Signals and Slots
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

A Practical UNIX Capability System
A Practical UNIX Capability System Adam Langley <[email protected]> 22nd June 2005 ii Abstract This report seeks to document the development of a capability security system based on a Linux kernel and to follow through the implications of such a system. After defining terms, several other capability systems are discussed and found to be excellent, but to have too high a barrier to entry. This motivates the development of the above system. The capability system decomposes traditionally monolithic applications into a number of communicating actors, each of which is a separate process. Actors may only communicate using the capabilities given to them and so the impact of a vulnerability in a given actor can be reasoned about. This design pattern is demonstrated to be advantageous in terms of security, comprehensibility and mod- ularity and with an acceptable performance penality. From this, following through a few of the further avenues which present themselves is the two hours traffic of our stage. Acknowledgments I would like to thank my supervisor, Dr Kelly, for all the time he has put into cajoling and persuading me that the rest of the world might have a trick or two worth learning. Also, I’d like to thank Bryce Wilcox-O’Hearn for introducing me to capabilities many years ago. Contents 1 Introduction 1 2 Terms 3 2.1 POSIX ‘Capabilities’ . 3 2.2 Password Capabilities . 4 3 Motivations 7 3.1 Ambient Authority . 7 3.2 Confused Deputy . 8 3.3 Pervasive Testing . 8 3.4 Clear Auditing of Vulnerabilities . 9 3.5 Easy Configurability . -

Ultimate++ Forum Probably with These Two Variables You Could Try to Integrate D-BUS
Subject: DBus integration -- need help Posted by jlfranks on Thu, 20 Jul 2017 15:30:07 GMT View Forum Message <> Reply to Message We are trying to add a DBus server to existing large U++ application that runs only on Linux. I've converted from X11 to GTK for Upp project config to be compatible with GIO dbus library. I've created a separate thread for the DBus server and ran into problems with event loop. I've gutted my DBus server code of everything except what is causing an issue. DBus GIO examples use GMainLoop in order for DBus to service asynchronous events. Everything compiles and runs except the main UI is not longer visible. There must be a GTK main loop already running and I've stepped on it with this code. Is there a way for me to obtain a pointer to the UI main loop and use it with my DBus server? How/where can I do that? Code snipped example as follows: ---- code snippet ---- myDBusServerMainThread() { //========================================================== ===== // // Enter main service loop for this thread // while (not needsExit ()) { // colaborate with join() GMainLoop *loop; loop = g_main_loop_new(NULL, FALSE); g_main_loop_run(loop); } } Subject: Re: DBus integration -- need help Posted by Klugier on Thu, 20 Jul 2017 22:30:17 GMT View Forum Message <> Reply to Message Hello, You could try use following methods of Ctrl to obtain gtk & gdk handlers: GdkWindow *gdk() const { return top ? top->window->window : NULL; } GtkWindow *gtk() const { return top ? (GtkWindow *)top->window : NULL; } Page 1 of 3 ---- Generated from Ultimate++ forum Probably with these two variables you could try to integrate D-BUS. -

Fundamentals of Xlib Programming by Examples
Fundamentals of Xlib Programming by Examples by Ross Maloney Contents 1 Introduction 1 1.1 Critic of the available literature . 1 1.2 The Place of the X Protocol . 1 1.3 X Window Programming gotchas . 2 2 Getting started 4 2.1 Basic Xlib programming steps . 5 2.2 Creating a single window . 5 2.2.1 Open connection to the server . 6 2.2.2 Top-level window . 7 2.2.3 Exercises . 10 2.3 Smallest Xlib program to produce a window . 10 2.3.1 Exercises . 10 2.4 A simple but useful X Window program . 11 2.4.1 Exercises . 12 2.5 A moving window . 12 2.5.1 Exercises . 15 2.6 Parts of windows can disappear from view . 16 2.6.1 Testing overlay services available from an X server . 17 2.6.2 Consequences of no server overlay services . 17 2.6.3 Exercises . 23 2.7 Changing a window’s properties . 23 2.8 Content summary . 25 3 Windows and events produce menus 26 3.1 Colour . 26 3.1.1 Exercises . 27 i CONTENTS 3.2 A button to click . 29 3.3 Events . 33 3.3.1 Exercises . 37 3.4 Menus . 37 3.4.1 Text labelled menu buttons . 38 3.4.2 Exercises . 43 3.5 Some events of the mouse . 44 3.6 A mouse behaviour application . 55 3.6.1 Exercises . 58 3.7 Implementing hierarchical menus . 58 3.7.1 Exercises . 67 3.8 Content summary . 67 4 Pixmaps 68 4.1 The pixmap resource . -
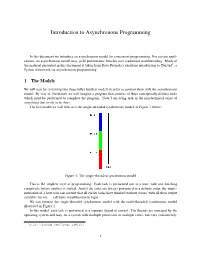
Introduction to Asynchronous Programming
Introduction to Asynchronous Programming In this document we introduce an asynchronous model for concurrent programming. For certain appli- cations, an asynchronous model may yield performance benefits over traditional multithreading. Much of the material presented in this document is taken from Dave Peticola’s excellent introduction to Twisted1, a Python framework for asynchronous programming. 1 The Models We will start by reviewing two (hopefully) familiar models in order to contrast them with the asynchronous model. By way of illustration we will imagine a program that consists of three conceptually distinct tasks which must be performed to complete the program. Note I am using task in the non-technical sense of something that needs to be done. The first model we will look at is the single-threaded synchronous model, in Figure 1 below: Figure 1: The single-threaded synchronous model This is the simplest style of programming. Each task is performed one at a time, with one finishing completely before another is started. And if the tasks are always performed in a definite order, the imple- mentation of a later task can assume that all earlier tasks have finished without errors, with all their output available for use — a definite simplification in logic. We can contrast the single-threaded synchronous model with the multi-threaded synchronous model illustrated in Figure 2. In this model, each task is performed in a separate thread of control. The threads are managed by the operating system and may, on a system with multiple processors or multiple cores, run truly concurrently, 1http://krondo.com/?page_id=1327 1 CS168 Async Programming Figure 2: The threaded model or may be interleaved together on a single processor. -

Qcontext, and Supporting Multiple Event Loop Threads in QEMU
IBM Linux Technology Center QContext, and Supporting Multiple Event Loop Threads in QEMU Michael Roth [email protected] © 2006 IBM Corporation IBM Linux Technology Center QEMU Threading Model Overview . Historically (earlier this year), there were 2 main types of threads in QEMU: . vcpu threads – handle execution of guest code, and emulation of hardware access (pio/mmio) and other trapped instructions . QEMU main loop (iothread) – everything else (mostly) GTK/SDL/VNC UIs QMP/HMP management interfaces Clock updates/timer callbacks for devices device I/O on behalf of vcpus © 2006 IBM Corporation IBM Linux Technology Center QEMU Threading Model Overview . All core qemu code protected by global mutex . vcpu threads in KVM_RUN can run concurrently thanks to address space isolation, but attempt to acquire global mutex immediately after an exit . Iothread requires global mutex whenever it's active © 2006 IBM Corporation IBM Linux Technology Center High contention as threads or I/O scale vcpu 1 vcpu 2 vcpu n iothread . © 2006 IBM Corporation IBM Linux Technology Center QEMU Thread Types . vcpu threads . iothread . virtio-blk-dataplane thread Drives a per-device AioContext via aio_poll Handles event fd callbacks for virtio-blk virtqueue notifications and linux_aio completions Uses port of vhost's vring code, doesn't (currently) use core QEMU code, doesn't require global mutex Will eventually re-use QEMU block layer code © 2006 IBM Corporation IBM Linux Technology Center QEMU Block Layer Features . Multiple image format support . Snapshots . Live Block Copy . Live Block migration . Drive-mirroring . Disk I/O limits . Etc... © 2006 IBM Corporation IBM Linux Technology Center More dataplane in the future . -

The Design and Use of the ACE Reactor an Object-Oriented Framework for Event Demultiplexing
The Design and Use of the ACE Reactor An Object-Oriented Framework for Event Demultiplexing Douglas C. Schmidt and Irfan Pyarali g fschmidt,irfan @cs.wustl.edu Department of Computer Science Washington University, St. Louis 631301 1 Introduction create concrete event handlers by inheriting from the ACE Event Handler base class. This class specifies vir- This article describes the design and implementation of the tual methods that handle various types of events, such as Reactor pattern [1] contained in the ACE framework [2]. The I/O events, timer events, signals, and synchronization events. Reactor pattern handles service requests that are delivered Applications that use the Reactor framework create concrete concurrently to an application by one or more clients. Each event handlers and register them with the ACE Reactor. service of the application is implemented by a separate event Figure 1 shows the key components in the ACE Reactor. handler that contains one or more methods responsible for This figure depicts concrete event handlers that implement processing service-specific requests. In the implementation of the Reactor pattern described in this paper, event handler dispatching is performed REGISTERED 2: accept() by an ACE Reactor.TheACE Reactor combines OBJECTS 5: recv(request) 3: make_handler() the demultiplexing of input and output (I/O) events with 6: process(request) other types of events, such as timers and signals. At Logging Logging Logging Logging Handler Acceptor LEVEL thecoreoftheACE Reactor implementation is a syn- LEVEL Handler Handler chronous event demultiplexer, such as select [3] or APPLICATION APPLICATION Event Event WaitForMultipleObjects [4]. When the demulti- Event Event Handler Handler Handler plexer indicates the occurrence of designated events, the Handler ACE Reactor automatically dispatches the method(s) of 4: handle_input() 1: handle_input() pre-registered event handlers, which perform application- specified services in response to the events. -

Events Vs. Threads COS 316: Principles of Computer System Design
Events vs. Threads COS 316: Principles of Computer System Design Amit Levy & Wyatt Lloyd Two Abstractions for Supporting Concurrency Problem: computationally light applications with large state-space ● How to support graphical interfaces with many possible interactions in each state? ● How to scale servers to handle many simultaneous requests? Corollary: how do we best utilize the CPU in I/O-bound workloads? ● Ideally, CPU should not be a bottleneck for saturating I/O Threads Event Event Event Event Event Wait for event Wait for event Wait for event ... Wait for event Wait for event Wait for event ... Wait for event Wait for event Wait for event ... Threads ● One thread per sequence of related I/O operations ○ E.g. one thread per client TCP connection ● When next I/O isn’t ready, block thread until it is ○ i.e. return to event handler instead of blocking for next event ● State machine is implicit in the sequential program ○ E.g., parse HTTP request, then send DB query, then read file from disk, then send HTTP response ● Only keeping track of relevant next I/O operations ● Any shared state must be synchronized ○ E.g. with locks, channels, etc ● In theory, scale by having a thread per connection Events Event Event Event Event Event Handle event kind A Wait for any event Handle event kind B Events ● Single “event-loop” waits for the next event (of any kind) ● When event arrives, handle it “to completion” ○ i.e. return to event handler instead of blocking for next event ● Event loop keeps track of state machine explicitly ○ How to handle an event depends on which state I’m in ○ E.g. -

Qt Event Loop, Networking and I/O API
Qt event loop, networking and I/O API Thiago Macieira, Qt Core Maintainer San Francisco, November 2013 Who am I? • Open Source developer for 15 years • C++ developer for 13 years • Software Architect at Intel’s Open Source Technology Center (OTC) • Maintainer of two modules in the Qt Project ‒ QtCore and QtDBus • MBA and double degree in Engineering • Previously, led the “Qt Open Governance” project 2 © 2013 Intel Agenda • The event loop • Event loops and threads • Networking and I/O 3 © 2013 Intel The Event Loop Classes relating to the event loop • QAbstractEventDispatcher • QEventLoop • QCoreApplication • QTimer & QBasicTimer • QSocketNotifier & QWinEventNotifer • QThread 5 © 2013 Intel What an event loop does • While !interrupted: • If there are new events, dispatch them • Wait for more events • Event loops are the inner core of modern applications ‒ Headless servers and daemons, GUI applications, etc. ‒ Everything but shell tools and file-processing tools 6 © 2013 Intel Qt event loop feature overview • Receives and translates GUI • Integrates with: events ‒ Generic Unix select(2) ‒ NSEvents (on Mac) ‒ Glib ‒ MSG (on Windows) ‒ Mac’s CFRunLoop ‒ BPS events (on Blackberry) ‒ Windows’s WaitForMultipleObjects ‒ X11 events (using XCB) • Services timers ‒ Wayland events ‒ With coarse timer support ‒ Many others • Polls sockets • Manages the event queue (priority queue) • Polls Windows events • Allows for event filtering • Thread-safe waking up 7 © 2013 Intel QAbstractEventDispatcher • Each thread has one instance • Only of interest if you’re -

Semantics of Asynchronous Javascript
Semantics of Asynchronous JavaScript Matthew C. Loring Mark Marron Daan Leijen Google Inc, USA Microsoft Research, USA Microsoft Research, USA [email protected] [email protected] [email protected] Abstract asynchronous API’s exposed by Node.js and for tools that The Node.js runtime has become a major platform for de- can help develop [15], debug [4], or monitor [10, 24] the velopers building cloud, mobile, or IoT applications using asynchronous behavior of their applications. JavaScript. Since the JavaScript language is single threaded, 1.1 Semantics of Node Event Queues Node.js programs must make use of asynchronous callbacks and event loops managed by the runtime to ensure appli- A major challenge for research and tooling development for cations remain responsive. While conceptually simple, this Node.js is the lack of a formal specification of the Node.js programming model contains numerous subtleties and be- asynchronous execution model. This execution model in- haviors that are defined implicitly by the current Node.js volves multiple event queues, some implemented in the na- implementation. This paper presents the first comprehensive tive C++ runtime, others in the Node.js standard library formalization of the Node.js asynchronous execution model API bindings, and still others defined by the JavaScript ES6 and defines a high-level notion of async-contexts to formalize promise language feature. These queues have different rules fundamental relationships between asynchronous events in regarding when they are processed, how processing is inter- an application. These formalizations provide a foundation leaved, and how/where new events are added to each queue. for the construction of static or dynamic program analysis These subtleties are often the difference between a respon- tools, support the exploration of alternative Node.js event sive and scalable application and one that exhibits a critical loop implementations, and provide a high-level conceptual failure. -

Enhancing Quality of Service Metrics for High Fan-In Node.Js Applications by Optimising the Network Stack
DEGREE PROJECT, IN COMPUTER SCIENCE , SECOND LEVEL LAUSANNE, SWITZERLAND 2015 Enhancing Quality of Service Metrics for High Fan-In Node.js Applications by Optimising the Network Stack LEVERAGING IX: THE DATAPLANE OPERATING SYSTEM FREDRIK PETER LILKAER KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF COMPUTER SCIENCE AND COMMUNICATION (CSC) Enhancing Quality of Service Metrics for High Fan-in Node.js Applications by Optimising the Network Stack -Leveraging IX: The Dataplane Operating System FREDRIK PETER LILKAER DD221X, Master’s Thesis in Computer Science (30 ECTS credits) Degree Progr. in Computer Science and Engineering 300 credits Master Programme in Computer Science 120 credits Royal Institute of Technology year 2015 Supervisor at EPFL was Edouard Bugnion Supervisor at CSC wa s Carl-Henrik Ek Examiner wa s Johan Håstad Presented: 2015-10-01 Royal Institute of Technology School of Computer Science and Communication KTH CSC SE-100 44 Stockholm, Sweden URL: www.kth.se/csc Abstract This thesis investigates the feasibility of porting Node.js, a JavaScript web application framework and server, to IX, a data- plane operating system specifically developed to meet the needs of high performance microsecond-computing type of applications in a datacentre setting. We show that porting requires exten- sions to the IX kernel to support UDS polling, which we imple- ment. We develop a distributed load generator to benchmark the framework. The results show that running Node.js on IX improves throughput by up to 20.6%, latency by up to 5.23×, and tail latency by up to 5.68× compared to a Linux baseline. We show how server side request level reordering affect the la- tency distribution, predominantly in cases where the server is load saturated. -
Performance Without the Event Loop
Performance without the event loop David Cheney Hello! My name is David, I've come all the way from Australia to talk to you today about Go, the programming language. I'm extremely excited to be here. So thank you to Leo, Ed, Elena, and the rest of the organisers for allowing me to be here today, it’s truely a humbling moment for me. I want to ask you two questions But, before we begin, I want to ask you the audience, two questions Are computers getting faster? The first question is, are computers getting faster? Depending on who you talk to people will either say “no, computers stopped getting faster some time ago”, or they may say “yes, of course computers are still getting faster”. So, can I ask you to raise your hand if you believe that in general that computers are still getting faster, compared to a year, or maybe even five years ago. Ok, that's a promising number. Do we need to rewrite our programs to make them faster? ok, so the second question Can I ask, if you have your hand raised, do you think that as a programmer, you can take advantage of the factors that continue to make computer faster without rewriting your programs. In other words, will the programs that were written in the past continue to get faster for free? Before we talk about fast code we need to talk about the hardware that will execute this code The title of this talk is “performance without the event loop”, but before we can talk about writing high performance code, we need to talk about the hardware that will execute this code. -

Event-Based Concurrency (Advanced)
33 Event-based Concurrency (Advanced) Thus far, we’ve written about concurrency as if the only way to build concurrent applications is to use threads. Like many things in life, this is not completely true. Specifically, a different style of concurrent pro- gramming is often used in both GUI-based applications [O96] as well as some types of internet servers [PDZ99]. This style, known as event-based concurrency, has become popular in some modern systems, including server-side frameworks such as node.js [N13], but its roots are found in C/UNIX systems that we’ll discuss below. The problem that event-based concurrency addresses is two-fold. The first is that managing concurrency correctly in multi-threaded applica- tions can be challenging; as we’ve discussed, missing locks, deadlock, and other nasty problems can arise. The second is that in a multi-threaded application, the developer has little or no control over what is scheduled at a given moment in time; rather, the programmer simply creates threads and then hopes that the underlying OS schedules them in a reasonable manner across available CPUs. Given the difficulty of building a general- purpose scheduler that works well in all cases for all workloads, some- times the OS will schedule work in a manner that is less than optimal. And thus, we have ... THE CRUX: HOW TO BUILD CONCURRENT SERVERS WITHOUT THREADS How can we build a concurrent server without using threads, and thus retain control over concurrency as well as avoid some of the problems that seem to plague multi-threaded applications? 33.1 The Basic Idea: An Event Loop The basic approach we’ll use, as stated above, is called event-based concurrency.