Empirical Studies of Performance Bugs and Performance Analysis Approaches for Software Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Just Another Perl Hack Neil Bowers1 Canon Research Centre Europe
Weblint: Just Another Perl Hack Neil Bowers1 Canon Research Centre Europe Abstract Weblint is a utility for checking the syntax and style of HTML pages. It was inspired by lint [15], which performs a similar function for C and C++ programmers. Weblint does not aspire to be a strict SGML validator, but to provide helpful comments for humans. The importance of quality assurance for web sites is introduced, and one particular area, validation of HTML, is described in more detail. The bulk of the paper is devoted to weblint: what it is, how it is used, and the design and implementation of the current development version. 1. Introduction The conclusion opens with a summary of the information and opinions given in this paper. A Web sites are becoming an increasingly critical part of selection of the lessons learned over the last four years how many companies do business. For many companies is given, followed by plans for the future, and related web sites are their business. It is therefore critical that ideas. owners of web sites perform regular testing and analysis, to ensure quality of service. 2. Web Site Quality Assurance There are many different checks and analyses which The following are some of the questions you should be you can run on a site. For example, how usable is your asking yourself if you have a web presence. I have site when accessed via a modem? An incomplete list of limited the list to those points which are relevant to similar analyses are given at the start of Section 2. -
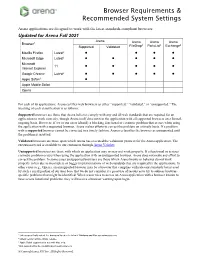
Browser Requirements & Recommended
Browser Requirements & Recommended System Settings Arena applications are designed to work with the latest standards-compliant browsers. Updated for Arena Fall 2021 Arena 1 Arena Arena Arena Browser 4 4 4 Supported Validated FileDrop PartsList Exchange Mozilla Firefox Latest2 l l l l Microsoft Edge Latest2 l l l l l Microsoft 11 l l l l l Internet Explorer Google Chrome Latest2 l l l l l Apple Safari3 l Apple Mobile Safari Opera For each of its applications, Arena certifies web browsers as either “supported,” “validated,” or “unsupported.” The meaning of each classification is as follows: Supported browsers are those that Arena believes comply with any and all web standards that are required for an application to work correctly, though Arena itself does not test the application with all supported browsers on a formal, ongoing basis. However, if we or our users identify a blocking functional or cosmetic problem that occurs when using the application with a supported browser, Arena makes efforts to correct the problem on a timely basis. If a problem with a supported browser cannot be corrected in a timely fashion, Arena reclassifies the browser as unsupported until the problem is resolved. Validated browsers are those upon which Arena has executed the validation protocol for the Arena application. The execution record is available to our customers through Arena Validate. Unsupported browsers are those with which an application may or may not work properly. If a functional or serious cosmetic problem occurs when using the application with an unsupported browser, Arena does not make any effort to correct the problem. -

Arena Training Guide for Administrators Table of Contents
Arena training guide for administrators Table of contents Preface 4 About this guide 4 Get to know Axiell 4 About Arena 5 Liferay 5 Portlets 5 Language handling 5 Styling 5 Arena architecture 6 Administration in Arena 7 Arena articles 7 Signing in to Arena 7 Signing in to Liferay 8 The Arena administration user interface 8 Accounts 11 User types in Arena 11 Permissions 12 Managing users in Liferay 14 Managing a roles in Liferay 16 Arena portal site administration 17 Admin: installation details 17 Site settings 19 Managing pages 21 Page permissions 21 Navigation 21 Configuring pages 21 Creating a page 22 Deleting a page 23 Arena Nova 25 Focus shortcuts 25 That’s how it works-articles 25 News articles 26 Event articles 26 Branch articles 26 FAQ articles 27 Image resources and image handling 27 Portlets in Arena 28 Symbols in the list of portlets 28 Portlets required for basic Arena functionality 28 Placement of portlets 29 Configuring portlets 30 The control toolbar 30 Look and feel 30 2 Assigning user permissions to portlets and pages 30 Liferay articles 32 Creating a Liferay article 32 Adding a Liferay article on a page 32 Arena articles 33 Approving articles 33 Handling abuse and reviews 34 Admin: moderation 34 Searching in catalogue records 36 Single words 36 Phrases 36 Multiple words 36 Truncation 36 Boolean operators 36 Fuzzy search and the similarity factor 36 Search parameters for catalogue records 37 Search parameters for Arena articles 40 Examples 40 Linking and syntaxes 41 Dynamic links 41 Syntax for similar titles 42 Syntax for other titles by the same author 42 Syntax for dynamic news list 42 3 Preface Simple, stylish and engaging, Arena is perfect for archives, libraries and museums to showcase and organize their collections in the public domain. -

Discontinued Browsers List
Discontinued Browsers List Look back into history at the fallen windows of yesteryear. Welcome to the dead pool. We include both officially discontinued, as well as those that have not updated. If you are interested in browsers that still work, try our big browser list. All links open in new windows. 1. Abaco (discontinued) http://lab-fgb.com/abaco 2. Acoo (last updated 2009) http://www.acoobrowser.com 3. Amaya (discontinued 2013) https://www.w3.org/Amaya 4. AOL Explorer (discontinued 2006) https://www.aol.com 5. AMosaic (discontinued in 2006) No website 6. Arachne (last updated 2013) http://www.glennmcc.org 7. Arena (discontinued in 1998) https://www.w3.org/Arena 8. Ariadna (discontinued in 1998) http://www.ariadna.ru 9. Arora (discontinued in 2011) https://github.com/Arora/arora 10. AWeb (last updated 2001) http://www.amitrix.com/aweb.html 11. Baidu (discontinued 2019) https://liulanqi.baidu.com 12. Beamrise (last updated 2014) http://www.sien.com 13. Beonex Communicator (discontinued in 2004) https://www.beonex.com 14. BlackHawk (last updated 2015) http://www.netgate.sk/blackhawk 15. Bolt (discontinued 2011) No website 16. Browse3d (last updated 2005) http://www.browse3d.com 17. Browzar (last updated 2013) http://www.browzar.com 18. Camino (discontinued in 2013) http://caminobrowser.org 19. Classilla (last updated 2014) https://www.floodgap.com/software/classilla 20. CometBird (discontinued 2015) http://www.cometbird.com 21. Conkeror (last updated 2016) http://conkeror.org 22. Crazy Browser (last updated 2013) No website 23. Deepnet Explorer (discontinued in 2006) http://www.deepnetexplorer.com 24. Enigma (last updated 2012) No website 25. -

Unix Quickref.Dvi
Summary of UNIX commands Table of Contents df [dirname] display free disk space. If dirname is omitted, 1. Directory and file commands 1994,1995,1996 Budi Rahardjo ([email protected]) display all available disks. The output maybe This is a summary of UNIX commands available 2. Print-related commands in blocks or in Kbytes. Use df -k in Solaris. on most UNIX systems. Depending on the config- uration, some of the commands may be unavailable 3. Miscellaneous commands du [dirname] on your site. These commands may be a commer- display disk usage. cial program, freeware or public domain program that 4. Process management must be installed separately, or probably just not in less filename your search path. Check your local documentation or 5. File archive and compression display filename one screenful. A pager similar manual pages for more details (e.g. man program- to (better than) more. 6. Text editors name). This reference card, obviously, cannot de- ls [dirname] scribe all UNIX commands in details, but instead I 7. Mail programs picked commands that are useful and interesting from list the content of directory dirname. Options: a user's point of view. 8. Usnet news -a display hidden files, -l display in long format 9. File transfer and remote access mkdir dirname Disclaimer make directory dirname The author makes no warranty of any kind, expressed 10. X window or implied, including the warranties of merchantabil- more filename 11. Graph, Plot, Image processing tools ity or fitness for a particular purpose, with regard to view file filename one screenfull at a time the use of commands contained in this reference card. -

Developing an Open Source Option for NASA Software
Developing An Open Source Option for NASA Software Patrick J. Moran NASA Ames Research Center, M/S T27A-2 Moffett Field, CA, 94035, USA [email protected] NAS Technical Report NAS-03-nnn April 7,2003 Abstract We present arguments in favor of developing an Open Source option for NASA software; in particular we discuss how Open Source is compatible with NASA’s mission. We compare and contrast several of the leading Open Source licenses, and propose one - the Mozilla license - for use by NASA. We also address some of the related issues for NASA with respect to Open Source. In particular, we dis- cuss some of the elements in the “External Release of NASA Software” document (NPG 2210.1A) that will likely have to be changed in order to make Open Source a’reality withm the agency. Contents 1 Introduction 3 2 Why Open Source Software? 4 2.1 NASA Perspective ........................... 4 2.2 Software Users’ Perspective ...................... 5 2.3 Software Developers’ Perspective ................... 5 2.4 PITAC Perspective ........................... 6 2.5 Academia Perspective .......................... 6 2.6 Department of Energy Perspective ................... 7 3 The Leading Open Source Licenses 7 3.1 GNU General Public License ...................... 7 3.2 GNU Lesser General Public License .................. 8 3.3 Mozilla Public License ......................... 8 3.4 BSD License .............................. 8 1 4 License Properties 9 4.1 Recognized by the Open Source Initiative ............... 9 4.2 Attribution Required ........................... 9 4.3 Redistribution Allowed ......................... 10 4.4 License Trumps in Derivative Works .................. 10 4.5 Derivatives Must Be Open Source Software .............. 10 4.6 Commercialization Allowed ..................... -

Abstracts Ing XML Information
394 TUGboat, Volume 20 (1999), No. 4 new precise meanings assigned old familar words.Such pairings are indispensable to those who must work in both languages — or those who must translate from one into the other! The specification covers 90 pages, the introduction another 124.And this double issue has still more: a comparison between SGML and XML, an introduction to Document Object Models (interfaces for XML doc- uments), generating MathML in Omega, a program to generate MathML-encoded mathematics, and finally, the issue closes with a translation of the XML FAQ (v.1.5, June 1999), maintained by Peter Flynn. In all, over 300 pages devoted to XML. Michel Goossens, XML et XSL : unnouveau d´epart pour le web [XML and XSL:Anewventure for the Web]; pp. 3–126 Late in1996, the W3C andseveral major soft- ware vendors decided to define a markup language specifically optimized for the Web: XML (eXtensible Markup Language) was born. It is a simple dialect of SGML, which does not use many of SGML’s seldom- used and complex functions, and does away with most limitations of HTML. After anintroduction to the XML standard, we describe XSL (eXtensible Stylesheet Language) for presenting and transform- Abstracts ing XML information. Finally we say a few words about other recent developments in the XML arena. [Author’s abstract] LesCahiersGUTenberg As mentioned in the editorial, this article is intended Contents of Double Issue 33/34 to be read in conjunction with the actual specification, (November 1999) provided later in the same issue. Michel Goossens, Editorial´ : XML ou la d´emocratisationdu web [Editorial: XML or, the Sarra Ben Lagha, Walid Sadfi and democratisationof the web]; pp. -

Cookie Policy
COOKIE POLICY When you visit our website https://www.arenamedia.com/ some cookies or other tracking technologies may be stored on your device (computer, tablet or smartphone). This Cookie Policy contains information on what cookies are, the type of cookies used by HAVAS S.A. on the website https://www.arenamedia.com/ and the purpose of such use, and your choices regarding cookies. This Cookie Policy should be read together with the Havas Data Protection Policy and Terms of Use. WHAT ARE COOKIES AND OTHER TRACKING TECHNOLOGIES? Cookies are small text files which contain an amount of data generated when you browse on a website and installed in your internet browser. The other tracking technologies, such as web beacons, pixels or clear gifs, work similarly to cookies. Cookies and other tracking technologies are used to monitor your activity on a website by enabling us (through first party cookies) or thirds (through third party cookies) to collect information about how you use the website and enhance the way it works and your visit on our website. There are two types of cookies: session cookies and persistent cookies. • Session cookies are temporary and therefore automatically deleted from your device every time you close your browser; • Persistent cookies remain on your device for a period of time specified in the cookie and are activated every time you visit the website which installed it. YOUR CHOICE REGARDING COOKIES You have a number of options to control or limit how we or third parties use cookies: • You can choose to delete all or some cookies from your device through your browser settings; • You can choose to prevent cookies from being installed on your device through your browser settings; • You can enable or disable cookies we use on our website by clicking on the “cookie setting” at the bottom of our website. -

HTML & CSS Basics&Print-Pdf
HTML FRONTEND MODULE Day #1 (today) Simple HTML / CSS (fonts, colors, box model) Day #2 Building components (buttons, forms, tabs, etc...) Day #3 Building layouts & grids (with CSS grids and Bootstrap) TODAY'S OBJECTIVES Learn HTML / CSS basics Code your prole page Put it online with Github Pages Add a xed sidebar for most advanced LECTURE BOILERPLATE https://github.com/lewagon/html-demo cd ~/code/$GITHUB_USERNAME git clone [email protected]:lewagon/html-demo.git cd html-demo stt FRONT-END LANGUAGES The languages your browser speaks CONTENT This is what Google cares about. Think of SEO. APPEARANCE How does it look? DYNAMIC BEHAVIOR Animate stuff on screen. Client-side form validation. It's a markup language (== structure) HTML Your page has different contents HTML HTML tags help you identify content HTML Hence, browser default styles will apply HTML And you will also be able to apply your own style rules if you want HTML SKELETON <!DOCTYPE html> <!-- end of file --> HTML SKELETON <!DOCTYPE html> <html> </html> <!-- end of file --> HTML SKELETON <!DOCTYPE html> <html> <head> </head> <body> </body> </html> <!-- end of file --> HTML SKELETON - HEAD <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>TEST</title> </head> <body> </body> </html> <!-- end of file --> HTML SKELETON - HEAD & GOOGLE <head> <!-- Google result text--> <title>Coding Bootcamp Le Wagon | Europe's Best Coding Boot <!-- Google result description--> <meta name="description" content="Le Wagon is Europe’s best </head> protip: max 55 characters for title & 160 characters -

Why Websites Can Change Without Warning
Why Websites Can Change Without Warning WHY WOULD MY WEBSITE LOOK DIFFERENT WITHOUT NOTICE? HISTORY: Your website is a series of files & databases. Websites used to be “static” because there were only a few ways to view them. Now we have a complex system, and telling your webmaster what device, operating system and browser is crucial, here’s why: TERMINOLOGY: You have a desktop or mobile “device”. Desktop computers and mobile devices have “operating systems” which are software. To see your website, you’ll pull up a “browser” which is also software, to surf the Internet. Your website is a series of files that needs to be 100% compatible with all devices, operating systems and browsers. Your website is built on WordPress and gets a weekly check up (sometimes more often) to see if any changes have occured. Your site could also be attacked with bad files, links, spam, comments and other annoying internet pests! Or other components will suddenly need updating which is nothing out of the ordinary. WHAT DOES IT LOOK LIKE IF SOMETHING HAS CHANGED? Any update to the following can make your website look differently: There are 85 operating systems (OS) that can update (without warning). And any of the most popular roughly 7 browsers also update regularly which can affect your site visually and other ways. (Lists below) Now, with an OS or browser update, your site’s 18 website components likely will need updating too. Once website updates are implemented, there are currently about 21 mobile devices, and 141 desktop devices that need to be viewed for compatibility. -

Arena Query SQL Customized Modulesa274
Arena Query: SQL-Customized Modules (Course #A274) Presented by: Alex Nicoletti Arena Product Owner ©2017 Shelby Systems, Inc. Other brand and product names are trademarks or registered trademarks of the respective holders. Objective To learn ways to use Arena to retrieve the information you need to know. Arena and the supporting infrastructure offer several tools to automate jobs. Metrics tally and draw graphs; Report Grids from Query, HTML, and Stored Procedure modules deliver information; Reporting Services can deliver reports via email on schedule. Be inspired to build a dashboard that keeps itself up to date. This session covers the following topics: You are going deep. It is important to remember that Arena runs on powerful software: Microsoft’s SQL Server. There are several methods you can employ to automate various processes using Arena as well as the technology behind it. SQL Server’s SQL Maintenance Plans/SQL Server Jobs SQL Server’s Database Triggers SQL Server’s Reporting Services Arena’s Agents Arena’s “Report Grid from Query” Module Arena’s “HTML from Stored Procedure” Module Arena’s Metrics Build a Dashboard! …and more? 2 SQL Server Maintenance Plans Why You Want Them SQL Server Maintenance Plans are considered an alternative to Arena’s Agent System – they require less code and are relatively simple to create and set up. The downside is they are not part of the Arena Database, nor part of the Arena app, so their backup is handled differently. Like any custom code, Shelby does not officially support them. Example of How to Use Them New Covenant Bible Church in Cedar Rapids, IA discovered a need to communicate delicate concerns about congregants in a manner that honored privacy. -

Impacting a Woman's World: Identifying the Factors That Influence
Impacting a Woman’s World: Identifying the Factors that Influence Female Advancement in the Workplace A collaborative thesis submitted to the Miami University Honors Program in partial fulfillment of the requirements for University Honors By Laura Elizabeth Barnett and Justine Kelly Lelchuk May, 2006 Oxford, Ohio ii ABSTRACT Impacting a Woman’s World: Identifying the Factors that Influence Female Advancement in the Workplace By Laura Elizabeth Barnett and Justine Kelly Lelchuk The present paper investigates the factors that influence female advancement in the workplace by comparing achieved and less achieved women in the workplace in order to understand how to aid other women interested in reaching an esteemed level in their places of employment. The purpose of this study was to explore and describe the aspirations, values, attributes, and actions of women currently serving as achieved women in the workplace. A triangulation of qualitative data, collection methods and data sources was utilized to assess what these women ascribe their achievements to in their careers. Among other factors, the results confirm that the achieved woman has higher self-esteem, higher self-efficacy, and more internal locus of control than the less achieved woman. The research also confirms that the achieved woman’s father has the most influence on her success. Additionally, the study’s results suggest that a female’s likelihood of becoming achieved is based on her ability to be independent rather than dependent, organized rather than disorganized, rational rather than emotional, energetic rather than apathetic, and self-assured rather than insecure. Taken together, the findings indicate the need for the creation of an information medium that communicates to young, ambitious women, helping them cultivate the qualities required to become achieved.