Compression-Based Investigation of the Dynamical Properties of Cellular Automata and Other Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

On Soliton Collisions Between Localizations in Complex ECA: Rules 54 and 110 and Beyond
On soliton collisions between localizations in complex ECA: Rules 54 and 110 and beyond Genaro J. Mart´ınez Departamento de Ciencias e Ingenier´ıade la Computaci´on, Escuela Superior de C´omputo,Instituto Polit´ecnico Nacional, M´exico Unconventional Computing Center, Computer Science Department, University of the West of England, Bristol BS16 1QY, United Kingdom genaro. martinez@ uwe. ac. uk Andrew Adamatzky Unconventional Computing Center, Computer Science Department, University of the West of England, Bristol BS16 1QY, United Kingdom andrew. adamatzky@ uwe. ac. uk Fangyue Chen School of Sciences, Hangzhou Dianzi University Hangzhou, Zhejiang 310018, P. R. China fychen@ hdu. edu. cn Leon Chua Electrical Engineering and Computer Sciences Department University of California at Berkeley, California, United States of America chua@ eecs. berkeley. edu In this paper we present a single-soliton two-component cellular au- tomata (CA) model of waves as mobile self-localizations, also known as: particles, waves, or gliders; and its version with memory. The model is based on coding sets of strings where each chain represents a unique mobile self-localization. We will discuss briefly the original soli- ton models in CA proposed with filter automata, followed by solutions in elementary CA (ECA) domain with the famous universal ECA Rule 110, and reporting a number of new solitonic collisions in ECA Rule 54. A mobile self-localization in this study is equivalent a single soliton because the collisions of these mobile self-localizations studied in this paper satisfies the property of solitonic collisions. We also present a arXiv:1301.6258v1 [nlin.CG] 26 Jan 2013 specific ECA with memory (ECAM), the ECAM Rule φR9maj:4, that displays single-soliton solutions from any initial codification (including random initial conditions) for a kind of mobile self-localization because such automaton is able to adjust any initial condition to soliton struc- tures. -

Investigation of Elementary Cellular Automata for Reservoir Computing
Investigation of Elementary Cellular Automata for Reservoir Computing Emil Taylor Bye Master of Science in Computer Science Submission date: June 2016 Supervisor: Stefano Nichele, IDI Norwegian University of Science and Technology Department of Computer and Information Science Summary Reservoir computing is an approach to machine learning. Typical reservoir computing approaches use large, untrained artificial neural networks to transform an input signal. To produce the desired output, a readout layer is trained using linear regression on the neural network. Recently, several attempts have been made using other kinds of dynamic systems in- stead of artificial neural networks. Cellular automata are an example of a dynamic system that has been proposed as a replacement. This thesis attempts to discover whether cellular automata are a viable candidate for use in reservoir computing. Four different tasks solved by other reservoir computing sys- tems are attempted with elementary cellular automata, a limited subset of all possible cellular automata. The effect of changing different properties of the cellular automata are investigated, and the results are compared with the results when performing the same experiments with typical reservoir computing systems. Reservoir computing seems like a potentially very interesting utilization of cellular automata. However, it is evident that more research into this field is necessary to reach performance comparable to existing reservoir computing systems. i ii Acknowledgements I would like to express my very great appreciation to my supervisor, Dr. Stefano Nichele. His insights, guidance and encouragement has proven invaluable and vital to the comple- tion of this thesis. I would also like to offer my special thanks to Solveig Isabel Taylor, who apart from being an excellent proofreader, also did a marvelous job at helping me search for literature. -

Universality in Elementary Cellular Automata
Universality in Elementary Cellular Automata Matthew Cook Department of Computation and Neural Systems,! Caltech, Mail Stop 136-93, Pasadena, California 91125, USA The purpose of this paper is to prove a conjecture made by Stephen Wolfram in 1985, that an elementary one dimensional cellular automaton known as “Rule 110” is capable of universal computation. I developed this proof of his conjecture while assisting Stephen Wolfram on research for A New Kind of Science [1]. 1. Overview The purpose of this paper is to prove that one of the simplest one di- mensional cellular automata is computationally universal, implying that many questions concerning its behavior, such as whether a particular se- quence of bits will occur, or whether the behavior will become periodic, are formally undecidable. The cellular automaton we will prove this for is known as “Rule 110” according to Wolfram’s numbering scheme [2]. Being a one dimensional cellular automaton, it consists of an infinitely long row of cells "Ci # i $ !%. Each cell is in one of the two states "0, 1%, and at each discrete time step every cell synchronously updates ' itself according to the value of itself and its nearest neighbors: &i, Ci ( F(Ci)1, Ci, Ci*1), where F is the following function: F(0, 0, 0) ( 0 F(0, 0, 1) ( 1 F(0, 1, 0) ( 1 F(0, 1, 1) ( 1 F(1, 0, 0) ( 0 F(1, 0, 1) ( 1 F(1, 1, 0) ( 1 F(1, 1, 1) ( 0 This F encodes the idea that a cell in state 0 should change to state 1 exactly when the cell to its right is in state 1, and that a cell in state 1 should change to state 0 just when the cells on both sides are in state 1. -

Lecture P4: Cellular Automata Arrays Allow Manipulation of Potentially Huge Amounts of Data
Array Review Lecture P4: Cellular Automata Arrays allow manipulation of potentially huge amounts of data. ■ All elements of the same type. – double, int ■ N-element array has elements indexed 0 through N-1. ■ Fast access to arbitrary element. – a[i] ■ Waste of space if array is "sparse." Reaction diffusion textures. Andy Witkin and Michael Kass Princeton University • COS 126 • General Computer Science • Fall 2002 • http://www.Princeton.EDU/~cs126 2 Cellular Automata Applications of Cellular Automata Cellular automata. (singular = cellular automaton) Modern applications. ■ Computer simulations that try to emulate laws of nature. ■ Simulations of biology, chemistry, physics. ■ Simple rules can generate complex patterns. – ferromagnetism according to Ising mode – forest fire propagation – nonlinear chemical reaction-diffusion systems – turbulent flow John von Neumann. (Princeton IAS, 1950s) – biological pigmentation patterns ■ Wanted to create and simulate artificial – breaking of materials life on a machine. – growth of crystals ■ Self-replication. – growth of plants and animals ■ ■ "As simple as possible, but no simpler." Image processing. ■ Computer graphics. ■ Design of massively parallel hardware. ■ Art. 3 4 How Did the Zebra Get Its Stripes? One Dimensional Cellular Automata 1-D cellular automata. ■ Sequence of cells. ■ Each cell is either black (alive) or white (dead). ■ In each time step, update status of each cell, depending on color of nearby cells from previous time step. Example rule. Make cell black at time t if at least one of its proper neighbors was black at time t-1. time 0 time 1 time 2 Synthetic zebra. Greg Turk 5 6 Cellular Automata: Designing the Code Cellular Automata: The Code How to store the row of cells. -
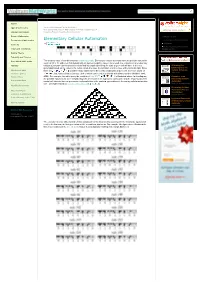
Elementary Cellular Automaton Calculus and Analysis Interactive Entries > Interactive Demonstrations >
Search MathWorld Algebra Applied Mathematics Discrete Mathematics > Cellular Automata > Recreational Mathematics > Mathematical Art > Mathematical Images > elementary cellular automaton Calculus and Analysis Interactive Entries > Interactive Demonstrations > Discrete Mathematics THINGS TO TRY: Foundations of Mathematics Elementary Cellular Automaton elementary cellular automaton 39th prime Geometry do the algebraic units contain History and Terminology Sqrt[2]+Sqrt[3]? Number Theory Probability and Statistics Recreational Mathematics The simplest class of one-dimensional cellular automata. Elementary cellular automata have two possible values for each cell (0 or 1), and rules that depend only on nearest neighbor values. As a result, the evolution of an elementary Topology cellular automaton can completely be described by a table specifying the state a given cell will have in the next A Strategy for generation based on the value of the cell to its left, the value the cell itself, and the value of the cell to its right. Since Exploring k=2, r=2 Alphabetical Index there are possible binary states for the three cells neighboring a given cell, there are a total of Cellular Automata John Kiehl Interactive Entries elementary cellular automata, each of which can be indexed with an 8-bit binary number (Wolfram 1983, Random Entry 2002). For example, the table giving the evolution of rule 30 ( ) is illustrated above. In this diagram, Dynamics of an the possible values of the three neighboring cells are shown in the top row of each panel, and the resulting value the Elementary Cellular New in MathWorld central cell takes in the next generation is shown below in the center. generations of elementary cellular automaton Automaton rule are implemented as CellularAutomaton[r, 1 , 0 , n]. -

Wolfram's Classification and Computation in Cellular Automata
Wolfram's Classification and Computation in Cellular Automata Classes III and IV Genaro J. Mart´ınez1, Juan C. Seck-Tuoh-Mora2, and Hector Zenil3 1 Unconventional Computing Center, Bristol Institute of Technology, University of the West of England, Bristol, UK. Departamento de Ciencias e Ingenier´ıade la Computaci´on,Escuela Superior de C´omputo,Instituto Polit´ecnicoNacional, M´exico. [email protected] 2 Centro de Investigaci´onAvanzada en Ingenier´ıaIndustrial Universidad Aut´onomadel Estado de Hidalgo, M´exico. [email protected] 3 Behavioural and Evolutionary Theory Lab Department of Computer Science, University of Sheffield, UK. [email protected] Abstract We conduct a brief survey on Wolfram's classification, in particular related to the computing capabilities of Cellular Automata (CA) in Wol- fram's classes III and IV. We formulate and shed light on the question of whether Class III systems are capable of Turing universality or may turn out to be \too hot" in practice to be controlled and programmed. We show that systems in Class III are indeed capable of computation and that there is no reason to believe that they are unable, in principle, to reach Turing-completness. Keywords: cellular automata, universality, unconventional computing, complexity, gliders, attractors, Mean field theory, information theory, compressibility. arXiv:1208.2456v2 [nlin.CG] 29 Aug 2012 1 Wolfram's classification of Cellular Automata A comment in Wolfram's A New Kind of Science gestures toward the first dif- ficult problem we will tackle (ANKOS) (page 235): trying to predict detailed properties of a particular cellular automaton, it was often enough just to know what class the cellular automaton was in. -

Complex Systems 530 2/9/21 What Is a Cellular Automaton?
Lecture 5: Introduction to Cellular Automata Complex Systems 530 2/9/21 What is a cellular automaton? • Automata: “a theoretical machine that changes its internal state based on inputs and its previous state” (usually finite and discrete) - Sayama p.185 • Cellular automata: automata on a regular spatial grid, that update state based on their neighbors’ states, using a state transition function • Usually synchronous, discrete in time & space, often deterministic (but not always!) 11.1. DEFINITION OF CELLULAR AUTOMATA 187 Configulation Configulation at time t at time t+1 Neighborhood T L C R B State set State-transition function C TR B L C TR B L C TR B L C TR B L { , } Figure 11.1: Schematic illustration of how cellular automata work. Sayama p. 187 (Chp. 11) Figure 11.2: Examples of neighborhoods often used for two-dimensional CA. Left: von Neumann neighborhood. Right: Moore neighborhood. Cellular automata • Cellular automata can generate highly nonlinear, even seemingly random behavior • Much more complexity than one might expect from simple rules—emergent behavior • To explore this, let’s start with an even ‘simpler’ type of cellular automata—1-dimensional CA and some of the classic work of Stephen Wolfram 1-dimensional CA • We can think of our grid as a string or line of cells • Finite sequence - 1 row of cells, so everyone has 2 neighbors except the end points • Choose how to interpret the ends (lack of neighbors or fixed states at ends) • Ring - all cells have 2 neighbors • Infinite sequence - an infinite number of cells arranged in a row 52 Chapter 6. -

CELLULAR AUTOMATA and APPLICATIONS 1. Introduction This
CELLULAR AUTOMATA AND APPLICATIONS GAVIN ANDREWS 1. Introduction This paper is a study of cellular automata as computational programs and their remarkable ability to create complex behavior from simple rules. We examine a number of these simple programs in order to draw conclusions about the nature of complexity seen in the world and discuss the potential of using such programs for the purposes of modeling. The information presented within is in large part the work of mathematician Stephen Wolfram, as presented in his book A New Kind of Science[1]. Section 2 begins by introducing one-dimensional cellular automata and the four classifications of behavior that they exhibit. In sections 3 and 4 the concept of computational universality discovered by Alan Turing in the original Turing machine is introduced and shown to be present in various cellular automata that demonstrate Class IV behav- ior. The idea of computational complexity as it pertains to universality and its implications for modern science are then examined. In section 1 2 GAVIN ANDREWS 5 we discuss the challenges and advantages of modeling with cellular automata, and give several examples of current models. 2. Cellular Automata and Classifications of Complexity The one-dimensional cellular automaton exists on an infinite hori- zontal array of cells. For the purposes of this section we will look at the one-dimensional cellular automata (c.a.) with square cells that are limited to only two possible states per cell: white and black. The c.a.'s rules determine how the infinite arrangement of black and white cells will be updated from time step to time step. -

Tesi Doctoral
. 472 (28-02-90) (28-02-90) 472 . TESI DOCTORAL Privada. Rgtre. Fund. Generalitat de Catalunya núm Catalunya de Generalitat Fund. Rgtre. Privada. Títol Aspects of algorithms and dynamics of cellular paradigms Realitzada per Giovanni E. Pazienza en el Centre Enginyeria i Arquitectura La Salle C.I.F. G: 59069740 Universitat Ramon Lull Fundació Lull Ramon Universitat 59069740 G: C.I.F. i en el Departament Electrónica y Comunicaciones Dirigida per Xavier Vilasís Cardona C. Claravall, 1-3 08022 Barcelona Tel. 936 022 200 Fax 936 022 249 E-mail: [email protected] www.url.es Aspects of algorithms and dynamics of cellular paradigms Giovanni E. Pazienza Ph.D. dissertation Supervisor: Dr. Xavier Vilas´ıs-Cardona Universitat Ramon Llull, December 2008 to Pedro, who is fighting for life Contents 1 Introduction 1 2 Cellular paradigms 5 2.1 Cellular Neural Networks . 5 2.2 CNN Universal Machine . 8 2.3 Cellular wave computer . 9 2.4 Cellular automata . 11 2.5 A glimpse of physical implementations of cellular paradigms . 17 2.5.1 Chips and emulations on reconfigurable devices . 18 2.5.2 Simulation on Graphics Processing Units . 19 3 Alternative proof for the universality of the CNN-UM 21 3.1 Turing machines, universality, and computability . 21 3.2 Universal CNN models . 23 3.3 GP+IM machine: an example of universal Turing machine . 24 3.4 Equivalent ways of describing CNN-UM functions . 26 3.4.1 Universal Machine on Flows diagrams . 27 3.4.2 Strings and binary trees . 28 3.4.3 Directed Acyclic Graphs . -

FINITE-WIDTH ELEMENTARY CELLULAR AUTOMATA 1. Introduction Stephen Wolfram's a New Kind of Science Explores Elementary Cellular
FINITE-WIDTH ELEMENTARY CELLULAR AUTOMATA IAN COLEMAN Abstract. This paper is an empirical study of eight-wide elementary cellu- lar automata motivated by Stephen Wolfram's conjecture about widespread universality in regular elementary cellular automata. Through examples, the concepts of equivalence, reversibility, and additivity in elementary cellular au- tomata are explored. In addition, we will view finite-width cellular automata in the context of finite-size state transition diagrams and develop foundational results about the behavior of finite-width elementary cellular automata. 1. Introduction Stephen Wolfram's A New Kind of Science explores elementary cellular au- tomata and universality in simple computational systems [3]. In 1985, Wolfram conjectured that an elementary cellular automaton could be Turing complete, thus capable of universal computation. At the turn of the century, Matthew Cook pub- lished a proof confirming that a particular cellular automaton, known as \Rule 110," was universal [1]. Wolfram currently conjectures that universality in non-trivial cel- lular automata (and other simple systems) is likely to be extremely common. This paper, in addition to an outline of Wolfram's basic work, is an empirical study seeking to add information and insight to the exploration of elementary cellular automata. Elementary cellular automata have become relevant given Wolfram's develop- ment of the Principle of Computational Equivalence. From Wolfram, the Principle of Computational Equivalence states that \almost all processes that are not ob- viously simple can be viewed as computations of equivalent sophistication [3, p. 5 , 716-717]." Wolfram's MathWorld explains further that \the principle of com- putational equivalence says that systems found in the natural world can perform computations up to a maximal (\universal") level of computational power, and that most systems do in fact attain this maximal level of computational power. -

Cellular Automata in Cryptographic Random Generators
Cellular Automata in Cryptographic Random Generators Jason Spencer College of Computing and Digital Media DePaul University arXiv:1306.3546v1 [cs.CR] 15 Jun 2013 A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science May 1, 2013 Abstract Cryptographic schemes using one-dimensional, three-neighbor cellular automata as a primitive have been put forth since at least 1985. Early results showed good statistical pseudorandomness, and the simplicity of their construction made them a natural candidate for use in cryptographic applications. Since those early days of cellular automata, research in the field of cryptography has developed a set of tools which allow designers to prove a particular scheme to be as hard as solving an instance of a well- studied problem, suggesting a level of security for the scheme. However, little or no literature is available on whether these cellular automata can be proved secure under even generous assumptions. In fact, much of the literature falls short of providing complete, testable schemes to allow such an analysis. In this thesis, we first examine the suitability of cellular automata as a primitive for building cryptographic primitives. In this effort, we focus on pseudorandom bit generation and noninvertibility, the behavioral heart of cryptography. In particular, we focus on cyclic linear and non-linear au- tomata in some of the common configurations to be found in the literature. We examine known attacks against these constructions and, in some cases, improve the results. Finding little evidence of provable security, we then examine whether the desirable properties of cellular automata (i.e. -
![Arxiv:2108.08606V1 [Cs.AI] 19 Aug 2021](https://docslib.b-cdn.net/cover/9325/arxiv-2108-08606v1-cs-ai-19-aug-2021-6379325.webp)
Arxiv:2108.08606V1 [Cs.AI] 19 Aug 2021
Prof. Sch¨onhage'sMysterious Machines J.-M. Chauvet Abstract. We give a simple Sch¨onhage'sStorage Modification Machine that simulates one iteration of the Rule 110 cellular automaton. This provides an alternative construction to the original Sch¨onhage's proof of the Turing completeness of the eponymous machines. 1 Introduction By a simple construction it is shown that iterations performed by the Rule 110 elementary cellular automaton can be duplicated by a small size Sch¨onhage Storage Modification Machine. 1.1 The Rule 110 cellular automaton Rule 110 is one of the elementary cellular automaton rules introduced by Stephen Wolfram in 1983 [5]. It specifies the next color in a cell, white or black, depend- ing on its color and its immediate neighbors. Its rule outcomes are encoded in the binary representation: 110decimal = 01101110binary. The rule 110 cellular au- tomaton is universal, as first conjectured by Wolfram and subsequently proven by Wolfram and Cook [1]. Fig. 1. Compact representation of the ECA Rule 110 Simulation of small universal Turing machines, or other simple universal models such as Post's tag systems and the cellular automaton Rule 110, is by now arXiv:2108.08606v1 [cs.AI] 19 Aug 2021 a standard way to prove that a large number of other models of computation, including a variety of physically-inspired systems, are computationally universal. In the following, we consider a slightly revised version of Sch¨onhage'sStorage Modification Machine (SMM) and propose such a simulation of the Rule 110 automaton. 1.2 Sch¨onhage'sStorage Modification Machines The variant presented here is from [2] where it is used to implement population protocol models.