Feature Selection Towards Soil Classification in the Context of Fertility Classes Using Machine Learning
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

The Epic Imagination in Contemporary Indian Literature
University of South Florida Scholar Commons Graduate Theses and Dissertations Graduate School May 2017 Modern Mythologies: The picE Imagination in Contemporary Indian Literature Sucheta Kanjilal University of South Florida, [email protected] Follow this and additional works at: http://scholarcommons.usf.edu/etd Part of the South and Southeast Asian Languages and Societies Commons Scholar Commons Citation Kanjilal, Sucheta, "Modern Mythologies: The pE ic Imagination in Contemporary Indian Literature" (2017). Graduate Theses and Dissertations. http://scholarcommons.usf.edu/etd/6875 This Dissertation is brought to you for free and open access by the Graduate School at Scholar Commons. It has been accepted for inclusion in Graduate Theses and Dissertations by an authorized administrator of Scholar Commons. For more information, please contact [email protected]. Modern Mythologies: The Epic Imagination in Contemporary Indian Literature by Sucheta Kanjilal A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy with a concentration in Literature Department of English College of Arts and Sciences University of South Florida Major Professor: Gurleen Grewal, Ph.D. Gil Ben-Herut, Ph.D. Hunt Hawkins, Ph.D. Quynh Nhu Le, Ph.D. Date of Approval: May 4, 2017 Keywords: South Asian Literature, Epic, Gender, Hinduism Copyright © 2017, Sucheta Kanjilal DEDICATION To my mother: for pencils, erasers, and courage. ACKNOWLEDGEMENTS When I was growing up in New Delhi, India in the late 1980s and the early 1990s, my father was writing an English language rock-opera based on the Mahabharata called Jaya, which would be staged in 1997. An upper-middle-class Bengali Brahmin with an English-language based education, my father was as influenced by the mythological tales narrated to him by his grandmother as he was by the musicals of Broadway impressario Andrew Lloyd Webber. -

Signatory ID Name CIN Company Name 02700003 RAM TIKA
Signatory ID Name CIN Company Name 02700003 RAM TIKA U55101DL1998PTC094457 RVS HOTELS AND RESORTS 02700032 BANSAL SHYAM SUNDER U70102AP2005PTC047718 SHREEMUKH PROPERTIES PRIVATE 02700065 CHHIBA SAVITA U01100MH2004PTC150274 DEJA VU FARMS PRIVATE LIMITED 02700070 PARATE VIJAYKUMAR U45200MH1993PTC072352 PARATE DEVELOPERS P LTD 02700076 BHARATI GHOSH U85110WB2007PTC118976 ACCURATE MEDICARE & 02700087 JAIN MANISH RAJMAL U45202MH1950PTC008342 LEO ESTATES PRIVATE LIMITED 02700109 NATESAN RAMACHANDRAN U51505TN2002PTC049271 RESHMA ELECTRIC PRIVATE 02700110 JEGADEESAN MAHENDRAN U51505TN2002PTC049271 RESHMA ELECTRIC PRIVATE 02700126 GUPTA JAGDISH PRASAD U74210MP2003PTC015880 GOPAL SEVA PRIVATE LIMITED 02700155 KRISHNAKUMARAN NAIR U45201GJ1994PTC021976 SHARVIL HOUSING PVT LTD 02700157 DHIREN OZA VASANTLAL U45201GJ1994PTC021976 SHARVIL HOUSING PVT LTD 02700183 GUPTA KEDAR NATH U72200AP2004PTC044434 TRAVASH SOFTWARE SOLUTIONS 02700187 KUMARASWAMY KUNIGAL U93090KA2006PLC039899 EMERALD AIRLINES LIMITED 02700216 JAIN MANOJ U15400MP2007PTC020151 CHAMBAL VALLEY AGRO 02700222 BHAIYA SHARAD U45402TN1996PTC036292 NORTHERN TANCHEM PRIVATE 02700226 HENDIN URI ZIPORI U55101HP2008PTC030910 INNER WELLSPRING HOSPITALITY 02700266 KUMARI POLURU VIJAYA U60221PY2001PLC001594 REGENCY TRANSPORT CARRIERS 02700285 DEVADASON NALLATHAMPI U72200TN2006PTC059044 ZENTERE SOLUTIONS PRIVATE 02700322 GOPAL KAKA RAM U01400UP2007PTC033194 KESHRI AGRI GENETICS PRIVATE 02700342 ASHISH OBERAI U74120DL2008PTC184837 ASTHA LAND SCAPE PRIVATE 02700354 MADHUSUDHANA REDDY U70200KA2005PTC036400 -
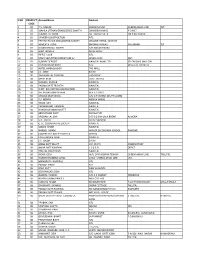
S NO PRODUCT CODE Accountname 1 CD PS
S NO PRODUCT AccountName Address CODE 1 CD P.S. MAUNI HOUSE NO 257 CHEENA KHAN LINE TLT. 2 CD MAHILA UTTHAN GRAMODYOG SANSTH CHANDRA NIWAS P.O MLT. 3 CD KUMAR JITENDRA 18 BARUM VILLA SHER KA DANDA 4 CD SAMEER CONSTRUCTION NTL. 5 CD PRITHVI RATAN GRAMODYOG SANSTH CHAUKRI TEHSIL- DIDIHAT 6 CD HEMLATA JOSHI BHOWALI NIWAS KAILAKHAN TLT. 7 CD SHARDOTSAVA SAMITI C/O NAGAR PALIKA 8 CD HINA TRAVELS MALL ROAD 9 CD RIFFLE CLUB NTL. 10 CD STAFF SECUTITIES FORFEITURE A/ SEVEN OAKS MLT. 11 CD SUNDRY DEPOSIT NAINITAL BANK LTD. SEVEN OAKS MALLITAL 12 CD KISHAN SINGH BISHT NTL. MALLITAL NAINITAL 13 CD HOTEL AMBASSADOR THE MALL 14 SB J.C JOSHI B.V.M 15 SB BANWARI LAL TANDON LUCKNOW 16 SB MANI RAM GOVT. HOUSE 17 SB SUBODH KUMAR NAINITAL 18 SB PADMA DATT TRIPATHI NAINITAL 19 SB DISTT. BEE KEEPING ASSOCIATION NAINITAL 20 SB HEERA BALLABH PATHAK M.E.S STORES 21 SB MADAN MOHAN LAL C/O S.P SAXENA DEUTY COMM 22 SB P.S MEHTA MEHRA NIWAS 23 SB HEMA SAH NAINITAL 24 SB PARMANAND KANDPAL NAINITAL 25 SB HARISH CHANDRA BHATT NAINITAL 26 SB BRIJ MOHAN PANT DURGA PUR 27 SB KRISHAN LAL SAH S/O B.D.SAH LALA BAZAR ALMORA 28 SB S.D. SINGH B.V.M NAINITAL 29 SB G.I.C. COOPERATIVE SOCIETY NAINITAL 30 SB SOBAN SINGH NAINITAL 31 SB NARAIN SWAMI HIGHER SECONDARY SCHOOL RAMGAR 32 SB COOPRETIVE SOCIETY GETHIA GETHIA 33 SB CIVIL ESRVICE CLUB NAINITAL 34 SB J.P. -

Uttrakhand Seems to Cut Off the Students Instead Including Them
U T T A R A K H A N D: NEED FOR A COMPREHENSIVE ECO-STRATEGY EDITOR R.P. DHASMANA CO-EDITOR VIJAY LAXMI DHOUNDIYAL V.K. PUBLISHERS, DA-9A D.D.A. FLATS, MUNIRKA, NEW DELHI-110 067 Simen puu ————————————————————————————————————— First edition: January 2008. © RPD-VLD Published by the Convener, SADED, Mr. Vijay Pratap DA- 9A. D.D.A. Flats, Munirka, New Delhi-110 067 and Simen puu, Finland, Director. —————— Helsinki. Also Available at: 1- 2- 3- 4- Printed at:———————————————————————————————————————— ——————————————————————————————————————————— ii UTTARAKHAND : Need for a Comprehensive Eco-Strategy ■ Introductory Preface The present venture is an humble attempt by the editors of the work to make the entire region of Uttarakhand known to those interested in respect of all that one wants to know about it. Then only one can think in terms of its eco- development or establishing eco-development in the newly formed State. To evolve a strategy for achieving these objectives, one has to understand the geographical profile and historical perspective of the region, understand its milieu and ethos of its people as well, its cultural background, fairs and festivals, language, folk songs and dances, its resources, simple technologies for capacity building of women there, vocational education, entrepreneurship, problems and needs of the local population, health status of the people, movements launched by the people from time to time and scores of things to determine the right mode of development. Part ‘A’ of the book deals with Uttarakhand–ID, Part ‘B’ talks of various challenges before the emerging State of Uttarakhand, economic scenariao and viability and Part ‘C’ deals with searching a role model of intelligent industrialisation of the State, finding out the main resources and their utilisation for the development of the State and Administrative and Management problems as also the strategy and approach to realize the objectives for the State. -

LIST of CANDIDATES for WHOM CALL LETTER ISSUED Note
Page No. 1 LIST OF CANDIDATES FOR WHOM CALL LETTER ISSUED TRADE : PIONEER EXAM DATE - 16 NOV 2009 (BATCH-3 & FINAL) ADVT- 01/2009 EXAM CENTRE - GREF CENTRE, PUNE - 15 CATEGORY - UR (DIGHI CAMP, PUNE - 411015 (MAHARASHTRA) Srl No. Control Name Father's Name Address No. DOB 1 PNR/UR/3 SACHCHITANAN KAWALDEV SACHCHITANAND 38116 D PRASAD S/O KAWALDEV PRASAD VILL - KANSO, PO - KANSO DIST - MAU 2-Apr-91 UTTAR PRADESH, PIN - 221706 PNR/UR/338116 2 PNR/UR/3 SUNIL KUMAR RAN SINGH SUNIL KUMAR S/O RAM SINGH 38258 VILL + PO - PRANPURA TEH - BAWAL , DIST - REWARI STATE - HARYANA , PIN - 123501 10-Oct-89 PNR/UR/338258 3 PNR/UR/3 HARI ANANT HARI RAMAN HARI ANANT SINGH 38265 SINGH SINGH S/O HARI RAMAN SINGH VILL - PURE SHOHARAT SINGH PO + PS - JAGDISHPUR DIST - SULTANPUR 15-Dec-89 UTTAR PRADESH , PIN - 227809 PNR/UR/338265 4 PNR/UR/3 SHYAM SUNDAR JIYA RAM SHYAM SUNDAR S/O JIYA RAM 38288 VILL + PO - BERHA PATTI HODAL , TEH - HODAL DIST - PALWAL 20-Jul-90 STATE - HARYANA , PIN - 121106 PNR/UR/338288 5 PNR/UR/3 SUNDAR SINGH KOMAL SINGH SUNDAR SINGH S/O KOMAL SINGH 38364 VILL - DAGSAH, PO - KURSANDA DIST - HATHRAS STATE - UTTAR PRADESH PIN - 281306 18-Mar-88 PNR/UR/338364 6 PNR/UR/3 UDHAM SINGH CHHINGARAM UDHAM SINGH S/O CHHINGARAM 38377 VILL - MAHU KHAS PO - MAHU IBRAHIMPUR TEH - HINDAUN CITY, DIST - KARAULI 15-Jun-88 STATE - RAJASTHAN, PIN - 322254 PNR/UR/338377 7 PNR/UR/3 AJITH OP J OMANAKUTTAN AJITH OP 38481 PILLAI S/O J OMANAKUTTAN PILLAI PLAVILAYIL VEEAU EAAVANASSERI PO - MYNAGAPPALLY, DIST - KOLLAM 5-Nov-88 STATE - KERALA, PIN - 690519 PNR/UR/338481 8 PNR/UR/3 JIBANANDA JUGAL CHANDRA JIBANANDA MONDAL 39033 MONDAL MONDAL S/O JUGAL CHANDRA MONDAL VILL - FULKHALI, PO - KECHUADANGA PS - MURUTIA, DIST - NADIA STATE - WEST BENGAL 9-Nov-87 PIN - 741172 PNR/UR/339033 Note:- Candidate who donot receive Call Letter by post , can also report for Trade Test / Interview with a copy of Attestation Form duly completed by downloading form from this web site. -

To Download the PDF File
Representing the Unrepresentable: The Bollywood Partition Film Natasha Master Honours Degree Carleton University A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment Of the requirements for the degree of Master of Arts In Film Studies. Carleton University OTTAWA, Ontario December 4th, 2009 © 2009, Natasha Master Library and Archives Bibliothgque et 1*1 Canada Archives Canada Published Heritage Direction du Branch Patrimoine de l'6dition 395 Wellington Street 395, rue Wellington Ottawa ON K1A0N4 Ottawa ON K1A0N4 Canada Canada Your file Votre r6f6rence ISBN: 978-0-494-64453-9 Our file Notre reference ISBN: 978-0-494-64453-9 NOTICE: AVIS: The author has granted a non- L'auteur a accorde une licence non exclusive exclusive license allowing Library and permettant a la Bibliotheque et Archives Archives Canada to reproduce, Canada de reproduire, publier, archiver, publish, archive, preserve, conserve, sauvegarder, conserver, transmettre au public communicate to the public by par telecommunication ou par Nnternet, preter, telecommunication or on the Internet, distribuer et vendre des theses partout dans le loan, distribute and sell theses monde, a des fins commerciales ou autres, sur worldwide, for commercial or non- support microforme, papier, electronique et/ou commercial purposes, in microform, autres formats. paper, electronic and/or any other formats. The author retains copyright L'auteur conserve la propriete du droit d'auteur ownership and moral rights in this et des droits moraux qui protege cette these. Ni thesis. Neither the thesis nor la these ni des extraits substantiels de celle-ci substantial extracts from it may be ne doivent etre imprimes ou autrement printed or otherwise reproduced reproduits sans son autorisation. -
Revisions Best Student Essays of the University of North Carolina at Pembroke Vol
ReVisions Best Student Essays of The University of North Carolina at Pembroke Vol. 5, No. 1 Spring 2005 EACHUM B OEL J ReVisions: Best Student Essays is a publication designed to celebrate the finest nonfiction work composed by undergraduate students at The University of North Carolina at Pembroke. This issue was copyedited, designed, and produced by the students in PRE 345: Computer-Assisted Editing and Publication De- sign. Jeshannah Ayala Allen Barfield Davina Gilbert Barbara Gushrowski Michelle McLean Cindy Saylor Mark Schulman Sara Oswald, Instructor This publication is designed to provide students with an opportunity to publish nonfiction work Selection Committee composed at UNCP, and the essays published by ReVisions: Best Student Essays will demonstrate the finest Jeff Frederick writing produced by UNCP students. Dept. of History All submissions must be nominated by a UNCP faculty member. Faculty members are encouraged Kim Gunter Dept. of English, Theatre, and Languages to nominate their students’ best nonfiction work. Students who feel that they have a strong essay for Jamie Litty submission are encouraged to ask a faculty member to sponsor that essay. A nomination form is included Dept. of Mass Communications on page 40 of this issue; forms are also available in the English, Theatre, and Languages Department in Dial Humanities Building. Forms may be photocopied. Editor Papers may cover any topic within any field of study at UNCP. We do not publish fiction or poetry. Susan Cannata We encourage submissions from all fields and majors. Dept. of English, Theatre, and Languages All submissions must be accompanied by a nomination form. Students should fill out the nomina- Managing Editor tion form completely and sign it, granting permission to the editors to edit and publish the essay if ac- Sara Oswald cepted. -

UNIT 4 QUEER(ING) CINEMA and Critical Analysis
Spectatorship, Censorship UNIT 4 QUEER(ING) CINEMA and Critical Analysis Himadri Roy Structure 4.1 Introduction 4.2 Objectives 4.3 Elements of Queer Cinema 4.4 Chronological Portrayal of Queer People 4.4.1 Portrayals from Independence till the Golden Era of 1970s 4.4.2 Portrayals from the Golden Era of 1970s till the 1990s 4.4.3 Recent Portrayals 4.5 Vernacular Queer Films of India 4.6 Queer Films Beyond Mainstream Cinema 4.7 Films Depicting Specific Queer Cultures 4.8 Let Us Sum Up 4.9 Unit End Questions 4.10 References 4.11 Suggested Readings 4.1 INTRODUCTION In the other units of this block, you have studied about gender, film making and cinema. Each unit focuses on different ways of reading a film. The first unit talks about how the camera becomes a mode of looking various ways of interpreting gender in a film. The second unit deals with the way the categories of gender are represented in cinema and the third unit attempts to define how the censor board of a country plays a pivotal role in determining what you as a spectator may expect from a film and the final product that reaches you. In this unit, you will learn more about how the ‘other’ gender or the queer category is represented in a film within a historical context. We will also examine how to trace the representation of groups known as LGBT or Lesbian-Gay-Bisexual-Transgender groups. 4.2 OBJECTIVES After going through this unit, you should be able to: • Describe the major elements of queer cinema; • Explain the different depictions of the queer people in different eras chronologically; • Talk about the other categories of films made in India; 129 Gender, Film and Cinema • Describe the vernacular queer cinema made in different regions of the country; and • Analyse how queer culture is portrayed in cinema. -

Poster Presentation Presenting Author Wise
Selected Abstract List Poster Presentation Presenting Author wise Presenting Roll Affiliation/Organization Discipline Cat. Title of Abstract Author* No Physics Department TEMPERATURE DEPENDENCE OF SOUND A. Kumar Gurukula Kangri Vishwavidyalya Physics 2 620 VELOCITY IN WATER Haridwar Department of Vegetable Sciences G.B. Pant University of Agriculture and Agricultural RATOONING IN CABBAGE HYBRIDS IN HIGH A.K. Sharma Technology 3 99 Sciences HILLS Pantnagar US Nagar Himalayan Institute of Pharmacy & Medical Science EVALUATION OF TINOSPORA INDICA Research including Aarti Bhatt 1 MUCILAGE AS A PHARMACEUTICAL 520 Atakfarm - Rajawala Pharmaceutical EXCIPIENT Dehradun Science Department of Zoology & Biotechnology ISOLATION AND SCREENING OF CELLULASE Biotechnology, Abhaya Shikhar H.N.B. Garhwal University PRODUCING THERMOPHILIC STRAINS AND Biochemistry & 1 162 Panwar (A Central University) ITS FERMENTATION ABILITY IN CELLULOSIC Microbiology Srinagar Garhwal BIOMASS (B.Tech ME-IV Sem.) PROMOTION OF GREEN TECHNOLOGY FOR Graphic Era Hill University Abhinav Madan Rural Technology 1 BEAUTIFICATION OF LAKES AND PONDS AS 632 Bhimtal A SOURCE OF ECOTOURISM PRODUCTS Nainital (UK) STRUCTURAL ANALYSIS AND PROTECTIVE Indian Veterinary Research Institute Veterinary Sciences EFFICACY OF RECOMBINANT 87 KDA OUTER Abhinendra Kumar Mukteswar & Animal 1 661 MEMBRANE PROTEIN (OMP87) OF Nainital Husbandry PASTEURELLA MULTOCIDA SEROGROUP B:2 Department of Pharmaceutical Chemistry Medical Science SYNTHESIS OF NEW PYRAZOLIDINE 3,5 Devsthali Vidyapeeth College of including -

The Daayraa Movie Download
The Daayraa Movie Download The Daayraa Movie Download 1 / 4 2 / 4 The Daayraa Movie Download c71e67ad50 daayraa movie, daayraa movie online, daayraa movie download, daayraa movie songs, daayraa 1996 full movie .... Download Daayraa (1997) Hindi Movie MP3 Songs. Daayraa hindi song, Daayraa djpunjab, Daayraa songs download, Daayraa mp3 juice, .... From ad films Abhinay had made a successful transition to films and ... the critically acclaimed Daayra and the fantasy film Paheli starring Shah ... 1. dayra movie 2. daayraa movie songs 3. daayraa full movie daayraa movie download daayraa movie online watch daayraa movie online daayraa full movie daayraa 1996 full movie daayraa hindi movie songs daayra .... The film features Tara Deshpande and Nirmal Pandey, with the entire plot taking ... The Square Circle; sometimes spelled as Daayra) is a 1996 Bollywood film, .... Daayraa (translation: The Square Circle) is a 1997 Bollywood movie, directed by Amol Palekar, starring Nirmal Pandey and Sonali Kulkarni.. In his films, the actor was more the common man with middle-class aspirations ... Daayraa (1996), starring Nirmal Pandey and Sonali Kulkarni, is an underrated, ... For all the latest Eye News, download Indian Express App. dayra movie dayra movie, daayraa movie online, daayraa movie songs, daayraa 1996 full movie download, daayraa full movie, daayraa 1996 full movie online, daayraa 1996 full movie, daayraa full movie download, daayraa full movie hindi, daayra movie songs Even in a short career span, Nirmal Pandey created an impressive body of work. Although, despite earning tremendous acclaim for his early films, the actor with .... Download watch daayraa 1996 full movie online .mp4 .avi .3gp .mkv. -

UNIVERSIDAD DE MURCIA Departamento De Filología Inglesa
UNIVERSIDAD DE MURCIA Departamento de Filología Inglesa Shakespeare, Bollywood and Beyond Shakespeare Transnacional: Su presencia en Bollywood y en la Diáspora Dª. Rosa María García Periago OMNP= To Manolo ACKNOWLEDGEMENTS My primary thanks are for my supervisor Dra. Dña. Clara Calvo López for her support, encouragement, constructive comments and useful feedback for this dissertation. I also have to thank her for always believing in me and in my potential, since she first met me when I was a 2 nd year undergraduate student. She has always been very open-minded to all my ideas and suggestions, and it has been very rewarding to work under her supervision. I also have to thank my tutors during my research stays at Queen’s University Belfast, SOAS (School of Oriental and African Studies) and at King’s College (London), since this project would not have been the same without them. Prof. Mark Thornton Burnett (Queen’s University Belfast) provided me with the necessary background and style to write the dissertation. His careful reading along the way, constructive comments and illuminating conversations were crucial in the early stages of this dissertation. Prof. Rachel Dwyer (SOAS) taught me a considerable part of what I know of Bollywood cinema. I thank her for her enthusiasm, brilliance, interesting comments, but, above all, for letting me attend her Bollywood cinema classes and for encouraging me to learn Hindi language. Last, but not least, I owe thanks to Dr. Sonia Massai for her availability, her kindness and her help. This dissertation would not have been possible without the generous support on FPU scholarship granted by the Ministerio de Educación y Ciencia. -

Literature to Films: a Study of Select Women Protagonists in Hindi Cinema
LITERATURE TO FILMS: A STUDY OF SELECT WOMEN PROTAGONISTS IN HINDI CINEMA THESIS Submitted to GOA UNIVERSITY For the Award of the degree of Doctor of Philosophy in English by Mrs. Bharati P. Falari Under the Guidance of Dr. (Mrs.) K. J. Budkuley Professor & Head, Department of English, Goa University, Taleigao Plateau, Goa - 403206. October 2013 CERTIFICATE As required under the University Ordinance, OB-9.9(viii), I hereby certify that the thesis entitled, Literature to Films: A Study of Select Women Protagonists in Hindi Cinema, submitted by Mrs.Bharati P.Falari for the Award of the Degree of Doctor of Philosophy in English has been completed under my guidance. The thesis is the record of the research work conducted by the candidate during the period of her study and has not previously formed the basis for the award of any Degree, Diploma, Associateship, Fellowship or other similar titles to her by this or any other University. Dr. (Mrs.) K.J.Budkuley Research Guide Professor & Head Department of English, Goa University. Date: i DECLARATION As required under the University Ordinance OB-9.9(v), I hereby declare that the thesis entitled, Literature to Films: A Study of Select Women Protagonists in Hindi Cinema, is the outcome of my own research undertaken under the guidance of Dr. (Mrs.) K.J.Budkuley, Professor & Head, Department of English, Goa University. All the sources used in the course of this work have been duly acknowledged in the thesis. This work has not previously formed the basis of any award of Degree, Diploma, Associateship, Fellowship or other similar titles to me, by this or any other University.