Twitter Bot Detection in the Context of the 2018 US Senate Elections
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

The Little Nazis KE V I N D
20170828 subscribers_cover61404-postal.qxd 8/22/2017 3:17 PM Page 1 September 11, 2017 $5.99 TheThe Little Nazis KE V I N D . W I L L I A M S O N O N T H E C HI L D I S H A L T- R I G H T $5.99 37 PLUS KYLE SMITH: The Great Confederate Panic MICHAEL LIND: The Case for Cultural Nationalism 0 73361 08155 1 www.nationalreview.com base_new_milliken-mar 22.qxd 1/3/2017 5:38 PM Page 1 !!!!!!!! ! !! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! !! "e Reagan Ranch Center ! 217 State Street National Headquarters ! 11480 Commerce Park Drive, Santa Barbara, California 93101 ! 888-USA-1776 Sixth Floor ! Reston, Virginia 20191 ! 800-USA-1776 TOC-FINAL_QXP-1127940144.qxp 8/23/2017 2:41 PM Page 1 Contents SEPTEMBER 11, 2017 | VOLUME LXIX, NO. 17 | www.nationalreview.com ON THE COVER Page 22 Lucy Caldwell on Jeff Flake The ‘N’ Word p. 15 Everybody is ten feet tall on the BOOKS, ARTS Internet, and that is why the & MANNERS Internet is where the alt-right really lives, one big online 35 THE DEATH OF FREUD E. Fuller Torrey reviews Freud: group-therapy session The Making of an Illusion, masquerading as a political by Frederick Crews. movement. Kevin D. Williamson 37 ILLUMINATIONS Michael Brendan Dougherty reviews Why Buddhism Is True: The COVER: ROMAN GENN Science and Philosophy of Meditation and Enlightenment, ARTICLES by Robert Wright. DIVIDED THEY STAND (OR FALL) by Ramesh Ponnuru 38 UNJUST PROSECUTION 12 David Bahnsen reviews The Anti-Trump Republicans are not facing their challenges. -
October 20, 2017
Distributed Free Each Friday Since 2009 October 20, 2017 www.pcpatriot.com Locally Owned And Operated ELECTION PREVIEW INSIDE Candidates sharply differ on gun issues RICHMOND, Va. (AP) — The two major party to be able to carry a concealed candidates in Virginia's race for governor sharply handgun without a permit. disagree when it comes to guns. Earlier this year, Democratic Republican Ed Gillespie has an A rating from the Gov. Terry McAuliffe vetoed National Rifle Association. He pledged to "oppose legislation allowing that — any and all attempts to weaken the Second against the wishes of the GOP- Amendment." controlled General assembly. Democrat Ralph Northam said he favors stricter Democrats in the legislature controls on gun ownership. He's backed by former have pushed unsuccessfully for New York City Mayor Michael Bloomberg's group Gillespie universal background checks, as well as by former Democratic Rep. Gabrielle including mandatory checks at Giffords, who was grievously wounded in a 2011 gun shows. shooting. Governors also can take uni- The positions play against type. Northam grew lateral action on guns, like up hunting on Virginia's Eastern Shore and owns McAuliffe did in banning guns two shotguns. from certain state-owned office Gillespie wrote in his 2006 book that he doesn't buildings by executive order. own a gun and recently declined to answer whether Guns on campuses are also a that was still the case. regular and poignant point of discussion due to the 2007 THE ISSUE: mass shooting at Virginia Tech. Northam Debates about guns take up a significant amount Liberty University President WEEKEND WEATHER of time each legislative session and groups on both Jerry Falwell Jr. -

Vienna/Oakton Connection ❖ November 14-20, 2018 Connection Editor Kemal Kurspahic News 703-778-9414 Or [email protected]
These Oakton Girl Scout conservation- ists are doing their part to create mon- arch habitats in the area. Girl Scouts Save Monarchs News, Page 5 Classifieds, Page 10 Classifieds, v Entertainment, Page 8 v Wexton Helps Dems Opinion, Page 4 HomeLifeStyle Take the House Page 7 News, Page 3 11-15-18 home in Requested Time sensitive material. material. sensitive Time Attention Postmaster: Postmaster: Attention ECR WSS ECR ‘Real Work of Advocacy Customer Postal permit #322 permit Easton, MD Easton, PAID Begins Again’ Postage U.S. News, Page 8 STD PRSRT Photo contributed Photo November 14-20, 2018 online at www.connectionnewspapers.com 2 ❖ Vienna/Oakton Connection ❖ November 14-20, 2018 www.ConnectionNewspapers.com Connection Editor Kemal Kurspahic News 703-778-9414 or [email protected] Photo by Marcus Sim Photo Photo by Michael Lee Pope Photo on via Facebook Former Gov. Terry McAuliffe tells the crowd assembled at Tim Kaine’s Packed house to celebrate Jennifer Wexton’s win in the 10th Congres- victory party that voters in Virginia rejected President Donald Trump’s sional District. campaign of “fear, hatred and division.” Democrats Seize Control of Northern Virginia Region once had its own brand of Republicanism; now that seems almost extinct. By Michael Lee Pope supporters taking a posi- The Connection and volun- Results tion as chair- Photo by Ken Pl Photo teers that U.S. SENATE man of a sub- ❖ he loss of two-term incumbent helped her Democrat Tim Kaine: ................. 1.9 million votes, 57 percent committee on ❖ Republican Corey Stewart: ........ 1.4 million votes, 41 percent U.S. -
June 19, 2020 Volume 4, No
This issue brought to you by Georgia Senate: The Road to Redemption By Jacob Rubashkin JUNE 19, 2020 VOLUME 4, NO. 12 Jon Ossoff has been the punchline of an expensive joke for the last three years. But the one-time failed House candidate might get the last laugh in a Senate race that has been out of the spotlight until recently. 2020 Senate Ratings Much of the attention around Georgia has focused on whether it’s a Toss-Up presidential battleground and the special election to fill the seat left by GOP Sen. Johnny Isakson. Collins (R-Maine) Tillis (R-N.C.) Polls consistently show Joe Biden running even with President McSally (R-Ariz.) Donald Trump, and Biden’s emerging coalition of non-white and Tilt Democratic Tilt Republican suburban voters has many Democrats feeling that this is the year they turn Georgia blue. Gardner (R-Colo.) In the race for the state’s other seat, appointed-GOP Sen. Kelly Lean Democratic Lean Republican Loeffler has been engulfed in an insider trading scandal, and though Peters (D-Mich.) KS Open (Roberts, R) the FBI has reportedly closed its investigation, it’s taken a heavy toll on Daines (R-Mont.) her image in the state. While she began unknown, she is now deeply Ernst (R-Iowa) unpopular; her abysmal numbers have both Republican and Democratic opponents thinking they can unseat her. Jones (D-Ala.) All this has meant that GOP Sen. David Perdue has flown under the Likely Democratic Likely Republican radar. But that may be changing now that the general election matchup Cornyn (R-Texas) is set. -

Building Alexa Skills Using Amazon Sagemaker and AWS Lambda
Bootcamp: Building Alexa Skills Using Amazon SageMaker and AWS Lambda Description In this full-day, intermediate-level bootcamp, you will learn the essentials of building an Alexa skill, the AWS Lambda function that supports it, and how to enrich it with Amazon SageMaker. This course, which is intended for students with a basic understanding of Alexa, machine learning, and Python, teaches you to develop new tools to improve interactions with your customers. Intended Audience This course is intended for those who: • Are interested in developing Alexa skills • Want to enhance their Alexa skills using machine learning • Work in a customer-focused industry and want to improve their customer interactions Course Objectives In this course, you will learn: • The basics of the Alexa developer console • How utterances and intents work, and how skills interact with AWS Lambda • How to use Amazon SageMaker for the machine learning workflow and for enhancing Alexa skills Prerequisites We recommend that attendees of this course have the following prerequisites: • Basic familiarity with Alexa and Alexa skills • Basic familiarity with machine learning • Basic familiarity with Python • An account on the Amazon Developer Portal Delivery Method This course is delivered through a mix of: • Classroom training • Hands-on Labs Hands-on Activity • This course allows you to test new skills and apply knowledge to your working environment through a variety of practical exercises • This course requires a laptop to complete lab exercises; tablets are not appropriate Duration One Day Course Outline This course covers the following concepts: • Getting started with Alexa • Lab: Building an Alexa skill: Hello Alexa © 2018, Amazon Web Services, Inc. -
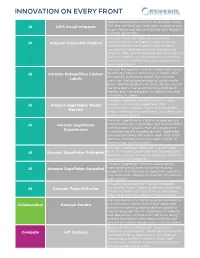
Innovation on Every Front
INNOVATION ON EVERY FRONT AWS DeepComposer uses AI to compose music. AI AWS DeepComposer The new service gives developers a creative way to get started and become familiar with machine learning capabilities. Amazon Transcribe Medical is a machine AI Amazon Transcribe Medical learning service that makes it easy to quickly create accurate transcriptions from medical consultations between patients and physician dictated notes, practitioner/patient consultations, and tele-medicine are automatically converted from speech to text for use in clinical documen- tation applications. Amazon Rekognition Custom Labels helps users AI Amazon Rekognition Custom identify the objects and scenes in images that are specific to business needs. For example, Labels users can find corporate logos in social media posts, identify products on store shelves, classify machine parts in an assembly line, distinguish healthy and infected plants, or detect animated characters in videos. Amazon SageMaker Model Monitor is a new AI Amazon SageMaker Model capability of Amazon SageMaker that automatically monitors machine learning (ML) Monitor models in production, and alerts users when data quality issues appear. Amazon SageMaker is a fully managed service AI Amazon SageMaker that provides every developer and data scientist with the ability to build, train, and deploy ma- Experiments chine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models. Amazon SageMaker Debugger is a new capa- AI Amazon SageMaker Debugger bility of Amazon SageMaker that automatically identifies complex issues developing in machine learning (ML) training jobs. Amazon SageMaker Autopilot automatically AI Amazon SageMaker Autopilot trains and tunes the best machine learning models for classification or regression, based on your data while allowing to maintain full control and visibility. -
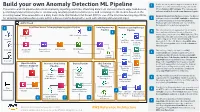
Build Your Own Anomaly Detection ML Pipeline
Device telemetry data is ingested from the field Build your own Anomaly Detection ML Pipeline 1 devices on a near real-time basis by calls to the This end-to-end ML pipeline detects anomalies by ingesting real-time, streaming data from various network edge field devices, API via Amazon API Gateway. The requests get performing transformation jobs to continuously run daily predictions/inferences, and retraining the ML models based on the authenticated/authorized using Amazon Cognito. incoming newer time series data on a daily basis. Note that Random Cut Forest (RCF) is one of the machine learning algorithms Amazon Kinesis Data Firehose ingests the data in for detecting anomalous data points within a data set and is designed to work with arbitrary-dimensional input. 2 real time, and invokes AWS Lambda to transform the data into parquet format. Kinesis Data AWS Cloud Firehose will automatically scale to match the throughput of the data being ingested. 1 Real-Time Device Telemetry Data Ingestion Pipeline 2 Data Engineering Machine Learning Devops Pipeline Pipeline The telemetry data is aggregated on an hourly 3 3 basis and re-partitioned based on the year, month, date, and hour using AWS Glue jobs. The Amazon Cognito AWS Glue Data Catalog additional steps like transformations and feature Device #1 engineering are performed for training the SageMaker AWS CodeBuild Anomaly Detection ML Model using AWS Glue Notebook Create ML jobs. The training data set is stored on Amazon Container S3 Data Lake. Amazon Kinesis AWS Lambda S3 Data Lake AWS Glue Device #2 Amazon API The training code is checked in an AWS Gateway Data Firehose 4 AWS SageMaker CodeCommit repo which triggers a Machine Training CodeCommit Containers Learning DevOps (MLOps) pipeline using AWS Dataset for Anomaly CodePipeline. -

Latest Poll Shows Gubernatorial Race Is Now a Dead Heat: 44-44 Here Are
Vol. 42, No 8 www.arlingtondemocrats.org August 2017 Latest poll shows gubernatorial The GOP may sue this conservative Virginia candidate race is now a dead heat: 44-44 over the The latest statewide poll shows a dead heat in 46 percent had no opinion. Gillespie was rated fa- the gubernatorial election with each major party vorably by 36 percent and unfavorably by 20 per- design of candidate drawing 44 percent support. cent with 44 percent having no opinion. his yard The poll, taken by Monmouth University in The poll found substantial regional differences. signs. New Jersey, surveyed 502 Virginians from July 20 Northam led in northern Virginia by 13 percentage to 23. points and in the eastern areas by 9 percentage points. The poll found only 3 percent support for Lib- Gillespie led by 2 percentage points in the center, a See Page ertarian Cliff Hyra and 1 percent for write-in candi- statistically meaningless difference, but by a whop- 5. dates, with 9 percent still undecided. That 9 per- ping 18 percentage points in the western areas. cent is enough to swing the election either way and The only other statewide poll published so far points to the need for a savvy campaign. was taken just after the primary by Quinnipiac Uni- As for issues, 37 percent put health care and versity and showed Northam with a comfortable health insurance as one of their top issues, which lead 47-39. would seem to play into the hands of Northam, a The race is expected to be an intense one with This Confederate-loving physician by profession. -

Cloud Computing & Big Data
Cloud Computing & Big Data PARALLEL & SCALABLE MACHINE LEARNING & DEEP LEARNING Ph.D. Student Chadi Barakat School of Engineering and Natural Sciences, University of Iceland, Reykjavik, Iceland Juelich Supercomputing Centre, Forschungszentrum Juelich, Germany @MorrisRiedel LECTURE 11 @Morris Riedel @MorrisRiedel Big Data Analytics & Cloud Data Mining November 10, 2020 Online Lecture Review of Lecture 10 –Software-As-A-Service (SAAS) ▪ SAAS Examples of Customer Relationship Management (CRM) Applications (PAAS) (introducing a growing range of machine (horizontal learning and scalability artificial enabled by (IAAS) intelligence Virtualization capabilities) in Clouds) [5] AWS Sagemaker [4] Freshworks Web page [3] ZOHO CRM Web page modfied from [2] Distributed & Cloud Computing Book [1] Microsoft Azure SAAS Lecture 11 – Big Data Analytics & Cloud Data Mining 2 / 36 Outline of the Course 1. Cloud Computing & Big Data Introduction 11. Big Data Analytics & Cloud Data Mining 2. Machine Learning Models in Clouds 12. Docker & Container Management 13. OpenStack Cloud Operating System 3. Apache Spark for Cloud Applications 14. Online Social Networking & Graph Databases 4. Virtualization & Data Center Design 15. Big Data Streaming Tools & Applications 5. Map-Reduce Computing Paradigm 16. Epilogue 6. Deep Learning driven by Big Data 7. Deep Learning Applications in Clouds + additional practical lectures & Webinars for our hands-on assignments in context 8. Infrastructure-As-A-Service (IAAS) 9. Platform-As-A-Service (PAAS) ▪ Practical Topics 10. Software-As-A-Service -

Roanoke College Poll Topline U.S. Senate Election August 22, 2018 Hi, I'm___And I'm Calling from Roanoke College. Ho
Roanoke College Poll Topline U.S. Senate Election August 22, 2018 Hi, I'm____________ and I'm calling from Roanoke College. How are you today/this evening? We're conducting a survey of Virginia residents regarding important issues and your opinion is very important to us. Your responses are confidential. 1. Are you registered to vote in Virginia? Yes 100% No [TERMINATE] 0% 2. How likely is it that you will vote in the election for senator in November? Is it very likely, somewhat likely, not very likely, or not likely at all? Very likely 86% Somewhat likely 14% Not very likely [TERMINATE] 0% Not likely at all [TERMINATE] 0% 3. Do you think things in the COUNTRY are generally going in the right direction or do you think things have gotten off on the wrong track? Right direction 37% Wrong track 56% Unsure 7% Refused 1% 4. Do you think things in the Commonwealth of Virginia re generally going in the right direction or do you think things have gotten off on the wrong track? Right direction 58% Wrong track 30% Unsure 10% Refused 2% 5. In general, do you approve or disapprove of the way Donald Trump is handling his job as President of the United States? Approve 32% Disapprove 53% Mixed 12% Don't Know/Refused 3% 6. In general, do you approve or disapprove of the way Ralph Northam is handling his job as Governor of Virginia? Approve 54% Disapprove 18% Mixed 13% Don't Know/Refused 15% 7. The 2018 election for senator is a few months away, but if the election for senator were held today, who would you vote for if the candidates were: [ROTATE FIRST THREE; READ FIRST THREE ONLY] Tim Kaine, the Democrat 49% Corey Stewart, the Republican 33% Matt Waters, the Libertarian 4% Undecided [VOLUNTERED ONLY] 14% 7. -

Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide
Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS: AWS Technical Guide Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Table of Contents Abstract and introduction .................................................................................................................... i Abstract .................................................................................................................................... 1 Introduction .............................................................................................................................. 1 Personas for an ML platform ............................................................................................................... 2 AWS accounts .................................................................................................................................... 3 Networking architecture ..................................................................................................................... -

Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework
Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework Analytics Lens: AWS Well-Architected Framework Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Analytics Lens AWS Well-Architected Framework Table of Contents Abstract ............................................................................................................................................ 1 Abstract .................................................................................................................................... 1 Introduction ...................................................................................................................................... 2 Definitions ................................................................................................................................. 2 Data Ingestion Layer ........................................................................................................... 2 Data Access and Security Layer ............................................................................................ 3 Catalog and Search Layer ...................................................................................................