Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Timeline 1994 July Company Incorporated 1995 July Amazon
Timeline 1994 July Company Incorporated 1995 July Amazon.com Sells First Book, “Fluid Concepts & Creative Analogies: Computer Models of the Fundamental Mechanisms of Thought” 1996 July Launches Amazon.com Associates Program 1997 May Announces IPO, Begins Trading on NASDAQ Under “AMZN” September Introduces 1-ClickTM Shopping November Opens Fulfillment Center in New Castle, Delaware 1998 February Launches Amazon.com Advantage Program April Acquires Internet Movie Database June Opens Music Store October Launches First International Sites, Amazon.co.uk (UK) and Amazon.de (Germany) November Opens DVD/Video Store 1999 January Opens Fulfillment Center in Fernley, Nevada March Launches Amazon.com Auctions April Opens Fulfillment Center in Coffeyville, Kansas May Opens Fulfillment Centers in Campbellsville and Lexington, Kentucky June Acquires Alexa Internet July Opens Consumer Electronics, and Toys & Games Stores September Launches zShops October Opens Customer Service Center in Tacoma, Washington Acquires Tool Crib of the North’s Online and Catalog Sales Division November Opens Home Improvement, Software, Video Games and Gift Ideas Stores December Jeff Bezos Named TIME Magazine “Person Of The Year” 2000 January Opens Customer Service Center in Huntington, West Virginia May Opens Kitchen Store August Announces Toys “R” Us Alliance Launches Amazon.fr (France) October Opens Camera & Photo Store November Launches Amazon.co.jp (Japan) Launches Marketplace Introduces First Free Super Saver Shipping Offer (Orders Over $100) 2001 April Announces Borders Group Alliance August Introduces In-Store Pick Up September Announces Target Stores Alliance October Introduces Look Inside The BookTM 2002 June Launches Amazon.ca (Canada) July Launches Amazon Web Services August Lowers Free Super Saver Shipping Threshold to $25 September Opens Office Products Store November Opens Apparel & Accessories Store 2003 April Announces National Basketball Association Alliance June Launches Amazon Services, Inc. -

Amazon Dynamodb
Dynamo Amazon DynamoDB Nicolas Travers Inspiré de Advait Deo Vertigo N. Travers ESILV : Dynamo Amazon DynamoDB – What is it ? • Fully managed nosql database service on AWS • Data model in the form of tables • Data stored in the form of items (name – value attributes) • Automatic scaling ▫ Provisioned throughput ▫ Storage scaling ▫ Distributed architecture • Easy Administration • Monitoring of tables using CloudWatch • Integration with EMR (Elastic MapReduce) ▫ Analyze data and store in S3 Vertigo N. Travers ESILV : Dynamo Amazon DynamoDB – What is it ? key=value key=value key=value key=value Table Item (64KB max) Attributes • Primary key (mandatory for every table) ▫ Hash or Hash + Range • Data model in the form of tables • Data stored in the form of items (name – value attributes) • Secondary Indexes for improved performance ▫ Local secondary index ▫ Global secondary index • Scalar data type (number, string etc) or multi-valued data type (sets) Vertigo N. Travers ESILV : Dynamo DynamoDB Architecture • True distributed architecture • Data is spread across hundreds of servers called storage nodes • Hundreds of servers form a cluster in the form of a “ring” • Client application can connect using one of the two approaches ▫ Routing using a load balancer ▫ Client-library that reflects Dynamo’s partitioning scheme and can determine the storage host to connect • Advantage of load balancer – no need for dynamo specific code in client application • Advantage of client-library – saves 1 network hop to load balancer • Synchronous replication is not achievable for high availability and scalability requirement at amazon • DynamoDB is designed to be “always writable” storage solution • Allows multiple versions of data on multiple storage nodes • Conflict resolution happens while reads and NOT during writes ▫ Syntactic conflict resolution ▫ Symantec conflict resolution Vertigo N. -

Building Machine Learning Inference Pipelines at Scale
Building Machine Learning inference pipelines at scale Julien Simon Global Evangelist, AI & Machine Learning @julsimon © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Problem statement • Real-life Machine Learning applications require more than a single model. • Data may need pre-processing: normalization, feature engineering, dimensionality reduction, etc. • Predictions may need post-processing: filtering, sorting, combining, etc. Our goal: build scalable ML pipelines with open source (Spark, Scikit-learn, XGBoost) and managed services (Amazon EMR, AWS Glue, Amazon SageMaker) © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Apache Spark https://spark.apache.org/ • Open-source, distributed processing system • In-memory caching and optimized execution for fast performance (typically 100x faster than Hadoop) • Batch processing, streaming analytics, machine learning, graph databases and ad hoc queries • API for Java, Scala, Python, R, and SQL • Available in Amazon EMR and AWS Glue © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. MLlib – Machine learning library https://spark.apache.org/docs/latest/ml-guide.html • Algorithms: classification, regression, clustering, collaborative filtering. • Featurization: feature extraction, transformation, dimensionality reduction. • Tools for constructing, evaluating and tuning pipelines • Transformer – a transform function that maps a DataFrame into a new -

Performance at Scale with Amazon Elasticache
Performance at Scale with Amazon ElastiCache July 2019 Notices Customers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents current AWS product offerings and practices, which are subject to change without notice, and (c) does not create any commitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. The responsibilities and liabilities of AWS to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers. © 2019 Amazon Web Services, Inc. or its affiliates. All rights reserved. Contents Introduction .......................................................................................................................... 1 ElastiCache Overview ......................................................................................................... 2 Alternatives to ElastiCache ................................................................................................. 2 Memcached vs. Redis ......................................................................................................... 3 ElastiCache for Memcached ............................................................................................... 5 Architecture with ElastiCache for Memcached ............................................................... -

Building Alexa Skills Using Amazon Sagemaker and AWS Lambda
Bootcamp: Building Alexa Skills Using Amazon SageMaker and AWS Lambda Description In this full-day, intermediate-level bootcamp, you will learn the essentials of building an Alexa skill, the AWS Lambda function that supports it, and how to enrich it with Amazon SageMaker. This course, which is intended for students with a basic understanding of Alexa, machine learning, and Python, teaches you to develop new tools to improve interactions with your customers. Intended Audience This course is intended for those who: • Are interested in developing Alexa skills • Want to enhance their Alexa skills using machine learning • Work in a customer-focused industry and want to improve their customer interactions Course Objectives In this course, you will learn: • The basics of the Alexa developer console • How utterances and intents work, and how skills interact with AWS Lambda • How to use Amazon SageMaker for the machine learning workflow and for enhancing Alexa skills Prerequisites We recommend that attendees of this course have the following prerequisites: • Basic familiarity with Alexa and Alexa skills • Basic familiarity with machine learning • Basic familiarity with Python • An account on the Amazon Developer Portal Delivery Method This course is delivered through a mix of: • Classroom training • Hands-on Labs Hands-on Activity • This course allows you to test new skills and apply knowledge to your working environment through a variety of practical exercises • This course requires a laptop to complete lab exercises; tablets are not appropriate Duration One Day Course Outline This course covers the following concepts: • Getting started with Alexa • Lab: Building an Alexa skill: Hello Alexa © 2018, Amazon Web Services, Inc. -
Innovation on Every Front
INNOVATION ON EVERY FRONT AWS DeepComposer uses AI to compose music. AI AWS DeepComposer The new service gives developers a creative way to get started and become familiar with machine learning capabilities. Amazon Transcribe Medical is a machine AI Amazon Transcribe Medical learning service that makes it easy to quickly create accurate transcriptions from medical consultations between patients and physician dictated notes, practitioner/patient consultations, and tele-medicine are automatically converted from speech to text for use in clinical documen- tation applications. Amazon Rekognition Custom Labels helps users AI Amazon Rekognition Custom identify the objects and scenes in images that are specific to business needs. For example, Labels users can find corporate logos in social media posts, identify products on store shelves, classify machine parts in an assembly line, distinguish healthy and infected plants, or detect animated characters in videos. Amazon SageMaker Model Monitor is a new AI Amazon SageMaker Model capability of Amazon SageMaker that automatically monitors machine learning (ML) Monitor models in production, and alerts users when data quality issues appear. Amazon SageMaker is a fully managed service AI Amazon SageMaker that provides every developer and data scientist with the ability to build, train, and deploy ma- Experiments chine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models. Amazon SageMaker Debugger is a new capa- AI Amazon SageMaker Debugger bility of Amazon SageMaker that automatically identifies complex issues developing in machine learning (ML) training jobs. Amazon SageMaker Autopilot automatically AI Amazon SageMaker Autopilot trains and tunes the best machine learning models for classification or regression, based on your data while allowing to maintain full control and visibility. -

Amazon Documentdb Deep Dive
DAT326 Amazon DocumentDB deep dive Joseph Idziorek Antra Grover Principal Product Manager Software Development Engineer Amazon Web Services Fulfillment By Amazon © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Agenda What is the purpose of a document database? What customer problems does Amazon DocumentDB (with MongoDB compatibility) solve and how? Customer use case and learnings: Fulfillment by Amazon What did we deliver for customers this year? What’s next? © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Purpose-built databases Relational Key value Document In-memory Graph Search Time series Ledger Why document databases? Denormalized data Normalized data model model { 'name': 'Bat City Gelato', 'price': '$', 'rating': 5.0, 'review_count': 46, 'categories': ['gelato', 'ice cream'], 'location': { 'address': '6301 W Parmer Ln', 'city': 'Austin', 'country': 'US', 'state': 'TX', 'zip_code': '78729'} } Why document databases? GET https://api.yelp.com/v3/businesses/{id} { 'name': 'Bat City Gelato', 'price': '$', 'rating': 5.0, 'review_count': 46, 'categories': ['gelato', 'ice cream'], 'location': { 'address': '6301 W Parmer Ln', 'city': 'Austin', 'country': 'US', 'state': 'TX', 'zip_code': '78729'} } Why document databases? response = yelp_api.search_query(term='ice cream', location='austin, tx', sort_by='rating', limit=5) Why document databases? for i in response['businesses']: col.insert_one(i) db.businesses.aggregate([ { $group: { _id: "$price", ratingAvg: { $avg: "$rating"}} } ]) db.businesses.find({ -
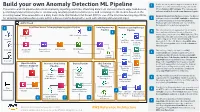
Build Your Own Anomaly Detection ML Pipeline
Device telemetry data is ingested from the field Build your own Anomaly Detection ML Pipeline 1 devices on a near real-time basis by calls to the This end-to-end ML pipeline detects anomalies by ingesting real-time, streaming data from various network edge field devices, API via Amazon API Gateway. The requests get performing transformation jobs to continuously run daily predictions/inferences, and retraining the ML models based on the authenticated/authorized using Amazon Cognito. incoming newer time series data on a daily basis. Note that Random Cut Forest (RCF) is one of the machine learning algorithms Amazon Kinesis Data Firehose ingests the data in for detecting anomalous data points within a data set and is designed to work with arbitrary-dimensional input. 2 real time, and invokes AWS Lambda to transform the data into parquet format. Kinesis Data AWS Cloud Firehose will automatically scale to match the throughput of the data being ingested. 1 Real-Time Device Telemetry Data Ingestion Pipeline 2 Data Engineering Machine Learning Devops Pipeline Pipeline The telemetry data is aggregated on an hourly 3 3 basis and re-partitioned based on the year, month, date, and hour using AWS Glue jobs. The Amazon Cognito AWS Glue Data Catalog additional steps like transformations and feature Device #1 engineering are performed for training the SageMaker AWS CodeBuild Anomaly Detection ML Model using AWS Glue Notebook Create ML jobs. The training data set is stored on Amazon Container S3 Data Lake. Amazon Kinesis AWS Lambda S3 Data Lake AWS Glue Device #2 Amazon API The training code is checked in an AWS Gateway Data Firehose 4 AWS SageMaker CodeCommit repo which triggers a Machine Training CodeCommit Containers Learning DevOps (MLOps) pipeline using AWS Dataset for Anomaly CodePipeline. -

Open Source in the Enterprise
Open Source in the Enterprise Andy Oram and Zaheda Bhorat Beijing Boston Farnham Sebastopol Tokyo Open Source in the Enterprise by Andy Oram and Zaheda Bhorat Copyright © 2018 O’Reilly Media. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online edi‐ tions are also available for most titles (http://oreilly.com/safari). For more information, contact our corporate/institutional sales department: 800-998-9938 or [email protected]. Editor: Michele Cronin Interior Designer: David Futato Production Editor: Kristen Brown Cover Designer: Karen Montgomery Copyeditor: Octal Publishing Services, Inc. July 2018: First Edition Revision History for the First Edition 2018-06-18: First Release The O’Reilly logo is a registered trademark of O’Reilly Media, Inc. Open Source in the Enterprise, the cover image, and related trade dress are trademarks of O’Reilly Media, Inc. The views expressed in this work are those of the authors, and do not represent the publisher’s views. While the publisher and the authors have used good faith efforts to ensure that the informa‐ tion and instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights. -

A Motion Is Requested to Authorize the Execution of a Contract for Amazon Business Procurement Services Through the U.S. Communities Government Purchasing Alliance
MOT 2019-8118 Page 1 of 98 VILLAGE OF DOWNERS GROVE Report for the Village Council Meeting 3/19/2019 SUBJECT: SUBMITTED BY: Authorization of a contract for Amazon Business procurement Judy Buttny services Finance Director SYNOPSIS A motion is requested to authorize the execution of a contract for Amazon Business procurement services through the U.S. Communities Government Purchasing Alliance. STRATEGIC PLAN ALIGNMENT The goals for 2017-2019 includes Steward of Financial Sustainability, and Exceptional, Continual Innovation. FISCAL IMPACT There is no cost to utilize Amazon Business procurement services through the U.S. Communities Government Purchasing Alliance. RECOMMENDATION Approval on the March 19, 2019 Consent Agenda. BACKGROUND U.S. Communities Government Purchasing Alliance is the largest public sector cooperative purchasing organization in the nation. All contracts are awarded by a governmental entity utilizing industry best practices, processes and procedures. The Village of Downers Grove has been a member of the U.S. Communities Government Purchasing Alliance since 2008. Through cooperative purchasing, the Village is able to take advantage of economy of scale and reduce the cost of goods and services. U.S. Communities has partnered with Amazon Services to offer local government agencies the ability to utilize Amazon Business for procurement services at no cost to U.S. Communities members. Amazon Business offers business-only prices on millions of products in a competitive digital market place and a multi-level approval workflow. Staff can efficiently find quotes and purchase products for the best possible price, and the multi-level approval workflow ensures this service is compliant with the Village’s competitive process for purchases under $7,000. -

Cloud Computing & Big Data
Cloud Computing & Big Data PARALLEL & SCALABLE MACHINE LEARNING & DEEP LEARNING Ph.D. Student Chadi Barakat School of Engineering and Natural Sciences, University of Iceland, Reykjavik, Iceland Juelich Supercomputing Centre, Forschungszentrum Juelich, Germany @MorrisRiedel LECTURE 11 @Morris Riedel @MorrisRiedel Big Data Analytics & Cloud Data Mining November 10, 2020 Online Lecture Review of Lecture 10 –Software-As-A-Service (SAAS) ▪ SAAS Examples of Customer Relationship Management (CRM) Applications (PAAS) (introducing a growing range of machine (horizontal learning and scalability artificial enabled by (IAAS) intelligence Virtualization capabilities) in Clouds) [5] AWS Sagemaker [4] Freshworks Web page [3] ZOHO CRM Web page modfied from [2] Distributed & Cloud Computing Book [1] Microsoft Azure SAAS Lecture 11 – Big Data Analytics & Cloud Data Mining 2 / 36 Outline of the Course 1. Cloud Computing & Big Data Introduction 11. Big Data Analytics & Cloud Data Mining 2. Machine Learning Models in Clouds 12. Docker & Container Management 13. OpenStack Cloud Operating System 3. Apache Spark for Cloud Applications 14. Online Social Networking & Graph Databases 4. Virtualization & Data Center Design 15. Big Data Streaming Tools & Applications 5. Map-Reduce Computing Paradigm 16. Epilogue 6. Deep Learning driven by Big Data 7. Deep Learning Applications in Clouds + additional practical lectures & Webinars for our hands-on assignments in context 8. Infrastructure-As-A-Service (IAAS) 9. Platform-As-A-Service (PAAS) ▪ Practical Topics 10. Software-As-A-Service -

Amazon Elasticache Deep Dive Powering Modern Applications with Low Latency and High Throughput
Amazon ElastiCache Deep Dive Powering modern applications with low latency and high throughput Michael Labib Sr. Manager, Non-Relational Databases © 2020, Amazon Web Services, Inc. or its Affiliates. Agenda • Introduction to Amazon ElastiCache • Redis Topologies & Features • ElastiCache Use Cases • Monitoring, Sizing & Best Practices © 2020, Amazon Web Services, Inc. or its Affiliates. Introduction to Amazon ElastiCache © 2020, Amazon Web Services, Inc. or its Affiliates. Purpose-built databases © 2020, Amazon Web Services, Inc. or its Affiliates. Purpose-built databases © 2020, Amazon Web Services, Inc. or its Affiliates. Modern real-time applications require Performance, Scale & Availability Users 1M+ Data volume Terabytes—petabytes Locality Global Performance Microsecond latency Request rate Millions per second Access Mobile, IoT, devices Scale Up-out-in E-Commerce Media Social Online Shared economy Economics Pay-as-you-go streaming media gaming Developer access Open API © 2020, Amazon Web Services, Inc. or its Affiliates. Amazon ElastiCache – Fully Managed Service Redis & Extreme Secure Easily scales to Memcached compatible performance and reliable massive workloads Fully compatible with In-memory data store Network isolation, encryption Scale writes and open source Redis and cache for microsecond at rest/transit, HIPAA, PCI, reads with sharding and Memcached response times FedRAMP, multi AZ, and and replicas automatic failover © 2020, Amazon Web Services, Inc. or its Affiliates. What is Redis? Initially released in 2009, Redis provides: • Complex data structures: Strings, Lists, Sets, Sorted Sets, Hash Maps, HyperLogLog, Geospatial, and Streams • High-availability through replication • Scalability through online sharding • Persistence via snapshot / restore • Multi-key atomic operations A high-speed, in-memory, non-Relational data store. • LUA scripting Customers love that Redis is easy to use.