Run-Length Encoding (RLE)
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Exploring the .BMP File Format
Exploring the .BMP File Format Don Lancaster Synergetics, Box 809, Thatcher, AZ 85552 copyright c2003 as GuruGram #14 http://www.tinaja.com [email protected] (928) 428-4073 The .BMP image standard is used by Windows and elsewhere to represent graphics images in any of several different display and compression options. The .BMP advantages are that each pixel is usually independently available for any alteration or modification. And that repeated use does not normally degrade the image. Because lossy compression is not used. Its main disadvantage is that file sizes are usually horrendous compared to JPEG, fractal, GIF, or other lossy compression schemes. A comparison of popular image standards can be found here. I’ve long been using the .BMP format for my eBay and my other phototography, scanning, and post processing. I firmly believe that… All photography, scanning, and all image post-processing should always be done using .BMP or a similar non-lossy format. Only after all post-processing is complete should JPEG or another compressed distribution format be chosen. Some current examples of my .BMP work now do include the IMAGIMAG.PDF post-processing tutorial, the Bitmap Typewriterthat generates fully anti-aliased small fonts, the Aerial Photo Combiner, and similar utilities and tutorials found on our Fonts & Images, PostScript, and on our Acrobat library pages. A few projects of current interest involving .BMP files include true view camera swings and tilts for a digital camera, distortion correction, dodging & burning, preventing white punchthrough on knockouts, and emphasis vignetting. Mainly applied to uncompressed RGBX 24-bit color .BMP files. -

Implementation of LSB Steganography and Its Evaluation for Various File Formats (LSB, JSTEG)
International Journal of Engineering Research & Technology (IJERT) ISSN: 2278-0181 Vol. 2 Issue 6, June - 2013 Implementation of LSB Steganography and its Evaluation for Various File Formats (LSB, JSTEG) Vivek Kumar, Sandesh Kumar, Lavalee Singh, Prateek Yadav MANGALAYATAN UNIVERSITY1, 2,3,4 ALIGARH Keywords: Steganography, Least ABSTRACT: Significant Bit (LSB), GIF, PNG, BMP. Steganography is derived from the Greek word steganos which literally means 1. INTRODUCTION “Covered” and graphy means “Writing”, In the current trends of the world, the i.e. covered writing. Steganography refers technologies have advanced so much that to the science of “invisible” Most of the individuals prefer using the communication. For hiding secret internet as the primary medium to transfer information in various file formats, there data from one end to another across the exists a large variety of steganographic IJERTIJERTworld. There are many possible ways to techniques some are more complex than transmit data using the internet: via e-mails, others and all of them have respective chats, etc. The data transition is made very strong and weak points. The Least simple, fast and accurate using the internet. Significant Bit (LSB) embedding However, one of the main problems with technique suggests that data can be sending data over the internet is the security hidden in the least significant bits of the threat it poses i.e. the personal or cover image and the human eye would be confidential data can be stolen or hacked in unable to notice the hidden image in the many ways. Therefore it becomes very cover file. This technique can be used for important to take data security into hiding images in 24-Bit, 8- Bit, Gray scale consideration, as it is one of the most format. -

Certified Digital Designer Professional Certification Examination Review
Digital Imaging & Editing and Digital & General Photography Certified Digital Designer Professional Certification Examination Review Within this presentation – We will use specific names and terminologies. These will be related to specific products, software, brands and trade names. ADDA does not endorse any specific software or manufacturer. It is the sole decision of the individual to choose and purchase based on their personal preference and financial capabilities. the Examination Examination Contain at Total 325 Questions 200 Questions in Digital Image Creation and Editing Image Editing is applicable to all Areas related to Digital Graphics 125 Question in Photography Knowledge and History Photography is applicable to General Principles of Photography Does not cover Photography as a General Arts Program Examination is based on entry level intermediate employment knowledge Certain Processes may be omitted that are required to achieve an end result ADDA Professional Certification Series – Digital Imaging & Editing the Examination Knowledge of Graphic and Photography Acronyms Knowledge of Graphic Program Tool Symbols Some Knowledge of Photography Lighting Ability to do some basic Geometric Calculations Basic Knowledge of Graphic History & Theory Basic Knowledge of Digital & Standard Film Cameras Basic Knowledge of Camera Lens and Operation General Knowledge of Computer Operation Some Common Sense ADDA Professional Certification Series – Digital Imaging & Editing This is the Comprehensive Digital Imaging & Editing Certified Digital Designer Professional Certification Examination Review Within this presentation – We will use specific names and terminologies. These will be related to specific products, software, brands and trade names. ADDA does not endorse any specific software or manufacturer. It is the sole decision of the individual to choose and purchase based on their personal preference and financial capabilities. -

What Images File Formats Do We Support?
What images file formats do we support? Written by Administrator - JPEG/JFIF JPEG (Joint Photographic Experts Group) is a compression method; JPEG-compressed images are usually stored in the JFIF (JPEG File Interchange Format) file format. JPEG compression is (in most cases) lossy compression . The JPEG/JFIF filename extension in DOS is JPG (other operating systems may use JPEG ). Nearly every digital camera can save images in the JPEG/JFIF format, which supports 8 bits per color (red, green, blue) for a 24-bit total, producing relatively small files. When not too great, the compression does not noticeably detract from the image's quality, but JPEG files suffer generational degradation when repeatedly edited and saved. Photographic images may be better stored in a lossless non-JPEG format if they will be re-edited, or if small "artifacts" (blemishes caused by the JPEG's compression algorithm) are unacceptable. The JPEG/JFIF format also is used as the image compression algorithm in many Adobe PDF files. Exif The Exif ( Exchangeable image file format ) format is a file standard similar to the JFIF format with TIFF extensions; it is incorporated in the JPEG-writing software used in most cameras. Its purpose is to record and to standardize the exchange of images with image metadata between digital cameras and editing and viewing software. The metadata are recorded for individual images and include such things as camera settings, time and date, shutter speed, exposure, image size, compression, name of camera, color information, etc. When images are viewed or edited by image editing software, all of this image information can be displayed. -

XL Vu+™ Videoprobe® Operating Manual
GE Measurement & Control Remote Visual Inspection XL Vu+™ VideoProbe® Operating Manual XLVUCMAN Rev. A July 2013 XL Vu+™ VideoProbe® Video Borescope Operating Manual XLVUCMAN Rev. A July 2013 ge-mcs.com ©2013 General Electric Company. All rights reserved. Technical content subject to change without notice. [no content intended for this page] ii Contents Chapter 1. Introduction 1.1 About this Manual . 1 1.2 Standard XL Vu+ System . 1 1.3 Optional Accessories . 2 1.4 Optional Software . 2 1.5 Indicators and Connectors . 3 1.6 Button Controls . 5 Chapter 2. Safety Information 2.1 Symbols and Terms . 7 2.2 General Warnings . 7 2.3 General Cautions . 8 2.4 Battery Warnings . 9 2.5 Symboles et termes employés . 10 2.6 Avertissements généraux . 10 2.7 Mentions générales « Attention » . 11 2.8 Avertissements liés à la batterie. 12 Chapter 3. Getting Started 3.1 System Removal . 13 3.2 System Power ON . 14 3.3 System Power OFF . 14 3.4 System Storage . 15 3.5 Mounting Accessories . 16 3.6 The Battery . 17 3.6.1 Installing the Battery . 17 3.6.2 Removing the Battery . 17 3.7 Battery Charge Level. 18 3.8 Charging the Battery . 18 3.9 Keyboard Support . 19 3.10 Saving Images and Video . 20 3.10.1 Still Images . 20 3.10.2 Video . 20 XL Vu+™ VideoProbe® Operating Manual iii Contents 3.11 Optical Tips . 21 3.11.1 Optical Tip Removal. 21 3.11.2 Optical Tip Installation . 21 3.12 Proper Use of the Tip Tool (3.9 mm only) . -

Various Raster and Vector Image File Formats
ISSN (Online) 2278-1021 ISSN (Print) 2319-5940 International Journal of Advanced Research in Computer and Communication Engineering Vol. 4, Issue 3, March 2015 Various Raster and Vector Image File Formats Sakshica1, Dr. Kusum Gupta2 Banasthali Vidyapith, Jaipur campus (Jaipur)1,2 Abstract: Image File Format is one of the standardized ways of storing digital images, with a large number of image file formats available it would be very difficult and challenging for the user to select appropriate image format for storing the images. Choosing the proper image file format according to the demand of the project or according to a specific parameter is of vital importance. Therefore, in this paper we provide a brief review on most common and different image file formats in order to ease the user to choose appropriate file formats while working with files. Keywords: Graphics Interchange Format (GIF), Joint Photographic Expert Group(JPEG), Portable Network Graphics(PNG), Tagged Image File Format(TIFF), Encapsulated PostScript (ESP), Portable Document Format (PDF), Adobe Illustrator (AI), Drawing eXchange Format (DXF). I. INTRODUCTION Images are an important part of today's digital world. File A. Resolution formats are essential when it comes to compatibility and Raster graphics depend upon having a resolution, which is storing images. An image file format is a standard way to counted in .dpi (dots per inch).The lower the resolution the organize and store image data. It defines how the data is smaller the file size [6]. arranged and the type of compression (if any) to be used. Low-resolution raster graphics would normally be set to There are several dozens of different image file formats 72 dpi and are used very often for web sites and presenta- [1]. -

Computer Labs: the BMP File Format
Computer Labs: The BMP file format 2o MIEIC Pedro F. Souto ([email protected]) November 26, 2018 Digital Image File Formats XPM as we have defined has some limitations I Good only for indexed modes I It is not standard I Need to manually edit the XPMs bmp has been used by many LCOM projects in recent years I It is relatively simple, and you can use some libraries available on the Web to load bmp files I It is supported by some well know graphics editors, e.g. GIMP Example: Using C Arrays to Store XPMs static char *pic1[] = { "32 13 4", /* number of columns and rows, in pixels, and colors */ ". 0", /* ’.’ denotes color value 0 */ "x 2", /* ’x’ denotes color value 2 */ "o 14", /* .. and so on */ "+ 4", "................................", /* the map */ "..............xxx...............", "............xxxxxxx.............", ".........xxxxxx+xxxxxx..........", "......xxxxxxx+++++xxxxxxx.......", "....xxxxxxx+++++++++xxxxxxx.....", "....xxxxxxx+++++++++xxxxxxx.....", "......xxxxxxx+++++xxxxxxx.......", ".........xxxxxx+xxxxxx..........", "..........ooxxxxxxxoo...........", ".......ooo...........ooo........", ".....ooo...............ooo......", "...ooo...................ooo...." }; Question How many elements does an XPM array have? The BMP File Structure Bitmap File Header File metadata: Bitmap Info Header/DIB Header Pixmap and pixel format metadata I There are several versions, the most recent one is v5 Color Table/RGB Quad Array i.e. color palette I Used mainly for indexed color representations Pixel Array the pixmap Other structures with extra information or for padding are optional. Image with the BMP file fomat , via Wikipedia Bitmap File Header typedef struct tagBITMAPFILEHEADER { WORD bfType; // this is 2 bytes DWORD bfSize; // this is 4 bytes WORD bfReserved1; WORD bfReserved2; DWORD bfOffBits; }; Type Must be ’B”M’, in ASCII I But there other format versions Size Size of file OffBits Pixmap array offset (in file) Bitmap Info Header I Contains metadata about: Pixmap e.g. -
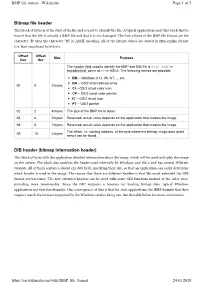
Bitmap File Header DIB Header (Bitmap Information Header)
BMP file format - Wikipedia Page 1 of 3 Bitmap file header This block of bytes is at the start of the file and is used to identify the file. A typical application reads this block first to ensure that the file is actually a BMP file and that it is not damaged. The first 2 bytes of the BMP file format are the character "B" then the character "M" in ASCII encoding. All of the integer values are stored in little-endian format (i.e. least-significant byte first). Offset Offset Size Purpose hex dec The header field used to identify the BMP and DIB file is 0x42 0x4D in hexadecimal, same as BM in ASCII. The following entries are possible: ◾ BM – Windows 3.1x, 95, NT, ... etc. ◾ BA – OS/2 struct bitmap array 00 0 2 bytes ◾ CI – OS/2 struct color icon ◾ CP – OS/2 const color pointer ◾ IC – OS/2 struct icon ◾ PT – OS/2 pointer 02 2 4 bytes The size of the BMP file in bytes 06 6 2 bytes Reserved; actual value depends on the application that creates the image 08 8 2 bytes Reserved; actual value depends on the application that creates the image The offset, i.e. starting address, of the byte where the bitmap image data (pixel 0A 10 4 bytes array) can be found. DIB header (bitmap information header) This block of bytes tells the application detailed information about the image, which will be used to display the image on the screen. The block also matches the header used internally by Windows and OS/2 and has several different variants. -

Tagged Image File Format (TIFF)
Tagged Image File Format (TIFF) Tagged Image File Format (TIFF) is a standard file format that is largely used in the publishing and printing industry. The extensible feature of this format allows storage of multiple bitmap images having different pixel depths, which makes it advantageous for image storage needs. Since it introduces no compression artifacts, the file format is preferred over others for archiving intermediate files. Tagged Image File Format, abbreviated TIFF or TIF, is a computer file format for storing raster graphics images, popular among graphic artists, the publishing industry, and photographers. TIFF is widely supported by scanning, faxing, word processing, optical character recognition, image manipulation, desktop publishing, and page-layout applications. The latest published version is 6.0 in 1992, subsequently updated with an Adobe Systems copyright after the latter acquired Aldus in 1994. Several Aldus or Adobe technical notes have been published with minor extensions to the format, and several specifications have been based on TIFF 6.0, including TIFF/EP (ISO 12234-2), TIFF/IT (ISO 12639), TIFF-F (RFC 2306) and TIFF-FX (RFC 3949). Filename extensions : .tiff, .tif Internet media type: image/tiff, image/tiff-fx Developed by: Aldus, now Adobe Systems Initial release: 1986; 34 years ago Type of format: Image file format A Tagged Image File Format or TIFF is a specific type of computer file format for storing raster graphic images and exchanging them between application programs. Examples of these programs include word processing, scanning, image manipulation or editors, optical character recognition, and desktop publishing applications, among others. The format was developed in 1986 by a group spearheaded by Aldus Corporation, which is now part of Adobe Inc. -

Data Compression
7 Image Compression (GIF) 7.1 Introduction Data communication increasingly involves the transmission of still and moving images. Compressing images into a standard form can give great savings in transmission times and storage lengths. Some of these forms are outlined in Table 7.1. The main parameters in a graphics file are: The picture resolution. This is defined by the number of pixels in the x- and y-directions. The number of colors per pixel. If N bits are used for the bit color then the total number of displayable colors will be 2N. For example, an 8-bit color field defines 256 colors, a 24-bit color field gives 224 or 16.7M colors. Most computer systems allow for 32-bit col- or, which gives over 4 billion colors. Palette size. Some systems reduce the number of bits used to display a color by reducing the number of displayable colors for a given palette size. Table 7.1 Typical standard compressed graphics formats File Compression Max. resolution type or colors TIFF Huffman RLE 48-bit color TIFF (tagged image file format) is typically used to and/or LZW transfer graphics from one computer system to another. It allows high resolutions and colors of up to 48 bits (16 bits for red, green and blue). PCX RLE 65 536 65 536 Graphics file format which uses RLE to compress the (24-bit color) image. Unfortunately, it make no provision for storing gray scale or color-correcting tables. GIF LZW 65 536 65 536 Standardized graphics file format which can be read (24-bit color, but by most graphics packages. -

An Exploration of the Operational Ramifications of Lossless Compression of 1000 Ppi Fingerprint Imagery
NISTIR 7779 - An Exploration of the Operational Ramifications of Lossless Compression of 1000 ppi Fingerprint Imagery NISTIR 7779 An Exploration of the Operational Ramifications of Lossless Compression of 1000 ppi Fingerprint Imagery Shahram Orandi John M. Libert John D. Grantham Kenneth Ko Stephen S. Wood Jin Chu Wu Lindsay M. Petersen Bruce Bandini http://dx.doi.org/10.6028/NIST.IR.7779 PAGE 1 OF 52 NISTIR 7779 - An Exploration of the Operational Ramifications of Lossless Compression of 1000 ppi Fingerprint Imagery PAGE 2 OF 52 NISTIR 7779 - An Exploration of the Operational Ramifications of Lossless Compression of 1000 ppi Fingerprint Imagery NISTIR 7779 An Exploration of the Operational Ramifications of Lossless Compression of 1000 ppi Fingerprint Imagery Shahram Orandi John M. Libert Kenneth Ko Stephen S. Wood Jin Chu Wu Information Access Division - Image Group Information Technology Laboratories John D. Grantham Systems Plus, Inc. Lindsay M. Petersen MITRE Corporation Bruce Bandini Booz Allen Hamilton, Inc. http://dx.doi.org/10.6028/NIST.IR.7779 August 2012 U.S. Department of Commerce Rebecca Blank, Acting Secretary National Institute of Standards and Technology Patrick D. Gallagher, Under Secretary of Commerce for Standards and Technology and Director PAGE 3 OF 52 NISTIR 7779 - An Exploration of the Operational Ramifications of Lossless Compression of 1000 ppi Fingerprint Imagery PAGE 4 OF 52 NISTIR 7779 - An Exploration of the Operational Ramifications of Lossless Compression of 1000 ppi Fingerprint Imagery ACKNOWLEDGEMENTS The authors wish to give special thanks to the following individuals and organizations for their support of this work: Federal Bureau of Investigation for all their support throughout this study T.J. -

Desiging and Editing Custom Graphics for Wincontrol
Desiging and Editing Custom Graphics for WinControl Includes WinControl, WinControl XL and WinControl XL Plus KMC Controls ◆ P.O. Box 497 ◆ 19476 Industrial Drive ◆ New Paris, IN 46553 883-019-12 Designing System Group Graphics Overview of System Groups KMC Controls Designing System Group Graphics With the system groups feature in WinControl, WinControl XL, and WinControl XL Plus you can assemble graphical user interfaces to control building automation systems. This article covers techniques and resources required to create system group background graphics using the three- dimensional graphic library elements provided with WinControl XL Plus. Animated graphics are beyond the scope of this article. Overview of System Groups System Groups are custom designed windows created for each project to provide quick access to the most often used parts of a system. A system group can be a few text-based controls or a complex graphical user interface that includes animated displays and site plans. With the library of graphics in WinControl XL Plus you can display all parts of a system such as temperature, setpoints and equipment settings. Links can be placed in system groups which open other system groups. System groups use graphics for two different purposes: • Background graphics display the overall view of the system or component. • Animated graphics display motion and provide control. Things you need to know Before you begin, take some time to become familiar with the following items. • The file formats JPG, GIF, and BMP. See Graphic file formats on page 7. • A paint or photo editing program. You will need to know how to cut, copy, paste, use the layers palette, and generate output files with Save As..