Contract Bridge Bidding by Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

England Are European Champions, Win Gold at Bridge Competition in Budapest
THE ENGLISH BRIDGE UNION Broadfields, Bicester Road Aylesbury, Bucks, HP19 8AZ Telephone 01296 317200 25th June 2016 PRESS RELEASE For immediate release England are European Champions, win Gold at bridge competition in Budapest As the battle for European glory continues on the football pitches of France, England's Women's bridge team have ensured that Britain will have at least one European Championship winning side this summer. England's Women's bridge team have won gold at the 53rd European Team Championships which have concluded today in Budapest. The team was in second or third place for most of the seven day event, but moved in to the gold medal position in the penultimate round of matches, and beat second placed Poland in the final match to confirm their place atop the table. This is the sixth consecutive World or European event at which the England Women's team has won a medal making them one of the most successful British international teams in any sport in recent years. The team was: Heather Dhondy & Nevena Senior; Sally Brock & Nicola Smith; Fiona Brown & Catherine Draper; non-playing-captain: Derek Patterson; Coach: David Burn. England's Open team1 and Senior team2 were less successful in their competitions, with both sides disappointingly finishing in 10th place. Teams from Wales and Scotland also took part, but none finished in the top 10. 37 countries participated in the Open competition, 24 in the Seniors' competition and 23 in the Women's competition. The event was run by the European Bridge League - www.eurobridge.org - and Brexit won't affect British participation in the 2018 event. -

15Th WORLD BRIDGE GAMES Wroclaw, Poland • 3Rd – 17Th September 2016
15th WORLD BRIDGE GAMES wroclaw, poland • 3rd – 17th september 2016 Coordinator: Jean-Paul Meyer • Editor: Brent Manley Co-editors: Jos Jacobs, Micke Melander, Ram Soffer, David Stern, Marek Wojcicki Lay out Editor: Monika Kümmel • Photographer: Ron Tacchi Issue NDailyo. 8 Bulletin Sunday, 10th September 2016 HOME TEAMS MAKE POLAND PROUD In Progress: The 20th Ourgame World Computer-Bridge Championship Contents Knockout results . .2 Besides being a genial host for the 15th World Bridge Games, Poland is playing some dynamic bridge. In three of the four events now in the knockout stage, Poland has Technology + bridge = the lead, in two cases by substantial margins. the ‘ultimate challenge’ . .5 In the Open, Poland has a 185-81 lead on Switzerland after four 16-board matches. Hands and Match reports . .6 In the Seniors series, Poland is ahead of Australia 175-117, and in the Women’s the The AGM of the IBPA . .7 home team leads Spain 138-111. Championship Diary . .9+11 Poland trails only in the Mixed Teams. After four sets, they are trailing Denmark From The Rules And 155-108. Regulations Committee . .19 Other notable scores from play on Saturday include a 131-81 score for New The Polish Corner . .20 Zealand over France in the Open series, where the strong USA team leads Spain by 133-126. Also in the Open series, the Netherlands are cruising against Russia with a 169-81 lead. Sweden is also feeling good about their day, leading Japan 157-74. Today’s Programme In the Women’s series, Germany and Norway are practically deadlocked, with Norway ahead just 132-130. -

Educating Toto Test Your Technique the Rabbit's Sticky Wicket
A NEW BRIDGE MAGAZINE The Rabbit’s Sticky Wicket Test Your Technique Educating Toto EDITION 22 October 2019 A NEW BRIDGE MAGAZINE – OCTOBER 2019 The State of the Union announcement of the Writing on its web site, the Chairman of the start of an U31 series English Bridge Union rightly pays tribute to the as from next year. performance of the English teams in the recently Funding these brings concluded World Championships in Wuhan. He a greater burden on A NEW concludes with the sentence: All in all an excel- the membership and lent performance and one I think the membership the current desire of will join with me in saying well done to our teams. the WBF to hold many events in China means If the EBU believe the membership takes pride that travel costs are high. The EBU expects to in the performance of its teams at international support international teams but not without level it is difficult to understand the decision to limit. That is, after all, one reason for its exist- BRIDGE withdraw financial support for English teams ence. We expect to continue to support junior hoping to compete in the World Bridge Games events into the future. We also expect to support MAGAZINE in 2020. (They will still pay the entry fees). They Editor: all our teams to at least some extent. Sometimes will continue to support some of the teams that is entry fee and uniform costs only. That is Mark Horton competing in the European Championships in true, for example of the Mixed series introduced Advertising: Madeira in 2020, but because it will now be eas- last year. -

Backs Against the Wall
Co-Ordinator: Jean-Paul Meyer, Chief Editor: Brent Manley, Layout Editor: George Hatzidakis, WebEditor: Akis Kanaris, Photographer: Ron Tacchi, Editors: Phillip Alder, Mark Horton, Barry Rigal Bulletin 13 - Friday, 17 October 2008 BACKS AGAINST THE WALL The Great Wall After their stirring match against the USA to make it to the gold-medal round of the Women’s series, China struggled in the first three sets against England. They will Today’s start play today trailing by 83 IMPs. In the Open series, the powerful Italian squad has a 45-IMP lead over England, which recovered in the third set after a rocky start. The USA Seniors are leading Japan by 43 after three sets. Schedule Three bronze medal winners were determined yesterday. Norway defeated Ger- 11.00 Open - Women - Senior many in the Open, USA beat Turkey in the Women’s and Indonesia got the best of Teams, Final, 4th Session Egypt in the Seniors. 14.20 Open - Women - Senior In the World Transnational Mixed Teams, today’s three-session final was set when Teams, Final, 5th Session Russia beat A-Everything Trust Group and Yeh Bros defeated Auken. 17.10 Open - Women - Senior Medal ceremonies Teams, Final, 6th Session Medal ceremonies for the Seniors and Transnational Mixed Teams will take place at 10.00 - 21.00 7:30 p.m. today in the auditorium at the BICC. Transnational Mixed Teams, The medals for the Open and Women’s teams will be awarded at 8:15 p.m. Buses Final for players and supporters will leave the Intercontinental Hotel for the BICC at 8 p.m. -

OCBL Open League: ROUND 7
OCBL JOURNAL Issue N. 23. Tuesday, 26 January, 2021 OCBL OPEN LEAGUE OCBL Open League: ROUND 7. 21.30 CET / 15.30 EST GROUP A Round 7 English Juniors VS Aus 1 Black VS Skeidar Bridge42 VS Goodman Moss VS Ireland Goded VS Mikadinho Turkish Delight VS Skalman GROUP B Sugi VS Harris Fredin VS Salvo Lupoveloce VS Ferguson Lebowitz VS Orca Denmark VS Bishel Fasting VS France Sud GROUP C Palma VS Alexander Norwegian Amazones VS BridgeScanner Leslie VS McIceberg VUGRAPH De Botton VS Seligman Koeppel VS Amateurs Amalgamated VS De Michelis The seventh round of the OCBL Open League will be played today. The OCBL JOURNAL The vugraph match will also be broadcast on Twitch! Today's commentators are Liam Milne and Magnus Olafsson (pictured in your MAILBOX above). Enjoy the show by connecting to the WBT Twitch channel at 21.30 CET / 15.30 EST: https://www.twitch.tv/worldbridgetour Send us your up-to-date pic, please! It has been a long time since many of us last met and we are doing our best to make your online Bridge experience as valuable as we can. Obviously when producing Bridge articles it is Would you like receiving the necessary OCBL Daily Journal to use photos from the archives, as the last Christian Bakke, Norway international face-to-face Bridge event was held by e-mail for free? several months ago (the 2020 Winter Games in Monaco). Since online play is at the moment our new ‘present’, we would like to represent it as Just drop your e-mail address here: it is! So if you can please send us a picture (can be a selfie) of yourself playing online https://ocbl.org/journal/ Bridge. -

SUPPLEMENTAL CONDITIONS of CONTEST for MOHANLAL BHARTIA MEMORIAL BRIDGE CHAMPIONSHIP – 2019 Under the Auspices of Bridge Federation of India
SUPPLEMENTAL CONDITIONS OF CONTEST For MOHANLAL BHARTIA MEMORIAL BRIDGE CHAMPIONSHIP – 2019 Under the auspices of Bridge Federation of India 1. PREAMBLE The conditions of contest herein set forth are supplemental to the General Conditions and Regulations for the National Tournaments as specified by the Bridge Federation of India, and are specific to the 11th Mohanlal Bhartia Memorial Grand Prix Bridge Championship -2019 to be played at WELCOM HOTEL, Dwarka, New Delhi from 14th March to 17th March 2019. The Championship will be conducted under the technical management of Bridge Federation of India. The schedule of events will be as published in the tournament prospectus. In case of necessity the Tournament Committee in consultation with the Chief Tournament Director may alter/modify the format of any of the events. The tournament will be played in accordance with the laws and provisions laid down by the World Bridge Federation (WBF) and Bridge Federation of India (BFI). The championship will follow the WBF – 2017 Laws of Duplicate Bridge. The event complies as qualifying event for purpose of Indian Open Team Selection Trials 2020 for the World Bridge Games 2020, as per the new Selection Policy of BFI, which will come into effect shortly. 2. CONDITIONS OF ENTRY 2.1 GENERAL RULES FOR ELIGIBILITY TO PARTICIPATE 2.1.1 Participation in this tournament is open to resident bridge players of Indian Nationality. Teams having one or more non-resident Indian bridge player or players of other NBO’s of foreign nationality are also allowed to participate. However the qualification for the Indian Team Selection trial will be available for a team, only if all the players of the team are Indian Nationals holding Indian passports. -
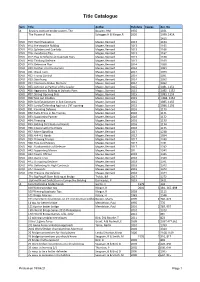
WABC Library by Title April 2021
Title Catalogue Sym Title Author Pub date Copies Acc. No A Beasley contract bridge system, The Beasley, HM 1935 1031 The Power of Pass Schogger,H & Klinger,R 2020 1399, 1414, 1415 DVD #13: Hand Evaluation Magee, Bernard 2013 1164 DVD #14: Pre-emptive Bidding Magee, Bernard 2013 1165 DVD #15: Splinters and Cue-bids Magee, Bernard 2013 1166 DVD #16: Avoidance Play Magee, Bernard 2013 1167 DVD #17: Play & Defence at Duplicate Pairs Magee, Bernard 2013 1168 DVD #18: Thinking Defence Magee, Bernard 2013 1169 DVD #19: Defensive Plan Magee, Bernard 2014 1088 DVD #20: Further into the Auction Magee, Bernard 2014 1089 DVD #21: Weak Twos Magee, Bernard 2014 1090 DVD #22: Trump Control Magee, Bernard 2014 1091 DVD #23: Sacrificing Magee, Bernard 2014 1092 DVD #24: Improving Bridge Memory Magee, Bernard 2014 1093 DVD #25: Defence as Partner of the Leader Magee, Bernard 2015 2 1081, 1151 DVD #26: Aggressive Bidding at Dulicate Pairs Magee, Bernard 2015 2 1082, 1152 DVD #27: Strong Opening Bids Magee, Bernard 2015 2 1083, 1153 DVD #28:Take out Doubles Magee, Bernard 2015 2 1084, 1154 DVD #29: Suit Establisment in Suit Contracts Magee, Bernard 2015 1085, 1155 DVD #30: Landy/Defending Against a 1NT opening Magee, Bernard 2015 2 1086, 1156 DVD #31: Counting Defence Magee, Bernard 2016 1170 DVD #32: Extra Tricks in No-Trumps Magee, Bernard 2016 1171 DVD #33: Supporting Partner Magee, Bernard 2016 1172 DVD #34; Finessing Magee, Bernard 2016 1173 DVD #35: Bidding Distributional Hands Magee, Bernard 2016 1174 DVD #36: Coping with Pre-Empts Magee, Bernard -

Beat Them at the One Level Eastbourne Epic
National Poetry Day Tablet scoring - the rhyme and reason Rosen - beat them at the one level Byrne - Ode to two- suited overcalls Gold - time to jump shift? Eastbourne Epic – winners and pictures English Bridge INSIDE GUIDE © All rights reserved From the Chairman 5 n ENGLISH BRIDGE Major Jump Shifts – David Gold 6 is published every two months by the n Heather’s Hints – Heather Dhondy 8 ENGLISH BRIDGE UNION n Bridge Fiction – David Bird 10 n Broadfields, Bicester Road, Double, Bid or Pass? – Andrew Robson 12 Aylesbury HP19 8AZ n Prize Leads Quiz – Mould’s questions 14 n ( 01296 317200 Fax: 01296 317220 Add one thing – Neil Rosen N 16 [email protected] EW n Web site: www.ebu.co.uk Basic Card Play – Paul Bowyer 18 n ________________ Two-suit overcalls – Michael Byrne 20 n World Bridge Games – David Burn 22 Editor: Lou Hobhouse n Raggett House, Bowdens, Somerset, TA10 0DD Ask Frances – Frances Hinden 24 n Beat Today’s Experts – Bird’s questions 25 ( 07884 946870 n [email protected] Sleuth’s Quiz – Ron Klinger’s questions 27 n ________________ Bridge with a Twist – Simon Cochemé 28 n Editorial Board Pairs vs Teams – Simon Cope 30 n Jeremy Dhondy (Chairman), Bridge Ha Ha & Caption Competition 32 n Barry Capal, Lou Hobhouse, Peter Stockdale Poetry special – Various 34 n ________________ Electronic scoring review – Barry Morrison 36 n Advertising Manager Eastbourne results and pictures 38 n Chris Danby at Danby Advertising EBU News, Eastbourne & Calendar 40 n Fir Trees, Hall Road, Hainford, Ask Gordon – Gordon Rainsford 42 n Norwich NR10 3LX -

15Th WORLD BRIDGE GAMES Wroclaw, Poland • 3Rd – 17Th September 2016
15th WORLD BRIDGE GAMES wroclaw, poland • 3rd – 17th september 2016 Coordinator: Jean-Paul Meyer • Editor: Brent Manley Co-editors: Jos Jacobs, Micke Melander, Ram Soffer, David Stern, Marek Wojcicki Lay out Editor: Monika Kümmel • Photographer: Ron Tacchi Issue NDailyo. 13 Bulletin Friday, 16th September 2016 IT’S ONE ON ONE FOR TITLE HOPEFULS Young bridge players work with some of the 22,000 playing cards strung together in Plac Solny on Thursday. Story on page 4 Eight teams will begin battle today for four championships, and three countries have chances to emerge with two world titles. France (Seniors and Women’s), the Contents Netherlands (Open and Mixed) and USA (Seniors and Women’s) each have two Results . .2 chances for gold. The match between USA and France in the Women’s will be a rematch from last year in Chennai, where the French prevailed. BBO Schedule . .4 The most dramatic of the victories on Thursday was staged by Monaco, who trailed Fun with bridge in Salt Square 4 by 46 IMPs at one point against Spain but rallied in the second half to emerge with Hands and Match Reports . .5 a 6-IMP win. Poland, one of the favorites in the Open, fell behind against a surging Dutch team The Polish Corner . .26 and never recovered, losing by 78. Prize Giving and Closing Ceremony The ceremony will take place on Saturday 17th in the auditorium, beginning Today’s Programme Today’s Programme at 20:00. It will be followed by a reception at the “La Pergola” restaurant. Players who wish to attend the dinner must collect their invitation card at Pairs: Teams: the Hospitality Desk. -

General Conditions of Contest for The
WORLD BRIDGE FEDERATION GENERAL CONDITIONS OF CONTEST For all World Championships and other Tournaments held under the auspices of the World Bridge Federation ©WBF May 2011 Issued by the World Bridge Federation Via della Moscova 46/5, Milan 20121, Italy Contents 1. World Mind Sport Games (WMSG) ................................................................................... 6 2. Definitions for the General Conditions Of Contest ........................................................... 6 2.1 Appeals Form ............................................................................................................ 6 2.2 Approved Recorder ................................................................................................... 6 2.3 Brown Sticker Announcement Form ......................................................................... 7 2.4 Chief Tournament Director and Assistant Chief Tournament Director .................... 7 2.5 Convention Card Desk .............................................................................................. 7 2.6 Director or Tournament Director ............................................................................. 7 2.7 Eligible Zone ............................................................................................................. 7 2.8 Executive Council ...................................................................................................... 7 2.9 Guide to Completion................................................................................................ -

ANNUAL REPORT of the ENGLISH BRIDGE UNION 1 September 2019 - 31 August 2020
AGM Shareholders Meeting 25th November 2020 Agenda Item 5 ANNUAL REPORT OF THE ENGLISH BRIDGE UNION 1 September 2019 - 31 August 2020 The English Bridge Union is the governing body for duplicate bridge in England, representing communities of bridge players at club, county and national level. It is funded by members for members and provides the infrastructure and development of the game in England. It is non-profit making and any and all surplus is invested in our national game. This report provides an insight in to the work that we do to support our clubs, counties and members. We would like to thank all the volunteers that make up our national team - the Directors of the Board and all the members of its committees and the dedicated team of staff led by Chief Executive, Gordon Rainsford. Volunteers are a precious commodity! The five year strategic aims document entitled “Raising our Game 2018-2023” has been overtaken by events and shelved; effort has been put into clarifying the services offered by, and the priorities of, the EBU in a world of online bridge alongside face-to-face bridge, as foundations for the development of a strategy over the next few months for the period up to 2025. The statutory annual report and accounts will be able to be viewed on our website www.ebu.co.uk shortly after the EBU’s Annual General Meeting on 25th November 2020. The Board The Board is made up of eight directors elected by the shareholders, who are the representatives of our counties, and up to two appointed by the Board, renewable annually. -

15Th WORLD BRIDGE GAMES Wroclaw, Poland • 3Rd – 17Th September 2016
15th WORLD BRIDGE GAMES wroclaw, poland • 3rd – 17th september 2016 Coordinator: Jean-Paul Meyer • Editor: Brent Manley Co-editors: Jos Jacobs, Micke Melander, Ram Soffer, David Stern, Marek Wojcicki Lay out Editor: Monika Kümmel • Photographer: Ron Tacchi Issue NDailyo. 6 Bulletin Friday, 9th September 2016 GREAT BRIDGE, FINE DINING IN LYON 2017 The 15th World Bridge Games are not yet halfway through in Wroclaw, but avid bridge players might want to start making plans for the next World Bridge Federation championship — the World Bridge Teams Championship in Lyon, France, next year. Patrick Bogacki The tournament is scheduled for Aug. 12 -26 in France’s third-largest city, one that is well known as the gastronomical centre of the country. At the same tournament, the WBF will conduct the World Open Youth Championships — Aug. 15-24 — and a two-day tournament for players 13 and younger. There will, of course, be the usual events: Bermuda Bowl, Venice Cup, d’Orsi Seniors Trophy and the World Transnational Open Teams, plus side games. At Thursday’s WBF Congress, French Bridge Federation Vice President Patrick Bogacki made a presentation to invite players to enjoy the many amenities of Lyon, from the fine dining — there are more than 1,000 restaurants — to opportunities to visit the vineyards of Beaujolais, Cotes du Rhone and Bourgogne, not to mention the historical city of Avignon, just an hour away by train. Bogacki noted that there are many hotels close to the Contents Convention Center, where the play takes place. The Today’s Programme organizers have negotiated discounted rates for players Schedules and Rankings .