Llnet: a Deep Autoencoder Approach to Natural Low-Light Image Enhancement
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

10S Johnson-Nyquist Noise Masatsugu Sei Suzuki Department of Physics, SUNY at Binghamton (Date: January 02, 2011)
Chapter 10S Johnson-Nyquist noise Masatsugu Sei Suzuki Department of Physics, SUNY at Binghamton (Date: January 02, 2011) Johnson noise Johnson-Nyquist theorem Boltzmann constant Parseval relation Correlation function Spectral density Wiener-Khinchin (or Khintchine) Flicker noise Shot noise Poisson distribution Brownian motion Fluctuation-dissipation theorem Langevin function ___________________________________________________________________________ John Bertrand "Bert" Johnson (October 2, 1887–November 27, 1970) was a Swedish-born American electrical engineer and physicist. He first explained in detail a fundamental source of random interference with information traveling on wires. In 1928, while at Bell Telephone Laboratories he published the journal paper "Thermal Agitation of Electricity in Conductors". In telecommunication or other systems, thermal noise (or Johnson noise) is the noise generated by thermal agitation of electrons in a conductor. Johnson's papers showed a statistical fluctuation of electric charge occur in all electrical conductors, producing random variation of potential between the conductor ends (such as in vacuum tube amplifiers and thermocouples). Thermal noise power, per hertz, is equal throughout the frequency spectrum. Johnson deduced that thermal noise is intrinsic to all resistors and is not a sign of poor design or manufacture, although resistors may also have excess noise. http://en.wikipedia.org/wiki/John_B._Johnson 1 ____________________________________________________________________________ Harry Nyquist (February 7, 1889 – April 4, 1976) was an important contributor to information theory. http://en.wikipedia.org/wiki/Harry_Nyquist ___________________________________________________________________________ 10S.1 Histrory In 1926, experimental physicist John Johnson working in the physics division at Bell Labs was researching noise in electronic circuits. He discovered random fluctuations in the voltages across electrical resistors, whose power was proportional to temperature. -

Survey of Noise in Image and Efficient Technique for Noise Reduction
International Journal of Science and Research (IJSR) ISSN (Online): 2319-7064 Index Copernicus Value (2015): 78.96 | Impact Factor (2015): 6.391 Survey of Noise in Image and Efficient Technique for Noise Reduction Arti Singh1, Madhu2 1, 2Research Scholar, Computer Science, BBAU University, Lucknow , Uttar Pradesh, India Abstract: Removing noise from the image is big challenge for researcher because removal of noise in image causes the artifacts and image blurring. Noise occurred in image during the time of capturing and transmission of the image. There are many methods for noise removal from the images. Many algorithms and techniques are available for removing noise from image, but each method exist their own assumptions, merits and demerits. Noise reduction algorithms for remove noise is totally depends on what type of noise occur in the image. In this paper, focus on some important type of noise and noise removal techniques is done. Keywords: Impulse noise, Gaussian noise , Speckle noise ,Poisson noise, mean filter, median filter ,etc 1. Introduction or over heated faulty component can cause noise arise in image because of sharp and sudden changes of Digital image processing is using of algorithms for image signal. 퐼 푖, 푗 푥 < 푙 improve quality order of digital image .This error on 퐼푠푝 푖, 푗 = image is called noise in image which do not reflect real 퐼푚푖푛 + 푌 퐼푚푎푥 −퐼푚푖푛 푥 > 푙 intensities of actual scene. There are two problems found x,y∈[0,1] are two uniformly distributed random variables in image processing: Blurring and image noise. Noise image occurred by many reasons: When we capture image from camera (scratches are available in camera). -
![Arxiv:2003.13216V1 [Cs.CV] 30 Mar 2020](https://docslib.b-cdn.net/cover/3269/arxiv-2003-13216v1-cs-cv-30-mar-2020-263269.webp)
Arxiv:2003.13216V1 [Cs.CV] 30 Mar 2020
Learning to Learn Single Domain Generalization Fengchun Qiao Long Zhao Xi Peng University of Delaware Rutgers University University of Delaware [email protected] [email protected] [email protected] Abstract : Source domain(s) <latexit sha1_base64="glUSn7xz2m1yKGYjqzzX12DA3tk=">AAAB8nicjVDLSsNAFL3xWeur6tLNYBFclaQKdllw47KifUAaymQ6aYdOJmHmRiihn+HGhSJu/Rp3/o2TtgsVBQ8MHM65l3vmhKkUBl33w1lZXVvf2Cxtlbd3dvf2KweHHZNkmvE2S2SieyE1XArF2yhQ8l6qOY1Dybvh5Krwu/dcG5GoO5ymPIjpSIlIMIpW8vsxxTGjMr+dDSpVr+bOQf4mVViiNai894cJy2KukElqjO+5KQY51SiY5LNyPzM8pWxCR9y3VNGYmyCfR56RU6sMSZRo+xSSufp1I6exMdM4tJNFRPPTK8TfPD/DqBHkQqUZcsUWh6JMEkxI8X8yFJozlFNLKNPCZiVsTDVlaFsq/6+ETr3mndfqNxfVZmNZRwmO4QTOwINLaMI1tKANDBJ4gCd4dtB5dF6c18XoirPcOYJvcN4+AY5ZkWY=</latexit> <latexit sha1_base64="9X8JvFzvWSXuFK0x/Pe60//G3E4=">AAACD3icbVDLSsNAFJ3UV62vqks3g0Wpm5LW4mtVcOOyUvuANpTJZNIOnUzCzI1YQv/Ajb/ixoUibt26829M2iBqPTBwOOfeO/ceOxBcg2l+GpmFxaXllexqbm19Y3Mrv73T0n6oKGtSX/iqYxPNBJesCRwE6wSKEc8WrG2PLhO/fcuU5r68gXHALI8MJHc5JRBL/fxhzyMwpEREjQnuAbuD6AI3ptOx43uEy6I+muT6+YJZMqfA86SckgJKUe/nP3qOT0OPSaCCaN0tmwFYEVHAqWCTXC/ULCB0RAasG1NJPKataHrPBB/EioNdX8VPAp6qPzsi4mk99uy4Mtle//US8T+vG4J7ZkVcBiEwSWcfuaHA4OMkHOxwxSiIcUwIVTzeFdMhUYRCHOEshPMEJ98nz5NWpVQ+LlWvq4VaJY0ji/bQPiqiMjpFNXSF6qiJKLpHj+gZvRgPxpPxarzNSjNG2rOLfsF4/wJA4Zw6</latexit> S S : Target domain(s) <latexit sha1_base64="ssITTP/Vrn2uchq9aDxvcfruPQc=">AAACD3icbVDLSgNBEJz1bXxFPXoZDEq8hI2Kr5PgxWOEJAaSEHonnWTI7Owy0yuGJX/gxV/x4kERr169+TfuJkF8FTQUVd10d3mhkpZc98OZmp6ZnZtfWMwsLa+srmXXN6o2iIzAighUYGoeWFRSY4UkKayFBsH3FF57/YvUv75BY2WgyzQIselDV8uOFECJ1MruNnygngAVl4e8QXhL8Rkvg+ki8Xbgg9R5uzfMtLI5t+COwP+S4oTk2ASlVva90Q5E5KMmocDaetENqRmDISkUDjONyGIIog9drCdUg4+2GY/+GfKdRGnzTmCS0sRH6veJGHxrB76XdKbX299eKv7n1SPqnDRjqcOIUIvxok6kOAU8DYe3pUFBapAQEEYmt3LRAwOCkgjHIZymOPp6+S+p7heKB4XDq8Pc+f4kjgW2xbZZnhXZMTtnl6zEKkywO/bAntizc+88Oi/O67h1ypnMbLIfcN4+ATKRnDE=</latexit> -
Next Topic: NOISE
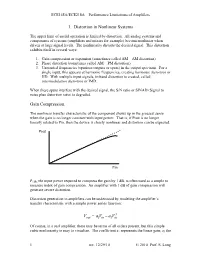
ECE145A/ECE218A Performance Limitations of Amplifiers 1. Distortion in Nonlinear Systems The upper limit of useful operation is limited by distortion. All analog systems and components of systems (amplifiers and mixers for example) become nonlinear when driven at large signal levels. The nonlinearity distorts the desired signal. This distortion exhibits itself in several ways: 1. Gain compression or expansion (sometimes called AM – AM distortion) 2. Phase distortion (sometimes called AM – PM distortion) 3. Unwanted frequencies (spurious outputs or spurs) in the output spectrum. For a single input, this appears at harmonic frequencies, creating harmonic distortion or HD. With multiple input signals, in-band distortion is created, called intermodulation distortion or IMD. When these spurs interfere with the desired signal, the S/N ratio or SINAD (Signal to noise plus distortion ratio) is degraded. Gain Compression. The nonlinear transfer characteristic of the component shows up in the grossest sense when the gain is no longer constant with input power. That is, if Pout is no longer linearly related to Pin, then the device is clearly nonlinear and distortion can be expected. Pout Pin P1dB, the input power required to compress the gain by 1 dB, is often used as a simple to measure index of gain compression. An amplifier with 1 dB of gain compression will generate severe distortion. Distortion generation in amplifiers can be understood by modeling the amplifier’s transfer characteristic with a simple power series function: 3 VaVaVout=−13 in in Of course, in a real amplifier, there may be terms of all orders present, but this simple cubic nonlinearity is easy to visualize. -

Performance Analysis of Spatial and Transform Filters for Efficient Image Noise Reduction
Performance Analysis of Spatial and Transform Filters for Efficient Image Noise Reduction Santosh Paudel Ajay Kumar Shrestha Pradip Singh Maharjan Rameshwar Rijal Computer and Electronics Computer and Electronics Computer and Electronics Computer and Electronics Engineering Engineering Engineering Engineering KEC, TU KEC, TU KEC, TU KEC, TU Lalitpur, Nepal Lalitpur, Nepal Lalitpur, Nepal Lalitpur, Nepal [email protected] [email protected] [email protected] [email protected] Abstract—During the acquisition of an image from its systems such as laser, acoustics and SAR (Synthetic source, noise always becomes integral part of it. Various Aperture Radar) images [3]. algorithms have been used in past to denoise the images. Image denoising still has scope for improvement. Visual This paper introduces different types of noise to be information transmitted in the form of digital images has considered in an image and analyzed for various spatial become a considerable method of communication in the and transforms domain filters by considering the image modern age, but the image obtained after transmission is metrics such as mean square error (MSE), root mean often corrupted due to noise. In this paper, we review the squared error (RMSE), Peak Signal to Noise Ratio existing denoising algorithms such as filtering approach (PSNR) and universal quality index (UQI). and wavelets based approach, and then perform their comparative study with bilateral filters. We use different II. BACKGROUND noise models to describe additive and multiplicative noise The Wavelet Transform (WT) is a powerful tool of in an image. Based on the samples of degraded pixel signal and image processing, which has been neighborhoods as inputs, the output of an efficient filtering successfully used in many scientific fields such as signal approach has shown a better image denoising performance. -

Thermal-Noise.Pdf
Thermal Noise Introduction One might naively believe that if all sources of electrical power are removed from a circuit that there will be no voltage across any of the components, a resistor for example. On average this is correct but a close look at the rms voltage would reveal that a "noise" voltage is present. This intrinsic noise is due to thermal fluctuations and can be calculated as may be done in your second year thermal physics course! The main goal of this experiment is to measure and characterize this noise: Johnson noise. In order to measure the intrinsic noise of a component one must first reduce the extrinsic sources of noise, i.e. interference. You have probably noticed that if you touch the input lead to an oscilloscope a large signal appears. Try this now and characterize the signal you see. Note that you are acting as an antenna! Make sure you look at both long time scales, say 10 ms, and shorter time scales, say 1 s. What are the likely sources of the signals you see? You may recall seeing this before in the First Year Laboratory. This interference is characterized by two features. First, the noise voltage is characterized by a spectrum, i.e. the noise voltage Vn ( f ) is a function of frequency. 2 Since noise usually has a time average of zero, the power spectrum Vn ( f ) is specified in each frequency interval df . Second, the measuring instrument is also characterized by a spectral response or bandwidth. In our case the bandwidth of the oscilloscope is from fL =0 (when input is DC coupled) to an upper frequency fH usually noted on the scope (beware of bandwidth limiting switches). -

Nasa Tm- 77750 Nasa Technical Memorandum Nasa Tm-77750
NASA TM- 77750 NASA TECHNICAL MEMORANDUM NASA TM-77750 NASA-TM-77750 19850004171 PATTERNS OF BEHAVIOD<TN LODGINGS EXPOSED TO TRAFFIC NOISE Jacques Lambert, Francois Simonnet Translation of "Comportements dans l'habitat soumis au bruit de circulation". Institut de Recherche des Transports, Arcueil, France, Rapport de Recherche I.R.T. No. 47, September, 1980, pp 1-145. 11.,. NATIONAL AERONAUTICS AND SPACE ADMINISTRATION WASHINGTON D.C. 20546 NOVEMBER 1984 • • \ IT........ f.n.• PM. ,. II. 0 ... I. .M.,...·.c.......... NAS1\. TM.,-77750 .. , ...... S....... PATTERNS or' BEHAVIOR IN I. • .,.,. hie November, 1984 TF~FFIC LODGINGS EXPOSED TO NOISE • •. ,.,te-t". 0, ee. 70 A.......c.. I. ''''e''''. 0. H.. Jacques Lambert, Francois Simonnet 11...... "-'..... '. 1-------------------------1... e.......... 0......... t. ' .......... 0,.......'... N... et4 ........ MAS... .~C; 42 SCITRAN • lox S4S6 .' II. ,,,..,......., ...c.....4 r.__ • a _..,.... ClI·un. 'rraul.t1oll, 12. SU4t1~&:r"&;rD_==_ .. Sp.at MaiIliat~.t.io.....-----------..f VUD1qtOD. D~Ce ~0546 No Ate-f c... I'" ...........,.......Translatlon. .. of "COITInortements dans l'habltat. soumis au bruit de circulation".'" Institut de·Recherche des Transports, Arcuei1, France, Rapport de Recherche' I ~R •. ~.· No. 47, September, 1980, pp. 1-145. , .. M ......· Thresho1c values at which public services should intervene ~o attenuate the noise nuisance are defined. Observations were made in the field of daily life at .. home. Data was collecte<J. on the use of loe1gings, on effects of noise on health and sleep~ and on the incidence of running away from home. A correlation was made also with the equipment. and noise insulation of lodgings. The results s.how that abov.eGG dB in daytime, there are behavior patterns that are extreme so far as they modify in a considerable manner the way bf, life of-people, living in both collective housing Capartments) and in individual houses • • ~. -

Noise Assessment Activities
Noise assessment activities Interesting stories in Europe ETC/ACM Technical Paper 2015/6 April 2016 Gabriela Sousa Santos, Núria Blanes, Peter de Smet, Cristina Guerreiro, Colin Nugent The European Topic Centre on Air Pollution and Climate Change Mitigation (ETC/ACM) is a consortium of European institutes under contract of the European Environment Agency RIVM Aether CHMI CSIC EMISIA INERIS NILU ÖKO-Institut ÖKO-Recherche PBL UAB UBA-V VITO 4Sfera Front page picture: Composite that includes: photo of a street in Berlin redesigned with markings on the asphalt (from SSU, 2014); view of a noise barrier in Alverna (The Netherlands)(from http://www.eea.europa.eu/highlights/cutting-noise-with-quiet-asphalt), a page of the website http://rumeur.bruitparif.fr for informing the public about environmental noise in the region of Paris. Author affiliation: Gabriela Sousa Santos, Cristina Guerreiro, Norwegian Institute for Air Research, NILU, NO Núria Blanes, Universitat Autònoma de Barcelona, UAB, ES Peter de Smet, National Institute for Public Health and the Environment, RIVM, NL Colin Nugent, European Environment Agency, EEA, DK DISCLAIMER This ETC/ACM Technical Paper has not been subjected to European Environment Agency (EEA) member country review. It does not represent the formal views of the EEA. © ETC/ACM, 2016. ETC/ACM Technical Paper 2015/6 European Topic Centre on Air Pollution and Climate Change Mitigation PO Box 1 3720 BA Bilthoven The Netherlands Phone +31 30 2748562 Fax +31 30 2744433 Email [email protected] Website http://acm.eionet.europa.eu/ 2 ETC/ACM Technical Paper 2015/6 Contents 1 Introduction ...................................................................................................... 5 2 Noise Action Plans ......................................................................................... -

Analysis of Image Noise in Multispectral Color Acquisition
ANALYSIS OF IMAGE NOISE IN MULTISPECTRAL COLOR ACQUISITION Peter D. Burns Submitted to the Center for Imaging Science in partial fulfillment of the requirements for Ph.D. degree at the Rochester Institute of Technology May 1997 The design of a system for multispectral image capture will be influenced by the imaging application, such as image archiving, vision research, illuminant modification or improved (trichromatic) color reproduction. A key aspect of the system performance is the effect of noise, or error, when acquiring multiple color image records and processing of the data. This research provides an analysis that allows the prediction of the image-noise characteristics of systems for the capture of multispectral images. The effects of both detector noise and image processing quantization on the color information are considered, as is the correlation between the errors in the component signals. The above multivariate error-propagation analysis is then applied to an actual prototype system. Sources of image noise in both digital camera and image processing are related to colorimetric errors. Recommendations for detector characteristics and image processing for future systems are then discussed. Indexing terms: color image capture, color image processing, image noise, error propagation, multispectral imaging. Electronic Distribution Edition 2001. ©Peter D. Burns 1997, 2001 All rights reserved. COPYRIGHT NOTICE P. D. Burns, ‘Analysis of Image Noise in Multispectral Color Acquisition’, Ph.D. Dissertation, Rochester Institute of Technology, 1997. Copyright © Peter D. Burns 1997, 2001 Published by the author All rights reserved. No part of this work may be reproduced, stored in a retrieval system, or transmitted in any form, or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission of the copyright holder. -
Noise Is Widespread
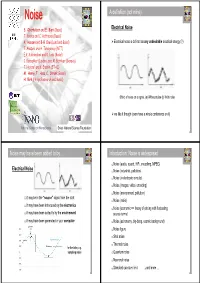
NoiseNoise A definition (not mine) Electrical Noise S. Oberholzer and E. Bieri (Basel) T. Kontos and C. Hoffmann (Basel) A. Hansen and B-R Choi (Lund and Basel) ¾ Electrical noise is defined as any undesirable electrical energy (?) T. Akazaki and H. Takayanagi (NTT) E.V. Sukhorukov and D. Loss (Basel) C. Beenakker (Leiden) and M. Büttiker (Geneva) T. Heinzel and K. Ensslin (ETHZ) M. Henny, T. Hoss, C. Strunk (Basel) H. Birk (Philips Research and Basel) Effect of noise on a signal. (a) Without noise (b) With noise ¾ we like it though (even have a whole conference on it) National Center on Nanoscience Swiss National Science Foundation 1 2 Noise may have been added to by ... Introduction: Noise is widespread Noise (audio, sound, HiFi, encodimg, MPEG) Electrical Noise Noise (industrial, pollution) Noise (in electronic circuits) Noise (images, video, encoding) Noise (environment, pollution) it may be in the “source” signal from the start Noise (radio) it may have been introduced by the electronics Noise (economic => theory of pricing with fluctuating it may have been added to by the envirnoment source terms) it may have been generated in your computer Noise (astronomy, big-bang, cosmic background) Noise figure Shot noise Thermal noise for the latter, e.g. sampling noise Quantum noise Neuronal noise Standard quantum limit and more ... 3 4 Introduction: Noise is widespread Introduction (Wikipedia) Noise (audio, sound, HiFi, encodimg, MPEG) Electronic Noise (from Wikipedia) Noise (industrial, pollution) Noise (in electronic circuits) Noise (images, video, encoding) Electronic noise exists in any electronic circuit as a result of random variations in current or voltage caused by the random movement of the Noise (environment, pollution) electrons carrying the current as they are jolted around by thermal energy.energy Noise (radio) The lower the temperature the lower is this thermal noise. -

Local Noise Action Plans
Practitioner Handbook for Local Noise Action Plans Recommendations from the SILENCE project SILENCE is an Integrated Project co-funded by the European Commission under the Sixth Framework Programme for R&D, Priority 6 Sustainable Development, Global Change and Ecosystems Guidance for readers Step 1: Getting started – responsibilities and competences • These pages give an overview on the steps of action planning and Objective To defi ne a leader with suffi cient capacities and competences to the noise abatement measures and are especially interesting for successfully setting up a local noise action plan. To involve all relevant stakeholders and make them contribute to the implementation of the plan clear competences with the leading department are needed. The END ... DECISION MAKERS and TRANSPORT PLANNERS. Content Requirements of the END and any other national or The current responsibilities for noise abatement within the local regional legislation regarding authorities will be considered and it will be assessed whether these noise abatement should be institutional settings are well fi tted for the complex task of noise considered from the very action planning. It might be advisable to attribute the leadership to beginning! another department or even to create a new organisation. The organisational settings for steering and carrying out the work to be done will be decided. The fi nancial situation will be clarifi ed. A work plan will be set up. If support from external experts is needed, it will be determined in this stage. To keep in mind For many departments, noise action planning will be an additional task. It is necessary to convince them of the benefi ts and the synergies with other policy fi elds and to include persons in the steering and working group that are willing and able to promote the issue within their departments. -

Measurement of Noise and Resolution in PET 1071 Large ROI in a Single Static Image
IOP PUBLISHING PHYSICS IN MEDICINE AND BIOLOGY Phys. Med. Biol. 55 (2010) 1069–1081 doi:10.1088/0031-9155/55/4/011 Simultaneous measurement of noise and spatial resolution in PET phantom images Martin A Lodge1, Arman Rahmim1 and Richard L Wahl1,2 1 Division of Nuclear Medicine, The Russell H. Morgan Department of Radiology and Radiological Sciences, Johns Hopkins University School of Medicine, Baltimore, MD, USA 2 Sidney Kimmel Comprehensive Cancer Center at Johns Hopkins, Johns Hopkins University School of Medicine, Baltimore, MD, USA E-mail: [email protected] Received 31 August 2009, in final form 21 December 2009 Published 28 January 2010 Online at stacks.iop.org/PMB/55/1069 Abstract As an aid to evaluating image reconstruction and correction algorithms in positron emission tomography, a phantom procedure has been developed that simultaneously measures image noise and spatial resolution. A commercially available 68Ge cylinder phantom (20 cm diameter) was positioned in the center of the field-of-view and two identical emission scans were sequentially performed. Image noise was measured by determining the difference between corresponding pixels in the two images and by calculating the standard deviation of these difference data. Spatial resolution was analyzed using a Fourier technique to measure the extent of the blurring at the edge of the phantom images. This paper addresses the noise aspects of the technique as the spatial resolution measurement has been described elsewhere. The noise measurement was validated by comparison with data obtained from multiple replicate images over a range of noise levels. In addition, we illustrate how simultaneous measurement of noise and resolution can be used to evaluate two different corrections for random coincidence events: delayed event subtraction and singles-based randoms correction.