Analysing Objective and Subjective Data in Social Sciences: Implications for Smart Cities
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Walk out in Sheffield
Walking Out In… Thursday 17th October Striders Walking Informati on Important Informati on Blacka Moor 5 miles - 4 hours Join expert, Ziggy, as we forage the Nature Reserve for exoti c fungi. EASY GOING WALKS MOST OF OUR WALKS ARE WITHIN THE CITY Leader: Rob Haslam - Tel: 0114 287 9466 Less than 3 miles long, on good surfaces, not too hilly and OF SHEFFIELD, THE LEAFIEST AND GREENEST with no awkward sti les. They are ideal for people making CITY IN THE UK. Tuesday 22nd October Strollers the transiti on from Health Walks. Shire Brook Valley 3 miles - 3 hours Knowledgeable walk leaders will guide you through Join expert, Ziggy, as we forage the Nature Reserve for exoti c STROLLER WALKS Sheffi eld’s ancient woodland, parks and greenspaces, Sheffield fungi on this easy walk with no sti les. About 3 miles long and are graded as generally easy. beside its rivers and canals, and show you its history. Leader: Rob Haslam - Tel: 0114 287 9466 Any diffi culti es are menti oned. Some walks are accompanied by experts in a parti cular Saturday 2nd November Striders *Meet at 9.45am STRIDER WALKS fi eld and others include guided tours of places not Above and About the Upper End of Rivelin 5-6 miles - 3-4 hours Usually about 5 miles or a litt le longer and in more normally open to the public. Hope we get some autumn colour around Rivelin and Wyming rural locati ons where you will encounter sti les, hills and Brook but, at this ti me of year, be prepared for winter weather. -
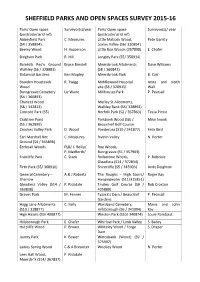
Sheffield Parks and Open Spaces Survey 2015-16
SHEFFIELD PARKS AND OPEN SPACES SURVEY 2015-16 Park/ Open space Surveyor(s)/year Park/ Open space Surveyor(s)/ year (postcode/ grid ref) (postcode/ grid ref) Abbeyfield Park C. Measures Little Matlock Wood, Pete Garrity (S4 / 358894) Loxley Valley (S6/ 310894) Beeley Wood H. Hipperson Little Roe Woods (357898) E. Chafer Bingham Park R. Hill Longley Park (S5/ 358914) Bolehills Rec’n Ground Bruce Bendell Meersbrook Allotments Dave Williams Walkley (S6 / 328883) (S8 / 360842) Botanical Gardens Ken Mapley Meersbrook Park B. Carr Bowden Housteads R. Twigg Middlewood Hospital Anita and Keith Wood site (S6 / 320915) Wall Burngreave Cemetery Liz Wade Millhouses Park P. Pearsall (S4 / 360893) Chancet Wood Morley St Allotments, (S8 / 342822) Walkley Bank (S6/ 328892) Concord Park (S5) Norfolk Park (S2 / 367860) Tessa Pirnie Crabtree Pond Parkbank Wood (S8) / Mike Snook (S5 / 362899) Beauchief Golf Course Crookes Valley Park D. Wood Ponderosa (S10 / 341877) Felix Bird Earl Marshall Rec C. Measures Rivelin Valley N. Porter Ground (S4 / 365898) Ecclesall Woods PLB/ J. Reilly/ Roe Woods, P. Medforth/ Burngreave (S5 / 357903) Endcliffe Park C. Stack Rollestone Woods, P. Ridsdale Gleadless (S14 / 372834) Firth Park (S5/ 368910) Shirecliffe (S5 / 345903) Andy Deighton General Cemetery – A & J Roberts The Roughs – High Storrs/ Roger Kay Sharrow Hangingwater (S11/315851) Gleadless Valley (S14 / P. Ridsdale Tinsley Golf Course (S9 / Bob Croxton 363838) 405880) Graves Park M. Fenner Tyzack’s Dam / Beauchief P. Pearsall Gardens Hagg Lane Allotments C. Kelly Wardsend Cemetery, Mavis and John (S10 / 318877) Hillsborough (S6 / 341904) Kay High Hazels (S9/ 400877) Weston Park (S10/ 340874) Louie Rombaut Hillsborough Park E. -

Community Tubes
Site 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 Community Tubes Brinsworth and Catcliffe Pringle Road Brinsworth 441627 389927 - 32 27 28 - 27 28 - - - - - - - - - - Broadway Brinsworth 441862 389459 - 36 27 28 - 31 30 - - - - - - - - - - Grange Farm Close 442832 389146 - 42 39 39 - 42 42 - - - - - - - - - - Catcliffe Junior School Old Schl La 442730 388748 - 37 26 24 - 25 26 - - - - - - - - - - Highfield View Catcliffe 442374 388915 - 32 27 28 - 29 29 - - - - - - - - - - Main Street Catcliffe 442593 388592 - 34 31 27 - 30 30 - - - - - - - - - - Sheffield Lane 442216 388398 - 30 29 26 - 25 26 - - - - - - - - - - Brinsworth Road 442565 388876 - 40 35 38 - 37 36 - - - - - - - - - - Derwent Crescent 441949 389405 - - 47 52 - 53 55 - - - - - - - - - - St. David's Drive 441279 390219 - - 27 26 - 29 30 - - - - - - - - - - Handsworth and Darnall Highfields Highfield Lane 441765 386876 - 35 35 28 35 30 28 27 26 - - - - - - - - St Mary's Church 441045 386206 - 38 36 32 40 32 32 34 29 - - - - - - - - Fitzallan Road Handsworth 440764 386357 - 29 30 25 28 26 24 24 - - - - - - - - - Rosy's /Anglers Rest 441812 386468 - 29 28 23 30 25 23 22 - - - - - - - - - 181 Handsworth Road 440459 386731 - 42 39 35 42 38 38 36 34 36 40 35 38 36 32 34 34 181 Handsworth Road 440402 386805 - 40 38 35 43 39 37 36 - - - - - - - - - Shop Front Parkway R/A 440213 387006 - 43 43 38 44 39 40 41 39 39 43 39 41 37 39 43 44 Greenwood Cres/62 Retford Rd 441518 386329 - 31 27 25 - 25 23 26 30 - - - - - - - - Prince of Wales Road 438824 -

THE WILD CITY the Coexistence of Wildlife and Human in Sheffield
THE WILD CITY The coexistence of wildlife and human in Sheffield 1970 3) 2020 future URBAN DESIGN THESIS PROJECT KEXIN CAI University of Sheffield School of Architecture ARC6982 Urban Design Project 3: Thesis The Wild City Academic Year 2019/2020 Module leader: Dr Beatrice De Carli Coexistence of wildlife and human in Sheffield Kexin Cai Registration no. 190249405 Supervisor: Beatrice De Carli, Cathryn Klasto, Esra Can Thesis submitted to the University of Sheffield in partial fulfilment of the requirements for the degree of MA in Urban Design Sheffield, 4 September 2020 Abstract In the UK, over 90% of the population already lives in cities. Human activities heavily impact on living conditions of wildlife and they alter wildlife habitats in cities. It is of great importance to bring wildlife back to cities and build wildlife-inclusive cities where humans and animals can friendly coexist. This thesis design aims to explore and analyze how urban design practitioners could deploy design methods to support wildlife and designing coexistence of human and wildlife in contemporary cities. The design-based research starts with the background context of both United Kingdom and Sheffield, investigating the state and pressures of wildlife. Due to the threatened situation of Willow tit in the UK and Sheffield, the analysis mainly focusses on the state of Willow tit in Sheffield, considering the background and specificity of this species. Then develops the problem statement and research questions in 3 aspects: space, social and management aspect. Next, the research of theoretical background strongly supports the whole thesis. The concept of ‘Care’ plays as a guiding principle in each aspect and ‘rewilding’ is the key practice throughout the development and design, aiming to construct a wildlife-inclusive city in Sheffield. -

What's on in September, 2017
Banner Cross Neighbourhood Group: What’s on in September, 2017 Fri Kylie Tribute Dinner 1st Napoleon’s Casino, Ecclesall Road Tickets for the night cost just £35 per person & include a 3 course meal and drink. You'll also get a £5 gaming chip to play with in the casino. Call 266 1115 to book and for information Sat Sheffield & Rotherham Wildlife Trust: Volunteer work day on Blacka Moor 2nd Blacka Moor is on the A625 out of Sheffield a few hundred yards on the left before Fox House. 10am – 3pm Practical volunteer days at Blacka Moor are held on the first Saturday and third Thursday every month. Tasks vary from footpath improvements and access work, to habitat and vegetation management. Gloves, tools, and refreshments are provided, but wear suitable outdoor clothes and boots, and bring some lunch and drinking water if you're able to come for the whole day. Please contact beforehand: 0114 263 4335 Sat Archer Lane Allotment and Home Grown Garden Society: Annual Flower and Vegetable Show 2nd Archer Lane allotments pavilion hut. Open to the public from 2.00pm. Trophies presented at 3.00pm Sat Friends of the Porter Valley: Moth Study 2nd Forge Dam café 7.30pm – 9.30pm This is a new topic for FoPV when Ben Keywood of the Wildlife Trust will set up a moth trap close to the Cafe and as dusk falls, will describe the species of moth which could be caught and studied. The number of moths actually caught could give an indication of the health of the valley. -

Analyzing Objective and Subjective Data in Social Sciences: Implications for Smart Cities
SPECIAL SECTION ON APPLICATIONS OF BIG DATA IN SOCIAL SCIENCES Received December 17, 2018, accepted January 5, 2019, date of publication February 4, 2019, date of current version February 22, 2019. Digital Object Identifier 10.1109/ACCESS.2019.2897217 Analyzing Objective and Subjective Data in Social Sciences: Implications for Smart Cities LAURA ERHAN 1, MARYLEEN NDUBUAKU1, ENRICO FERRARA1, MILES RICHARDSON2, DAVID SHEFFIELD2, FIONA J. FERGUSON2, PAUL BRINDLEY3, AND ANTONIO LIOTTA 1, (Senior Member, IEEE) 1Data Science Research Centre, University of Derby, Derby DE22 1GB, U.K. 2Human Sciences Research Centre, University of Derby, Derby DE22 1GB, U.K. 3Department of Landscape Architecture, The University of Sheffield, Sheffield S10 2TN, U.K. Corresponding author: Laura Erhan ([email protected]) This work was supported by the IWUN Project funded by the Natural Environment Research Council, ESRC, BBSRC, AHRC, and Defra under Grant NE/N013565/1. ABSTRACT The ease of deployment of digital technologies and the Internet of Things gives us the opportunity to carry out large-scale social studies and to collect vast amounts of data from our cities. In this paper, we investigate a novel way of analyzing data from social sciences studies by employing machine learning and data science techniques. This enables us to maximize the insight gained from this type of studies by fusing both objective (sensor information) and subjective data (direct input from the users). The pilot study is concerned with better understanding the interactions between citizens and urban green spaces. A field experiment was carried out in Sheffield, U.K., involving 1870 participants for two different time periods (7 and 30 days). -

Project Spend Details1
15 September 2010 S106 Community Assembly Report South Agreement Site(s) of Works if Ref/ By S106 Amount/Date Agreement Development Heads of specified in Appropriate Project Site(s) agreed BB No. Value Received Date/No. Site Terms Agreement Priority Sites Amount by Assembly 512 P&C £16,420.00 19/09/2005 Gatefield Social Recreational Not Specified Broadfield Rd OS£16,420.00 Broadfield Rd OS 05/00488/FUL 536 space within the Abbeydale Rd locality of the site Awaiting Money Sheffield 524 P&C £10,035.00 12/12/2005 Recreational Not Specified Broadfield Rd OS£10,035.00 Broadfield Rd OS 05/04092/FUL space within the Hale St locality of the site Awaiting Money Sheffield 611 £5,400.0019/09/2006 Land between Recreational Not Specified Trees - Chelsea Park£5,400.00 Trees - Chelsea Park 06/01957/FUL 285-3 space within the Psalter Lane locality of the site Overall proposal needed from Community Forester Awaiting Money 0 Sheffield 640 ? £17,150.00 16/10/2006 Land off Recreational Not Specified Millhouses Park£17,150.00 Not Agreed Yet 06/02875/FUL space within the Archer Rd locality of the site Awaiting Money 0 Sheffield 747 £5,490.0010/09/2007 Site of To be used as a Not Specified Trees£5,490.00 Trees 07/01028/FUL 122-1 contribution Psalter Lane towards local recreational facilities. Overall proposal needed from Community Forester Awaiting Money Sheffield 751 £11,450.0005/09/2007 Land at Towards the Not Specified Trees£11,450.00 Trees 07/01414/FUL 131 provision of Psalter Lane open space within the catchment area Awaiting Money Sheffield of the site 783 £9,000.0024/01/2008 Land between Recreational Not Specified Jordanthorpe Playground£9,000.00 Jordanthorpe Playground 07/03993/FUL space within the Dyche Close and locality of the Dyche Place site Awaiting Money Sheffield Page 1 of 7 15 September 2010 S106 Community Assembly Report South Agreement Site(s) of Works if Ref/ By S106 Amount/Date Agreement Development Heads of specified in Appropriate Project Site(s) agreed BB No. -

I Would Like to Be Considered for the Position of Overview and Scrutiny
AGENDA ITEM: 10(b) Page nos. 100 – 145 Meeting Cabinet Date 8 June 2009 OPEN SPACES IN BARNET REVIEW REPORT OF THE CLEANER, GREENER, TRANSPORT & DEVELOPMENT OVERVIEW AND SCRUTINY COMMITTEE 100 1. SCOPE OF THE REVIEW 1.1 On 16th February 2008 the committee concluded the Parks in Barnet review. At the Cleaner, Greener, Transport and Development OSC meeting on 16th February 2009, the committee considered Councillor Julie Johnson’s Member’s item – “As I said in the council chamber at the last full council meeting I would be asking the committee to agree to extend the parks review to include open spaces. Open spaces are an integral part of Barnet’s green environment and obviously all members of this committee are well aware of how important these are to their own constituents. However some are under utilized for various reasons whilst many such as the Welsh Harp Reservoir and Scratch Woods for example are popular and well used. Criterion- 1) What level of public use is made of open space? 2) Is there any local or community involvement ( friends group, wildlife watch etc)? 3) Is the standard of maintenance acceptable? 4) How well is the space publicised and is access clear and convenient? 5) Is public use encouraged by paths, bridleways, way-marking tree identification, picnic areas, organised walks and events? 6) What public facilities already exist i.e. sports equipment etc? But do all open spaces meet this criteria and if not is there more we could do to make open spaces a success story in Barnet? Can I recommend to the committee that members of the review working party visit a minimum of three designated open spaces each? Councillor Andrew McNeil and Mr. -

A Century of Remembrance the Stories of the Men on the War Memorial Dore News
DORE VILLAGE SOCIETY NO. 132 WINTER 2018 ISSN 0965-8912 A Century of Remembrance The stories of the men on the war memorial Dore News Thank you to the residents of Dore Thanks to deliverers St Vincent’s Furniture Store charity wish to thank the many residents Gillian, Geoff and by extension the whole of the Dore to Door team and households in Dore who have most generously supported St would like to thank three of our deliverers who are no longer able Vincent’s for the past 31 years, donating good quality furniture and to distribute this magazine and are retiring. Brenda Fryer has been household items. Everything they received from you was given delivering Dore to Door for 22 years, Tony Long for about 20 years, away free of charge to help homeless families and individuals in and Graham Oates for seven years. What wonderful service to the Sheffield rebuild their lives. community! Since St Vincent’s started in 1987, almost 100,000 people have Between them they have almost 50 years of service, and they benefited from their help and over 14,000 tonnes of furniture has are just three of the sixty or so people who turn out in all weathers been saved from going into landfill sites. If any residents wish to to ensure that you get your community magazine on time. make further donations in the future either of furniture, or a financial Our distributon network ensures that we reach 3,600 homes - donation helping us keep our vans on the road, please telephone that’s over 7000 people - with Dore to Door every quarter. -

Meersbrook Park Sheffield Green Flag Management Plan 2012 – 2017
Meersbrook Park Sheffield Green Flag Management Plan 2012 - 2017 “To encourage increased educational and recreational use, enhance and preserve the historic features and views, whilst promoting sustainability and biodiversity within the park.” 1 MEERSBROOK PARK Management & Maintenance Plan Part A – The Plan A1. INTRODUCTION p 7 A1.1. The Purpose of the Management & Maintenance Plan p 7 A1.2. Remit of the Plan p 7 A1.3. Outcome of the Plan p 8 A1.4. Period covered by the Plan p 8 A2. PRODUCING THE PLAN p 8 A2.1. Development of the Plan p 8 A2.2. People Involved in Preparing the Plan p 8 A2.3. Consultation p 9 A2.4. Vision for the Park p 9 A2.5. Reviewing the Plan p 9 A2.6. Political and Community Support p 9 2 A3. THE PARK p 11 A3.1. Location p 11 A3.2. Local Context p 11 A3.3. General Description p 12 A3.4. Site Statistics p 14 A3.5. Topography and Geology p 14 A3.6. Landscape Character p 14 A3.7. History & Development p 16 A3.8. Chronology p 20 A3.9. Historical Significance p 21 A3.10 Facilities p 21 A3.11 Site Access p 23 A4. LEGAL AND PLANNING ISSUES p 24 A4.1. Land Ownership p 24 A4.2. Leases, Licences & Agreement p 24 A4.3. Byelaws p 25 A4.4. Planning Designations p 25 A5. POLICY CONTEXT p 27 A5.1. Sheffield City Council Strategies and Policies p 27 A6. USE OF THE PARK p 28 A6.1. User Profile p 28 A6.2. -

Of 2 Bowling Club Address Abbey BC Abbey Hotel, Chesterfield Road, S8
Hyperlinks in the left column open Google Maps at the location of the selected club Bowling Club Address Abbey BC Abbey Hotel, Chesterfield Road, S8 0SH Abbeyfield Abbeyfield Park, Burngreave Road, Sheffield, S4 7AT Bolehills Bole Hills Recreation Ground, Northfield Avenue, S10 1QN Bradfield Low Bradfield, Sheffield, S6 6LB Bradway Bradway Road, Sheffield, S17 4QW Clifton Park Parkfield Road, Rotherham, S65 2AT Colley Park Remington Road, Parson Cross S5 9AB Crookesmoor Crookes Valley Road, Sheffield, S10 1BA Crookes Social Crookes WMC, Mulehouse Road, S10 1TD Davy BC 630 Prince of Wales Road, Sheffield S9 4ER Ecclesfield Ecclesfield Park, Mill Road, Sheffield, S35 9WG Firth Park Firth Park Road, Sheffield, S5 6HH Frecheville Hopedale Road, Sheffield, S12 4QB Fulwood Slayleigh Lane, Sheffield, S10 3LR Graves Park Charles Ashmore Road, Meadowhead, Sheffield, S8 8GJ Greenhill Greenhill Park, Low Edges Crescent, Sheffield, S8 7LH Grenoside Main Street, Grenoside, Sheffield, S35 8PN Hallam Grange Hallam Grange Sports Club, 70-72 Slayleigh lane, Sheffield, S10 3RH Hallam Prop Hands Road, Walkley, Sheffield, S10 1NB Herdings Herdings Park, Raeburn Road, Gleadless Valley, Sheffield, S14 1DB High Hazels High Hazels Park, Catley Road, Off Greenland Road, Darnall, Sheffield, S9 5JF Hillsborough Hillsborough Park, Middlewood Road, Hillsborough, Sheffield, S6 4HD Hollinsend Hollinsend Park, Ridgeway Road, S12 2SR Laycocks Archer Road, Sheffield, S8 0JY Longley Longley Park, Crower Road, Sheffield, S5 7PN Maltby Coronation Park, Muglet Lane, Maltby, -

A Map & Guide That Walks You Through Sheffield's Radical History
SHEFFIELD RADICALS WALK A map & guide that walks you through Sheffield’s radical history Sheffield has a proud history of radical ideas. Over the last three hundred years, the men and women of this city have come together to try to change the world over and over again: from penning ballads on the cost of bread, to setting up revolutionary cafes; from demanding the right to roam in the land that surrounds the city, to donating land to the city itself. This short walk, from Weston Park Museum to the Town Hall, aims to introduce you to just some of the individuals, groups and causes that have grown up within our hills. Some are familiar, some are forgotten; some were revolutionary, others were slow and steady; some were successful (eventually) whilst some ended in abject failure. But all are testament to a simple fact: that this small city has seen its fair share of big ideas. N WE A61 S Allen Street Furnace Hill THE PONDEROSSA ad Scotland Street 7 West Bar radise St radise Pa North Church St Church North therthorpe Ro Upper Allen Street Ne SCOTLAND Crookes STREET Valley Road t Queen St 6 Bank Street Solly Stree Silver Street reet Hollis t 8 CROOKES CROFT HOUSE Crof 9 t Lee Crof VALLEY SETTLEMENT Tenter Stree PARADISE PARK Garden Street SQUARE East Pa Y t Weston Street Saint Georges Close Red Hill To ork Street Beet Street wnhead St Wheelden St Bailey Street Bolsover Street JAMES rade Bailey Lane Campo Lane 10 High Street 3 Rockingham Stree MONTGOMERY Mushroom Street Siddall St Broad LaneNewcastle Street 11 WESTON BROOK HILL MARK Church Street PARK 5 THE MAPPIN Leopold Street MAPPIN ROUNDABOUT Mappin Street 2 FIRTH BUILDING VICTORIA ART GALLERY Chapel W FIRTH Trippet Lane HALL EBENEZER THE DIAMOND t 1 WESTON COURT 14 ELLIOT Glossop Road BUILDING alk PARK Portobello Street MUSEUM JOSEPH CROW Fargate Holly Street THE 12 Carv R MATHER ACT egent Street UPPER J.G.