Perceptual Quality Assessment of Smartphone Photography”
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

China Equity Strategy
June 5, 2019 09:40 AM GMT MORGAN STANLEY ASIA LIMITED+ China Equity Strategy | Asia Pacific Jonathan F Garner EQUITY STRATEGIST [email protected] +852 2848-7288 The Rubio "Equitable Act" - Our Laura Wang EQUITY STRATEGIST [email protected] +852 2848-6853 First Thoughts Corey Ng, CFA EQUITY STRATEGIST [email protected] +852 2848-5523 Fran Chen, CFA A new bill sponsored by US Senator Marco Rubio has the EQUITY STRATEGIST potential to cause significant change in the listing domains of [email protected] +852 2848-7135 Chinese firms. After the market close in the US yesterday 4th June the Wall Street Journal published an Op-Ed by US Senator Marco Rubio in which he announced that he intends to sponsor the “Equitable Act” – an acronym for Ensuring Quality Information and Transparency for Abroad-Based Listings on our Exchanges. At this time the text of the bill has not been published and we are seeking additional information about its contents and likelihood of passing. However, our early reaction is that this has the potential to cause significant changes in the domain for listings of Chinese firms going forward with the potential for de- listing of Chinese firms on US exchanges and re-listing elsewhere (most likely Hong Kong). More generally we see this development as part of an increased escalation of tensions between China and the US on multiple fronts which should cap the valuation multiple for China equities, in particular in the offshore index constituents and US-listed parts of the universe. We provide a list of the potentially impacted China / HK names with either primary or secondary listings on Amex, NYSE or Nasdaq. -

Leading Chinese Cross-Border Brands – the Top 50
Leading Chinese cross-border brands The Top 50 kpmg.com/cn © 2018 KPMG, a Hong Kong partnership and a member firm of the KPMG network of independent member firms affiliated with KPMG International Cooperative (“KPMG International”), a Swiss entity. All rights reserved. Contents Foreword: KPMG & Facebook 2 Executive summary 4 Methodology 6 Top 50 Chinese global brands 8 Survey commentary 10 Chinese brands going global – business opportunities for SMEs 32 • Thought leader: Yan Zhu, Head, Institute of Internet Industry, Tsinghua University 34 Going global and ensuring market diversification 36 Customer centricity 44 Thought leaders 58 • Kaitian Zeng, Co-founder, 37 Interactive Entertainment 58 • Yue Leng, General Manager, Tmall Global, Alibaba Group 59 • Scott Thiel, Partner, DLA Piper 60 • Gu He, Vice President, Shenzhen Globalegrow E-Commerce Co., Ltd. 62 • Chibo Tang, Managing Director, Gobi Partners 63 • Ethan Wang, Vice President, NetEase 64 • Scott Kronick, Chief Executive, Public Relations & Influence, Asia, Ogilvy 65 • Alen Wu, Vice President, OPPO Mobile; Head of Business, Overseas Markets 66 • Beehong Hong, General Manager, Brand Management Centre, TRANSSION Holdings 67 Acknowledgements 68 About us 69 Contact us 70 Leading Chinese cross-border brands: The Top 50 1 © 2018 KPMG, a Hong Kong partnership and a member firm of the KPMG network of independent member firms affiliated with KPMG International Cooperative (“KPMG International”), a Swiss entity. All rights reserved. © 2018 KPMG, a Hong Kong partnership and a member firm of the KPMG network of independent member firms affiliated with KPMG International Cooperative (“KPMG International”), a Swiss entity. All rights reserved. Foreword Global trade has long been a hallmark of Chinese business culture. -

Site List Fashion, Food & Home
SITE LIST FASHION, FOOD & HOME MARCH 2020 The John Lewis Partnership’s relationships with its suppliers are based on honesty, fairness, courtesy and promptness. In return, the Partnership expects its suppliers to obey the law and to respond the wellbeing of their employees, local communities and the environment. The sites featured in the list below are John Lewis & Partners suppliers’ production sites which represent 100% of John Lewis & Partners’ branded product. Region Number of Sites Africa 23 Americas 14 Arab States 1 Asia Pacific 1195 Europe & Central Asia 526 United Kingdom 548 Total 2307 Active Union or Product No. of Female Male Site Name Address Country Worker Category Workers Worker % Worker % Committee Afa 3 Calzatura Sh.P.K. Velabisht, Beral, Albania Fashion 221 73% 27% Yes Weingut Rabl Weraingraben 10, Langenlois Austria Food 20 25% 75% No Weingut Markus Hurber Cmbh & Cokg Rechersdorf An Der Traisen, Weinriedenweg 13 Austria Food * No Akh Fashions 133-134 Hemayetpur, Savar, Dhaka, Dhaka 1340 Bangladesh Fashion 1222 65% 35% Yes Aman Graphics & Designs Ltd Najim Nagar, Dhaka, Savar Bangladesh Fashion 3804 60% 40% Yes Aman Knittings Ltd Kulashur, Hemayetpur, Dhaka, Savar Bangladesh Fashion 1715 46% 54% Yes Bando Eco Apparels Ld. Plot #188/2, Block G-A, Chanpur, Amin Bazar, Savar, Dhaka, Dhaka, Dhaka Bangladesh Fashion 1200 53% 47% Yes Basic Shirts Ltd Plot # 341, Majukhan, Po: Harbaid, Ps Gazipur Sadar, Gazipur Bangladesh Fashion 2410 70% 30% Yes Direct Sports & Leisurewear (Bd) Limited Plot No. S.A. 07, 08, R.S. 11, 12, 13 Karamtola Pubail Gazipur, Dhaka, Bangladesh Fashion 374 65% 35% No Energypac Fashion Ltd. -
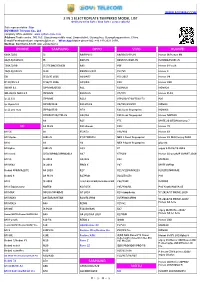
2 in 1 Electroplate Tempered Model List Iphone Samsung
WWW.BOYIMAX.COM 2 IN 1 ELECTROPLATE TEMPERED MODEL LIST Ordinary white light / blue light / aurora colorful Sale representative :Star BOYIMAX® Telecom Co., Ltd company office website: www.i-phonecase.com Address:Trade centra , NO.163, Qiaozhong middle road, Liwan distirct, Guangzhou, Guangdong province, China. E-mail/Facebook/skype: [email protected] ,WhatsApp/Mobile phone NO.:+86 189 2621 0199, WeChat: BOYIMAX-STAR ,QQ: 2233234410 IPHONE SAMSUNG OPPO VIVO HUAWEI 6G(4.7)/6S J2 R9/FIPLUS X9/X9S/V5PLUS Honor 9I/Honor 9N 6G(5.5)/6SPLUS J5 R9PLUS X9SPLUS/X9PLUS P20PRO/P20PLUS 7G(4.7)/8G J7/J7CORE/J7NEO R9S Y66 Honor 9 Youth 7G(5.5)/8PLUS J120 R9SPLUS/F3P Y67/V5 Honor 9 5G J510/J5 2016 A39/A57 Y53 2017 Honor V9 IP 8X/XS 5.8 J710/J7 2016 A59/FIS X20 Honor V10 9G/XR 6.1 J2PRIME/G530 R11 X20PLUS NOVA2S 9PLUS/XS MAX 6.5 J5PRIME R11PLUS V7/Y75 Honor PLAY ip 11 6.1 J7PRIME R11S V7PLUS/Y79/Y75S/Y73 P20 ip 11pro 5.8 J3PRO/J330 R11SPLUS V9/Y85/Z1\Z3X NOVA3 ip 11 pro max J5PRO/J530 A79 X21 back fingerprint NOVA3I J7PRO/J730/J7PLUS A83/A1 X21 front fingerprint Honor NOTE10 A8 R15 Y71 MATE 20 LITE/Maimang 7 MI A8 PLUS R15 dream X21I Honor 7X MI 5X S8 F5/A73 Y83/Y81 Honor 8X MI 5Splus S8PLUS F7/F7YOUTH NEX S front fingerprint Honor 8X MAX/enjoy MAX MI 6 S9 A3 NEX A back fingerprint play 8C MI 6plus S9PLUS A33 X7 enjoy 9 PLUS/Y9 2019 MI note3 J250/J2PRO/J2PRO2018 A37 X7PLUS Honor 10 youth/P SMART 2019 MI 5S J4 2018 A5/A3S X23 MATE20 MI MIX2 J6 2018 FIND X Y97 MATE20PRO Redmi 6PRO/A2LITE A6 2018 R17 V11/V11PRO/X21S P20LITE/NOVA3E Redmi 6 A6 PLUS R17PRO V11I/Z3I/Z3 -

Ew 01357AR-25032021.Pdf
Contents Annual Report 2020 Contents Contents CORPORATE INFORMATION 2 2020 HIGHLIGHTS 4 KEY FINANCIAL DATA OF CONTINUING OPERATIONS 5 KEY OPERATIONAL DATA OF CONTINUING OPERATIONS 6 CHAIRMAN’S STATEMENT 7 MANAGEMENT DISCUSSION AND ANALYSIS 10 DIRECTORS AND SENIOR MANAGEMENT 21 REPORT OF THE DIRECTORS 28 CORPORATE GOVERNANCE REPORT 61 ENVIRONMENTAL, SOCIAL AND GOVERNANCE REPORT 78 INDEPENDENT AUDITOR’S REPORT 109 CONSOLIDATED INCOME STATEMENT 115 CONSOLIDATED STATEMENT OF COMPREHENSIVE INCOME 116 CONSOLIDATED BALANCE SHEET 117 CONSOLIDATED STATEMENT OF CHANGES IN EQUITY 119 CONSOLIDATED STATEMENT OF CASH FLOWS 121 NOTES TO THE CONSOLIDATED FINANCIAL STATEMENTS 123 FIVE YEAR FINANCIAL SUMMARY 216 DEFINITIONS 217 1 Corporate Information MEITU, INC. Corporate Information BOARD OF DIRECTORS AUDITOR PricewaterhouseCoopers Executive Directors Certified Public Accountants Mr. CAI Wensheng (Chairman of the Board) Registered Public Interest Entity Auditor Mr. WU Zeyuan (also known as: Mr. WU Xinhong) REGISTERED OFFICE Non-Executive Directors The offices of Conyers Trust Company (Cayman) Limited Dr. GUO Yihong Cricket Square, Hutchins Drive Dr. LEE Kai-fu PO Box 2681 Mr. CHEN Jiarong Grand Cayman, KY1-1111 Cayman Islands Independent Non-Executive Directors Mr. ZHOU Hao HEADQUARTERS Mr. LAI Xiaoling 1-3/F, Block 2 Mr. ZHANG Ming (also known as: Mr. WEN Chu) Building No. 6, Wanghai Road Ms. KUI Yingchun Siming District Xiamen, Fujian AUDIT COMMITTEE PRC Mr. ZHOU Hao (Chairman) Dr. GUO Yihong PRINCIPAL PLACE OF BUSINESS Mr. LAI Xiaoling IN HONG KONG Room 8106B, Level 81 REMUNERATION COMMITTEE International Commerce Centre Mr. LAI Xiaoling (Chairman) 1 Austin Road West Dr. LEE Kai-fu Kowloon Mr. ZHANG Ming (also known as: Mr. -

Meitu, Inc. 美图公司 (Incorporated in the Cayman Islands with Limited Liability and Carrying on Business in Hong Kong As “美圖之家”) (Stock Code: 1357)
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this announcement. Meitu, Inc. 美图公司 (Incorporated in the Cayman Islands with limited liability and carrying on business in Hong Kong as “美圖之家”) (Stock Code: 1357) INSIDE INFORMATION AND PROFIT WARNING This announcement is made by Meitu, Inc. (the “Company”, together with its subsidiaries and Xiamen Meitu Networks Technology Co., Ltd. and its subsidiaries, collectively the “Group”, “we” or “us”) pursuant to Rule 13.09(2)(a) of the Rules Governing the Listing of Securities on The Stock Exchange of Hong Kong Limited (the “Listing Rules”) and the Inside Information Provisions (as defined under the Listing Rules) under Part XIVA of the Securities and Futures Ordinance (Chapter 571 of the Laws of Hong Kong). INSIDE INFORMATION REGARDING THE GROUP'S SMART HARDWARE BUSINESS The board (the “Board”) of directors (the “Directors”) of the Company is pleased to announce that on November 19, 2018, the Company and Xiaomi Corporation (a company incorporated in the Cayman Islands with limited liability and listed on the Main Board of The Stock Exchange of Hong Kong Limited with stock code: 1810) (“Xiaomi”) entered into a strategic cooperation framework agreement (the “Strategic Cooperation Agreement”). While the Group remains committed to grow the Meitu branded smartphones and other smart hardware business, the Board has determined that it is in the Group's interests to operate this business by way of cooperating with a partner with the scale and reach of Xiaomi. -

Electronic 3D Models Catalogue (On July 26, 2019)
Electronic 3D models Catalogue (on July 26, 2019) Acer 001 Acer Iconia Tab A510 002 Acer Liquid Z5 003 Acer Liquid S2 Red 004 Acer Liquid S2 Black 005 Acer Iconia Tab A3 White 006 Acer Iconia Tab A1-810 White 007 Acer Iconia W4 008 Acer Liquid E3 Black 009 Acer Liquid E3 Silver 010 Acer Iconia B1-720 Iron Gray 011 Acer Iconia B1-720 Red 012 Acer Iconia B1-720 White 013 Acer Liquid Z3 Rock Black 014 Acer Liquid Z3 Classic White 015 Acer Iconia One 7 B1-730 Black 016 Acer Iconia One 7 B1-730 Red 017 Acer Iconia One 7 B1-730 Yellow 018 Acer Iconia One 7 B1-730 Green 019 Acer Iconia One 7 B1-730 Pink 020 Acer Iconia One 7 B1-730 Orange 021 Acer Iconia One 7 B1-730 Purple 022 Acer Iconia One 7 B1-730 White 023 Acer Iconia One 7 B1-730 Blue 024 Acer Iconia One 7 B1-730 Cyan 025 Acer Aspire Switch 10 026 Acer Iconia Tab A1-810 Red 027 Acer Iconia Tab A1-810 Black 028 Acer Iconia A1-830 White 029 Acer Liquid Z4 White 030 Acer Liquid Z4 Black 031 Acer Liquid Z200 Essential White 032 Acer Liquid Z200 Titanium Black 033 Acer Liquid Z200 Fragrant Pink 034 Acer Liquid Z200 Sky Blue 035 Acer Liquid Z200 Sunshine Yellow 036 Acer Liquid Jade Black 037 Acer Liquid Jade Green 038 Acer Liquid Jade White 039 Acer Liquid Z500 Sandy Silver 040 Acer Liquid Z500 Aquamarine Green 041 Acer Liquid Z500 Titanium Black 042 Acer Iconia Tab 7 (A1-713) 043 Acer Iconia Tab 7 (A1-713HD) 044 Acer Liquid E700 Burgundy Red 045 Acer Liquid E700 Titan Black 046 Acer Iconia Tab 8 047 Acer Liquid X1 Graphite Black 048 Acer Liquid X1 Wine Red 049 Acer Iconia Tab 8 W 050 Acer -

Technology 6 November 2017
INDUSTRY NOTE China | Technology 6 November 2017 Technology EQUITY RESEARCH China Summit Takeaway: AI, Semi, Smartphone Value Chain Key Takeaway We hosted several experts and 24 A/H corporates at our China Summit and Digital Disruption tour last week. Key takeaways: 1) AI shifting from central cloud to the edge (end devices), driving GPU/FPGA demand in near term, 2) AI leaders in China rolling out own ASICs in the next 2~3 years, 3) China's new role in semi, forging ahead in design and catching up in foundry. In smartphone value chain, maintain AAC as top pick for lens opportunity and Xiaomi strength. CHINA Artificial Intelligence - From cloud to edge computing: The rise of AI on the edge (terminal devices, like surveillance cameras, smartphones) from central cloud, can solve one key weakness of AI: the brains are located thousands of miles away from the applications. The benefits of AI on the edge include: 1) better analysis based on non-compressed raw data, which contains more information, 2) lower requirement on bandwidth, as transmitted data has been pre-processed, 3) faster response. This will keep driving the demands for GPUs and FPGAs in near term. Meanwhile, China's leading AI companies including Hikvision (002415 CH) and Unisound (private, leader in voice recognition) also noted they may develop own ASICs in the next 2~3 years, for better efficiency and low power. While machines getting smarter, we notice increasing concerns on data privacy. Governments are not only implementing Big Data laws and policies, also starts investing AI leaders, like Face ++ (computer vision) in China. -

A Video-Based Attack for Android Pattern Lock
This is a repository copy of A Video-based Attack for Android Pattern Lock. White Rose Research Online URL for this paper: http://eprints.whiterose.ac.uk/151216/ Version: Accepted Version Article: Ye, G, Tang, Z, Fang, D et al. (4 more authors) (2018) A Video-based Attack for Android Pattern Lock. ACM Transactions on Privacy and Security, 21 (4). 19. ISSN 2471-2566 https://doi.org/10.1145/3230740 © 2018, ACM. This is the author's version of the work. It is posted here for your personal use. Not for redistribution. The definitive Version of Record was published in ACM Transactions on Privacy and Security (TOPS), https://doi.org/10.1145/3230740. Reuse Items deposited in White Rose Research Online are protected by copyright, with all rights reserved unless indicated otherwise. They may be downloaded and/or printed for private study, or other acts as permitted by national copyright laws. The publisher or other rights holders may allow further reproduction and re-use of the full text version. This is indicated by the licence information on the White Rose Research Online record for the item. Takedown If you consider content in White Rose Research Online to be in breach of UK law, please notify us by emailing [email protected] including the URL of the record and the reason for the withdrawal request. [email protected] https://eprints.whiterose.ac.uk/ A Video-based Atack for Android Patern Lock GUIXIN YE, ZHANYONG TANG∗, DINGYI FANG, XIAOJIANG CHEN, Northwest University, China WILLY WOLFF, Lancaster University, U. K. ADAM J. -

携手新时代 共赢创未来 Innovating and Collaborating for What’S Next
携手新时代 共赢创未来 Innovating and collaborating for what’s next Qualcomm中国技术与合作峰会 Qualcomm Technology Day January 25, 2018 #Qualcomm中国技术与合作峰会# Beijing, China Welcome Frank Meng Chairman Qualcomm International, Inc. China January 25, 2018 #Qualcomm中国技术与合作峰会# Beijing, China The opportunity ahead Steve Mollenkopf CEO Qualcomm Incorporated Years of driving the 30+ evolution of wireless Fabless # semiconductor 1 company ~8.6 Billion Cumulative smartphone unit shipments forecast between 2017–2021 Source: Gartner, Sep. ‘17 Mobile technology is powering the 5G global economy The mobile roadmap is leading the way Qualcomm is the R&D engine A strategy for continued growth $20B — RF-Front End Extending the reach of mobile technology $77B — Adjacent industries Core mobile — $32B ~$150B Datacenter — $19B Serviceable addressable Automotive IoT and security opportunity in 2020 $16B $43B Mobile compute Networking $7B $11B Source: combination of third party and internal estimates. Includes SAM for pending NXP acquisition. Note: SAM excludes QTL. Executing on our strategy Automotive IoT and security >$3 Billion in FY17 QCT revenues Up >75% over FY15 Mobile compute Networking FY17 revenue across auto, IoT, security, networking and mobile compute A proven business model that has enabled value creation between China and US Invent Share Collaborate Our commitment to China Supporting growth across many industries China Mobile Semiconductors Automotive China Telecom SMIC | SJ Semiconductor Geely | BYD | ZongMu China Unicom Corp. Huaqin Longcheer IoT Mobile WingTech -

We Hope This Letter Finds You and Your Families Safe and Well
May 2021 Dear Fellow Stockholders: We hope this letter finds you and your families safe and well. The past year will be remembered as the year of COVID-19. It was a year in which a global pandemic was declared, triggering a global health and financial crisis. Our ability to rapidly pivot and prevail under these fast-changing and uncertain conditions is a testimony to our perseverance, agility, focus and strength as an organization. We are proud that during fiscal year 2020 our team continued to deliver on our commitments to our stockholders. Notwithstanding the financial and commercial turbulence brought on by the crisis, we were able to execute prudently, expand our market reach, build value for our customers, partners and communities, deliver solid results and emerge a stronger and more resilient organization. Our technologies and solutions are playing a more instrumental role in the new paradigm under which we are—and will likely continue to be—living and working. In this new paradigm, there is significantly more time spent at home offices where interactions are predominantly made via collaboration tools that substitute for travel and face-to-face meeting. This means more voice and video call traffic. In addition, individuals and organizations, now more than ever, are reliant on digital transformation using voice as a preferred interface to control things intuitively and touch free. Moreover, advanced collaboration and communication tools are increasingly necessary to drive business continuity and productivity. Our innovative products -

Qualcomm® Quick Charge™ Technology Device List
One charging solution is all you need. Waiting for your phone to charge is a thing of the past. Quick Charge technology is ® designed to deliver lightning-fast charging Qualcomm in phones and smart devices featuring Qualcomm® Snapdragon™ mobile platforms ™ and processors, giving you the power—and Quick Charge the time—to do more. Technology TABLE OF CONTENTS Quick Charge 5 Device List Quick Charge 4/4+ Quick Charge 3.0/3+ Updated 09/2021 Quick Charge 2.0 Other Quick Charge Devices Qualcomm Quick Charge and Qualcomm Snapdragon are products of Qualcomm Technologies, Inc. and/or its subsidiaries. Devices • RedMagic 6 • RedMagic 6Pro Chargers • Baseus wall charger (CCGAN100) Controllers* Cypress • CCG3PA-NFET Injoinic-Technology Co Ltd • IP2726S Ismartware • SW2303 Leadtrend • LD6612 Sonix Technology • SNPD1683FJG To learn more visit www.qualcomm.com/quickcharge *Manufacturers may configure power controllers to support Quick Charge 5 with backwards compatibility. Power controllers have been certified by UL and/or Granite River Labs (GRL) to meet compatibility and interoperability requirements. These devices contain the hardware necessary to achieve Quick Charge 5. It is at the device manufacturer’s discretion to fully enable this feature. A Quick Charge 5 certified power adapter is required. Different Quick Charge 5 implementations may result in different charging times. Devices • AGM X3 • Redmi K20 Pro • ASUS ZenFone 6* • Redmi Note 7* • Black Shark 2 • Redmi Note 7 Pro* • BQ Aquaris X2 • Redmi Note 9 Pro • BQ Aquaris X2 Pro • Samsung Galaxy