Information Technology — Universal Multiple-Octet Coded Character Set (UCS) —
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Transport and Map Symbols Range: 1F680–1F6FF
Transport and Map Symbols Range: 1F680–1F6FF This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

Framing Cyclic Revolutionary Emergence of Opposing Symbols of Identity Eppur Si Muove: Biomimetic Embedding of N-Tuple Helices in Spherical Polyhedra - /
Alternative view of segmented documents via Kairos 23 October 2017 | Draft Framing Cyclic Revolutionary Emergence of Opposing Symbols of Identity Eppur si muove: Biomimetic embedding of N-tuple helices in spherical polyhedra - / - Introduction Symbolic stars vs Strategic pillars; Polyhedra vs Helices; Logic vs Comprehension? Dynamic bonding patterns in n-tuple helices engendering n-fold rotating symbols Embedding the triple helix in a spherical octahedron Embedding the quadruple helix in a spherical cube Embedding the quintuple helix in a spherical dodecahedron and a Pentagramma Mirificum Embedding six-fold, eight-fold and ten-fold helices in appropriately encircled polyhedra Embedding twelve-fold, eleven-fold, nine-fold and seven-fold helices in appropriately encircled polyhedra Neglected recognition of logical patterns -- especially of opposition Dynamic relationship between polyhedra engendered by circles -- variously implying forms of unity Symbol rotation as dynamic essential to engaging with value-inversion References Introduction The contrast to the geocentric model of the solar system was framed by the Italian mathematician, physicist and philosopher Galileo Galilei (1564-1642). His much-cited phrase, " And yet it moves" (E pur si muove or Eppur si muove) was allegedly pronounced in 1633 when he was forced to recant his claims that the Earth moves around the immovable Sun rather than the converse -- known as the Galileo affair. Such a shift in perspective might usefully inspire the recognition that the stasis attributed so widely to logos and other much-valued cultural and heraldic symbols obscures the manner in which they imply a fundamental cognitive dynamic. Cultural symbols fundamental to the identity of a group might then be understood as variously moving and transforming in ways which currently elude comprehension. -

Proposal to Add U+2B95 Rightwards Black Arrow to Unicode Emoji
Proposal to add U+2B95 Rightwards Black Arrow to Unicode Emoji J. S. Choi, 2015‐12‐12 Abstract In the Unicode Standard 7.0 from 2014, ⮕ U+2B95 was added with the intent to complete the family of black arrows encoded by ⬅⬆⬇ U+2B05–U+2B07. However, due to historical timing, ⮕ U+2B95 was not yet encoded when the Unicode Emoji were frst encoded in 2009–2010, and thus the family of four emoji black arrows were mapped not only to ⬅⬆⬇ U+2B05–U+2B07 but also to ➡ U+27A1—a compatibility character for ITC Zapf Dingbats—instead of ⮕ U+2B95. It is thus proposed that ⮕ U+2B95 be added to the set of Unicode emoji characters and be given emoji‐ and text‐style standardized variants, in order to match the properties of its siblings ⬅⬆⬇ U+2B05–U+2B07, with which it is explicitly unifed. 1 Introduction Tis document primarily discusses fve encoded characters, already in Unicode as of 2015: ⮕ U+2B95 Rightwards Black Arrow: Te main encoded character being discussed. Located in the Miscellaneous Symbols and Arrows block. ⬅⬆⬇ U+2B05–U+2B07 Leftwards, Upwards, and Downwards Black Arrow: Te three black arrows that ⮕ U+2B95 completes. Also located in the Miscellaneous Symbols and Arrows block. ➡ U+27A1 Black Rightwards Arrow: A compatibility character for ITC Zapf Dingbats. Located in the Dingbats block. Tis document proposes the addition of ⮕ U+2B95 to the set of emoji characters as defned by Unicode Technical Report (UTR) #51: “Unicode Emoji”. In other words, it proposes: 1. A property change: ⮕ U+2B95 should be given the Emoji property defned in UTR #51. -
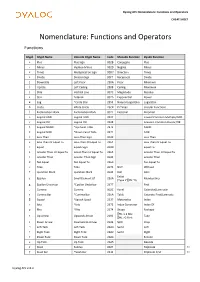
Dyalog APL Binding Strengths
Dyalog APL Nomenclature: Functions and Operators CHEAT SHEET Nomenclature: Functions and Operators Functions Glyph Glyph Name Unicode Glyph Name Code Monadic Function Dyadic Function + Plus Plus Sign 002B Conjugate Plus - Minus Hyphen-Minus 002D Negate Minus × Times Multiplication Sign 00D7 Direction Times ÷ Divide Division Sign 00F7 Reciprocal Divide ⌊ Downstile Left Floor 230A Floor Minimum ⌈ Upstile Left Ceiling 2308 Ceiling Maximum | Stile Vertical Line 007C Magnitude Residue * Star Asterisk 002A Exponential Power ⍟ Log *Circle Star 235F Natural Logarithm Logarithm ○ Circle White Circle 25CB Pi Times Circular Functions ! Exclamation Mark Exclamation Mark 0021 Factorial Binomial ∧ Logical AND Logical AND 2227 Lowest Common Multiple/AND ∨ Logical OR Logical OR 2228 Greatest Common Divisor/OR ⍲ Logical NAND *Up Caret Tilde 2372 NAND ⍱ Logical NOR *Down Caret Tilde 2371 NOR < Less Than Less-Than Sign 003C Less Than ≤ Less Than Or Equal To Less-Than Or Equal To 2264 Less Than Or Equal To = Equal Equals Sign 003D Equal To ≥ Greater Than Or Equal To Great-Than Or Equal To 2265 Greater Than Or Equal To > Greater Than Greater-Than Sign 003E Greater Than ≠ Not Equal Not Equal To 2260 Not Equal To ~ Tilde Tilde 007E NOT Without ? Question Mark Question Mark 003F Roll Deal Enlist ∊ Epsilon Small Element Of 220A Membership (Type if ⎕ML=0) ⍷ Epsilon Underbar *Epsilon Underbar 2377 Find , Comma Comma 002C Ravel Catenate/Laminate ⍪ Comma Bar *Comma Bar 236A Table Catenate First/Laminate ⌷ Squad *Squish Quad 2337 Materialise Index ⍳ Iota *Iota 2373 -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Dictation Presentation.Pptx
Dictaon using Apple Devices Presentaon October 10, 2013 Trudy Downs Operang Systems • iOS6 • iOS7 • Mountain Lion (OS X10.8) Devices • iPad 3 or iPad mini • iPod 4 • iPhone 4s, 5 or 5c or 5s • Desktop running Mountain Lion • Laptop running Mountain Lion Dictaon Shortcut Words • Shortcut WordsDictaon includes many voice “shortcuts” that allows you to manipulate the text and insert symbols while you are speaking. Here’s a list of those shortcuts that you can use: - “new line” is like pressing Return on your keyboard - “new paragraph” creates a new paragraph - “cap” capitalizes the next spoken word - “caps on/off” capitalizes the spoken sec&on of text - “all caps” makes the next spoken word all caps - “all caps on/off” makes the spoken sec&on of text all caps - “no caps” makes the next spoken word lower case - “no caps on/off” makes the spoken sec&on of text lower case - “space bar” prevents a hyphen from appearing in a normally hyphenated word - “no space” prevents a space between words - “no space on/off” to prevent a sec&on of text from having spaces between words More Dictaon Shortcuts • - “period” or “full stop” places a period at the end of a sentence - “dot” places a period anywhere, including between words - “point” places a point between numbers, not between words - “ellipsis” or “dot dot dot” places an ellipsis in your wri&ng - “comma” places a comma - “double comma” places a double comma (,,) - “quote” or “quotaon mark” places a quote mark (“) - “quote ... end quote” places quotaon marks around the text spoken between - “apostrophe” -

TITLE of the PAPER 1. First Steps 2 1.1. General Mathematics 2 1.2
TITLE OF THE PAPER STEVEN J. MILLER ABSTRACT. The point of these notes is to give a quick introduction to some of the standard commands of LaTeX; for more information see any reference book. Thus we concentrate on a few key things that will allow you to handle most situations. For the most part, we have tried to have the text describe the commands; though of course we cannot do this everywhere. You should view both the .tex code and the output (either .pdf or .dvi) simultaneously. CONTENTS 1. First Steps 2 1.1. General Mathematics 2 1.2. One Line Equations 3 1.3. Labeling Equations 4 1.4. Multi-Line Equations: Eqnarray 5 1.5. Lemmas,Propositions,TheoremsandCorollaries 6 1.6. Using Subsubsections 7 1.7. Tables 10 1.8. Matrices and Shortcuts 10 2. Environments I 13 2.1. Shortcut Environments 13 2.2. Enumeration, Itemizing, and General Latex and Linux Commands 13 3. Graphics and Color 14 3.1. Inserting Graphics 14 3.2. Color 14 4. Environments II 15 4.1. Lists 15 4.2. Emphasize and Bolding 15 4.3. Centering Text 15 4.4. Refering to Bibliography 15 4.5. Font sizes 15 5. Documentclassandglobalformatting 16 6. Further Reading 16 Acknowledgements 17 Date: October 14, 2011. 2000 Mathematics Subject Classification. 11M06 (primary), 12K02 (secondary). Key words and phrases. How to use TeX. The author would like to thank to Daneel Olivaw for comments on an earlier draft. The author was supported by a grant from the University of Trantor, and it is a pleasure to thank them for their generosity. -

Hiragana Chart
ひらがな Hiragana Chart W R Y M H N T S K VOWEL ん わ ら や ま は な た さ か あ A り み ひ に ち し き い I る ゆ む ふ ぬ つ す く う U れ め へ ね て せ け え E を ろ よ も ほ の と そ こ お O © 2010 Michael L. Kluemper et al. Beginning Japanese, Tuttle Publishing, an imprint of Periplus Editions (HK) Ltd. All rights reserved. www.TimeForJapanese.com. 1 Beginning Japanese 名前: ________________________ 1-1 Hiragana Activity Book 日付: ___月 ___日 一、 Practice: あいうえお かきくけこ がぎぐげご O E U I A お え う い あ あ お え う い あ お う あ え い あ お え う い お う い あ お え あ KO KE KU KI KA こ け く き か か こ け く き か こ け く く き か か こ き き か こ こ け か け く く き き こ け か © 2010 Michael L. Kluemper et al. Beginning Japanese, Tuttle Publishing, an imprint of Periplus Editions (HK) Ltd. All rights reserved. www.TimeForJapanese.com. 2 GO GE GU GI GA ご げ ぐ ぎ が が ご げ ぐ ぎ が ご ご げ ぐ ぐ ぎ ぎ が が ご げ ぎ が ご ご げ が げ ぐ ぐ ぎ ぎ ご げ が 二、 Fill in each blank with the correct HIRAGANA. SE N SE I KI A RA NA MA E 1. -

Handy Katakana Workbook.Pdf
First Edition HANDY KATAKANA WORKBOOK An Introduction to Japanese Writing: KANA THIS IS A SUPPLEMENT FOR BEGINNING LEVEL JAPANESE LANGUAGE INSTRUCTION. \ FrF!' '---~---- , - Y. M. Shimazu, Ed.D. -----~---- TABLE OF CONTENTS Page Introduction vi ACKNOWLEDGEMENlS vii STUDYSHEET#l 1 A,I,U,E, 0, KA,I<I, KU,KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #1 2 PRACTICE: A, I,U, E, 0, KA,KI, KU,KE, KO, GA,GI,GU, GE,GO, N WORKSHEET #2 3 MORE PRACTICE: A, I, U, E,0, KA,KI,KU, KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #~3 4 ADDmONAL PRACTICE: A,I,U, E,0, KA,KI, KU,KE, KO, GA,GI,GU,GE,GO, N STUDYSHEET #2 5 SA,SHI,SU,SE, SO, ZA,JI,ZU,ZE,ZO, TA, CHI, TSU, TE,TO, DA, DE,DO WORI<SHEEI' #4 6 PRACTICE: SA,SHI,SU,SE, SO, ZA,II, ZU,ZE,ZO, TA, CHI, 'lSU,TE,TO, OA, DE,DO WORI<SHEEI' #5 7 MORE PRACTICE: SA,SHI,SU,SE,SO, ZA,II, ZU,ZE, W, TA, CHI, TSU, TE,TO, DA, DE,DO WORKSHEET #6 8 ADDmONAL PRACI'ICE: SA,SHI,SU,SE, SO, ZA,JI, ZU,ZE,ZO, TA, CHI,TSU,TE,TO, DA, DE,DO STUDYSHEET #3 9 NA,NI, NU,NE,NO, HA, HI,FU,HE, HO, BA, BI,BU,BE,BO, PA, PI,PU,PE,PO WORKSHEET #7 10 PRACTICE: NA,NI, NU, NE,NO, HA, HI,FU,HE,HO, BA,BI, BU,BE, BO, PA, PI,PU,PE,PO WORKSHEET #8 11 MORE PRACTICE: NA,NI, NU,NE,NO, HA,HI, FU,HE, HO, BA,BI,BU,BE, BO, PA,PI,PU,PE,PO WORKSHEET #9 12 ADDmONAL PRACTICE: NA,NI, NU, NE,NO, HA, HI, FU,HE, HO, BA,BI,3U, BE, BO, PA, PI,PU,PE,PO STUDYSHEET #4 13 MA, MI,MU, ME, MO, YA, W, YO WORKSHEET#10 14 PRACTICE: MA,MI, MU,ME, MO, YA, W, YO WORKSHEET #11 15 MORE PRACTICE: MA, MI,MU,ME,MO, YA, W, YO WORKSHEET #12 16 ADDmONAL PRACTICE: MA,MI,MU, ME, MO, YA, W, YO STUDYSHEET #5 17 -

Na Kana Magiti Kei Na Lotu
1 NA KANA MAGITI KEI NA LOTU (Vola Tabu : Maciu 22:1-10; Luke 14:12-24) Vola ko Rev. Dr. Ilaitia S. Tuwere. Sa inaki ni vunau oqo me taroga ka sauma talega na taro : A cava na Lotu? Ni da tekivu edaidai ena noda solevu vakalotu, sa na yaga meda taroga ka tovolea talega me sauma na taro oqori. Ia, ena levu na kena isau eda na solia, me vaka na: gumatuataki ni masu kei na vulici ni Vola Tabu, bula vakayalo, muria na ivakarau se lawa ni lotu ka vuqa tale. Na veika oqori era ka dina ka tu kina eso na isau ni taro : A Cava na Lotu. Na i Vola Tabu e sega ni tuvalaka vakavosa vei keda na ibalebale ni lotu. E vakavuqa me boroya vei keda na iyaloyalo me vakadewataka kina na veika eso e vinakata me tukuna. E sega talega ni solia e duabulu ga na iyaloyalo me baleta na lotu. E vuqa sara e solia vei keda. Oqori me vaka na Qele ni Sipi kei na i Vakatawa Vinaka; na Vuni Vaini kei na Tabana; na i Vakavuvuli kei iratou na nona Gonevuli se Tisaipeli, na Masima se Rarama kei Vuravura, na Ulu kei na Vo ni Yago taucoko, ka vuqa tale. Ena mataka edaidai, meda raica vata yani na iyaloyalo ni kana magiti. E rua na kena ivakamacala eda rogoca, mai na Kosipeli i Maciu kei na nei Luke. Na kana magiti se na solevu edua na ivakarau vakaitaukei. Eda soqoni vata kina vakaveiwekani ena noda veikidavaki kei na marau, kena veitalanoa, kena sere kei na meke, kena salusalu kei na kumuni iyau. -

Supplemental Information 1: System Assumptions
Electronic Supplementary Material (ESI) for Lab on a Chip This journal is © The Royal Society of Chemistry 2011 Supplemental Information 1: System Assumptions Starting from the mass transfer equation: ∂C 2 + υ ⋅ ∇C = D∇ C + R ∂t (a) Distance between the droplet and air channels, O(10‐4) m is much smaller than the distance between the droplet channel PDMS device boundary O(10‐2) m, so little € mass transfer is out of the device and most mass transfer is into the air channel. (b) Assume the oil provides no resistance as compared to the PDMS. (c) Assume psuedo‐steady state since the PDMS boundaries and concentration boundary conditions are fixed: ∂C = 0 ∂t (d) No convection € υ = 0 (e) No reaction € R = 0 (f) Since the oil provides little resistance to mass transfer, the end of the droplets can be assumes as a constant value with surface area equal to the height of the droplet, h, multiplied by the width of the droplet (g) The concentration out the top is a function of the distance between droplet and air channels and will related to mass transfer out the sides for fixed droplet/air separations. This mass transfer can be represented by multiplying by an effective area. Therefore the system is simplified to one dimension. ∂ 2C = 0 ∂x 2 BC1 C(x = 0) = Csat,PDMS € Csat,PDMS BC2 C(x = d) = Cair = HCair Csat,air € (Csat,PDMS − HCair ) C = Csat,PDMS − x d € dC C − HC J = −D = D ( sat,PDMS air ) dx d € € Electronic Supplementary Material (ESI) for Lab on a Chip This journal is © The Royal Society of Chemistry 2011 Supplemental Information 2: Droplet Change This derivation and model is derived assuming an approximate rectangular block shaped droplet with constant fluxes (Jtop, Jend, Jside) out of each the top, the ends and the side of the drop (Atop, Aend, Aside) in Equation S1.