Development of Large Vocabulary Speech Recognition System with Keyword Search for Manipuri
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Origin and Development of the Meitei Language
International Journal of Multidisciplinary Research and Modern Education (IJMRME) ISSN (Online): 2454 - 6119 (www.rdmodernresearch.org) Volume II, Issue I, 2016 ORIGIN AND DEVELOPMENT OF THE MEITEI LANGUAGE Khongbantabam Naobi Devi Ph.D Scholar, Department of English, Ethiraj College for Women, Chennai, Tamilnadu Abstract: Meitei language is an Indo-Aryan language. The Indo- Aryans came to Manipur and settled in the Manipur from the 4th century B.C. onwards. The noted historian and scholar R.K. Jhalajit Singh present his views on the topic to Dr. Suniti Kumar Chatterjee, the great scholar and experts on language. He expressed as Meitei language may not belong to the Kuki- Chin sub-group of the Tibeto-Burman branch; but belongs to the Sino-Tibetan family of language. All the language that belongs to the Tibeto-Burman, a sub-branch of the Sino- Tibetan family of languages, is mono- syllabic. The Meiteis language is not a monosyllabic language; it is a polysyllabic language. In meiteis language, majority of words have more than one syllable. A language should be classified because of grammar. This is the universal principle accepted on all. A language cannot be classified according to vocabulary. If we begin to classify a language according to its vocabulary, the results will be incorrect. The first settlers of the Indo-Aryans in Manipur spoke Sanskrit. Later settlers spoke Prakrit. When Prakrit was removed as spoken language, they spoke Apabhransha.. The combination of Apabhransha and Mongoloid languages gave birth to the Manipuri language by about 1074 A.D. In the olden days of the Meitei language, which was formed by the interaction of Apabhransha and Mongoloid languages, the most important words were taken from Sanskrit. -

A Manipuri-English Bilingual Electronic Dictionary -Design and Implementation S
ISSN: 2277-3754 ISO 9001:2008 Certified International Journal of Engineering and Innovative Technology (IJEIT) Volume 2, Issue 1, July 2012 A Manipuri-English Bilingual Electronic Dictionary -Design and Implementation S. Poireiton Meitei, Shantikumar Ningombam, H.Mamata Devi, Bipul Syam Purkayastha Abstract— Bilingual Electronic dictionaries are some kind of II. MANIPURI LANGUAGE system that hopes to process natural languages as people have Manipuri, locally known as Meiteilon (the Meitei+lon information about words, their meaning and relative information(from source language) to another(target) language. „language‟), is spoken basically in the state of Manipur So, machine readable electronic dictionary becomes the central which is in the north eastern India. It is also spoken in resources for Natural Language applications. Dictionaries and Assam, Tripura, Mizoram, Burma and Bangladesh. other lexical resources are not yet widely available in electronic Manipuri is the only medium of communication among 29 form for Manipuri Language. This paper describes the design different mother tongues. Hence it is regarded as lingua and implementation of a developing Electronic franca of Manipur state. Since 20 August 1992 Manipuri Manipuri-English Bilingual dictionary. This implementation become the first TB (Tibeto Burman) language to receive will provide a more effective combination of traditional recognition as a schedule VIII language of India. Before this Manipuri-English bi-lingual lexicographic information and every date, Manipuri has adopted as the medium of their conceptual information. instruction and examination. More and above, Manipuri is Index Terms: - Manipuri Language, Bilingual, Dictionaries, taught up to Ph.D. level in the Indian Universities. It is also Tibeto Burman, Natural language Processing. -

An Analysis Towards the Development of Electronic Bilingual Dictionary (Manipuri-English) -A Report
Sagolsem Poireiton Meitei et al, / (IJCSIT) International Journal of Computer Science and Information Technologies, Vol. 3 (2) , 2012,3423-3426 An Analysis towards the Development of Electronic Bilingual Dictionary (Manipuri-English) -A Report Sagolsem Poireiton Meitei, Shantikumar Ningombam, Prof. Bipul Syam Purkayastha Department of Computer Science Assam University, Silchar-788011 ABSTRACT-Meaningful sentences are composed of travel dictionaries, dictionaries of idioms and meaningful words; any system that hopes to process natural colloquialisms, a guide to pronunciation, a grammar languages as people do must have information about words, reference, common phrases and collocations, and a their meaning and relative words in another language. This dictionary of foreign loan words information is traditionally provided through electronic dictionaries. But these dictionary entries evolved for the convenience of human readers, not for machines. So, machine MANIPURI LANGUAGE readable electronic dictionary becomes the central resources Manipuri, locally known as Meiteilon (the Meitei+lon for Natural Language applications. Dictionaries and other ‘language’), is spoken basically in the state of Manipur lexical resources are not yet widely available in electronic form which is in the north eastern india. It is also spoken in for Manipuri language. And there is no machine readable Assam, Tripura, Mizoram, Burma and Bangladesh. dictionary that can provide both of lexical resources and Manipuri is the only medium of communication among 29 conceptual information. This paper describes the ongoing different mother tongues. Hence it is regarded as lingua development of an Electronic Manipuri Bilingual dictionary. franca of Manipur state. Since 20 August 1992 Manipuri This implementation will provide a more effective combination become the first TB (Tibeto Burman) language to receive of traditional English-Manipuri bi-lingual lexicographic information and their conceptual information recognition as a schedule VIII language of India. -

The Art of Not Being Scripted So Much. the Politics of Writing Hmong
The Art of Not Being Scripted So Much The Politics of Writing Hmong Language(s)1 Jean Michaud This article discusses the persistent absence of a consensus on a script for the language of the Hmong, a kinship-based society of 5 million spread over the uplands of Southwest China and northern Indochina, with a vigorous diaspora in the West. In search of an explanation for this unusual situation, this article proposes a political reading inspired by James C. Scott’s 2009 book The Art of Not Being Governed. A particular focus is put on Scott’s claim of tactical rejection of literacy among upland groups of Asia. To set the scene, the case of the Hmong is briefly exposed before detailing the successive appearance of orthographies for their language(s) over one century. It is then argued that the lack of consensus on a common writing system might be a reflection of deeper political motives rather than merely the result of historical processes. Anthropologists and linguists have long noted that it is com- writing system appears to be of little interest to the majority of mon for stateless, kinship-based societies such as the Hmong its speakers (Thao 2006)—outside very specific moments of to shape neither their own script nor borrow someone else’s rebellious crises, a point I return to later. (Goody 1968). Here, the twist is that while the Hmong as a I am not suggesting that the Hmong situation is monolithic; group have not adopted a common writing system, over two on the contrary, it is multifarious, as we will see. -

THE LANGUAGES of MANIPUR: a CASE STUDY of the KUKI-CHIN LANGUAGES* Pauthang Haokip Department of Linguistics, Assam University, Silchar
Linguistics of the Tibeto-Burman Area Volume 34.1 — April 2011 THE LANGUAGES OF MANIPUR: A CASE STUDY OF THE KUKI-CHIN LANGUAGES* Pauthang Haokip Department of Linguistics, Assam University, Silchar Abstract: Manipur is primarily the home of various speakers of Tibeto-Burman languages. Aside from the Tibeto-Burman speakers, there are substantial numbers of Indo-Aryan and Dravidian speakers in different parts of the state who have come here either as traders or as workers. Keeping in view the lack of proper information on the languages of Manipur, this paper presents a brief outline of the languages spoken in the state of Manipur in general and Kuki-Chin languages in particular. The social relationships which different linguistic groups enter into with one another are often political in nature and are seldom based on genetic relationship. Thus, Manipur presents an intriguing area of research in that a researcher can end up making wrong conclusions about the relationships among the various linguistic groups, unless one thoroughly understands which groups of languages are genetically related and distinct from other social or political groupings. To dispel such misconstrued notions which can at times mislead researchers in the study of the languages, this paper provides an insight into the factors linguists must take into consideration before working in Manipur. The data on Kuki-Chin languages are primarily based on my own information as a resident of Churachandpur district, which is further supported by field work conducted in Churachandpur district during the period of 2003-2005 while I was working for the Central Institute of Indian Languages, Mysore, as a research investigator. -

Neo-Vernacularization of South Asian Languages
LLanguageanguage EEndangermentndangerment andand PPreservationreservation inin SSouthouth AAsiasia ed. by Hugo C. Cardoso Language Documentation & Conservation Special Publication No. 7 Language Endangerment and Preservation in South Asia ed. by Hugo C. Cardoso Language Documentation & Conservation Special Publication No. 7 PUBLISHED AS A SPECIAL PUBLICATION OF LANGUAGE DOCUMENTATION & CONSERVATION LANGUAGE ENDANGERMENT AND PRESERVATION IN SOUTH ASIA Special Publication No. 7 (January 2014) ed. by Hugo C. Cardoso LANGUAGE DOCUMENTATION & CONSERVATION Department of Linguistics, UHM Moore Hall 569 1890 East-West Road Honolulu, Hawai’i 96822 USA http:/nflrc.hawaii.edu/ldc UNIVERSITY OF HAWAI’I PRESS 2840 Kolowalu Street Honolulu, Hawai’i 96822-1888 USA © All text and images are copyright to the authors, 2014 Licensed under Creative Commons Attribution Non-Commercial No Derivatives License ISBN 978-0-9856211-4-8 http://hdl.handle.net/10125/4607 Contents Contributors iii Foreword 1 Hugo C. Cardoso 1 Death by other means: Neo-vernacularization of South Asian 3 languages E. Annamalai 2 Majority language death 19 Liudmila V. Khokhlova 3 Ahom and Tangsa: Case studies of language maintenance and 46 loss in North East India Stephen Morey 4 Script as a potential demarcator and stabilizer of languages in 78 South Asia Carmen Brandt 5 The lifecycle of Sri Lanka Malay 100 Umberto Ansaldo & Lisa Lim LANGUAGE ENDANGERMENT AND PRESERVATION IN SOUTH ASIA iii CONTRIBUTORS E. ANNAMALAI ([email protected]) is director emeritus of the Central Institute of Indian Languages, Mysore (India). He was chair of Terralingua, a non-profit organization to promote bi-cultural diversity and a panel member of the Endangered Languages Documentation Project, London. -

Non-Structural Case Marking in Tibeto-Burman and Artificial Languages*
Non-structural Case Marking in Tibeto-Burman and Artificial Languages* Alexander R. Coupe Sander Lestrade Nanyang Technological University Radboud University This paper discusses the diachronic development of non-structural case marking in Tibeto- Burman and in computer simulations of language evolution. It is shown how case marking is initially motivated by the pragmatic need to disambiguate between two core arguments, but eventually may develop flagging functions that even extend into the intransitive domain. Also, it is shown how different types of case-marking may emerge from various underlying disambiguation strategies. 1. Introduction This paper was motivated by the authors’ serendipitous discovery that a computer simulation of the emergence of case marking produced results that are uncannily similar to attested grammaticalization pathways and patterns of core case marking observed in the grammars of many Tibeto-Burman (henceforth TB) languages with pragmatically-motivated case marking. When it manifests, core case marking in both the natural and artificial languages appears to be initially motivated by the same fundamental need to disambiguate semantic roles. In other words, whenever some meaning does not follow inherently from the semantics of the dependency relationship holding between a head and its arguments, it must be encoded explicitly in the grammars of both the simulated language and the natural languages. Disambiguating case marking is most likely to appear in clauses with two core arguments when either one may potentially fulfill the role of the agent. Under these circumstances, some grammatical means of distinguishing an A argument from an O argument may be required to clarify meaning. 1 Conversely, if semantic roles can be unambiguously assigned to core arguments because of the semantic nature of their referents, then there may be no overt marking, even in bivalent clauses, so the use of core case marking is observed to have a pragmatic basis. -

Sumi Tone: a Phonological and Phonetic Description of a Tibeto-Burman Language of Nagaland
Sumi tone: a phonological and phonetic description of a Tibeto-Burman language of Nagaland Amos Benjamin Teo Submitted in total fulfilment of the requirements of the degree of Masters by Research (by Thesis Only) December 2009 School of Languages and Linguistics The University of Melbourne Abstract Previous research on Sumi, a Tibeto-Burman language spoken in the extreme northeast of India, has found it to have three lexical tones. However, the few phonological studies of Sumi have focused mainly on its segmental phonology and have failed to provide any substantial account of the tone system. This thesis addresses the issue by providing the first comprehensive description of tone in this language. In addition to confirming three contrastive tones, this study also presents the first acoustic phonetic analysis of Sumi, looking at the phonetic realisation of these tones and the effects of segmental perturbations on tone realisation. The first autosegmental representation of Sumi tone is offered, allowing us to account for tonal phenomena such as the assignment of surface tones to prefixes that appear to be lexically unspecified for tone. Finally, this investigation presents the first account of morphologically conditioned tone variation in Sumi, finding regular paradigmatic shifts in the tone on verb roots that undergo nominalisation. The thesis also offers a cross-linguistic comparison of the tone system of Sumi with that of other closely related Kuki-Chin-Naga languages and some preliminary observations of the historical origin and development of tone in these languages are made. This is accompanied by a typological comparison of these languages with other Tibeto-Burman languages, which shows that although these languages are spoken in what has been termed the ‘Indosphere’, their tone systems are similar to those of languages spoken further to the east in the ‘Sinosphere’. -

Download (4MB)
North East Indian Linguistics Volume 3 Edited by Gwendolyn Hyslop • Stephen Morey. Mark W. Post EOUNDATlON® S (j) ® Ie S Delhi· Bengaluru • Mumbai • Kolkata • Chennai • Hyderabad • Pune Published by Cambridge University Press India Pvt. Ltd. under the imprint of Foundation Books Cambridge House, 438114 Ansari Road, Daryaganj, New Delhi 110002 Cambridge University Press India Pvt. Ltd. C-22, C-Block, Brigade M.M., K.R. Road, Iayanagar, Bengaluru 560 070 Plot No. 80, Service Industries, Sbirvane, Sector-I, Neru!, Navi Mumbai 400 706 10 Raja Subodb Mullick Square, 2nd Floor, Kolkata 700 013 2111 (New No. 49), 1st Floor, Model School Road, Thousand Lights, Chcnnai 600 006 House No. 3-5-874/6/4, (Near Apollo Hospital), Hyderguda, Hyderabad 500 029 Agarwal Pride, 'A' Wing, 1308 Kasba Peth, Near Surya Hospital, :"Pune 411 011 © Cambridge Universiry Press India Pvt. Ltd. First Published 20 II ISBN 978-81-7596-793-9 All rights reserved. No reproduction of any part may take place without the written pennission of Cambridge University Press India Pvl. Ltd., subject to statutory exception and to the provision of relevant collective licensing agreements. Cambridge" Universiry Press India Pvl. Ltd. has no responsibility for the persistence or accuracy of URLs for external or third-parry internet websites referred to in this book, and does not guarantee that any content on such websites is, or will remain, accurate or appropriate. Typeset at SanchauLi Image Composers, New Deihi. Published by Manas Saikia for Cambridge University Press India Pvl. Ltd. and printed at Sanat Printers, Kundli. Haryana Contents About the Contributors v Foreword Chungkham Yashawanta Singh ix A Note from the Editors xvii The View from Manipur 1. -

February 1 Page 2
Imphal Times Supplementary issue 2 Editorial National & International News Imphal, Monday, February 1, 2016 Aung San Suu Kyi leads party into historic Burma parliament Positive attitude Despite the landslide, Burma’s constitution reserves 25 % of seats to the military The Strife torn State of Manipur, inspite of the unenviable tag By Esther Htusan, of a disturbed area, has much more potential and unexplored The Associated Press Ethnic rebellions potential than that of being one with the most prolific and Yangoon, Feb 1: Burma’s parliament a threat industrious system for churning out militant groups, thought dominated by pro-democracy leader The military called an election in the tag is unlikely to come off anytime soon in the foreseeable Aung San Suu Kyi’s party on 1990, which Suu Kyi’s party won future. On a brighter note, we have some of the most diverse Monday began a new and historic handsomely, only to see the results and varied vegetables, fruits, pulses, cereals and grains. session that will install the country’s annulled by the military and many of Condiments that has not yet been regular ingredients in first democratically elected its leading members harassed and Mainland India has been in use in the North East for centuries. government in more than 50 years. jailed. Suu Kyi was put under house The introduction of Korean channel “Arirang” revealed an The National League for Democracy arrest prior to the 1990 election and astonishing similarity, both in the ingredients as well as in the won a landslide in the Nov. 8 spent 15 of the next 22 years mostly methods of preparations, in the diets of the two regions. -

Proposal to Encode the Kaithi Script in ISO/IEC 10646
Proposal to Encode the Kaithi Script in ISO/IEC 10646 Anshuman Pandey University of Michigan Ann Arbor, Michigan, U.S.A. [email protected] December 13, 2007 Contents Proposal Summary Form i 1 Introduction 1 1.1 Description ..................................... ...... 1 1.2 Justification for Encoding . ........... 1 1.3 Acknowledgments ................................. ...... 2 1.4 ProposalHistory ................................. ....... 2 2 Characters Proposed 3 2.1 CharactersNotProposed . ......... 4 2.2 Basis for Character Shapes . .......... 4 3 Technical Features 8 3.1 Name ............................................ 8 3.2 Classification ................................... ....... 8 3.3 Allocation...................................... ...... 8 3.4 EncodingModel................................... ...... 8 3.5 CharacterProperties. .......... 8 3.6 Collation ....................................... ..... 11 3.7 Typology of Characters . ......... 11 4 Background 13 4.1 Origins ......................................... 13 4.2 Name ............................................ 13 4.3 Definitions...................................... ...... 13 4.4 Languages Written in the Script . ........... 14 4.5 Standardization and Growth . .......... 16 4.6 Decline ......................................... 16 4.7 Usage ........................................... 17 5 Orthography 23 5.1 Distinguishing Features . ........... 23 5.2 Vowels.......................................... 23 5.3 Consonants ...................................... ..... 23 5.4 Nasalization................................... -
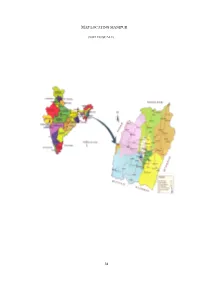
31 Map Locating Manipur
MAP LOCATING MANIPUR (NOT TO SCALE) 31 Chapter: 3 Environment, Archaeological and Historical Setting The state of Manipur is situated in the eastern border of the northeastern corner of the Indian subcontinent. Manipur lies between 23° 50‟ and 25° 41‟ N, and 93° 59‟ and 94° 45‟ E., with its capital as Imphal. It is bounded by three Indian states and one country; i.e. Nagaland in the north, Assam in the west, Mizoram in the south, and Burma in the east (Cover page). Manipur covers an area of 22,347 sq. km. with a population of 27,21,756, Male: 1369,764; Female: 13,51,992 with 79.85% literary rate (Census 2011). Manipur is a state where several ethnic groups reside. “Thus ethnologically and linguistically, the Meiteis (locals of Manipur) are Tibeto-Burman of the southern Mongoloid with Austroloid, Aryan, and Tai admixtures (including some Negrito and Dravidians elements?). Sociologically, the Meiteis have absorbed these foreign elements and completely integrated them in their social structure” (Kabui, 2011:21). Various regions of Manipur have been ruled by several clans at some point of time but the central plain has been the seat of the Ninthoujas, which emerged as the most powerful clan in the history of Manipur. Many scholars agreed that Manipur had an independent long reign of the Ninthouja clan, starting from Lord Nong-da-Lairel Pakhangba (A.D. 33) till King Kulachandra (A.D.1890). Manipur came under the British sway on 12th April, 1891 after the defeat in the Khongjom War. It later came to be recognized as the twentieth state of the Indian Union on 21st January 1972.