Pathalias UUCP Paper
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SMTP (Simple Mail Transfer Protocol)
P1: JsY JWBS001A-60.tex WL041/Bidgoli WL041-Bidgoli.cls May 12, 2005 3:27 Char Count= 0 SMTP (Simple Mail Transfer Protocol) Vladimir V. Riabov, Rivier College Introduction 1 SMTP Security Issues 12 SMTP Fundamentals 1 SMTP Vulnerabilities 12 SMTP Model and Protocol 2 SMTP Server Buffer Overflow Vulnerability 15 User Agent 4 Mail Relaying SMTP Vulnerability 15 Sending e-Mail 4 Mail Relaying SMTP Vulnerability in Microsoft Mail Header Format 4 Windows 2000 15 Receiving e-Mail 4 Encapsulated SMTP Address Vulnerability 15 The SMTP Destination Address 4 Malformed Request Denial of Service 16 Delayed Delivery 4 Extended Verb Request Handling Flaw 16 Aliases 5 Reverse DNS Response Buffer Overflow 16 Mail Transfer Agent 5 Firewall SMTP Filtering Vulnerability 16 SMTP Mail Transaction Flow 5 Spoofing 16 SMTP Commands 6 Bounce Attack 16 Mail Service Types 6 Restricting Access to an Outgoing Mail SMTP Service Extensions 8 Server 17 SMTP Responses 8 Mail Encryption 17 SMTP Server 8 Bastille Hardening System 17 On-Demand Mail Relay 8 POP and IMAP Vulnerabilities 17 Multipurpose Internet Mail Extensions Standards, Organizations, and (MIME) 8 Associations 18 MIME-Version 10 Internet Assigned Numbers Authority 18 Content-Type 10 Internet Engineering Task Force Working Content-Transfer-Encoding 10 Groups 18 Content-Id 11 Internet Mail Consortium 18 Content-Description 11 Mitre Corporation 18 Security Scheme for MIME 11 Conclusion 18 Mail Transmission Types 11 Glossary 18 Mail Access Modes 11 Cross References 19 Mail Access Protocols 11 References 19 POP3 11 Further Reading 22 IMAP4 12 INTRODUCTION and IMAP4), SMTP software, vulnerability and security issues, standards, associations, and organizations. -

Table of Contents
Table of Contents Preface .................................................................................................... xiii Part I: The Web Environment Chapter 1—Designing for a Variety of Browsers ...................... 3 Browsers ................................................................................................. 3 Design Strategies .................................................................................... 9 Writing Good HTML ............................................................................. 11 Knowing Your Audience ..................................................................... 12 Considering Your Site’s Purpose ......................................................... 13 Test! Test! Test! ..................................................................................... 13 Chapter 2—Designing for a Variety of Displays .................... 14 Dealing with Unknown Monitor Resolutions ..................................... 14 Fixed versus Flexible Web Page Design ............................................. 19 Accessibility .......................................................................................... 23 Alternative Displays .............................................................................. 26 Chapter 3—Web Design Principles for Print Designers ...................................................................... 28 Color on the Web ................................................................................. 28 Graphics on the Web .......................................................................... -

Linux Certification Bible.Pdf
Turn in: .75 Board: 7.0625 .4375 VISIBLE SPINE = 1.75 .4375 Board: 7.0625 Turn in: .75 The only guide you need for Linux+ exam success . “This is the all-inclusive Linux+ guide you’ve been looking for.” You’re holding in your hands the most comprehensive and effective guide available for the CompTIA Linux+ 100% — Tim Sosbe, Editorial Director, Certification Magazine COMPREHENSIVE 100% exam. Trevor Kay delivers incisive, crystal-clear explanations of every Linux+ topic, highlighting exam- ONE HUNDRED PERCENT critical concepts and offering hands-on tips that can help you in your real-world career. Throughout, he COMPREHENSIVE Covers CompTIA Linux+ AUTHORITATIVE provides pre-tests, exam-style assessment questions, and scenario problems — everything you need to Exam XK0-001 WHAT YOU NEED master the material and pass the exam. ONE HUNDRED PERCENT Inside, you’ll find complete coverage Linux+ of Linux+ exam objectives Linux+ Master the • Get up to speed on Linux basics and understand the differences material for the between different Linux distributions CompTIA Linux+ • Tackle Linux installation, from planning to network configuration, Exam XK0-001 dual-boot systems, and upgrades Test your knowledge • Get the scoop on managing Linux disks, file systems, and with assessment processes; implementing security; and backing up your system Hundreds of unique, exam-like questions give you a random set of questions each questions and • Learn the ins and outs of configuring the X Window time you take the exam. scenario problems system and setting up a network • Find out how to establish users and groups, navigate Practice on the Linux file system, and use Linux system commands A customizable format enables state-of-the-art • Delve into troubleshooting techniques for the boot you to define test-preparation process, software, and networking your own software preferences • Get a handle on maintaining system hardware, from for question CPU and memory to peripherals presentation. -

The Complete Solutions Guide for Every Linux/Windows System Administrator!
Integrating Linux and Windows Integrating Linux and Windows By Mike McCune Publisher : Prentice Hall PTR Pub Date : December 19, 2000 ISBN : 0-13-030670-3 • Pages : 416 The complete solutions guide for every Linux/Windows system administrator! This complete Linux/Windows integration guide offers detailed coverage of dual- boot issues, data compatibility, and networking. It also handles topics such as implementing Samba file/print services for Windows workstations and providing cross-platform database access. Running Linux and Windows in the same environment? Here's the comprehensive, up-to-the-minute solutions guide you've been searching for! In Integrating Linux and Windows, top consultant Mike McCune brings together hundreds of solutions for the problems that Linux/Windows system administrators encounter most often. McCune focuses on the critical interoperability issues real businesses face: networking, program/data compatibility, dual-boot systems, and more. You'll discover exactly how to: Use Samba and Linux to deliver high-performance, low-cost file and print services to Windows workstations Compare and implement the best Linux/Windows connectivity techniques: NFS, FTP, remote commands, secure shell, telnet, and more Provide reliable data exchange between Microsoft Office and StarOffice for Linux Provide high-performance cross-platform database access via ODBC Make the most of platform-independent, browser-based applications Manage Linux and Windows on the same workstation: boot managers, partitioning, compressed drives, file systems, and more. For anyone running both Linux and Windows, McCune delivers honest and objective explanations of all your integration options, plus realistic, proven solutions you won't find anywhere else. Integrating Linux and Windows will help you keep your users happy, your costs under control, and your sanity intact! 1 Integrating Linux and Windows 2 Integrating Linux and Windows Library of Congress Cataloging-in-Publication Data McCune, Mike. -

New Features of AWT in Java
Preface The Abstract Window Tookit (AWT) provides the user interface for Java programs. Unless you want to construct your own GUI or use a crude text-only interface, the AWT provides the tools you will use to communicate with the user. Although we are beginning to see some other APIs for building user interfaces, like Netscape’s IFC (Internet Foundation Classes), those alternative APIs will not be in widespread use for some time, and some will be platform specific. Likewise, we are beginning to see automated tools for building GUIs in Java; Sun’s JavaBeans effort promises to make such tools much more widespread. (In fact, the biggest changes in Java 1.1 prepare the way for using the various AWT components as JavaBeans.) How- ever, even with automated tools and JavaBeans in the future, an in-depth knowl- edge of AWT is essential for the practicing Java programmer. The major problem facing Java developers these days is that AWT is a moving tar- get. Java 1.0.2 is being replaced by Java 1.1, with many significant new features. Java 1.1 was released on February 18, 1997, but it isn’t clear how long it will take for 1.1 to be accepted in the market. The problem facing developers is not just learning about the new features and changes in Java 1.1, but also knowing when they can afford to use these new features in their code. In practice, this boils down to one question: when will Netscape Navigator support Java 1.1? Rumor has it that the answer is “as soon as possible”—and we all hope this rumor is correct. -

Eudora® Email 7.1 User Guide for Windows
Eudora® Email 7.1 User Guide for Windows This manual was written for use with the Eudora® for Windows software version 7.1. This manual and the Eudora software described in it are copyrighted, with all rights reserved. This manual and the Eudora software may not be copied, except as otherwise provided in your software license or as expressly permitted in writing by QUALCOMM Incorporated. Export of this technology may be controlled by the United States Government. Diversion contrary to U.S. law prohibited. Copyright © 2006 by QUALCOMM Incorporated. All rights reserved. QUALCOMM, Eudora, Eudora Pro, Eudora Light, and QChat are registered trademarks of QUALCOMM Incorporated. PureVoice, SmartRate, MoodWatch, WorldMail, Eudora Internet Mail Server, and the Eudora logo are trademarks of QUALCOMM Incorporated. Microsoft, Outlook, Outlook Express, and Windows are either registered trademarks or trademarks of Microsoft Incorporated in the United States and/or other countries. Adobe, Acrobat, and Acrobat Exchange are registered trademarks of Adobe Systems Incorporated. Apple and the Apple logo are registered trademarks, and QuickTime is a trademark of Apple Computer, Inc. Netscape, Netscape Messenger, and Netscape Messenger are registered trademarks of the Netscape Communications Corporation in the United States and other countries. Netscape's logos and Netscape product and service names are also trademarks of Netscape Communications Corporation, which may be registered in other countries. All other trademarks and service marks are the property of their respective owners. Use of the Eudora software and other software and fonts accompanying your license (the "Software") and its documentation are governed by the terms set forth in your license. -

Protocols: U, V
Protocols: U, V • UAAC, on page 3 • UARPS, on page 4 • UDPLITE, on page 5 • UIS, on page 6 • ULISTPROC, on page 7 • ULP, on page 8 • ULPNET, on page 9 • ULTRASURF, on page 10 • UNIDATA-LDM, on page 11 • UNITE-AIRLINES, on page 12 • UNIFY, on page 13 • UOL, on page 14 • UPS, on page 15 • URM, on page 16 • USAA, on page 17 • USA-TODAY, on page 18 • USBANK, on page 19 • USPS, on page 20 • UTI, on page 21 • UTIME, on page 22 • UTMPCD, on page 23 • UTMPSD, on page 24 • UUCP, on page 25 • UUCP-PATH, on page 26 • UUCP-RLOGIN, on page 27 • UUIDGEN, on page 28 • VACDSM-APP, on page 29 • VACDSM-SWS, on page 30 • VATP, on page 31 • VDOLIVE, on page 32 • VEMMI, on page 33 • VENTRILO, on page 34 • VERIZON-WEB-SERVICES , on page 35 Protocols: U, V 1 Protocols: U, V • VERIZON-WIRELESS-WEB, on page 36 • VIBER, on page 37 • VID, on page 38 • VIDEO-OVER-HTTP, on page 39 • VIDEOTEX, on page 40 • VINE, on page 41 • VIRTUAL-PLACES, on page 42 • VISA, on page 43 • VKONTAKTE, on page 44 • VMNET, on page 45 • VMPWSCS, on page 46 • VMTP, on page 47 • VMWARE-FDM, on page 48 • VMWARE-VIEW, on page 49 • VMWARE-VMOTION, on page 50 • VMWARE-VSPHERE, on page 51 • VNAS, on page 52 • VNC, on page 53 • VNC-HTTP, on page 54 • VPP, on page 55 • VPPS-QUA, on page 56 • VPPS-VIA, on page 57 • VRRP, on page 58 • VSINET, on page 59 • VSLMP, on page 60 Protocols: U, V 2 Protocols: U, V UAAC UAAC Name/CLI Keyword uaac Full Name UAAC Protocol Description Registered with IANA on port 145 TCP/UDP Reference http://www.iana.org/assignments/service-names-port-numbers/service-names-port-numbers.xml Global ID L4:145 ID 946 Known Mappings UDP Port 145 TCP Port 145 IP Protocol - IP Version IPv4 Support Yes IPv6 Support Yes Application Group other Business Relevance default. -

Thesis W. Ebbers
FACING THE DIGITAL WORLD CONNECTING A PERMANENTLY CHANGING INTERNET TO RIGID ORGANISATIONAL STRUCTURES Wolfgang Ebbers … Neo, sooner or later you're going to realize, just as I did, there's a difference between knowing the path and walking the path. The Matrix (The Wachowski Brothers, 1999) Cover Design: Indra Simons Cover Photo: Indra Simons Page Layout: Belastingdienst - beladoc Printing: Ted Gigaprint ISBN 90-365-1792-3 Copyright © 2002, Wolfgang Ebbers, The Netherlands, Arnhem All rights reserved. Subject to exceptions provided for by law, no part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior permission of the copyright owner. No part of this publication may be adapted in whole or in part without prior written permission of the author. Wolfgang Ebbers [email protected] www.isiweb.nl/ebbers FACING THE DIGITAL WORLD CONNECTING A PERMANENTLY CHANGING INTERNET TO RIGID ORGANISATIONAL STRUCTURES met een samenvatting in het Nederlands PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Universiteit Twente, op gezag van de rector magnificus, prof. dr. F.A. van Vught, volgens besluit van het College voor Promoties in het openbaar te verdedigen op woensdag 4 september 2002 te 15:00 uur. door Wolfgang Erich Ebbers Geboren op 3 juni 1969 te Winterswijk Promotores: Prof. dr. J.A.G.M. van Dijk, Faculteit Wijsbegeerte en Maatschappijwetenschappen, Universiteit Twente. Prof. dr. J. Groebel, European Institute for the Media. Table of contents 1 Table of contents Preface 3 Introduction 5 Summary 9 1. -
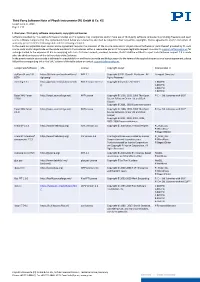
Third Party Software Note of the Physik Instrumente
Third Party Software Note of Physik Instrumente (PI) GmbH & Co. KG Issued: June 17, 2020 Page 1 / 33 I. Overview - Third-party software components, copyrights and licenses Software provided by PI as well as firmware installed on PI’s systems may incorporate and/or make use of third-party software components (including freeware and open source software components). The components listed below are covered by and shall be subject to their respective copyrights, license agreements and/or disclaimers of warranty, presented in the following table and the following section II. In the event an applicable open source license agreement requires the provision of the source code and/or object code of Software or parts thereof provided by PI, such source code and/or object code will be made available to the Customer within a reasonable period of time upon legitimate request via e-mail to [email protected] for a charge limited to the expenses PI has in complying with such Customer request; provided, however, that PI shall be entitled to reject such Customer request if it is made after the third anniversary of the delivery date of the Software. In the event a certain source code is delivered in executable form and has to be made available pursuant to the terms of the applicable open source license agreement, please follow the corresponding link in the ‘URL’ column of the table below or contact [email protected]. Component/Software URL License Copyright owner Incorporated in dglOpenGL.pas 1.8 https://github.com/saschawillems/ MPL 1.1 Copyright © DGL-OpenGL-Portteam - All Hexapod_Simutool BETA dglopengl Rights Reserved eventlog 0.2.x https://github.com/balabit/eventlo BSD 3-Clause License Copyright © by Balazs Scheidler C-884 FW g C-885 FW C-886 FW C-887 FW Expat XML Parser http://expat.sourceforge.net/ MIT License Copyright © 1998, 1999, 2000 Thai Open PI C++ Std. -

Distributing the News: UUCP to UUNET Ued Revising B News Until 1984, When He Produced Version 2.10.1
Distributing the News UUCP to UUNET PETERHISTORY H. SALUS Peter H. Salus is the author of f you were lucky enough to be on the ARPANET in the 1970s, you could A Quarter Century of UNIX get mail and news (in the form of a topical mailing list). But in January (1994), Casting the Net (1995), 1976 there were still only 63 hosts, and you had to be one of the elite to and The Daemon, the Gnu and I gain access. But soon there were methods to reach other sites. Like UNIX, the Penguin (2008). [email protected] the software began in New Jersey. Let’s look at the next dozen years. In 1976, Mike Lesk at Bell Labs came up with a program called UUCP—“UNIX to UNIX copy.” UUCP enabled users to send mail, transfer files, and execute remote commands. Lesk first called it a “scheme for better distribution” (Mini-Systems Newsletter, January 1977); but only a month later it was referred to as UUCP. First designed to operate over 300 baud lines, UUCP was finally published in February 1978. UUCP was taken up widely and this led to a need for improvements. The next version was written by Lesk and Dave Nowitz, with contributions by Greg Chesson, and appeared in Seventh Edition UNIX in October 1978. Enter Usenet In late 1979, the Seventh Edition was installed at the University of North Carolina at Chapel Hill. Steve Bellovin—partly as an exercise in the new system and partly to fill an administra- tive need—wrote a rudimentary news system as a UNIX shell file. -

List Software Pengganti Windows Ke Linux
Tabel Padanan Aplikasi Windows di Linux Untuk Migrasi Selasa, 18-08-2009 Kesulitan besar dalam melakukan migrasi dari Windows ke Linux adalah mencari software pengganti yang berkesesuaian. Berikut ini adalah tabel padanan aplikasi Windows di Linux yang disusun dalam beberapa kategori. Nama Program Windows Linux 1) Networking. 1) Netscape / Mozilla. 2) Galeon. 3) Konqueror. 4) Opera. [Prop] Internet Explorer, 5) Firefox. Web browser Netscape / Mozilla, Opera 6) Nautilus. [Prop], Firefox, ... 7) Epiphany. 8) Links. (with "-g" key). 9) Dillo. 10) Encompass. 1) Links. 1) Links 2) ELinks. Console web browser 2) Lynx 3) Lynx. 3) Xemacs + w3. 4) w3m. 5) Xemacs + w3. 1) Evolution. 2) Netscape / Mozilla/Thunderbird messenger. 3) Sylpheed / Claws Mail. 4) Kmail. Outlook Express, 5) Gnus. Netscape / Mozilla, 6) Balsa. Thunderbird, The Bat, 7) Bynari Insight GroupWare Suite. Email client Eudora, Becky, Datula, [Prop] Sylpheed / Claws Mail, 8) Arrow. Opera 9) Gnumail. 10) Althea. 11) Liamail. 12) Aethera. 13) MailWarrior. 14) Opera. 1) Evolution. Email client / PIM in MS 2) Bynari Insight GroupWare Suite. Outlook Outlook style [Prop] 3) Aethera. 4) Sylpheed. 5) Claws Mail 1) Sylpheed. 2) Claws Mail Email client in The Bat The Bat 3) Kmail. style 4) Gnus. 5) Balsa. 1) Pine. [NF] 2) Mutt. Mutt [de], Pine, Pegasus, Console email client 3) Gnus. Emacs 4) Elm. 5) Emacs. 1) Knode. 2) Pan. 1) Agent [Prop] 3) NewsReader. 2) Free Agent 4) Netscape / Mozilla Thunderbird. 3) Xnews 5) Opera [Prop] 4) Outlook 6) Sylpheed / Claws Mail. 5) Netscape / Mozilla Console: News reader 6) Opera [Prop] 7) Pine. [NF] 7) Sylpheed / Claws Mail 8) Mutt. -

IBM Z/OS V1R13 Communications Server TCP/IP Implementation: Volume 2 Standard Applications
Front cover IBM z/OS V1R13 Communications Server TCP/IP Implementation: Volume 2 Standard Applications Provides information about z/OS Communications Server TCP/IP standard applications Discusses how to take advantage of TCP/IP standard applications for your needs Includes TCP/IP application implementation examples Mike Ebbers Rama Ayyar Octavio L Ferreira Yohko Ojima Gilson Cesar de Oliveira Mike Riches Maulide Xavier ibm.com/redbooks International Technical Support Organization IBM z/OS V1R13 Communications Server TCP/IP Implementation: Volume 2 Standard Applications December 2011 SG24-7997-00 Note: Before using this information and the product it supports, read the information in “Notices” on page ix. First Edition (December 2011) This edition applies to Version 1, Release 13 of IBM z/OS Communications Server (product number 5694-A01). © Copyright International Business Machines Corporation 2011. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . ix Trademarks . .x Preface . xi The team who wrote this book . xii Now you can become a published author, too! . xiii Comments welcome. xiv Stay connected to IBM Redbooks . xiv Chapter 1. The syslog daemon . 1 1.1 Conceptual overview of syslogd . 2 1.1.1 What is syslogd. 2 1.1.2 How syslogd works . 3 1.1.3 How can syslogd be deployed . 3 1.2 Log messages to different files and to a single file . 5 1.2.1 Description of logging to multiple files and to a single file. 5 1.2.2 Configuration of multiple files and a single file .