A Bilingual (Gurmukhi-Roman) Online Handwriting Identification and Recognition System
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
LAST FIRST EXP Updated As of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If Athlete's Name Is Not on List Acevedo Jr
LAST FIRST EXP Updated as of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If athlete's name is not on list Acevedo Jr. Ma 2/27/2020 they will need a medical packet Adams Br 1/17/2021 completed before they can Aguilar Br 12/6/2020 participate in any event. Aguilar-Soto Al 8/7/2020 Alka Ja 9/27/2021 Allgire Ra 6/20/2022 Almeida Br 12/27/2021 Amason Ba 5/19/2022 Amy De 11/8/2019 Anderson Ca 4/17/2021 Anderson Mi 5/1/2021 Ardizone Ga 7/16/2021 Arellano Da 2/8/2021 Arevalo Ju 12/2/2020 Argueta-Reyes Al 3/19/2022 Arnett Be 9/4/2021 Autry Ja 6/24/2021 Badeaux Ra 7/9/2021 Balinski Lu 12/10/2020 Barham Ev 12/6/2019 Barnes Ca 7/16/2020 Battle Is 9/10/2021 Bergen Co 10/11/2021 Bermudez Da 10/16/2020 Biggs Al 2/28/2020 Blanchard-Perez Ke 12/4/2020 Bland Ma 6/3/2020 Blethen An 2/1/2021 Blood Na 11/7/2020 Blue Am 10/10/2021 Bontempo Lo 2/12/2021 Bowman Sk 2/26/2022 Boyd Ka 5/9/2021 Boyd Ty 11/29/2021 Boyzo Mi 8/8/2020 Brach Sa 3/7/2021 Brassard Ce 9/24/2021 Braunstein Ja 10/24/2021 Bright Ca 9/3/2021 Brookins Tr 3/4/2022 Brooks Ju 1/24/2020 Brooks Fa 9/23/2021 Brooks Mc 8/8/2022 Brown Lu 11/25/2021 Browne Em 10/9/2020 Brunson Jo 7/16/2021 Buchanan Tr 6/11/2020 Bullerdick Mi 8/2/2021 Bumpus Ha 1/31/2021 LAST FIRST EXP Updated as of 8/10/19 Burch Co 11/7/2020 Burch Ma 9/9/2021 Butler Ga 5/14/2022 Byers Je 6/14/2021 Cain Me 6/20/2021 Cao Tr 11/19/2020 Carlson Be 5/29/2021 Cerda Da 3/9/2021 Ceruto Ri 2/14/2022 Chang Ia 2/19/2021 Channapati Di 10/31/2021 Chao Et 8/20/2021 Chase Em 8/26/2020 Chavez Fr 6/13/2020 Chavez Vi 11/14/2021 Chidambaram Ga 10/13/2019 -

Review of Research
Review Of ReseaRch impact factOR : 5.7631(Uif) UGc appROved JOURnal nO. 48514 issn: 2249-894X vOlUme - 8 | issUe - 7 | apRil - 2019 __________________________________________________________________________________________________________________________ AN ANALYSIS OF CURRENT TRENDS FOR SANSKRIT AS A COMPUTER PROGRAMMING LANGUAGE Manish Tiwari1 and S. Snehlata2 1Department of Computer Science and Application, St. Aloysius College, Jabalpur. 2Student, Deparment of Computer Science and Application, St. Aloysius College, Jabalpur. ABSTRACT : Sanskrit is said to be one of the systematic language with few exception and clear rules discretion.The discussion is continued from last thirtythat language could be one of best option for computers.Sanskrit is logical and clear about its grammatical and phonetically laws, which are not amended from thousands of years. Entire Sanskrit grammar is based on only fourteen sutras called Maheshwar (Siva) sutra, Trimuni (Panini, Katyayan and Patanjali) are responsible for creation,explainable and exploration of these grammar laws.Computer as machine,requires such language to perform better and faster with less programming.Sanskrit can play important role make computer programming language flexible, logical and compact. This paper is focused on analysis of current status of research done on Sanskrit as a programming languagefor .These will the help us to knowopportunity, scope and challenges. KEYWORDS : Artificial intelligence, Natural language processing, Sanskrit, Computer, Vibhakti, Programming language. -

The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes
Portland State University PDXScholar Mathematics and Statistics Faculty Fariborz Maseeh Department of Mathematics Publications and Presentations and Statistics 3-2018 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hu Sun University of Macau Christine Chambris Université de Cergy-Pontoise Judy Sayers Stockholm University Man Keung Siu University of Hong Kong Jason Cooper Weizmann Institute of Science SeeFollow next this page and for additional additional works authors at: https:/ /pdxscholar.library.pdx.edu/mth_fac Part of the Science and Mathematics Education Commons Let us know how access to this document benefits ou.y Citation Details Sun X.H. et al. (2018) The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes. In: Bartolini Bussi M., Sun X. (eds) Building the Foundation: Whole Numbers in the Primary Grades. New ICMI Study Series. Springer, Cham This Book Chapter is brought to you for free and open access. It has been accepted for inclusion in Mathematics and Statistics Faculty Publications and Presentations by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. Authors Xu Hu Sun, Christine Chambris, Judy Sayers, Man Keung Siu, Jason Cooper, Jean-Luc Dorier, Sarah Inés González de Lora Sued, Eva Thanheiser, Nadia Azrou, Lynn McGarvey, Catherine Houdement, and Lisser Rye Ejersbo This book chapter is available at PDXScholar: https://pdxscholar.library.pdx.edu/mth_fac/253 Chapter 5 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hua Sun , Christine Chambris Judy Sayers, Man Keung Siu, Jason Cooper , Jean-Luc Dorier , Sarah Inés González de Lora Sued , Eva Thanheiser , Nadia Azrou , Lynn McGarvey , Catherine Houdement , and Lisser Rye Ejersbo 5.1 Introduction Mathematics learning and teaching are deeply embedded in history, language and culture (e.g. -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ]. -

South Asian Art a Resource for Classroom Teachers
South Asian Art A Resource for Classroom Teachers South Asian Art A Resource for Classroom Teachers Contents 2 Introduction 3 Acknowledgments 4 Map of South Asia 6 Religions of South Asia 8 Connections to Educational Standards Works of Art Hinduism 10 The Sun God (Surya, Sun God) 12 Dancing Ganesha 14 The Gods Sing and Dance for Shiva and Parvati 16 The Monkeys and Bears Build a Bridge to Lanka 18 Krishna Lifts Mount Govardhana Jainism 20 Harinegameshin Transfers Mahavira’s Embryo 22 Jina (Jain Savior-Saint) Seated in Meditation Islam 24 Qasam al-Abbas Arrives from Mecca and Crushes Tahmasp with a Mace 26 Prince Manohar Receives a Magic Ring from a Hermit Buddhism 28 Avalokiteshvara, Bodhisattva of Compassion 30 Vajradhara (the source of all teachings on how to achieve enlightenment) CONTENTS Introduction The Philadelphia Museum of Art is home to one of the most important collections of South Asian and Himalayan art in the Western Hemisphere. The collection includes sculptures, paintings, textiles, architecture, and decorative arts. It spans over two thousand years and encompasses an area of the world that today includes multiple nations and nearly a third of the planet’s population. This vast region has produced thousands of civilizations, birthed major religious traditions, and provided fundamental innovations in the arts and sciences. This teaching resource highlights eleven works of art that reflect the diverse cultures and religions of South Asia and the extraordinary beauty and variety of artworks produced in the region over the centuries. We hope that you enjoy exploring these works of art with your students, looking closely together, and talking about responses to what you see. -

Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Kannada LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-kannada-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: kannada-test-labels-06mar19-en.txt 2. Script for which the LGR is Proposed ISO 15924 Code: Knda ISO 15924 N°: 345 ISO 15924 English Name: Kannada Latin transliteration of the native script name: Native name of the script: ಕನ#ಡ Maximal Starting Repertoire (MSR) version: MSR-4 Some languages using the script and their ISO 639-3 codes: Kannada (kan), Tulu (tcy), Beary, Konkani (kok), Havyaka, Kodava (kfa) 1 Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) 3. Background on Script and Principal Languages Using It 3.1 Kannada language Kannada is one of the scheduled languages of India. It is spoken predominantly by the people of Karnataka State of India. It is one of the major languages among the Dravidian languages. Kannada is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad. -

Implementation of Sanskrit Linguistics in Artificial Intelligence Programming
ISSN: 2456 - 3935 International Journal of Advances in Computer and Electronics Engineering Volume: 02 Issue: 02, February 2017, pp. 17 – 27 Implementation of Sanskrit Linguistics in Artificial Intelligence Programming Neetesh Vashishtha UG Scholar, Department of Computer Science Engineering, Jaipur Engineering College and Research Center, India Email: [email protected] Abstract: This research paper is directed towards examining the extent to which the Sanskrit language can be implemented in programming, principally in the domain of Artificial Intelligence. This paper can be divided into three major sections. The first section explains the significance of Sanskrit over other languages. The second section explores that if it’s actually beneficial to program in Sanskrit rather than English. The third section includes coding of two identical AI programs, one made to interact in English and the other in Sanskrit. They are analyzed separately and then compared collectively to seek for the advantages the Sanskrit linguistics offer in Artificial Intelligence programming. We then conclude that Sanskrit, when used for communicating with the AI machines, is remarkable with an astounding versatility and brilliant learning abilities for an AI. The Sanskrit being strict and bundled, results in a compact and unambiguous form of conversations with the AI programs. Keyword: Artificial Intelligence; Deep Learning; Java; Language linguistics; Machine Learning; Sanskrit 1. INTRODUCTION The primary objective of this paper is to present The number of possible incorrect sentences are- the possibility of adopting Sanskrit as a means of 5! – 1 = 120-1 communication with the artificial intelligence. The = 119 permutations paper also aims to extend this proposal with pro- gramming the AI in Sanskrit Linguistics. -
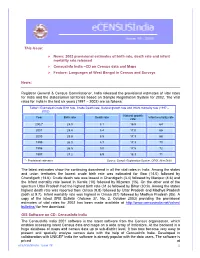
Census of India Website at Censusinfo.Html
This Issue: News: 2002 provisional estimates of birth rate, death rate and infant mortality rate released CensusInfo India –CD on Census data and Maps Feature: Languages of West Bengal in Census and Surveys News: Registrar General & Census Commissioner, India released the provisional estimates of vital rates for India and the states/union territories based on Sample Registration System for 2002. The vital rates for India in the last six years (1997 – 2002) are as follows: Table1: Estimated Crude Birth rate, Crude Death rate, Natural growth rate and Infant mortality rate (1997 – 2002) Natural growth Year Birth rate Death rate Infant mortality rate rate 2002* 25.0 8.1 16.9 64 2001 25.4 8.4 17.0 66 2000 25.8 8.5 17.3 68 1999 26.0 8.7 17.3 70 1998 26.5 9.0 17.5 72 1997 27.2 8.9 18.3 71 * - Provisional estimates Source: Sample Registration System, ORGI, New Delhi The latest estimates show the continuing downtrend in all the vital rates in India. Among the states and union territories the lowest crude birth rate was estimated for Goa (14.0) followed by Chandigarh (14.6). Crude death rate was lowest in Chandigarh (3.4) followed by Manipur (4.6) and the Infant mortality rate lowest in Kerala (10) followed by Mizoram (15). On the other end of the spectrum Uttar Pradesh had the highest birth rate (31.6) followed by Bihar (30.9). Among the states highest death rate was reported from Orissa (9.8) followed by Uttar Pradesh and Madhya Pradesh (both at 9.7). -

Edatlas: an Efficient Disambiguation Algorithm for Texting in Languages with Abugida Scripts
edATLAS: An Efficient Disambiguation Algorithm for Texting in Languages with Abugida Scripts Sourav Ghosh, Sourabh Vasant Gothe, Chandramouli Sanchi, Barath Raj Kandur Raja Samsung R&D Institute Bangalore, Karnataka, India 560037 Email: { sourav.ghosh, sourab.gothe, cm.sanchi, barathraj.kr }@samsung.com Abstract—Abugida refers to a phonogram writing system where each syllable is represented using a single consonant or typographic ligature, along with a default vowel or optional diacritic(s) to denote other vowels. However, texting in these languages has some unique challenges in spite of the advent of devices with soft keyboard supporting custom key layouts. The number of characters in these languages is large enough to require characters to be spread over multiple views in the layout. Having to switch between views many times to type a single word hinders the natural thought process. This prevents popular usage of native keyboard layouts. On the other hand, supporting romanized scripts (native words transcribed using Latin characters) with language model based suggestions is also set back by the lack of uniform romanization rules. (a) (b) To this end, we propose a disambiguation algorithm and showcase its usefulness in two novel mutually non-exclusive Fig. 1: Application of edATLAS in (a) ambiguous input for input methods for languages natively using the abugida writing abugida scripts, and (b) word variants for romanized scripts system: (a) disambiguation of ambiguous input for abugida scripts, and (b) disambiguation of word variants in romanized scripts. We benchmark these approaches using public datasets, and show an improvement in typing speed by 19:49%, 25:13%, who prefer transliteration layouts [4] by a very large margin, 14:89 and %, in Hindi, Bengali, and Thai, respectively, using as seen in Figure 2. -

Conditioning Factors for Fertility Decline in Bengal: History, Language Identity, and Openness to Innovations
Conditioning Factors for Fertility Decline in Bengal: History, Language Identity, and Openness to Innovations ALAKA MALWADE BASU SAJEDA AMIN DECLINES IN FERTILITY in the contemporary world tend to be explained in contemporary terms. Immediate causes are sought and generally center around issues of changing demand and supply. More specifically, the pro- ponents of the importance of changing demand stress the changing struc- tural conditions that alter the costs and benefits of children, while the “sup- ply-siders” give central importance to family planning programs which purportedly increase awareness and practice of contraception so that birth control becomes both desirable and possible. In recent years, these explanations have become enriched by another class of explanations that focus on the spread of positive attitudes toward controlled fertility and toward contraception. These attitudes may arise through means that are only tangentially related to changing economic en- vironments or to government population policy. In particular, they may develop through a process of diffusion of ideas from individuals already posi- tively inclined in this direction. Montgomery and Casterline (1998) provide a clear definition of such diffusion of attitudes in the context of social change: they refer to diffusion as “a process in which individuals’ decisions…are affected by the knowledge, attitudes, and behavior of others with whom they come in contact” (p. 39). These “others” may be of different kinds—peer groups, elites, family, friends, and so on—and the contact may occur in a vari- ety of ways. Montgomery and Casterline (1998) postulate three principal mechanisms for these “social effects”: social learning, social influence, and social norms. -

Sanskrit As a Programming Language: Possibilities & Difficulties Vipin Mishra
IJISET - International Journal of Innovative Science, Engineering & Technology, Vol. 2 Issue 4, April 2015. www.ijiset.com ISSN 2348 – 7968 Sanskrit as a Programming Language: Possibilities & Difficulties Vipin Mishra Abstract In the past twenty years, much time, effort, and money has been expended on designing an unambiguous representation of natural languages to make them accessible to computer processing. These efforts have centered on creating schemata designed to parallel logical relations with relations expressed by the syntax and semantics of natural languages, which are clearly cumbersome and ambiguous in their function as vehicles for the transmission of logical data. Understandably, there is a widespread belief that natural languages are unsuitable for the transmission of many ideas that artificial languages can render with great precision and mathematical rigor. But this dichotomy, which has served as a premise underlying much work in the areas of linguistics and artificial intelligence, is a false one. There is at least one language, Sanskrit, which for the duration of almost 1,000 years was a living spoken language with a considerable literature of its own. Besides works of literary value, there was a long philosophical and grammatical tradition that has continued to exist with undiminished vigor until the present century. Among the accomplishments of the grammarians can be reckoned a method for paraphrasing Sanskrit in a manner that is identical not only in essence but in form with current work in Artificial Intelligence. This article demonstrates that a natural language can serve as an artificial language also, and that much work in AI has been reinventing a wheel millennia old. -

Proposal to Encode 0C34 TELUGU LETTER LLLA
Proposal to encode 0C34 TELUGU LETTER LLLA Shriramana Sharma, Suresh Kolichala, Nagarjuna Venna, Vinodh Rajan jamadagni, suresh.kolichala, vnagarjuna and vinodh.vinodh: *-at-gmail.com 2012Jan-17 §1. Character to be encoded 0C34 TELUGU LETTER LLLA §2. Background LLLA is the Unicode term for the native form in South Indian scripts of the voiced retroflex approximant. It is an ill-informed notion that it is limited or unique to one particular language or script. Such written forms are already known to exist in Tamil, Malayalam and Kannada and characters for the same are already encoded in Unicode. Evidence for the native presence of corresponding written forms of LLLA in other South Indian scripts, which may or may not be identical to characters already encoded, is forthcoming. This document provides evidence for Telugu LLLA identical to Kannada LLLA and requests its encoding. Similar evidence is to be expected for other South Indian scripts in future as well. §3. Attestation Currently the Telugu script does not use LLLA. However historic usage before the 10th century is undeniably attested. When the literary Telugu language was effectively standardized by the time of the Mahābhārata of Nannayya in the 11th century, this letter had disappeared from use. It is clear that this disappeared from the Telugu language long before it disappeared from Kannada. However, it was definitely used as part of the Telugu script and language and is considered a Telugu character by Telugu epigraphist scholars. Even though the pre-10th-century Telugu writing had much (more) in common with the Kannada writing of those days and is perhaps better analysed as a single proto-Telugu Kannada script, and hence the older written form would not be a part of the modern Telugu 1 script currently encoded in the block 0C00-0C7F, the modern written form used when transcribing the older form is most definitely a part of the modern Telugu script and hence should be encoded as part of it.