname] display free disk space. If dirname is omitted, 1. Directory and file commands 1994,1995,1996 Budi Rahardjo ([email protected]) display all available disks. The output maybe This is a summary of UNIX commands available 2. Print-related commands in blocks or in Kbytes. Use df -k in Solaris. on most UNIX systems. Depending on the config- uration, some of the commands may be unavailable 3. Miscellaneous commands du [dirname] on your site. These commands may be a commer- display disk usage. cial program, freeware or public domain program that 4. Process management must be installed separately, or probably just not in less filename your search path. Check your local documentation or 5. File archive and compression display filename one screenful. A pager similar manual pages for more details (e.g. man program- to (better than) more. 6. Text editors name). This reference card, obviously, cannot de- ls [dirname] scribe all UNIX commands in details, but instead I 7. Mail programs picked commands that are useful and interesting from list the content of directory dirname. Options: a user's point of view. 8. Usnet news -a display hidden files, -l display in long format 9. File transfer and remote access mkdir dirname Disclaimer make directory dirname The author makes no warranty of any kind, expressed 10. X window or implied, including the warranties of merchantabil- more filename 11. Graph, Plot, Image processing tools ity or fitness for a particular purpose, with regard to view file filename one screenfull at a time the use of commands contained in this reference card. -

Developing an Open Source Option for NASA Software
Developing An Open Source Option for NASA Software Patrick J. Moran NASA Ames Research Center, M/S T27A-2 Moffett Field, CA, 94035, USA [email protected] NAS Technical Report NAS-03-nnn April 7,2003 Abstract We present arguments in favor of developing an Open Source option for NASA software; in particular we discuss how Open Source is compatible with NASA’s mission. We compare and contrast several of the leading Open Source licenses, and propose one - the Mozilla license - for use by NASA. We also address some of the related issues for NASA with respect to Open Source. In particular, we dis- cuss some of the elements in the “External Release of NASA Software” document (NPG 2210.1A) that will likely have to be changed in order to make Open Source a’reality withm the agency. Contents 1 Introduction 3 2 Why Open Source Software? 4 2.1 NASA Perspective ........................... 4 2.2 Software Users’ Perspective ...................... 5 2.3 Software Developers’ Perspective ................... 5 2.4 PITAC Perspective ........................... 6 2.5 Academia Perspective .......................... 6 2.6 Department of Energy Perspective ................... 7 3 The Leading Open Source Licenses 7 3.1 GNU General Public License ...................... 7 3.2 GNU Lesser General Public License .................. 8 3.3 Mozilla Public License ......................... 8 3.4 BSD License .............................. 8 1 4 License Properties 9 4.1 Recognized by the Open Source Initiative ............... 9 4.2 Attribution Required ........................... 9 4.3 Redistribution Allowed ......................... 10 4.4 License Trumps in Derivative Works .................. 10 4.5 Derivatives Must Be Open Source Software .............. 10 4.6 Commercialization Allowed .....................